

Environment friendly real-time synchronization of knowledge inside information lakes current challenges. Any information inaccuracies or latency points can considerably compromise analytical insights and subsequent enterprise methods. Organizations more and more require synchronized information in close to real-time to extract actionable intelligence and reply promptly to evolving market dynamics. Moreover, scalability stays a priority for information lake implementations, which should accommodate increasing volumes of streaming information and keep optimum efficiency with out incurring excessive operational prices.
Schema evolution is the method of modifying the construction (schema) of an information desk to accommodate modifications within the information over time, similar to including or eradicating columns, with out disrupting ongoing operations or requiring an entire information rewrite. Schema evolution is significant in streaming information environments for a number of causes. Not like batch processing, streaming pipelines function constantly, ingesting information in actual time from sources which are actively serving manufacturing purposes. Supply methods naturally evolve over time as companies add new options, refine information fashions, or reply to altering necessities. With out correct schema evolution capabilities, even minor modifications to supply schemas can power streaming pipeline shutdowns, requiring builders to manually reconcile schema variations and rebuild tables.
Such disruptions scale back the core worth proposition of streaming architectures—steady, low-latency information processing. Organizations can keep uninterrupted information flows and maintain supply methods evolving independently through the use of the seamless schema evolution supplied by Apache Iceberg. This reduces operational friction and maintains the supply of real-time analytics and purposes at the same time as underlying information constructions change.
Apache Iceberg is an open desk format, delivering important capabilities for streaming workloads, together with strong schema evolution help. This essential function allows desk schemas to adapt dynamically as supply database constructions evolve, sustaining operational continuity. Consequently, when database columns endure additions, removals, or modifications, the information lake accommodates these modifications seamlessly with out requiring handbook intervention or risking information inconsistencies.
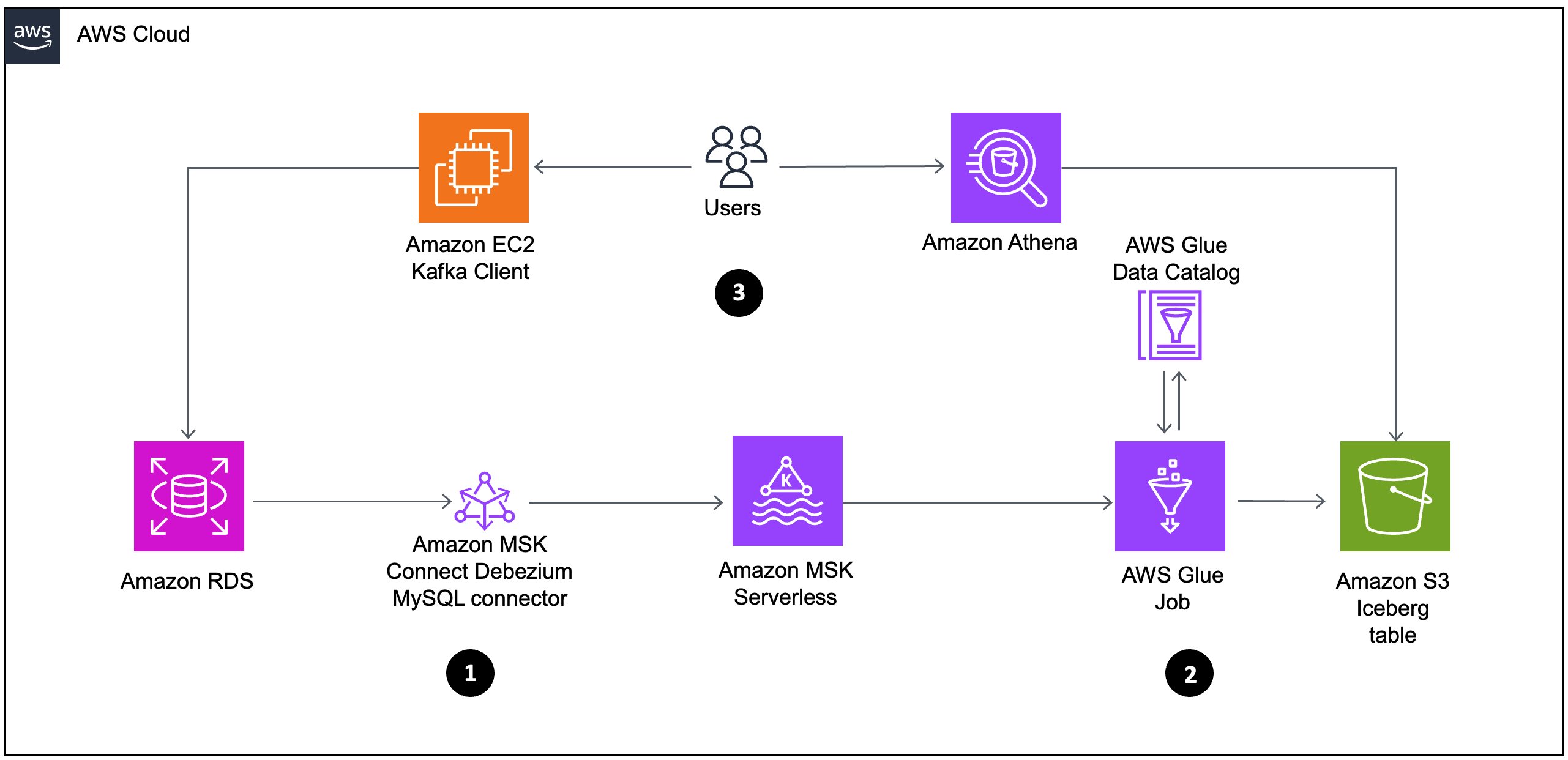
Our complete resolution showcases an end-to-end real-time CDC pipeline that allows speedy processing of knowledge modifications from Amazon Relational Database Service (Amazon RDS) for MySQL, streaming altered information on to AWS Glue streaming jobs utilizing Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless. These jobs frequently course of incoming modifications and replace Iceberg tables on Amazon Easy Storage Service (Amazon S3) in order that the information lake displays the present state of the operational database atmosphere in actual time. By utilizing Apache Iceberg’s complete schema evolution help, our ETL pipeline mechanically adapts to database schema modifications, offering information lake consistency and currentness with out handbook intervention. This strategy combines full course of management with instantaneous analytics on operational information, eliminating conventional latency, and future-proofs the answer to handle evolving organizational information wants. The structure’s inherent flexibility facilitates adaptation to various use circumstances requiring speedy information insights.
Resolution overview
To successfully deal with streaming challenges, we suggest an structure utilizing Amazon MSK Serverless, a complete managed Apache Kafka service that autonomously provisions and scales computational and storage assets. This resolution gives a frictionless mechanism for ingesting and processing streaming information with out the complexity of capability administration. Our implementation makes use of Amazon MSK Join with the Debezium MySQL connector to seize and stream database modifications in actual time. Somewhat than using conventional batch processing methodologies, we implement an AWS Glue streaming job that immediately consumes information from Kafka subjects, processes CDC occasions as they happen, and writes remodeled information to Apache Iceberg tables on Amazon S3.
The workflow consists of the next:
- Knowledge flows from Amazon RDS by Amazon MSK Join utilizing the Debezium MySQL connector to Amazon MSK Serverless. This represents a CDC pipeline that captures database modifications from the relational database and streams them to Kafka.
- From Amazon MSK Serverless, the information then strikes to AWS Glue job, which processes the information and shops it in Amazon S3 as Iceberg tables. The AWS Glue job interacts with the AWS Glue Knowledge Catalog to keep up metadata in regards to the datasets.
- Analyze the information utilizing the serverless interactive question service Amazon Athena, which can be utilized to question the iceberg desk created in Knowledge Catalog. This enables for interactive information evaluation with out managing infrastructure.
The next diagram illustrates the structure that we implement by this publish. Every quantity corresponds to the previous listing and exhibits main elements that you just implement.
Conditions
Earlier than getting began, be sure you have the next:
- An lively AWS account with billing enabled
- An AWS Identification and Entry Administration (IAM) person with particular permissions to create and handle assets, similar to a digital personal cloud (VPC), subnet, safety group, IAM roles, NAT gateway, web gateway, Amazon Elastic Compute Cloud (Amazon EC2) consumer, MSK Serverless, MSK Connector and its plugin AWS Glue job, and S3 buckets.
- Ample VPC capability in your chosen AWS Area.
For this publish, we create the answer assets within the US East (N. Virginia) – us-east-1 Area utilizing AWS CloudFormation templates. Within the following sections, we present you how you can configure your assets and implement the answer.
Configuring CDC and processing utilizing AWS CloudFormation
On this publish, you utilize the CloudFormation template vpc-msk-mskconnect-rds-client-gluejob.yaml. This template units up the streaming CDC pipeline assets similar to a VPC, subnet, safety group, IAM roles, NAT, web gateway, EC2 consumer, MSK Serverless, MSK Join, Amazon RDS, S3 buckets, and AWS Glue job.
To create the answer assets for the CDC pipeline, full the next steps:
- Launch the stack
vpc-msk-mskconnect-rds-client-gluejob.yamlutilizing the CloudFormation template:
- Present the parameter values as listed within the following desk.
A B C 1 Parameters Description Pattern worth 2 EnvironmentName An atmosphere identify that’s prefixed to useful resource names. msk-iceberg-cdc-pipeline 3 DatabasePassword Database admin account password. **** 4 InstanceType MSK consumer EC2 occasion kind. t2.micro 5 LatestAmiId Newest AMI ID of Amazon Linux 3 for ec2 occasion. You should utilize the default worth. /aws/service/ami-amazon-linux-latest/al2023-ami-kernel-default-x86_64 6 VpcCIDR IP vary (CIDR notation) for this VPC. 10.192.0.0/16 7 PublicSubnet1CIDR IP vary (CIDR notation) for the general public subnet within the first Availability Zone. 10.192.10.0/24 8 PublicSubnet2CIDR IP vary (CIDR notation) for the general public subnet within the second Availability Zone. 10.192.11.0/24 9 PrivateSubnet1CIDR IP vary (CIDR notation) for the personal subnet within the first Availability Zone. 10.192.20.0/24 10 PrivateSubnet2CIDR IP vary (CIDR notation) for the personal subnet within the second Availability Zone. 10.192.21.0/24 11 NumberOfWorkers Variety of employees for AWS Glue streaming job. 3 12 GlueWorkerType Employee kind for AWS Glue streaming job. For instance, G.1X. G.1X 13 GlueDatabaseName Identify of the AWS Glue Knowledge Catalog database. glue_cdc_blogdb 14 GlueTableName Identify of the AWS Glue Knowledge Catalog desk. iceberg_cdc_tbl
The stack creation course of can take roughly 25 minutes to finish. You possibly can verify the Outputs tab for the stack after the stack is created, as proven within the following screenshot.
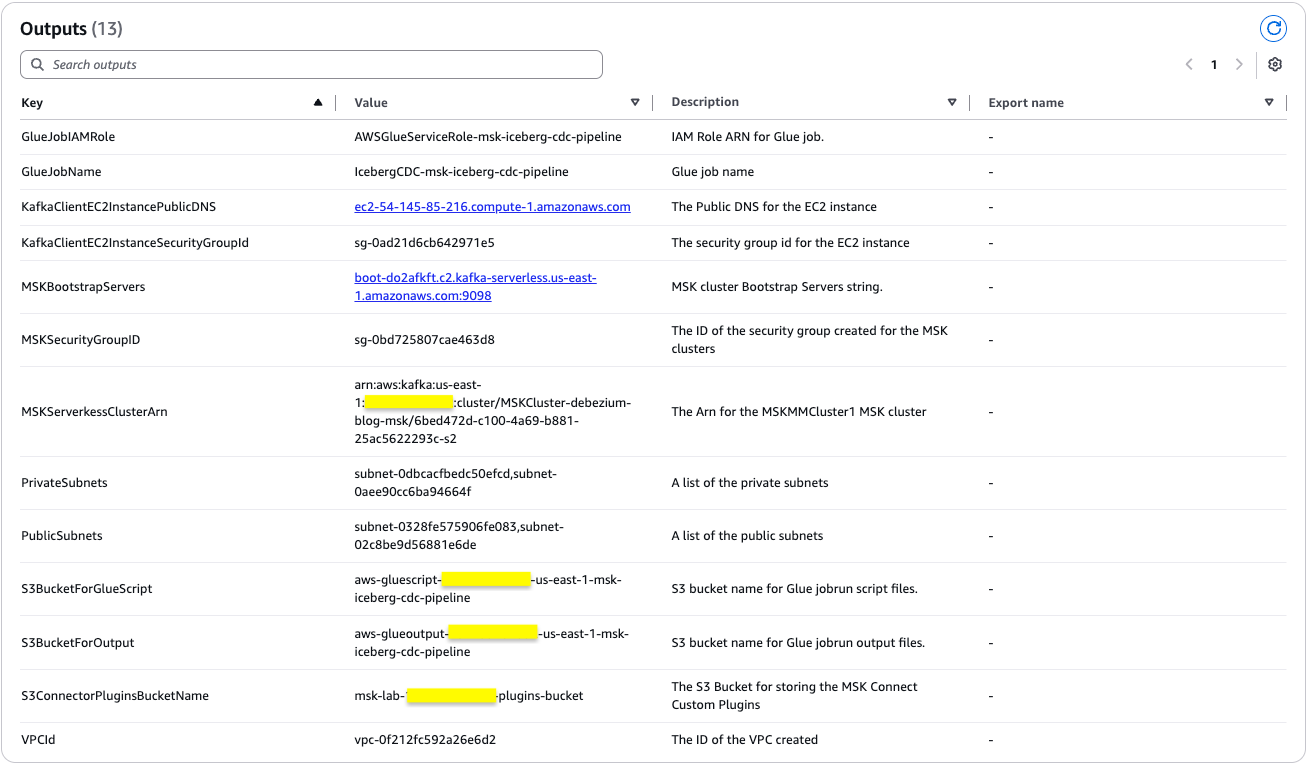
Following the profitable deployment of the CloudFormation stack, you now have a completely operational Amazon RDS database atmosphere. The database occasion comprises the salesdb database with the buyer desk populated with 30 information information.
These information have been streamed to the Kafka subject by the Debezium MySQL connector implementation, establishing a dependable CDC pipeline. With this basis in place, proceed to the following section of the information structure: close to real-time information processing utilizing the AWS Glue streaming job.
Run the AWS Glue streaming job
To switch the information load from the Kafka subject (created by the Debezium MySQL connector for database desk buyer) to the Iceberg desk, run the AWS Glue streaming job configured by the CloudFormation setup. This course of will migrate all present buyer information from the supply database desk to the Iceberg desk. Full the next steps:
- On the CloudFormation console, select the stack vpc-msk-mskconnect-rds-client-gluejob.yaml
- On the Outputs tab, retrieve the identify of the AWS Glue streaming job from the GlueJobName row. Within the following screenshot, the identify is IcebergCDC-msk-iceberg-cdc-pipeline.

- On the AWS Glue console, select ETL jobs within the navigation pane.
- Seek for the AWS Glue job named IcebergCDC-msk-iceberg-cdc-pipeline.
- Select the job identify to open its particulars web page.
- Select Run to start out the job. On the Runs tab, verify if the job ran with out failure.


You have to wait roughly 2 minutes for the job to course of earlier than persevering with. This pause permits the jobrun to totally course of information from the Kafka subject (preliminary load) and create the Iceberg desk.
Question the Iceberg desk utilizing Athena
After the AWS Glue streaming job has efficiently began and the Iceberg desk has been created within the Knowledge Catalog, comply with these steps to validate the information utilizing Athena:
- On the Athena console, navigate to the question editor.
- Select the Knowledge Catalog as the information supply.
- Select the database glue_cdc_blogdb.
- To validate the information, enter the next question to preview the information and discover the entire rely:
The next screenshot exhibits the output of the instance question.


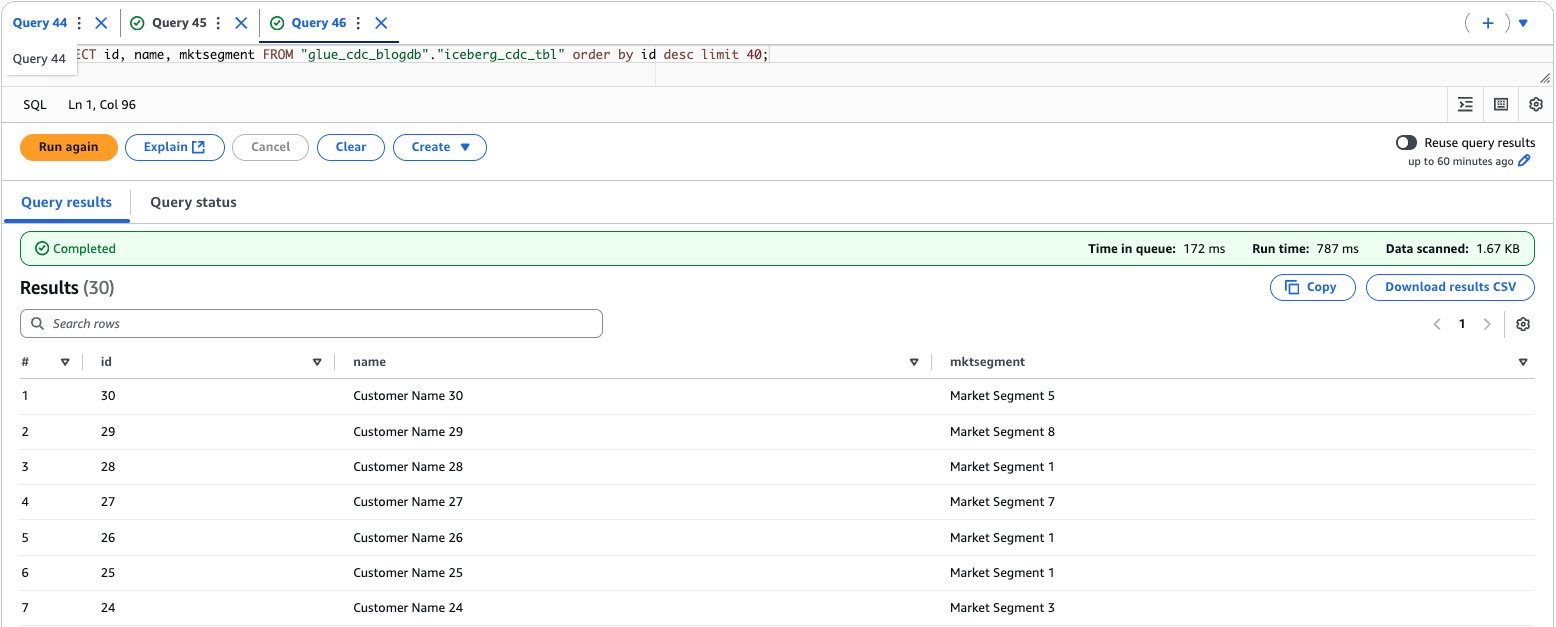
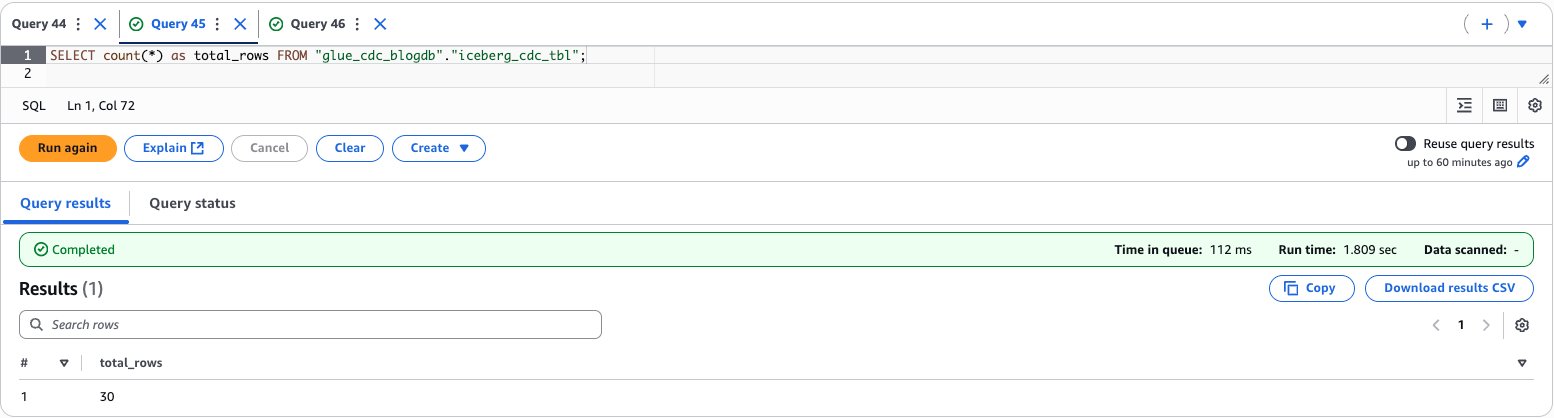
After performing the previous steps, you’ve established an entire close to real-time information processing pipeline by operating an AWS Glue streaming job that transfers information from Kafka subjects to an Apache Iceberg desk, then verified the profitable information migration by querying the outcomes by Amazon Athena.
Add incremental (CDC) information for additional processing
Now that you just’ve efficiently accomplished the preliminary full information load, it’s time to give attention to the dynamic elements of the information pipeline. On this part, we discover how the system handles ongoing information modifications similar to insertions, updates, and deletions in Amazon RDS for MySQL database. These modifications received’t go unnoticed. Our Debezium MySQL connector stands able to seize every modification occasion, remodeling database modifications right into a steady stream of knowledge. Working in tandem with our AWS Glue streaming job, this structure is designed to promptly course of and propagate each change in our supply database by our information pipeline.Let’s see this real-time information synchronization mechanism in motion, demonstrating how our trendy information infrastructure maintains consistency throughout methods with minimal latency. Observe these steps:
- On the Amazon EC2 console, entry the EC2 occasion that you just created utilizing the CloudFormation template named as KafkaClientInstance.

- Log in to the EC2 occasion utilizing AWS Techniques Supervisor Agent (SSM Agent). Choose the occasion named as KafkaClientInstance after which select Join.

- Enter the next instructions to insert the information into the RDS desk. Use the identical database password you entered while you created the CloudFormation stack.
- Now carry out the insert, replace, and delete within the CUSTOMER desk.

- Validate the information to confirm the insert, replace, and delete information within the Iceberg desk from Athena, as proven within the following screenshot.


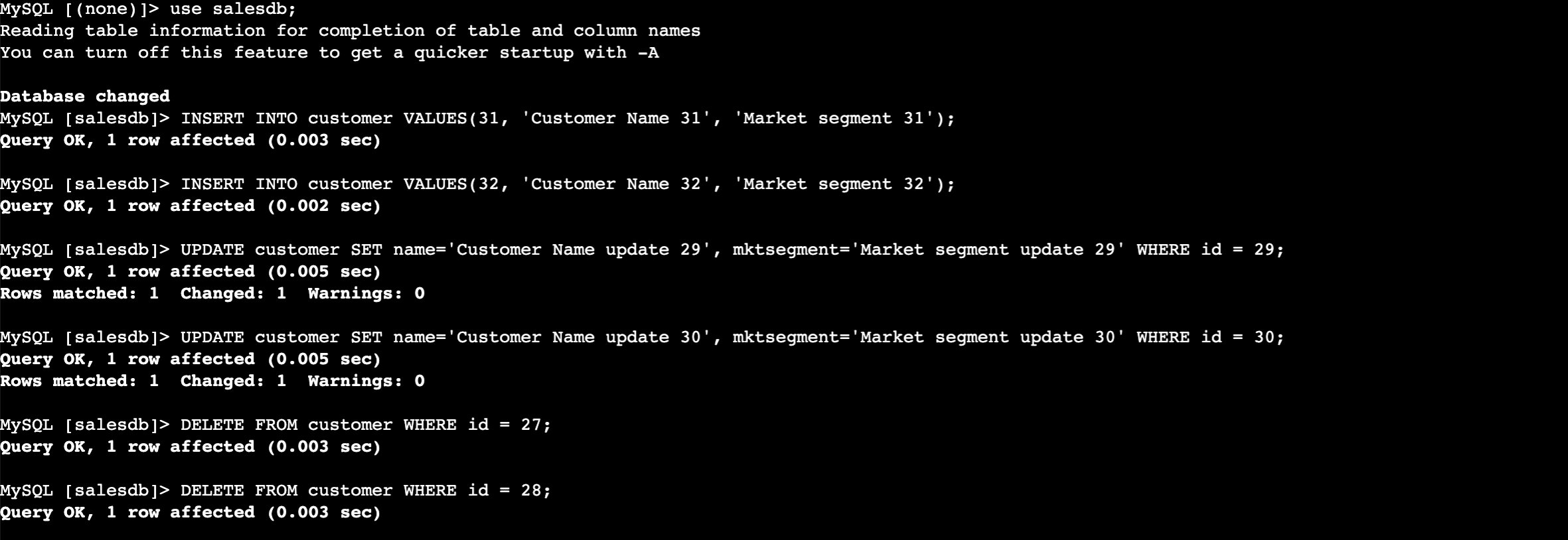
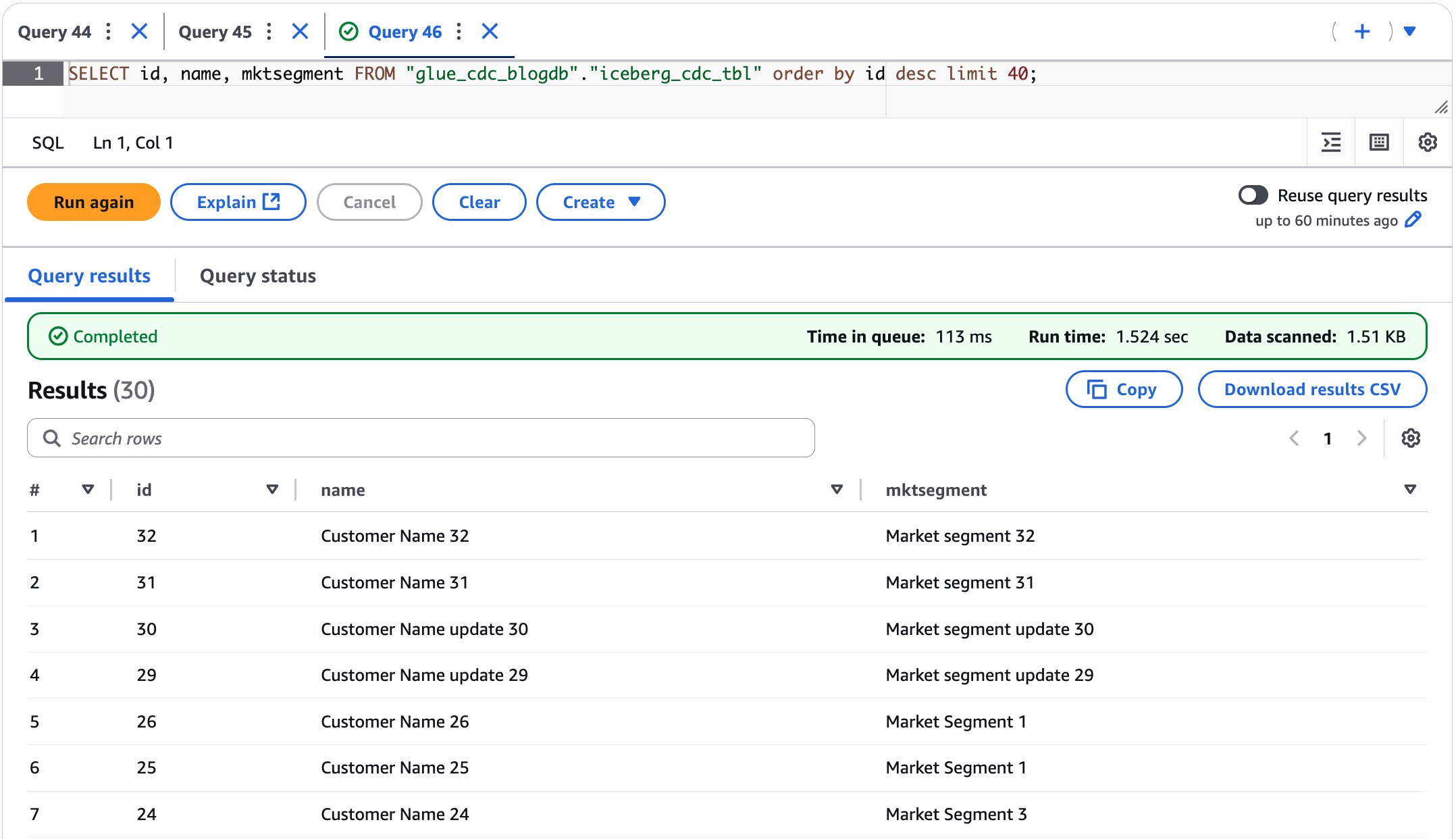
After performing the previous steps, you’ve realized how our CDC pipeline handles ongoing information modifications by performing insertions, updates, and deletions within the MySQL database and verifying how these modifications are mechanically captured by Debezium MySQL connector, streamed by Kafka, and mirrored within the Iceberg desk in close to actual time.
Schema evolution: Including new columns to the Iceberg desk
The schema evolution mechanism on this implementation gives an automatic strategy to detecting and including new columns from incoming information to present Iceberg tables. Though Iceberg inherently helps strong schema evolution capabilities (together with including, dropping, and renaming columns, updating varieties, and reordering), this code particularly automates the column addition course of for streaming environments. This automation makes use of Iceberg’s underlying schema evolution capabilities, which assure correctness by distinctive column IDs that guarantee new columns by no means learn present values from one other column. By dealing with column additions programmatically, the system reduces operational overhead in streaming pipelines the place handbook schema administration would create bottlenecks. Nonetheless, dropping and renaming columns, updating varieties, and reordering nonetheless required handbook intervention.
When new information arrives by Kafka streams, the handle_schema_evolution() operate orchestrates a four-step course of to make sure seamless desk schema updates.
- It analyzes the incoming batch DataFrame to deduce its schema construction, cataloging all column names and their corresponding information varieties.
- It retrieves the prevailing Iceberg desk’s schema from the AWS Glue catalog to ascertain a baseline for comparability.
- The system then performs a schema comparability utilizing technique compare_schemas() between batch schema with present desk schema.
- If the incoming body comprises fewer columns than the catalog desk, no motion is taken.
- It identifies any new columns current within the incoming information that don’t exist within the present desk construction and returns an inventory of recent columns that have to be added.
- New columns will likely be added on the final.
- Deal with kind evolution isn’t supported. If wanted, you’ll be able to deal with the identical at remark # Deal with kind evolution within the compare_schemas() technique.
- If the vacation spot desk has columns which are dropped within the supply desk, it doesn’t drop these columns. If that’s required to your use case, you need to use drop column manually utilizing
ALTER TABLE ... DROP COLUMN. - Renaming the column isn’t supported. To rename the column use case, manually evolve the schema utilizing ALTER TABLE … RENAME COLUMN.
- Lastly, if new columns are found, the operate executes ALTER TABLE … ADD COLUMN statements to evolve the Iceberg desk schema, including the brand new columns with their acceptable information varieties.
This strategy eliminates the necessity for handbook schema administration and prevents information pipeline failures that might usually happen when encountering sudden fields in streaming information. The implementation additionally consists of correct error dealing with and logging to trace schema evolution occasions, making it significantly precious for environments the place information constructions regularly change.
On this part, we display how our system handles structural modifications to the underlying information mannequin by including a brand new standing column to the buyer desk and populating it with default values. Our structure is designed to seamlessly propagate these schema modifications all through the pipeline in order that downstream analytics and processing capabilities stay uninterrupted whereas accommodating the improved information mannequin. This flexibility is important for sustaining a responsive, business-aligned information infrastructure that may evolve alongside altering organizational wants.
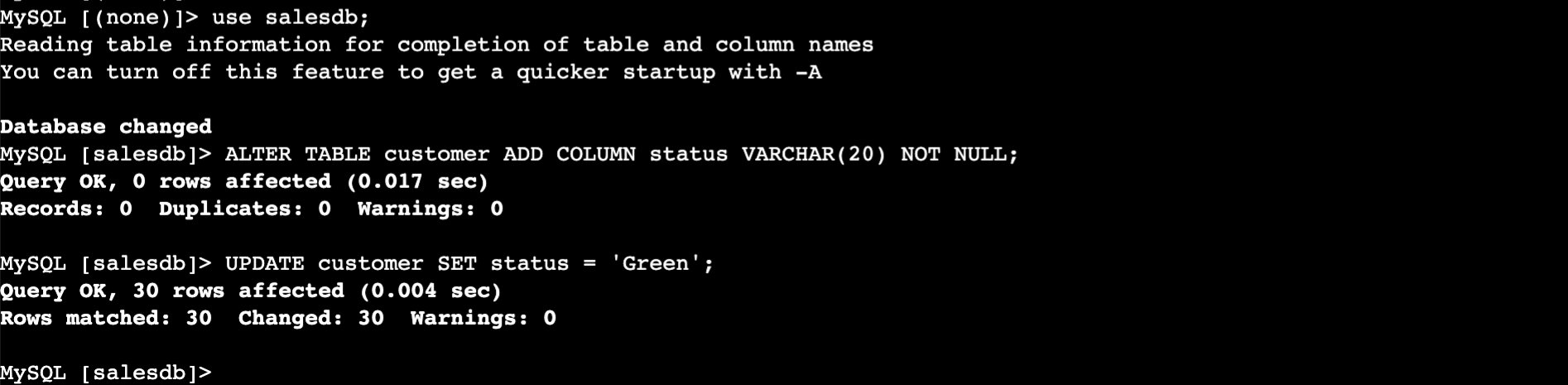
- Add a brand new
standingcolumn to thebuyerdesk and populate it with default values asInexperienced.
- Use the Athena console to validate the information and schema evolution, as proven within the following screenshot.

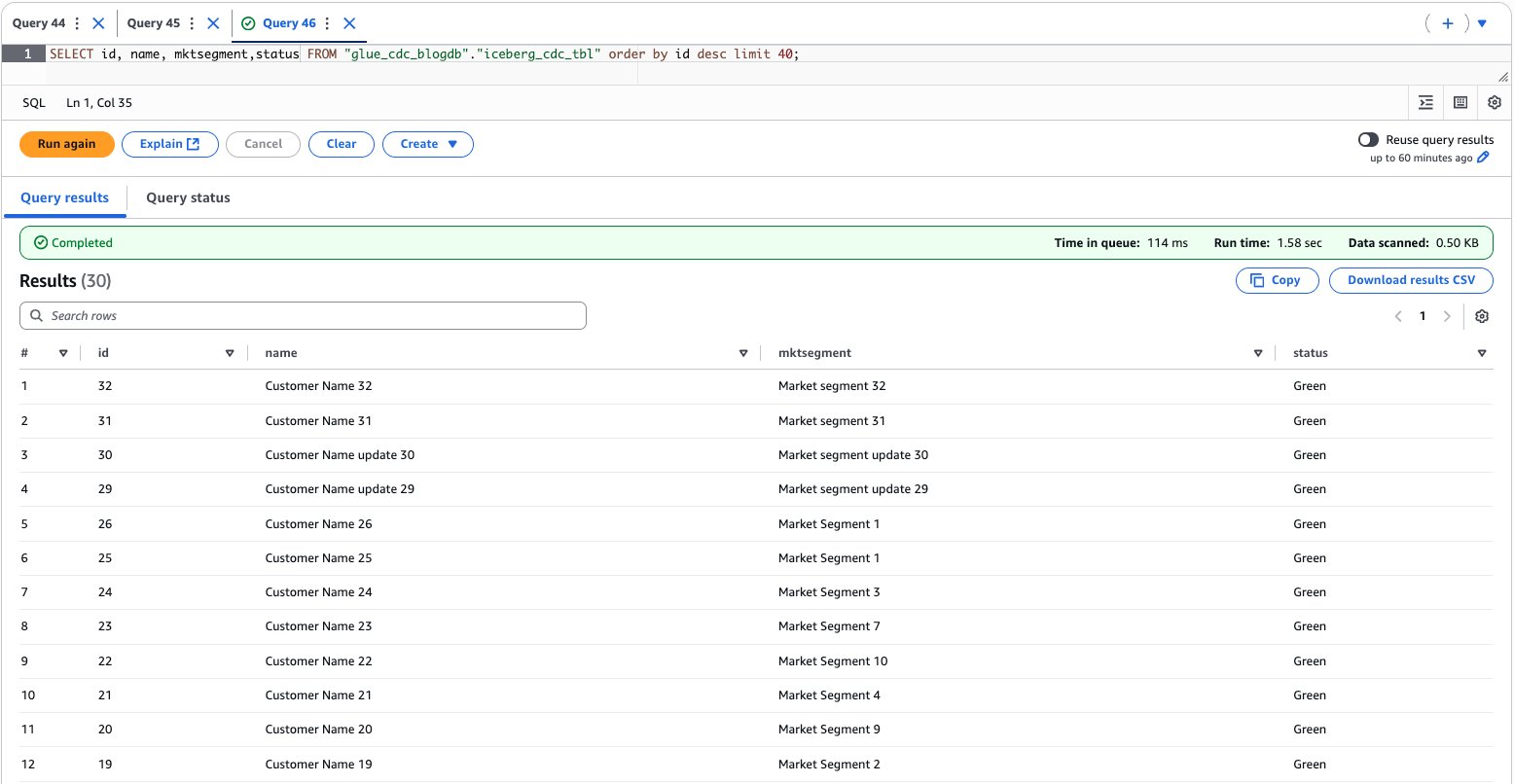
{kind=link}
When schema evolution happens in an Iceberg desk, the metadata.json file undergoes particular updates to trace and handle these modifications. In job when schema evolution detected, it ran the next question to evolve the schema for the Iceberg desk.
We checked the metadata.json file in Amazon S3 for iceberg desk location, and the next screenshot exhibits how the schema advanced.
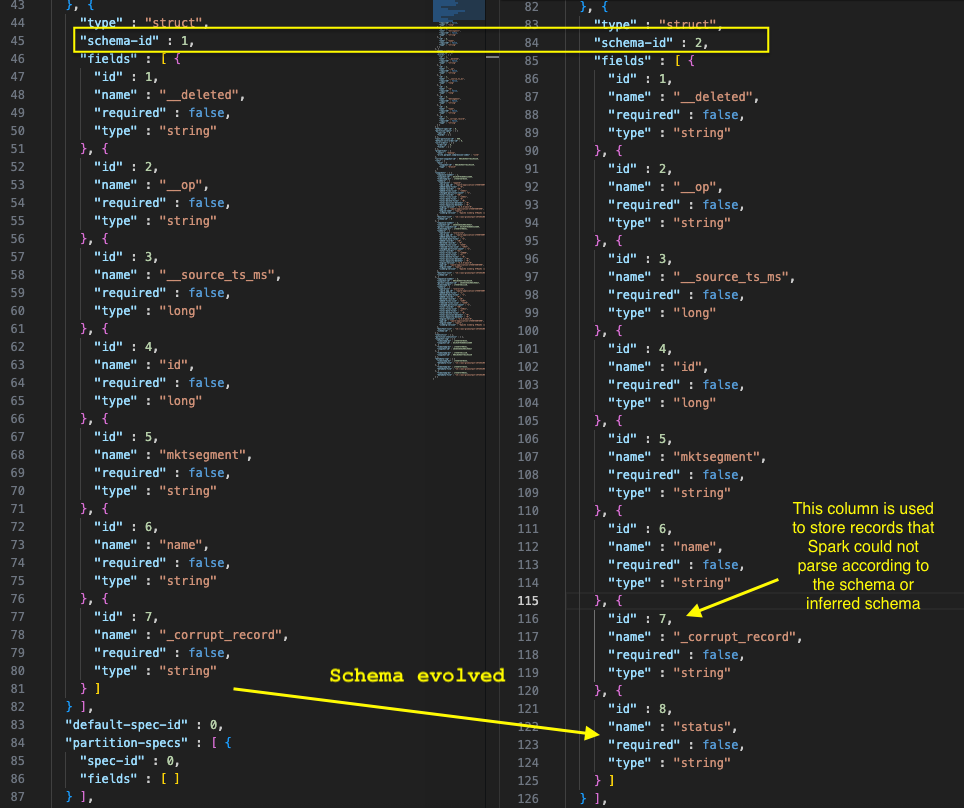
We now clarify how our implementation handles schema evolution by mechanically detecting and including new columns from incoming information streams to present Iceberg tables. The system employs a four-step course of that analyzes incoming information schemas, compares them with present desk constructions, identifies new columns, and executes the mandatory ALTER TABLE statements to evolve the schema with out handbook intervention, although sure schema modifications nonetheless require handbook dealing with.
Clear up
To scrub up your assets, full the next steps:
- Cease the operating AWS Glue streaming job:
- On the AWS Glue console, select ETL jobs within the navigation pane.
- Seek for the AWS Glue job named IcebergCDC-msk-iceberg-cdc-pipeline.
- Select the job identify to open its particulars web page.
- On the Runs tab, choose operating jobrun and select Cease job run. Affirm that the job stopped efficiently.
- Take away the AWS Glue database and desk:
- On the AWS Glue console, select Tables within the navigation pane, choose
iceberg_cdc_tbl, and select Delete. - Select Databases within the navigation pane, choose
glue_cdc_blogdb, and select Delete.
- On the AWS Glue console, select Tables within the navigation pane, choose
- Delete the CloudFormation stack vpc-msk-mskconnect-rds-client-gluejob.yaml.
Conclusion
This publish showcases an answer that companies can use to entry real-time information insights with out the normal delays between information creation and evaluation. By combining Amazon MSK Serverless, Debezium MySQL connector, AWS Glue streaming, and Apache Iceberg tables, the structure captures database modifications immediately and makes them instantly accessible for analytics by Amazon Athena. A standout function is the system’s means to mechanically adapt when database constructions change—similar to including new columns—with out disrupting operations or requiring handbook intervention. This eliminates the technical complexity usually related to real-time information pipelines and gives enterprise customers with essentially the most present info for decision-making, successfully bridging the hole between operational databases and analytical methods in a cheap, scalable means.