

{kind=link}
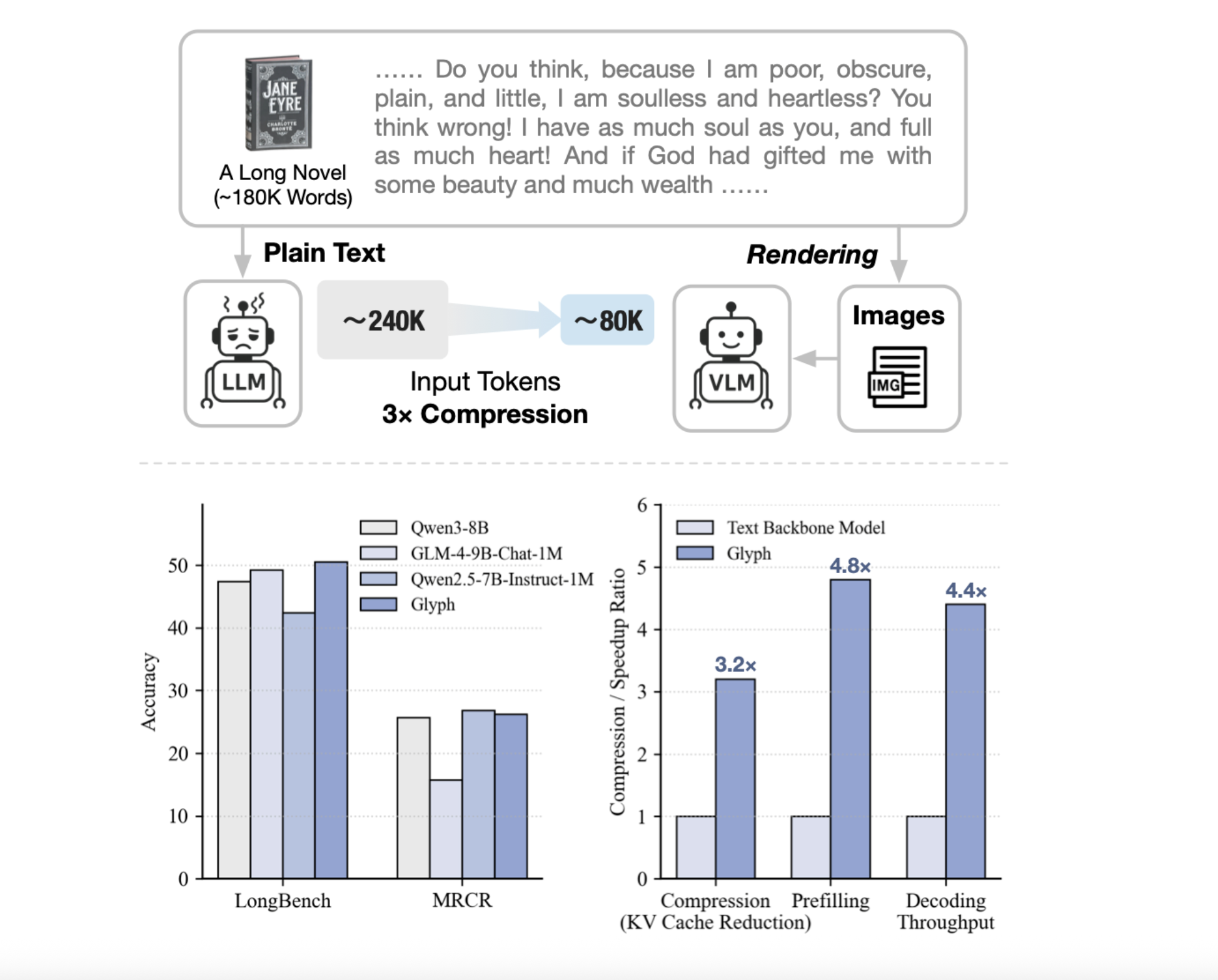
Can we render lengthy texts as photographs and use a VLM to attain 3–4× token compression, preserving accuracy whereas scaling a 128K context towards 1M-token workloads? A crew of researchers from Zhipu AI launch Glyph, an AI framework for scaling the context size by visual-text compression. It renders lengthy textual sequences into photographs and processes them utilizing imaginative and prescient–language fashions. The system renders extremely lengthy textual content into web page photographs, then a imaginative and prescient language mannequin, VLM, processes these pages finish to finish. Every visible token encodes many characters, so the efficient token sequence shortens, whereas semantics are preserved. Glyph can obtain 3-4x token compression on lengthy textual content sequences with out efficiency degradation, enabling important good points in reminiscence effectivity, coaching throughput, and inference pace.
Why Glyph?
Typical strategies develop positional encodings or modify consideration, compute and reminiscence nonetheless scale with token rely. Retrieval trims inputs, however dangers lacking proof and provides latency. Glyph adjustments the illustration, it converts textual content to pictures and shifts burden to a VLM that already learns OCR, format, and reasoning. This will increase info density per token, so a set token funds covers extra unique context. Underneath excessive compression, the analysis crew present a 128K context VLM can tackle duties that originate from 1M token degree textual content.
System design and coaching
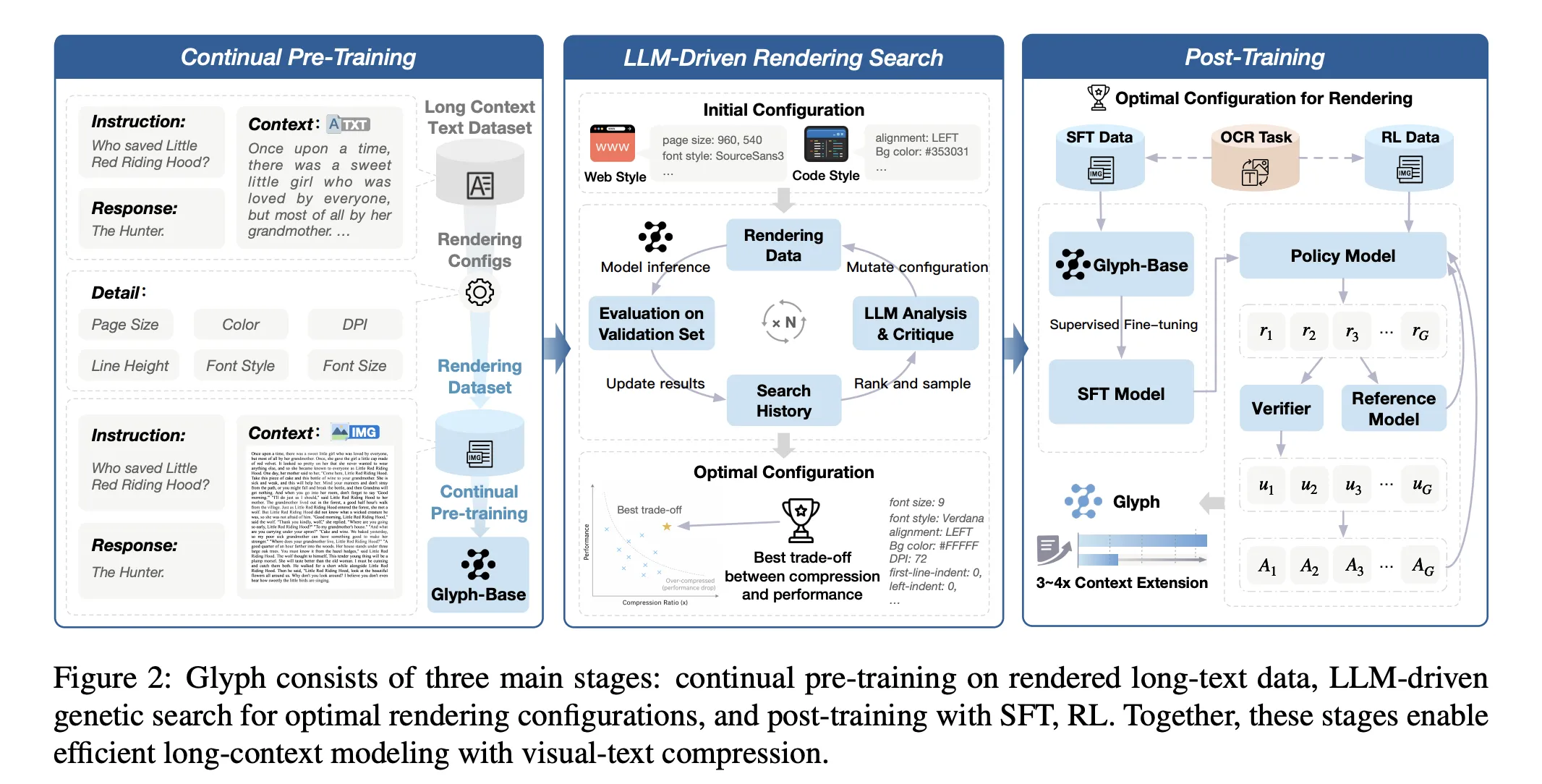
The tactic has three phases, continuous pre coaching, LLM pushed rendering search, and publish coaching. Continuous pre coaching exposes the VLM to massive corpora of rendered lengthy textual content with various typography and kinds. The target aligns visible and textual representations, and transfers lengthy context expertise from textual content tokens to visible tokens. The rendering search is a genetic loop pushed by an LLM. It mutates web page measurement, dpi, font household, font measurement, line peak, alignment, indent, and spacing. It evaluates candidates on a validation set to optimize accuracy and compression collectively. Publish coaching makes use of supervised superb tuning and reinforcement studying with Group Relative Coverage Optimization, plus an auxiliary OCR alignment activity. The OCR loss improves character constancy when fonts are small and spacing is tight.
Outcomes, efficiency and effectivity…
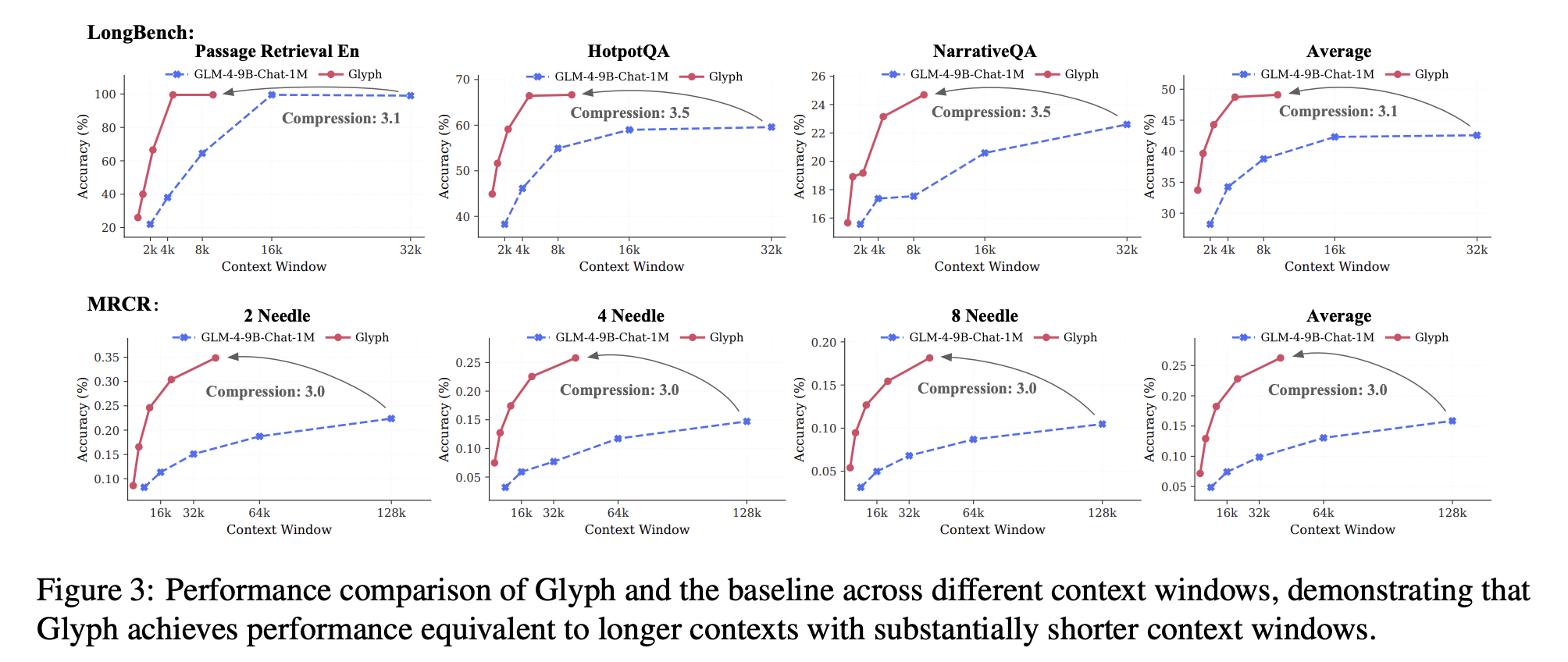
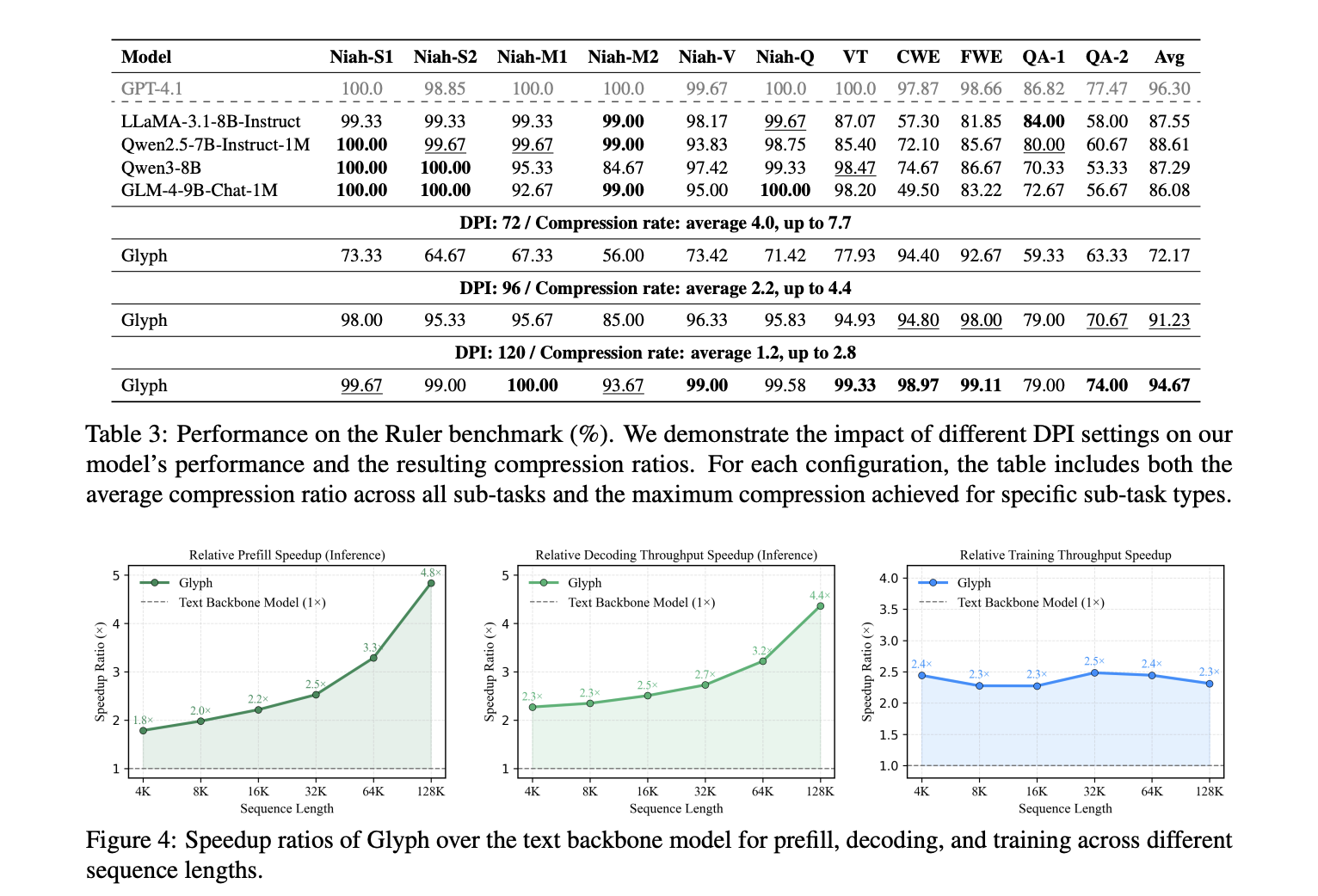
LongBench and MRCR set up accuracy and compression underneath lengthy dialogue histories and doc duties. The mannequin achieves a median efficient compression ratio about 3.3 on LongBench, with some duties close to 5, and about 3.0 on MRCR. These good points scale with longer inputs, since each visible token carries extra characters. Reported speedups versus the textual content spine at 128K inputs are about 4.8 instances for prefill, about 4.4 instances for decoding, and about 2 instances for supervised superb tuning throughput. The Ruler benchmark confirms that greater dpi at inference time improves scores, since crisper glyphs assist OCR and format parsing. The analysis crew studies dpi 72 with common compression 4.0 and most 7.7 on particular sub duties, dpi 96 with common compression 2.2 and most 4.4, and dpi 120 with common 1.2 and most 2.8. The 7.7 most belongs to Ruler, to not MRCR.
So, what? Functions
Glyph advantages multimodal doc understanding. Coaching on rendered pages improves efficiency on MMLongBench Doc relative to a base visible mannequin. This means that the rendering goal is a helpful pretext for actual doc duties that embrace figures and format. The principle failure mode is sensitivity to aggressive typography. Very small fonts and tight spacing degrade character accuracy, particularly for uncommon alphanumeric strings. The analysis crew exclude the UUID subtask on Ruler. The method assumes server facet rendering and a VLM with robust OCR and format priors.
Key Takeaways
- Glyph renders lengthy textual content into photographs, then a imaginative and prescient language mannequin processes these pages. This reframes long-context modeling as a multimodal downside and preserves semantics whereas lowering tokens.
- The analysis crew studies token compression is 3 to 4 instances with accuracy similar to robust 8B textual content baselines on long-context benchmarks.
- Prefill speedup is about 4.8 instances, decoding speedup is about 4.4 instances, and supervised superb tuning throughput is about 2 instances, measured at 128K inputs.
- The system makes use of continuous pretraining on rendered pages, an LLM pushed genetic search over rendering parameters, then supervised superb tuning and reinforcement studying with GRPO, plus an OCR alignment goal.
- Evaluations embrace LongBench, MRCR, and Ruler, with an excessive case displaying a 128K context VLM addressing 1M token degree duties. Code and mannequin card are public on GitHub and Hugging Face.
Glyph treats lengthy context scaling as visible textual content compression, it renders lengthy sequences into photographs and lets a VLM course of them, lowering tokens whereas preserving semantics. The analysis crew claims 3 to 4 instances token compression with accuracy similar to Qwen3 8B baselines, about 4 instances quicker prefilling and decoding, and about 2 instances quicker SFT throughput. The pipeline is disciplined, continuous pre coaching on rendered pages, an LLM genetic rendering search over typography, then publish coaching. The method is pragmatic for million token workloads underneath excessive compression, but it depends upon OCR and typography decisions, which stay knobs. General, visible textual content compression provides a concrete path to scale lengthy context whereas controlling compute and reminiscence.
Try the Paper, Weights and Repo. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.