

{kind=link}
Think about the next situation: you and a workforce of cyber specialists have been tasked with defending your group from cyberattacks. You’ve developed a machine studying (ML) mannequin to display incoming and outgoing site visitors. You’re feeling you possibly can relaxation straightforward, as your mannequin achieves near-perfect efficiency throughout check and analysis. At some point, you might be woke up by a frantic name out of your CEO—your prospects’ personal knowledge have been leaked. How may this occur? you suppose to your self, as you start investigating why your mannequin didn’t cease this assault.
This example is just not merely hypothetical. Research have discovered that fashions that have been as soon as extremely efficient at detecting malicious exercise turn out to be considerably much less efficient as assault patterns evolve (in Android purposes, encrypted site visitors, and malware). As ML and different synthetic intelligence (AI) fashions turn out to be pervasive, it’s more and more vital to make sure these fashions proceed to carry out effectively when deployed. For cybersecurity fashions, this implies they need to be capable of adapt to counter clever adversaries as they evolve their strategies. Repeatedly monitoring efficiency for indicators of drift and retraining, when mandatory, may be important to keep away from vital and dear losses.
On the Software program Engineering Institute (SEI), we’ve an extended historical past of labor on the forefront of cybersecurity and machine studying, from establishing C/C++ safe coding requirements to founding the primary AI safety incident response workforce. Whereas ML is a probably transformative know-how for securing info techniques, the cyber panorama is ever altering as a result of the behaviors of customers, attackers, and knowledge techniques evolve over time. If not addressed, these modifications can degrade the efficiency of even the perfect ML-based defenses. Measures have to be in place to detect and reply to drift earlier than real-world harms are enacted.
On this put up, we describe what causes drift, talk about how you can detect it, and supply a case research.
What Is Drift?
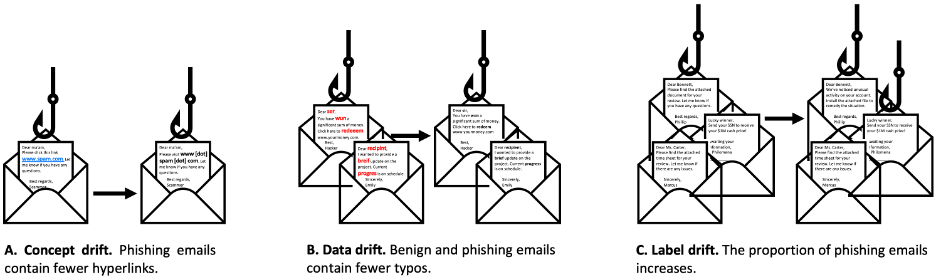
Issues change over time. {Hardware} and software program techniques are up to date, people undertake new behaviors, and environments shift. Adversaries adapt their ways. Modifications that have an effect on knowledge used or predicted by an ML mannequin are referred to as drift. There are three major varieties of drift: knowledge drift, idea drift, and label drift. We illustrate these utilizing an ML-based e-mail classifier for instance:
{kind=link}

Idea drift is outlined by modifications within the relationships between options and outcomes. Idea drift may be notably problematic as a result of the discovered relationship between options and outcomes could now not maintain. Idea drift is extremely related in settings the place adversarial actions are frequent. When adversaries purpose to evade detection, they might modify their behaviors, for instance to raised mimic benign customers. For instance, adversaries sending phishing emails could uncover emails containing hyperlinks are blocked by our phishing classifier mannequin. To bypass this, adversaries could cease together with hyperlinks in phishing emails, altering the connection between hyperlink-containing textual content and the chance an e-mail is a phishing try (Determine 1, Panel A).
Information drift—generally referred to as function or covariate drift—refers to modifications within the distributions of a number of options over time. Information drift alone doesn’t have an effect on relationships between options and outcomes. For a classifier, knowledge drift happens when one thing impacts all courses equally. For our e-mail classifier, benign and phishing emails incorporating textual content written by massive language fashions (LLMs) may trigger knowledge drift by lowering the typical variety of typos within the textual content (Determine 1, Panel B).
Label drift refers to modifications within the distribution of outcomes. For classifier fashions, label drift signifies the proportion of observations in every class has modified. Label drift can negatively affect classification fashions which are delicate to class imbalances. For the phishing e-mail classifier, a change within the proportion of emails which are phishing makes an attempt could be an instance of label drift (Determine 1, Panel C).
{kind=link}
Determine 1: Three major varieties of drift: knowledge drift, idea drift, and label drift illustrated utilizing the instance of a phishing e-mail classifier.
Some of these drift typically co-occur. For instance, a change in consumer conduct may have an effect on the general distribution of a function (function drift) in addition to the connection between that function and the result class (idea drift). As a result of these totally different drift sorts can have various impacts on production-level ML fashions, it is very important perceive what varieties of drift are occurring.
How Can We Detect Drift?
Whereas drift may cause mannequin efficiency degradation, there are strategies to establish and scale back degradation. One step to safe ML fashions towards drift is to implement drift detectors. These strategies establish when the working setting has modified and challenge alerts, enabling well timed mannequin retraining. Drift detection has been famous as a CISA know-how of curiosity and is listed as a required step within the lifecycle of AI techniques within the DoD handbook Operational Check and Analysis and Stay Fireplace Check and Analysis of Synthetic Intelligence-Enabled and Autonomous Techniques.
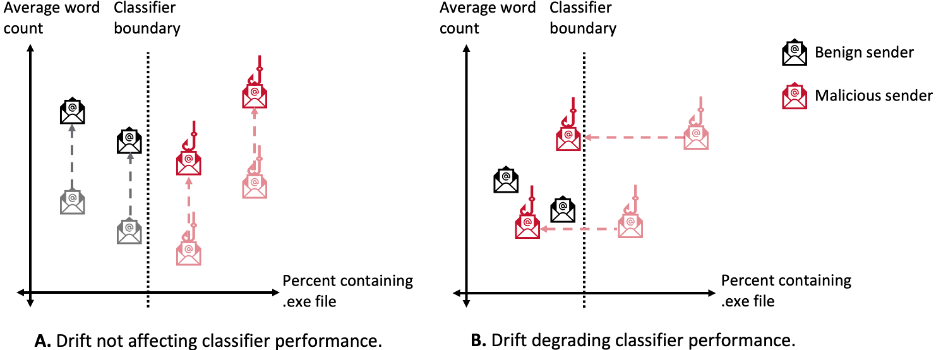
Drift may be detected in two methods: (1) by monitoring for modifications in efficiency metrics or (2) by monitoring for modifications in knowledge distributions. Modifications in efficiency metrics, akin to accuracy or root imply squared error (RMSE), point out a discrepancy between coaching and deployment environments. Monitoring for modifications in ML mannequin efficiency metrics straight is interesting as a result of mannequin efficiency is what an analyst goals to optimize; drift that doesn’t negatively affect mannequin efficiency may be safely ignored. Determine 2 illustrates drift that doesn’t have an effect on the classifier (Panel A) and drift that degrades classifier efficiency (Panel B).
In lots of purposes, labeled manufacturing knowledge is just not accessible. In these circumstances, drift can solely be detected by monitoring for modifications within the distributions of the options. A easy technique of monitoring for drift in unlabeled knowledge is to observe every function individually. A big distributional change in a function can point out the manufacturing setting has drifted from the coaching setting.
A limitation of this strategy, notably with high-dimensional cyber knowledge, is that drift in uninformative options that doesn’t negatively affect ML mannequin efficiency could nonetheless set off an alert.
To keep away from these false alarms, drift detection strategies have been developed to particularly goal drift that impacts mannequin predictions. One such technique, a method referred to as margin density drift detection (MD3), defines a margin round a classifier’s choice boundary. The margin corresponds to a area the place the classifier has low confidence in its class predictions. By establishing a baseline % of observations falling inside the margin, a drift alarm may be triggered when a big proportion of observations drift in or out of this margin. In different phrases, MD3 triggers an alert when the mannequin encounters an unexpectedly excessive variety of circumstances which are troublesome (or straightforward) to categorise. Because the choice boundary determines how a classifier assigns labels, MD3 solely alerts an alarm for drift that might have an effect on mannequin predictions.
{kind=link}
Determine 2: Drift impacts classifier efficiency provided that it shifts observations throughout the classifier boundary.
Case Examine: DNS Information Exfiltration
On the SEI, we carried out a case research utilizing a DNS exfiltration dataset. We chosen DNS knowledge exfiltration as a result of it offers a sensible cybersecurity use-case for ML-based detection with an adversary trying to evade detection.
Information exfiltration poses a critical menace for organizations coping with confidential or proprietary info. For instance, in 2024, hackers executed a large-scale ransomware assault on Change Healthcare, a subsidiary of UnitedHealth Group. The assault compromised delicate knowledge—together with names, Social Safety numbers, and well being info—of greater than 129 million people, with a price to UnitedHealth Group of over $2.8 billion. Different notable current knowledge leaks embrace the software program firm Crimson Hat’s inner GitLab, the U.S. federal courts case administration and digital case submitting system, and TransUnion’s Salesforce account.
Whereas there are numerous strategies of knowledge exfiltration accessible to adversaries, an often-overlooked route is by way of DNS. DNS, or Area Title System, is the protocol used to translate human-readable domains into IP addresses. Sometimes, DNS requests are handed from a consumer’s machine by a firewall to DNS servers, which return a vacation spot IP handle. Adversaries who’ve established a foothold on a consumer’s machine can reap the benefits of this course of to covertly encode knowledge within the DNS request and get better this knowledge on a DNS server they management. Whereas identified malicious servers may be simply blocked by a firewall, it’s troublesome to pre-emptively block novel ones.
ML classifiers can defend from knowledge exfiltration over DNS to novel DNS servers. Such a classifier may be skilled on labeled DNS requests to establish traits predictive of knowledge exfiltration. To exfiltrate knowledge over DNS, adversaries encode knowledge in DNS requests despatched to adversary-controlled domains. To maximise the quantity of knowledge despatched, these requests typically are lengthy and include a number of ranges of domains, akin to “123abc.3xf2z.instance.com.” Due to the distinctive traits of malicious DNS site visitors, options akin to request size and variety of subdomains can be utilized to coach a classifier. Whereas a classifier skilled on these options could carry out effectively at first, what occurs when an adversary discovers their exfiltration makes an attempt are being thwarted?
Simulation Description
The dataset comprises benign DNS requests in addition to malicious DNS requests exfiltrating knowledge. Of the malicious requests, some have been unobfuscated—the DNS requests have been created with none try to cover the malicious exercise—and the remaining have been obfuscated. The obfuscation strategies embrace shortening the DNS request size, lowering the entropy of the DNS request, and growing the time between subsequent requests. We sampled from these knowledge to create two datasets: a pre-drift dataset containing labeled benign and unobfuscated exfiltration DNS requests and a post-drift dataset containing benign and obfuscated exfiltration DNS requests. We skilled a random forest classifier on a subset of the pre-drift dataset and calibrated an MD3 detector. We then sampled the rest of the pre-drift dataset, simulating 40 days of pre-drift knowledge, and sampled from the post-drift dataset, simulating 40 days of post-drift knowledge.
Outcomes
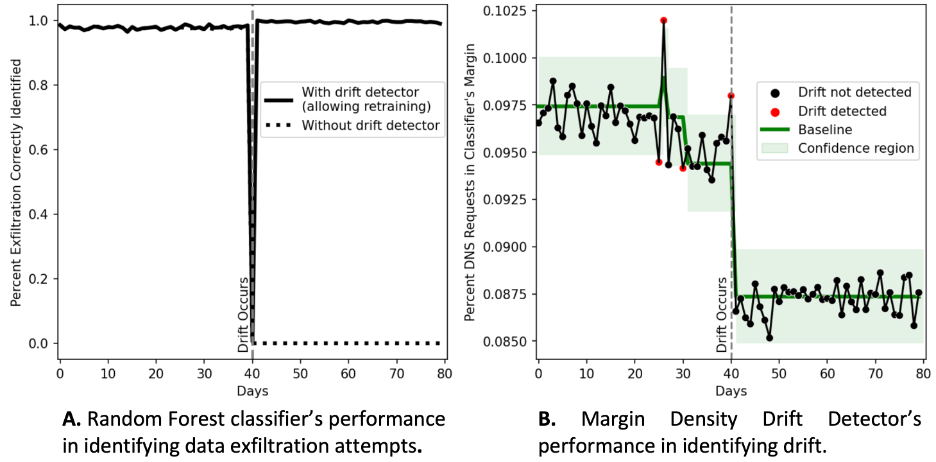
We first checked the random forest classifier’s efficiency on the pre-drift knowledge. It carried out very effectively, precisely detecting almost all exfiltration makes an attempt (the dashed line in Determine 3, Panel A earlier than day 40).
Subsequent, we checked the classifier’s efficiency on the post-drift knowledge. The efficiency plummeted: exfiltration makes an attempt have been now not detectable (dashed line Determine 3, Panel A after day 40).
We applied an MD3 detector to check whether or not it may correctly detect the drift. The detector triggered a small variety of false positives earlier than drift started (the crimson factors earlier than day 40 in Determine 3, Panel B) and instantly detected drift as soon as it occurred (the crimson level at day 40 in Determine 3, Panel B).
The efficiency of the exfiltration detector different tremendously when implementing a drift detector with retraining. Following the onset and detection of drift, the classifier was retrained and regained its excessive efficiency on the post-drift knowledge (see the stable line in Determine 3, Panel A, after day 40).
{kind=link}
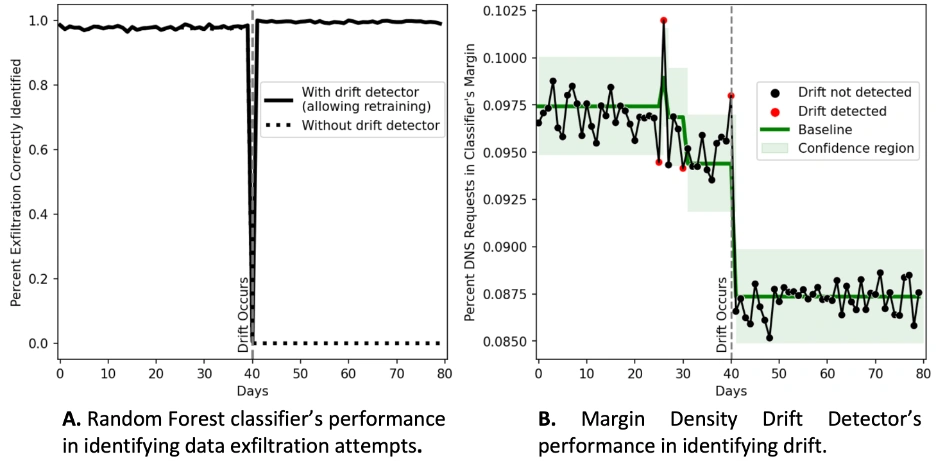
Determine 3: Case research outcomes demonstrating drift detection with retraining is efficient at sustaining classifier efficiency within the presence of drift.
This case research demonstrates that drift detectors accompanied with mannequin retraining may be an efficient technique to preserve well-performing ML fashions in dynamic environments.
Deploying ML Options within the Presence of Change
ML-powered applied sciences are invaluable within the protection towards cyber attackers. By studying patterns, ML fashions will help defend towards novel attackers. Nevertheless, ML cyber defenses are prone to adversaries who modify their behaviors to imitate benign customers.
One technique to safe ML fashions towards drift is thru deployment monitoring. When drift is detected, an ML mannequin may be retrained on the brand new knowledge, updating the discovered patterns and enhancing mannequin efficiency. We discovered that MD3 is an efficient drift detection approach for cyber knowledge as a result of it may be adopted for a variety of ML fashions, doesn’t require labeled knowledge, and isn’t useful resource intensive.