

{kind=link}

(inray27/Shutterstock)
Even earlier than generative AI arrived on the scene, corporations struggled to adequately safe their knowledge, purposes, and networks. Within the unending cat-and-mouse recreation between the nice guys and the unhealthy guys, the unhealthy guys win their share of battles. Nonetheless, the arrival of GenAI brings new cybersecurity threats, and adapting to them is the one hope for survival.
There’s all kinds of ways in which AI and machine studying work together with cybersecurity, a few of them good and a few of them unhealthy. However by way of what’s new to the sport, there are three patterns that stand out and deserve specific consideration, together with slopsquatting, immediate injection, and knowledge poisoning.
Slopsquatting
“Slopsquatting” is a contemporary AI tackle “typosquatting,” the place ne’er-do-wells unfold malware to unsuspecting Net vacationers who occur to mistype a URL. With slopsquatting, the unhealthy guys are spreading malware by way of software program improvement libraries which were hallucinated by GenAI.

‘Slopsquatting’ is a brand new technique to compromise AI techniques (flightofdeath/shutterstock)
We all know that giant language fashions (LLMs) are vulnerable to hallucinations. The tendency to create issues out of entire material shouldn’t be a lot a bug of LLMs, however a function that’s intrinsic to the best way LLMs are developed. A few of these confabulations are humorous, however others could be severe. Slopsquatting falls into the latter class.
Massive corporations have reportedly beneficial Pythonic libraries which were hallucinated by GenAI. In a latest story in The Register, Bar Lanyado, safety researcher at Lasso Safety, defined that Alibaba beneficial customers set up a pretend model of the respectable library referred to as “huggingface-cli.”
Whereas it’s nonetheless unclear whether or not the unhealthy guys have weaponized slopsquatting but, GenAI’s tendency to hallucinate software program libraries is completely clear. Final month, researchers revealed a paper that concluded that GenAI recommends Python and JavaScript libraries that don’t exist about one-fifth of the time.
“Our findings reveal that that the common proportion of hallucinated packages is a minimum of 5.2% for industrial fashions and 21.7% for open-source fashions, together with a staggering 205,474 distinctive examples of hallucinated package deal names, additional underscoring the severity and pervasiveness of this risk,” the researchers wrote within the paper, titled “We Have a Package deal for You! A Complete Evaluation of Package deal Hallucinations by Code Producing LLMs.”
Out of the 205,00+ situations of package deal hallucination, the names seemed to be impressed by actual packages 38% of the time, have been the outcomes of typos 13% of the time, and have been fully fabricated 51% of the time.
Immediate Injection
Simply while you thought it was secure to enterprise onto the Net, a brand new risk emerged: immediate injection.
Just like the SQL injection assaults that plagued early Net 2.0 warriors who didn’t adequately validate database enter fields, immediate injections contain the surreptitious injection of a malicious immediate right into a GenAI-enabled software to attain some aim, starting from data disclosure and code execution rights.
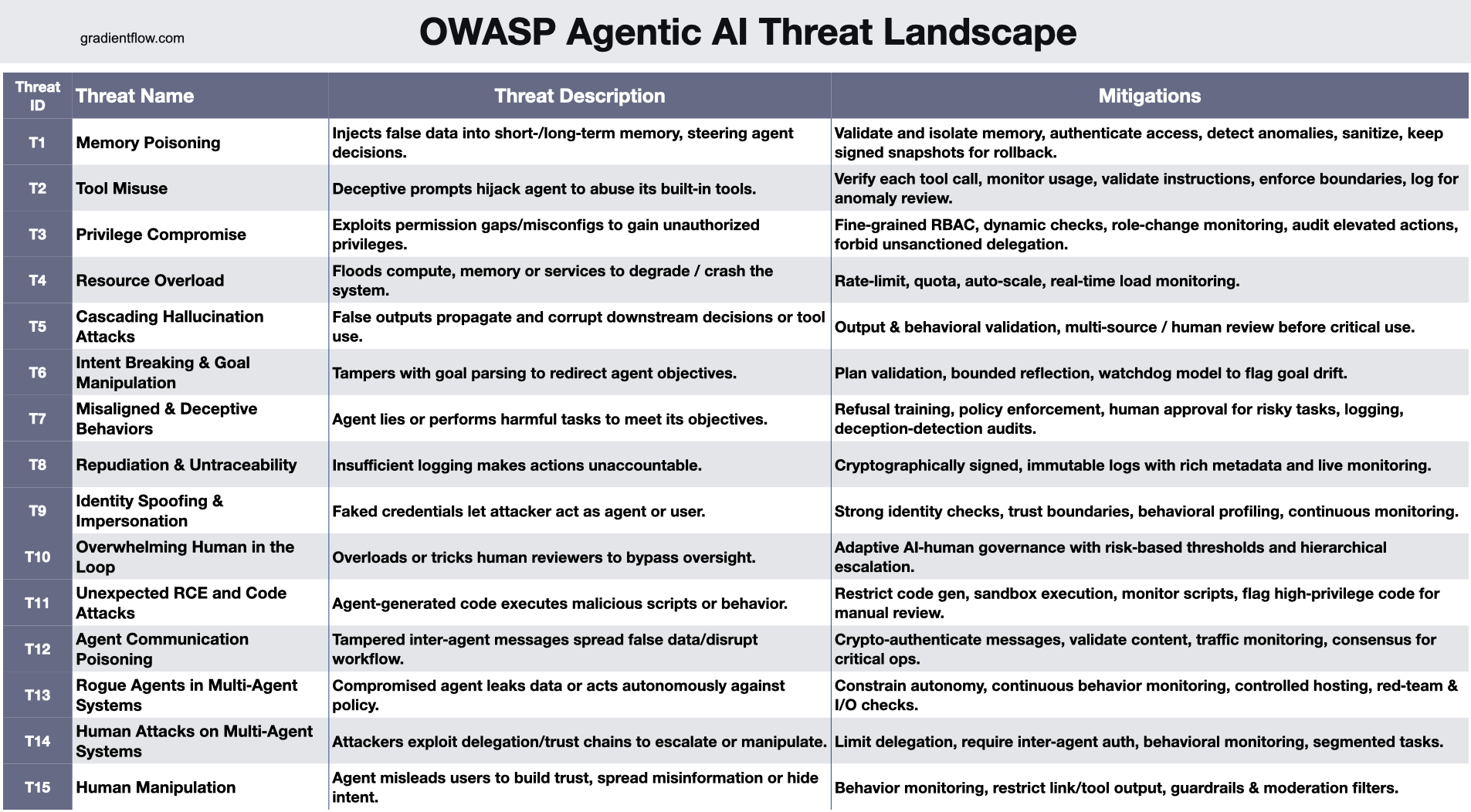
A listing of AI safety threats from OWASP (Supply: Ben Lorica)
Mitigating these types of assaults is tough due to the character of GenAI purposes. As a substitute of inspecting code for malicious entities, organizations should examine the entirery of a mannequin, together with all of its weights. That’s not possible in most conditions, forcing them to undertake different strategies, says knowledge scientist Ben Lorica.
“A poisoned checkpoint or a hallucinated/compromised Python package deal named in an LLM‑generated necessities file may give an attacker code‑execution rights inside your pipeline,” Lorica writes in a latest installment of his Gradient Move e-newsletter. “Commonplace safety scanners can’t parse multi‑gigabyte weight information, so further safeguards are important: digitally signal mannequin weights, keep a ‘invoice of supplies’ for coaching knowledge, and maintain verifiable coaching logs.”
A twist on the immediate injection assault was just lately described by researchers at HiddenLayer, who name their approach “coverage puppetry.”
“By reformulating prompts to appear to be one of some varieties of coverage information, akin to XML, INI, or JSON, an LLM could be tricked into subverting alignments or directions,” the researchers write in a abstract of their findings. “In consequence, attackers can simply bypass system prompts and any security alignments educated into the fashions.”
The corporate says its strategy to spoofing coverage prompts permits it to bypass mannequin alignment and produce outputs which are in clear violation of AI security insurance policies, together with CBRN (Chemical, Organic, Radiological, and Nuclear), mass violence, self-harm and system immediate leakage.
Knowledge Poisoning
Knowledge lies on the coronary heart of machine studying and AI fashions. So if a malicious consumer can inject, delete, or change the info that a company makes use of to coach an ML or AI mannequin, then she or he can doubtlessly skew the educational course of and drive the ML or AI mannequin to generate an antagonistic outcome.

Signs and remediations of knowledge poisoining (Supply: CrowdStrike)
A type of adversarial AI assaults, knowledge poisoning or knowledge manipulation poses a severe danger to organizations that depend on AI. Based on the safety agency CrowdStrike, knowledge poisoning is a danger to healthcare, finance, automotive, and HR use instances, and might even doubtlessly be used to create backdoors.
“As a result of most AI fashions are continuously evolving, it may be tough to detect when the dataset has been compromised,” the corporate says in a 2024 weblog put up. “Adversaries usually make delicate–however potent–adjustments to the info that may go undetected. That is very true if the adversary is an insider and due to this fact has in-depth details about the group’s safety measures and instruments in addition to their processes.”
Knowledge poisoning could be both focused or non-targeted. In both case, there are telltale indicators that safety professionals can search for that point out whether or not their knowledge has been compromised.
AI Assaults as Social Engineering
These three AI assault vectors–slopsquatting, immediate injection, and knowledge poisoning–aren’t the one ways in which cybercriminals can assault organizations through AI. However they’re three avenues that AI-using organizations ought to concentrate on to thwart the potential compromise of their techniques.
Except organizations take pains to adapt to the brand new ways in which hackers can compromise techniques by way of AI, they run the chance of changing into a sufferer. As a result of LLMs behave probabilistically as a substitute of deterministically, they’re much extra liable to social engineering-types of assaults than conventional techniques, Lorica says.
“The result’s a harmful safety asymmetry: exploit strategies unfold quickly by way of open-source repositories and Discord channels, whereas efficient mitigations demand architectural overhauls, refined testing protocols, and complete workers retraining,” Lorica writes. “The longer we deal with LLMs as ‘simply one other API,’ the broader that hole turns into.”
Associated Objects:
CSA Report Reveals AI’s Potential for Enhancing Offensive Safety
Your APIs are a Safety Threat: Safe Your Knowledge in an Evolving Digital Panorama
Cloud Safety Alliance Introduces Complete AI Mannequin Threat Administration Framework