

{kind=link}
Retrieval-Augmented Era (RAG) techniques improve generative AI capabilities by integrating exterior doc retrieval to supply contextually wealthy responses. With the discharge of GPT 4.1, characterised by distinctive instruction-following, coding excellence, long-context assist (as much as 1 million tokens), and notable affordability, constructing agentic RAG techniques turns into extra highly effective, environment friendly, and accessible. On this article, we’ll uncover what makes GPT-4.1 so highly effective and learn to construct an agentic RAG system utilizing GPT-4.1 mini.
Overview of GPT 4.1
GPT 4.1 considerably improves upon its predecessors, offering substantial features in:
- Coding: Achieves a 55% success fee on SWE-bench Verified, considerably outperforming GPT 4o.
- Instruction Following: Enhanced capabilities to deal with advanced, multi-step, and nuanced directions successfully.
- Lengthy Context: Helps a context window of as much as 1 million tokens, appropriate for broad information evaluation. Nonetheless, retrieval accuracy barely decreases with prolonged contexts.
- Price Effectivity: GPT-4.1 provides 83% decrease prices and 50% diminished latency in comparison with GPT-4o.
What’s New in GPT 4.1?
OpenAI has rolled out the GPT-4.1 lineup, together with three fashions: GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. Here’s what it provides:
1. 1M Token Context: Assume Larger Prompts
One of many headline options is the 1-million-token context window – a primary for OpenAI. Now you can feed in large blocks of code, analysis papers, or complete doc units in a single go. That stated, whereas it handles scale impressively, pinpoint accuracy fades because the enter grows, so it’s greatest used for broad context understanding moderately than surgical precision.
2. Coding Upgrades: Smarter, Multilingual, Extra Correct

In the case of programming, GPT-4.1 steps up considerably:
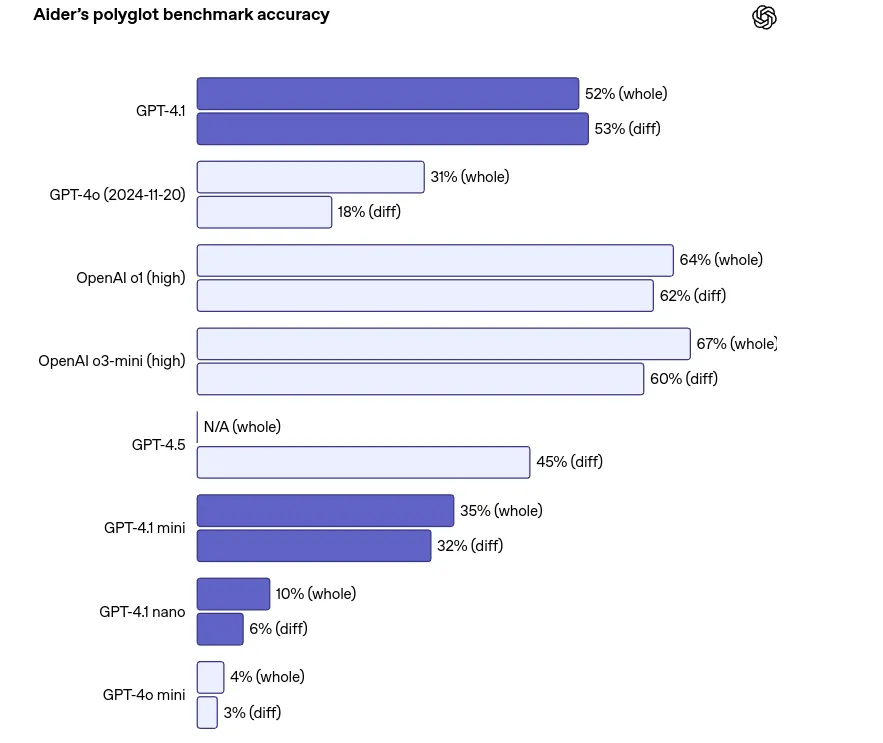
- Python Benchmarks: It scores 55% on SWE-bench verified, outdoing GPT-4o.
- Multilingual Code Duties: Because of the Polyglot benchmark, it could possibly deal with a number of languages higher than earlier than.
- Very best for auto-generating code, debugging, and even aiding in full-stack builds.
3. Higher Instruction Following
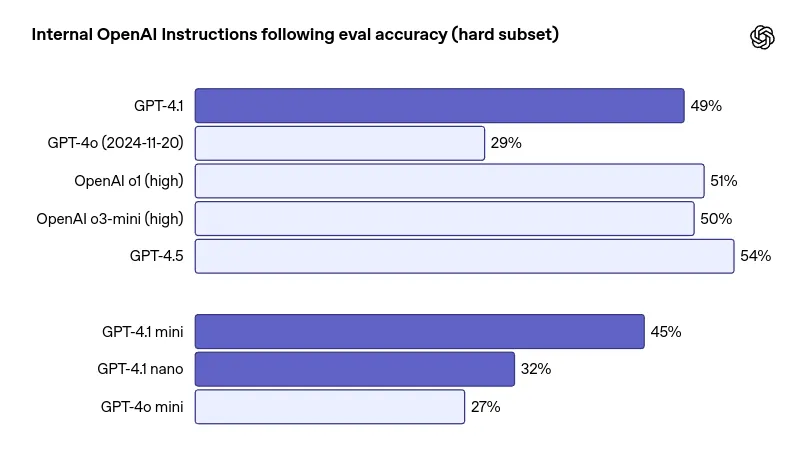
GPT-4.1 is now extra aware of multi-step directions and nuanced formatting guidelines. Whether or not you’re designing workflows or constructing AI brokers, this mannequin is a lot better at doing what you really ask for.
4. Pace & Price: Half the Latency, Fraction of the Value
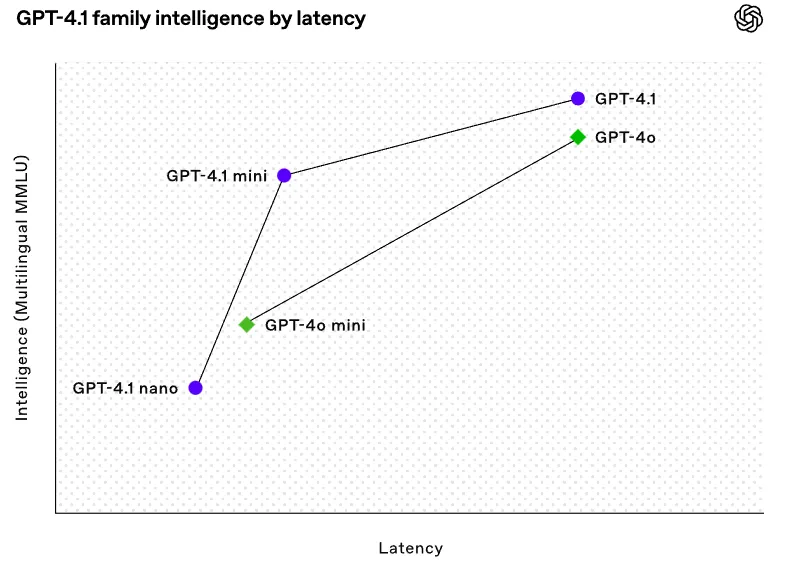
This model is optimized for efficiency and affordability:
- 50% quicker response occasions
- 83% cheaper than GPT-4o
- The Nano variant is especially geared for high-frequency, budget-sensitive use – excellent for scaling purposes with tight margins.
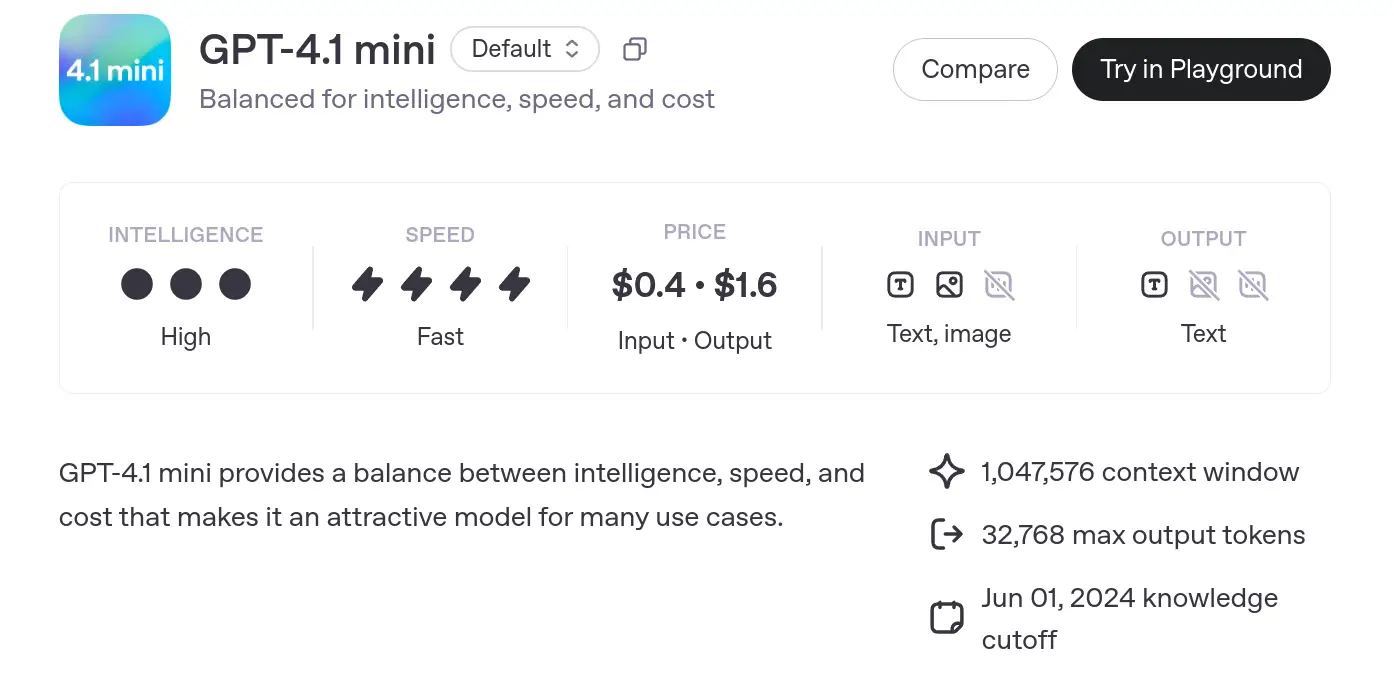
- The GPT-4.1 mini mannequin is designed to steadiness intelligence, pace, and value. It provides excessive intelligence and quick pace, making it appropriate for a lot of use instances.
- Pricing: $0.4 – $1.6 per input-output.
- Enter: Textual content and picture.
- Output: Textual content.
- Context Window: 1,047,576 tokens (giant capability for processing).
- Max Output: 32,768 tokens.
- Data Cutoff: June 1, 2024.
Learn this text to know extra: All About OpenAI’s Newest GPT 4.1 Household
Constructing Agentic RAG Utilizing GPT 4.1 mini
I’m constructing a multi-document, agentic RAG system with GPT 4.1 mini. Right here’s the workflow.
- Ingests two lengthy PDFs (on ML and GenAI economics).
- Chunks them into overlapping items (chunk_size=5000, chunk_overlap=300)—designed to protect context.
- Embeds these chunks utilizing OpenAI’s text-embedding-3-small mannequin.
- Shops them in two separate Chroma vector shops for environment friendly similarity-based retrieval.
- Wraps the retrieval+LLM immediate logic into two chains (one per matter).
- Exposes these chains as instruments to a LangChain Zero-Shot Agent, which routes the question to the suitable context.
- Queries like “Why is Self-Consideration used?” or “How will advertising change with GenAI?” are answered precisely and contextually—because of the large chunks and high-quality retrieval.
1. Setup and Set up
!pip set up langchain==0.3.23
!pip set up -U langchain-openai
!pip set up langchain-community==0.3.11
!pip set up langchain-chroma==0.1.4
!pip set up pypdfSet up the mandatory imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.brokers import AgentType, Instrument, initialize_agentI’m pinning particular variations of LangChain packages and associated dependencies for compatibility—sensible transfer.
2. OpenAI API Key
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY3. Load PDFs utilizing PyPDFLoader
pdf_dir = "/content material/document_pdf"
machinelearning_paper = os.path.be a part of(pdf_dir, "Machinelearningalgorithm.pdf")
genai_paper = os.path.be a part of(pdf_dir, "the-economic-potential-of-generative-ai-
the-next-productivity-frontier.pdf")
# Load particular person PDF paperwork
print("Loading ml pdf...")
ml_loader = PyPDFLoader(machinelearning_paper)
ml_documents = ml_loader.load()
print("Loading genai pdf...")
genai_loader = PyPDFLoader(genai_paper)
genai_documents = genai_loader.load()Hundreds the PDFs into LangChain Doc objects. Every web page turns into one Doc.
3. Chunk with RecursiveCharacterTextSplitter
# Cut up the paperwork
text_splitter = RecursiveCharacterTextSplitter(chunk_size=5000, chunk_overlap=300)
ml_splits = text_splitter.split_documents(ml_documents)
genai_splits = text_splitter.split_documents(genai_documents)
print(f"Created {len(ml_splits)} splits for ml PDF")
print(f"Created {len(genai_splits)} splits for genai PDF")That is the guts of your long-context dealing with. This instrument:
- Retains chunks underneath 5000 tokens.
- Preserves context with 300 overlap.
The recursive splitter tries splitting on paragraphs → sentences → characters, preserving as a lot semantic construction as potential.
Ml_splits[:3]

genai_splits[:5]

4. Embedding with OpenAIEmbeddings
# particulars right here: https://openai.com/weblog/new-embedding-models-and-api-updates
openai_embed_model = OpenAIEmbeddings(mannequin="text-embedding-3-small")I’m utilizing the 2024 text-embedding-3-small mannequin, which is:
- Smaller, quicker, but extra correct than older fashions.
- Nice for cost-effective, high-quality retrieval.
5. Retailer in Chroma Vector Shops
# Create separate vectorstores
ml_vectorstore = Chroma.from_documents(
paperwork=ml_splits,
embedding=openai_embed_model,
collection_metadata={"hnsw:area": "cosine"},
collection_name="ml-knowledge"
)
genai_vectorstore = Chroma.from_documents(
paperwork=genai_splits,
embedding=openai_embed_model,
collection_metadata={"hnsw:area": "cosine"},
collection_name="genai-knowledge"
)Right here, I’m creating two vector shops:
- One for ML-related chunks
- One for GenAI-related chunks
Utilizing cosine similarity for retrieval:
ml_retriever = ml_vectorstore.as_retriever(search_type="similarity_score_threshold",search_kwargs={"okay": 5,"score_threshold": 0.3})
genai_retriever = genai_vectorstore.as_retriever(search_type="similarity_score_threshold",search_kwargs={"okay": 5,"score_threshold": 0.3})Solely return the highest 5 chunks with sufficient similarity. Retains solutions tight.
question = "what are ML algorithms?"
top3_docs = ml_retriever.invoke(question)
top3_docs
6. Retrieval and Immediate Creation
# Create the immediate templates
ml_prompt = ChatPromptTemplate.from_template(
"""
You're an professional in machine studying algorithms with deep technical information of the sphere.
Reply the next query primarily based solely on the offered context extracted from related machine studying analysis paperwork.
Context:
{context}
Query:
{query}
If the reply can't be discovered within the context, please reply with: "I haven't got sufficient data to reply this query primarily based on the offered context."
"""
)
genai_prompt = ChatPromptTemplate.from_template(
"""
You're an professional within the financial influence and potential of generative AI applied sciences throughout industries and markets.
Reply the next query primarily based solely on the offered context associated to the financial features of generative AI.
Context:
{context}
Query:
{query}
If the reply can't be discovered within the context, please state "I haven't got sufficient data to reply this query primarily based on the offered context."
"""
)Right here, I’m creating context-specific prompts:
- ML QA system: asks about algorithms, coaching, and so forth.
- GenAI QA system: focuses on financial influence, cross-industry makes use of.
These prompts additionally guard towards hallucination with:
“If the reply can’t be discovered within the context… reply with: ‘I don’t have sufficient data…’”
Good for reliability.
7. LCEL Chains
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4.1-mini-2025-04-14", temperature=0)def format_docs(docs):
return "nn".be a part of(doc.page_content for doc in docs)# Create the RAG chains utilizing LCEL
ml_chain = (
{
"context": lambda query: format_docs(ml_retriever.get_relevant_documents(query)),
"query": RunnablePassthrough()
}
| ml_prompt
| llm
| StrOutputParser()
)
genai_chain = (
{
"context": lambda query: format_docs(genai_retriever.get_relevant_documents(query)),
"query": RunnablePassthrough()
}
| genai_prompt
| llm
| StrOutputParser()
)That is the place LangChain Expression Language (LCEL) shines.
- Retrieve chunks
- Format them as context
- Inject into the immediate
- Ship to gpt-4.1-mini
- Parse the response string
It’s elegant, reusable, and modular.
8. Outline Instruments for Agent
# Outline the instruments
instruments = [
Tool(
name="ML Knowledge QA System",
func=ml_chain.invoke,
description="Useful for when you need to answer questions related to machine learning concepts, models, training techniques, evaluation metrics, algorithms and practical implementations. Covers supervised and unsupervised learning, model optimization, bias-variance tradeoff, feature engineering, and algorithm selection. Input should be a fully formed question."
),
Tool(
name="GenAI QA System",
func=genai_chain.invoke,
description="Useful for when you need to answer questions about the economic impact, market potential, and cross-industry implications of generative AI technologies. Input should be a fully formed question. Responses are based strictly on the provided context related to the economics of generative AI."
)
]Every chain turns into a Instrument in LangChain. Instruments are like plug-and-play capabilities for the agent.
9. Initialize Agent
# Initialize the agent
agent = initialize_agent(
instruments,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)I’m utilizing the Zero-Shot ReAct agent, which interprets the question, decides which instrument (ML or GenAI) to make use of, and routes the enter accordingly.
10. Question Time!
end result = agent.invoke("How advertising and sale might be remodeled utilizing Generative AI?")
Agent:
- Chooses GenAI QA System
- Retrieves prime context chunks from GenAI vectorstore
- Codecs immediate
- Sends to GPT-4.1
- Returns a grounded, non-hallucinated reply
result1 = agent.invoke("why Self-Consideration is used?")
Agent:
- Chooses ML QA System
- Retrieves prime context chunks from ML vectorstore
- Codecs immediate
- Sends to GPT-4.1mini
- Returns a grounded, non-hallucinated reply
result2 = agent.invoke("what are Tree-based algorithms?")
GPT-4.1 proves to be exceptionally efficient for working with giant paperwork, because of its prolonged context window of as much as 1 million tokens. This enhancement eliminates the long-standing limitations confronted with earlier fashions, the place paperwork needed to be closely chunked into small segments, typically dropping semantic coherence.
With the power to deal with giant chunks, such because the 5000-token segments used right here, GPT-4.1 can ingest and purpose over dense, information-rich sections with out lacking contextual hyperlinks throughout paragraphs or pages. That is particularly helpful in situations involving advanced paperwork like educational papers or {industry} whitepapers, the place understanding typically is determined by multi-page continuity. The mannequin handles these prolonged chunks precisely and delivers context-grounded responses with out hallucinations, a functionality additional amplified by well-designed retrieval prompts.
Furthermore, in a RAG pipeline, the standard of responses is closely tied to how a lot helpful context the mannequin can devour directly. GPT-4.1 removes the earlier ceiling, making it potential to retrieve and purpose over full conceptual items moderately than fragmented excerpts. In consequence, you’ll be able to ask deep, nuanced questions on lengthy paperwork and obtain exact, well-informed solutions, making GPT-4.1 a game-changer for production-grade doc evaluation and retrieval-based purposes.
Additionally learn: A Complete Information to Constructing Agentic RAG Methods with LangGraph
Extra Than Only a “Needle in a Haystack”
This can be a needle-in-a-haystack benchmark evaluating how effectively completely different fashions can retrieve or purpose over a related piece of data (a “needle”) buried inside a protracted context (“haystack”).
GPT-4.1 excels at discovering particular details in giant paperwork, however OpenAI pushed issues additional with the OpenAI-MRCR benchmark, which assessments multi-fact retrieval:
- With 2 key details (“needles”): GPT-4.1 does higher than 4.0.
- With 4 or extra: Bigger fashions like GPT-4.5 nonetheless dominate, particularly in shorter enter situations.
8-needle situation – that means 8 related items of data are embedded in an extended sequence of tokens, and the mannequin is examined on its capacity to retrieve or reference them precisely.
So, whereas GPT-4.1 handles fundamental long-context duties effectively, it’s not fairly prepared for deep, interconnected reasoning but.
2 Needle
This usually refers to a less complicated model of the duty, presumably with fewer classes or easier choice factors. The “accuracy” on this case is measured by how effectively the mannequin performs when distinguishing between two classes or making two distinct choices.

4 Needle
This may contain a extra advanced process the place there are 4 distinct classes or outcomes to foretell. It’s a more difficult process for the mannequin in comparison with “2 needle,” that means the mannequin has to make extra nuanced distinctions.

8 Needle
An much more advanced situation, the place the mannequin has to appropriately predict from eight completely different classes or outcomes. The upper the “needle” depend, the more difficult the duty is, requiring the mannequin to display a broader vary of understanding and accuracy.

Nonetheless, relying in your use case (particularly for those who’re working with underneath 200K tokens), alternate options like DeepSeek-R1 or Gemini 2.5 may offer you extra worth per greenback.
Nonetheless, in case your wants embody cutting-edge reasoning or essentially the most up-to-date information, watch GPT-4.5 or rivals like Gemini.
GPT-4.1 is probably not a complete game-changer, nevertheless it’s a sensible evolution, particularly for builders. OpenAI targeted on sensible enhancements: higher coding assist, lengthy context processing, and decrease prices to make the fashions extra accessible.
Nonetheless, areas like benchmark transparency and information freshness go away area for rivals to leap in. As competitors ramps up, GPT-4.1 proves OpenAI is listening—now it’s Google, Anthropic, and the remainder’s transfer.
Why Chunking Works So Nicely (5000 + 300 overlap)?
The config:
- chunk_size = 5000
- chunk_overlap = 300
Why is that this efficient with GPT-4.1?
- GPT-4.1 helps 1M token context. Feeding longer chunks is lastly helpful now. Smaller chunks would’ve missed the semantic glue between concepts unfold throughout paragraphs.
- 5000-token chunks guarantee minimal semantic splitting, capturing giant conceptual items like “Transformer structure” or “financial implications of GenAI”.
- 300-token overlap helps protect cross-chunk context, stopping cutoff points.
That’s probably why you’re not seeing misses or hallucinations—you’re giving the LLM precisely the chunked context it wants.
Alright, let’s break this down with a step-by-step information to constructing an agentic Retrieval-Augmented Era (RAG) pipeline utilizing GPT-4.1 and leveraging its 1 million token context window functionality by chunking and indexing two giant PDFs (50+ pages every) to retrieve correct solutions with zero hallucination.
Key Advantages and Concerns of GPT 4.1
- Enhanced Retrieval: Superior efficiency in single-fact retrieval however barely decrease effectiveness in advanced, multi-information synthesis duties in comparison with bigger fashions like GPT-4.5.
- Price-effectiveness: Significantly the Nano variant, ultimate for budget-sensitive, high-throughput duties.
- Developer-friendly: Very best for coding purposes, authorized doc evaluation, and prolonged context duties.
Conclusion
GPT-4.1 Mini emerges as a strong and cost-effective basis for establishing agentic Retrieval-Augmented Era (RAG) techniques. Its assist for a 1 million token context window permits for the ingestion of enormous, semantically wealthy doc chunks, enhancing the mannequin’s capacity to supply contextually grounded and correct responses.
GPT-4.1 Mini’s enhanced instruction-following capabilities, long-context dealing with, and affordability make it a superb selection for growing subtle, production-grade RAG purposes. Its design facilitates deep, nuanced interactions with in depth paperwork, positioning it as a helpful asset within the evolving panorama of AI-driven data retrieval.
Regularly Requested Questions
Bigger chunks let GPT-4.1 “see” greater concepts abruptly—like explaining an entire recipe as an alternative of simply itemizing components. Smaller chunks may break up up related concepts (like separating “why self-attention works” from “the way it’s calculated”), making solutions much less correct.
In case you dump all the pieces into one pile, the mannequin may combine up solutions about machine studying algorithms with economics stories. Separating them is like giving the AI two specialised brains: one for coding and one for enterprise evaluation.
Yep! It’s ~83% cheaper than GPT-4.0 for fundamental duties, and the Nano variant is constructed for apps needing tons of queries on a funds (like chatbots for buyer assist). However for those who’re doing ultra-complex duties, greater fashions like GPT-4.5 may nonetheless be price the price.
Completely. The 1 M-token context means you’ll be able to feed it complete contracts or stories with out dropping the larger image. Simply tweak the prompts to say, “You’re a authorized professional analyzing clauses…” and it’ll adapt.
It’s manner higher at multilingual duties than older variations! For coding, it understands combined languages (like Python + SQL). For textual content, it helps frequent languages like Spanish or French—however for area of interest dialects, rivals like Gemini 2.5 may nonetheless edge it out.
Whereas it’s nice at discovering single details in lengthy docs, asking it to attach 8+ hidden particulars (like fixing a thriller novel) can journey it up. For deep evaluation, pair it with a human, or perhaps, look forward to GPT-4.5!
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Obsessed with storytelling and crafting compelling narratives that remodel concepts into impactful content material. I really like studying about know-how revolutionizing our life-style.
Login to proceed studying and revel in expert-curated content material.