

{kind=link}
Clients new to Amazon OpenSearch Service usually ask what number of shards their indexes want. An index is a set of shards, and an index’s shard depend can have an effect on each indexing and search request effectivity. OpenSearch Service can soak up massive quantities of information, break up it into smaller models referred to as shards, and distribute these shards throughout a dynamically altering set of situations.
On this submit, we offer some sensible steerage for figuring out the best shard depend in your use case.
Shards overview
A search engine has two jobs: create an index from a set of paperwork, and search that index to compute the best-matching paperwork. In case your index is sufficiently small, a single partition on a single machine can retailer that index. For bigger doc units, in circumstances the place a single machine isn’t massive sufficient to carry the index, or in circumstances the place a single machine can’t compute your search outcomes successfully, the index will be break up into partitions. These partitions are referred to as shards in OpenSearch Service. Every doc is routed to a shard that’s calculated, by default, by utilizing a hash of that doc’s ID.
A shard is each a unit of storage and a unit of computation. OpenSearch Service distributes shards throughout nodes in your cluster to parallelize index storage and processing. In the event you add extra nodes to an OpenSearch Service area, it robotically rebalances the shards by shifting them between the nodes. The next determine illustrates this course of.
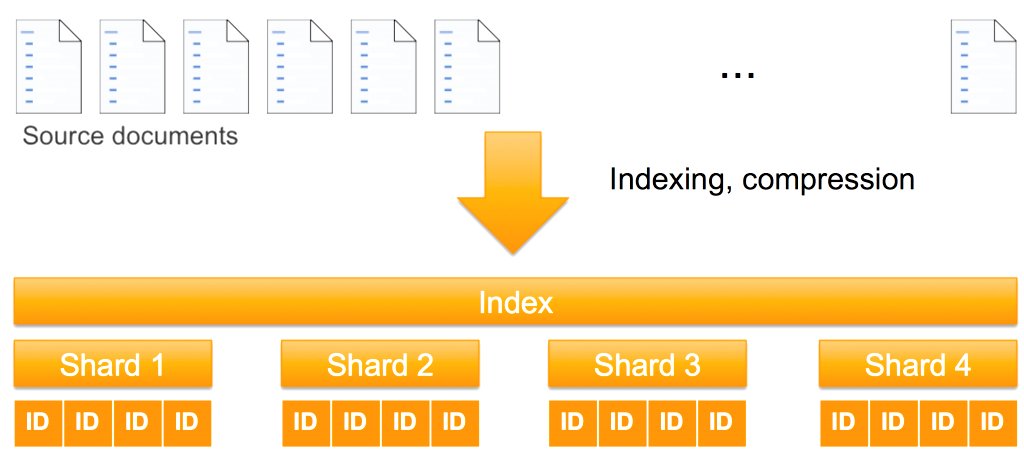
As storage, major shards are distinct from each other. The doc set in a single shard doesn’t overlap the doc set in different shards. This strategy makes shards unbiased for storage.
As computational models, shards are additionally distinct from each other. Every shard is an occasion of an Apache Lucene index that computes outcomes on the paperwork it holds. As a result of all of the shards comprise the index, they need to perform collectively to course of every question and replace request for that index. To course of a question, OpenSearch Service routes the question to an information node for a major or reproduction shard. Every node computes its response domestically and the shard responses get aggregated for a closing response. To course of a write request (a doc ingestion or an replace to an current doc), OpenSearch Service routes the request to the suitable shards—major then reproduction. As a result of most writes are bulk requests, all shards of an index are usually used.
The 2 several types of shards
There are two sorts of shards in OpenSearch Service—major and reproduction shards. In an OpenSearch index configuration, the first shard depend serves to partition information and the reproduction depend is the variety of full copies of the first shards. For instance, in case you configure your index with 5 major shards and 1 reproduction, you’ll have a complete of 10 shards: 5 major shards and 5 reproduction shards.
The first shard receives writes first. The first shard passes paperwork to the reproduction shards for indexing by default. OpenSearch Service’s O-series situations use section replication. By default, OpenSearch Service waits for acknowledgment from reproduction shards earlier than confirming a profitable write operation to the shopper. Major and reproduction shards present redundant information storage, enhancing cluster resilience in opposition to node failures. Within the following instance, the OpenSearch Service area has three information nodes. There are two indexes, inexperienced (darker) and blue (lighter), every of which has three shards. The first for every shard is printed in crimson. Every shard additionally has a single reproduction, proven with no define.
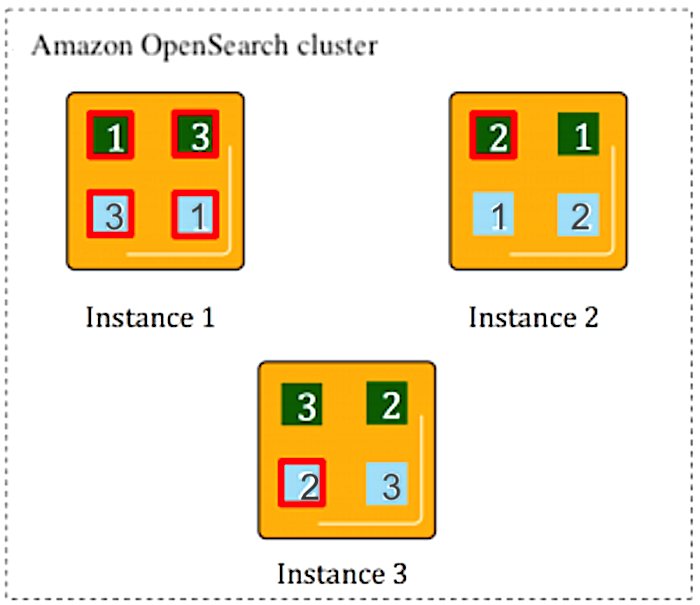
OpenSearch Service maps shards to nodes primarily based on quite a few guidelines. Probably the most primary rule is that major and reproduction shards are by no means put onto the identical node. If an information node fails, OpenSearch Service robotically creates one other information node and re-replicates shards from surviving nodes and redistributes them throughout the cluster. If major shards fail, reproduction shards are promoted to major to stop information loss and supply steady indexing and search operations.
So what number of shards? Give attention to storage first
There are three sorts of workloads that OpenSearch customers usually preserve: seek for purposes, log analytics, and as a vector database. Search workloads are read-heavy and latency delicate. They’re usually tied to an software to reinforce search functionality and efficiency. A standard sample is to index the information in relational databases to present customers extra filtering capabilities and supply environment friendly full textual content search.
Log workloads are write-heavy and obtain information constantly from purposes and community gadgets. Sometimes, that information is put right into a altering set of indexes, primarily based on an indexing time interval like day by day or month-to-month relying on the use case. As an alternative of indexing primarily based on time interval, you should use rollover insurance policies primarily based on index dimension or doc depend to ensure shard sizing greatest practices are adopted.
Vector database workloads use the OpenSearch Service k-Nearest Neighbor (k-NN) plugin to index vectors from an embedding pipeline. This permits semantic search, which measures relevance utilizing the that means of phrases quite than precisely matching the phrases. The embedding mannequin from the pipeline maps multimodal information right into a vector with probably 1000’s of dimensions. OpenSearch Service searches throughout vectors to supply search outcomes.
To find out the optimum variety of shards in your workload, begin together with your index storage necessities. Though storage necessities can differ broadly, a common guideline is to make use of 1:1.25 utilizing the supply information dimension to estimate utilization. Additionally, compression algorithms default to efficiency, however may also be adjusted to scale back dimension. In relation to shard sizes, take into account the next primarily based on the workload:
- Search – Divide your complete storage requirement by 30 GB.
- If search latency is excessive, use a smaller shard dimension (as little as 10GB), rising the shard depend and parallelism for question processing.
- Growing the shard depend reduces the quantity of labor at every shard (they’ve fewer paperwork to course of), but in addition will increase the quantity of networking for distributing the question and gathering the response. To stability these competing issues, study your common hit depend. In case your hit depend is excessive, use smaller shards. In case your hit depend is low, use bigger shards.
- Logs – Divide the storage requirement in your desired time interval by 50 GB.
- If utilizing an ISM coverage with rollover, take into account setting the min_size parameter to 50 GB.
- Growing the shard depend for logs workloads equally improves parallelism. Nevertheless, most queries for logs workloads have a small hit depend, so question processing is gentle. Logs workloads work properly with bigger shard sizes, however shard smaller in case your question workload is heavier.
- Vector – Divide your complete storage requirement by 50 GB.
- Decreasing shard dimension (as little as 10GB) can enhance search latency when your vector queries are hybrid with a heavy lexical part. Conversely, rising shard dimension (as excessive as 75GB) can enhance latency when your queries are pure vector queries.
- OpenSearch gives different optimization strategies for vector databases, together with vector quantization and disk-based search.
- Ok-NN queries behave like extremely filtered search queries, with low hit counts. Subsequently, bigger shards are inclined to work properly. Be ready to shard smaller when your queries are heavier.
Don’t be afraid of utilizing a single shard
In case your index comprises lower than the suggested shard dimension (30 GB for search and 50 GB in any other case), we suggest that you just use a single major shard. Though it’s tempting so as to add extra shards pondering it’ll enhance efficiency, this strategy can truly be counterproductive for smaller datasets due to the added networking. Every shard you add to an index distributes the processing of requests for that index throughout a further node. Efficiency can lower as a result of there’s overhead for distributed operations to separate and mix outcomes throughout nodes when a single node can do it sufficiently.
Set the shard depend
If you create an OpenSearch index, you set the first and reproduction counts for that index. As a result of you may’t dynamically change the first shard depend of an current index, it’s important to make this vital configuration determination earlier than indexing your first doc.
You set the shard depend utilizing the OpenSearch create index API. For instance (present your OpenSearch Service area endpoint URL and index title):
When you’ve got a single index workload, you solely have to do that one time, once you create your index for the primary time. When you’ve got a rolling index workload, you create a brand new index repeatedly. Use the index template API to automate making use of settings to all new indexes whose title matches the template. The next instance units the shard depend for any index whose title has the prefix logs (present your OpenSearch service endpoint area URL and index template title):
Conclusion
This submit outlined primary shard sizing greatest practices, however further components would possibly affect the best index configuration you select to implement in your OpenSearch Service area.
For extra details about sharding, check with Optimize OpenSearch index shard sizes or Shard technique. Each sources may also help you higher fine-tune your OpenSearch Service area to optimize its out there compute sources.
Concerning the authors
 Tom Burns is a Senior Cloud Assist Engineer at AWS and is predicated within the NYC space. He’s a subject knowledgeable in Amazon OpenSearch Service and engages with clients for vital occasion troubleshooting and enhancing the supportability of the service. Outdoors of labor, he enjoys taking part in along with his cats, taking part in board video games with buddies, and taking part in aggressive video games on-line.
Tom Burns is a Senior Cloud Assist Engineer at AWS and is predicated within the NYC space. He’s a subject knowledgeable in Amazon OpenSearch Service and engages with clients for vital occasion troubleshooting and enhancing the supportability of the service. Outdoors of labor, he enjoys taking part in along with his cats, taking part in board video games with buddies, and taking part in aggressive video games on-line.
 Ron Miller is a Options Architect primarily based out of NYC, supporting transportation and logistics clients. Ron works intently with AWS’s Information & Analytics specialist group to advertise and assist OpenSearch. On the weekend, Ron is a shade tree mechanic and trains to finish triathlons.
Ron Miller is a Options Architect primarily based out of NYC, supporting transportation and logistics clients. Ron works intently with AWS’s Information & Analytics specialist group to advertise and assist OpenSearch. On the weekend, Ron is a shade tree mechanic and trains to finish triathlons.