

The Amazon SageMaker lakehouse structure has expanded its tag-based entry management (TBAC) capabilities to incorporate federated catalogs. This enhancement extends past the default AWS Glue Knowledge Catalog sources to embody Amazon S3 Tables, Amazon Redshift knowledge warehouses. TBAC can be supported on federated catalogs from knowledge sources Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. TBAC offers you a complicated permission administration that makes use of tags to create logical groupings of catalog sources, enabling directors to implement fine-grained entry controls throughout their complete knowledge panorama with out managing particular person resource-level permissions.
Conventional knowledge entry administration usually requires guide project of permissions on the useful resource stage, creating vital administrative overhead. TBAC solves this by introducing an automatic, inheritance-based permission mannequin. When directors apply tags to knowledge sources, entry permissions are routinely inherited, eliminating the necessity for guide coverage modifications when new tables are added. This streamlined strategy not solely reduces administrative burden but in addition enhances safety consistency throughout the info ecosystem.
TBAC could be arrange via the AWS Lake Formation console, and accessible utilizing Amazon Redshift, Amazon Athena, Amazon EMR, AWS Glue, and Amazon SageMaker Unified Studio. This makes it invaluable for organizations managing advanced knowledge landscapes with a number of knowledge sources and enormous datasets. TBAC is very helpful for enterprises implementing knowledge mesh architectures, sustaining regulatory compliance, or scaling their knowledge operations throughout a number of departments. Moreover, TBAC allows environment friendly knowledge sharing throughout completely different accounts, making it simpler to take care of safe collaboration.
On this publish, we illustrate tips on how to get began with fine-grained entry management of S3 Tables and Redshift tables within the lakehouse utilizing TBAC. We additionally present tips on how to entry these lakehouse tables utilizing your alternative of analytics providers, corresponding to Athena, Redshift, and Apache Spark in Amazon EMR Serverless in Amazon SageMaker Unified Studio.
Resolution overview
For illustration, we take into account a fictional firm known as Instance Retail Corp, as lined within the weblog publish Speed up your analytics with Amazon S3 Tables and Amazon SageMaker Lakehouse. Instance Retail’s management has determined to make use of the SageMaker lakehouse structure to unify knowledge throughout S3 Tables and their Redshift knowledge warehouse. With this lakehouse structure, they will now conduct analyses throughout their knowledge to determine at-risk clients, perceive the affect of personalised advertising campaigns on buyer churn, and develop focused retention and gross sales methods.
Alice is a knowledge administrator with the AWS Identification and Entry Administration (IAM) function LHAdmin in Instance Retail Corp, and he or she needs to implement tag-based entry management to scale permissions throughout their knowledge lake and knowledge warehouse sources. She is utilizing S3 Tables with Iceberg transactional functionality to realize scalability as updates are streamed throughout billions of buyer interactions, whereas offering the identical sturdiness, availability, and efficiency traits that S3 is understood for. She already has a Redshift namespace, which comprises historic and present knowledge about gross sales, clients prospects, and churn info. Alice helps an prolonged staff of builders, engineers, and knowledge scientists who require entry to the info surroundings to develop enterprise insights, dashboards, ML fashions, and data bases. This staff consists of:
- Bob, a knowledge steward with IAM function
DataSteward, is the area proprietor and manages entry to the S3 Tables and warehouse knowledge. He allows different groups who construct studies to be shared with management. - Charlie, a knowledge analyst with IAM function
DataAnalyst, builds ML forecasting fashions for gross sales development utilizing the pipeline or buyer conversion throughout a number of touchpoints, and makes these accessible to finance and planning groups. - Doug, a BI engineer with IAM function
BIEngineer, builds interactive dashboards to funnel buyer prospects and their conversions throughout a number of touchpoints, and makes these accessible to hundreds of gross sales staff members.
Alice decides to make use of the SageMaker lakehouse structure to unify knowledge throughout S3 Tables and Redshift knowledge warehouse. Bob can now carry his area knowledge into one place and handle entry to a number of groups requesting entry to his knowledge. Charlie can shortly construct Amazon QuickSight dashboards and use his Redshift and Athena experience to offer fast question outcomes. Doug can construct Spark-based processing with AWS Glue or Amazon EMR to construct ML forecasting fashions.
Alice’s objective is to make use of TBAC to make fine-grained entry way more scalable, as a result of they will grant permissions on many sources without delay and permissions are up to date accordingly when tags for sources are added, modified, or eliminated.The next diagram illustrates the answer structure.

Alice as Lakehouse admin and Bob as Knowledge Steward determines that following high-level steps are wanted to deploy the answer:
- Create an S3 Tables bucket and allow integration with the Knowledge Catalog. It will make the sources accessible underneath the federated catalog
s3tablescatalogwithin the lakehouse structure with Lake Formation for entry management. Create a namespace and a desk underneath the desk bucket the place the info shall be saved. - Create a Redshift cluster with tables, publish your knowledge warehouse to the Knowledge Catalog, and create a catalog registering the namespace. It will make the sources accessible underneath a federated catalog within the lakehouse structure with Lake Formation for entry management.
- Delegate permissions to create tags and grant permissions on Knowledge Catalog sources to
DataSteward. - As
DataSteward, outline tag ontology primarily based on the use case and create Tags. Assign these LF-Tags to the sources (database or desk) to logically group lakehouse sources for sharing primarily based on entry patterns. - Share the S3 Tables catalog desk and Redshift desk utilizing tag-based entry management to
DataAnalyst, who makes use of Athena for evaluation and Redshift Spectrum for producing the report. - Share the S3 Tables catalog desk and Redshift desk utilizing tag-based entry management to
BIEngineer, who makes use of Spark in EMR Serverless to additional course of the datasets.
Knowledge steward defines the tags and project to sources as proven:
| Tags | Knowledge Sources |
Area = gross sales Sensitivity = false | S3 Desk: buyer( c_salutation, c_preferred_cust_flag,c_first_sales_date_sk, |
Area = gross sales Sensitivity = true | S3 Desk: buyer( c_first_name, c_last_name, c_email_address, c_birth_year) |
Area = gross sales Sensitivity = false | Redshift Desk: gross sales.store_sales |
The next desk summarizes the tag expression that’s granted to roles for useful resource entry:
| Consumer | Persona | Permission Granted | Entry |
| Bob | DataSteward | SUPER_USER on catalogs | Admin entry on buyer and store_sales. |
| Charlie | DataAnalyst | Area = gross sales Sensitivity = false | Entry to non -sensitive knowledge that’s aligned to gross sales area: buyer(non-sensitive columns) and store_sales. |
| Doug | BIEngineer | Area = gross sales | Entry to all datasets that’s aligned to gross sales area: buyer and store_sales. |
Conditions
To observe together with this publish, full the next prerequisite steps:
- Have an AWS account and admin consumer with entry to the next AWS providers:
- Athena
- Amazon EMR
- IAM
- Lake Formation and the Knowledge Catalog
- Amazon Redshift
- Amazon S3
- IAM Identification Middle
- Amazon SageMaker Unified Studio
- Create a knowledge lake admin (
LHAdmin). For directions, see Create a knowledge lake administrator. - Create an IAM function named
DataStewardand fix permissions for AWS Glue and Lake Formation entry. For directions, confer with Knowledge lake administrator permissions. - Create an IAM function named
DataAnalystand fix permissions for Amazon Redshift and Athena entry. For directions, confer with Knowledge analyst permissions. - Create an IAM function named
BIEngineerand fix permissions for Amazon EMR entry. That is additionally the EMR runtime function that the Spark job will use to entry the tables. For directions on the function permissions, confer with Job runtime roles for EMR serverless. - Create an IAM function named
RedshiftS3DataTransferRolefollowing the directions in Conditions for managing Amazon Redshift namespaces within the AWS Glue Knowledge Catalog. - Create an EMR Studio and fix an EMR Serverless namespace in a non-public subnet to it, following the directions in Run interactive workloads on Amazon EMR Serverless from Amazon EMR Studio.
Create knowledge lake tables utilizing an S3 Tables bucket and combine with the lakehouse structure
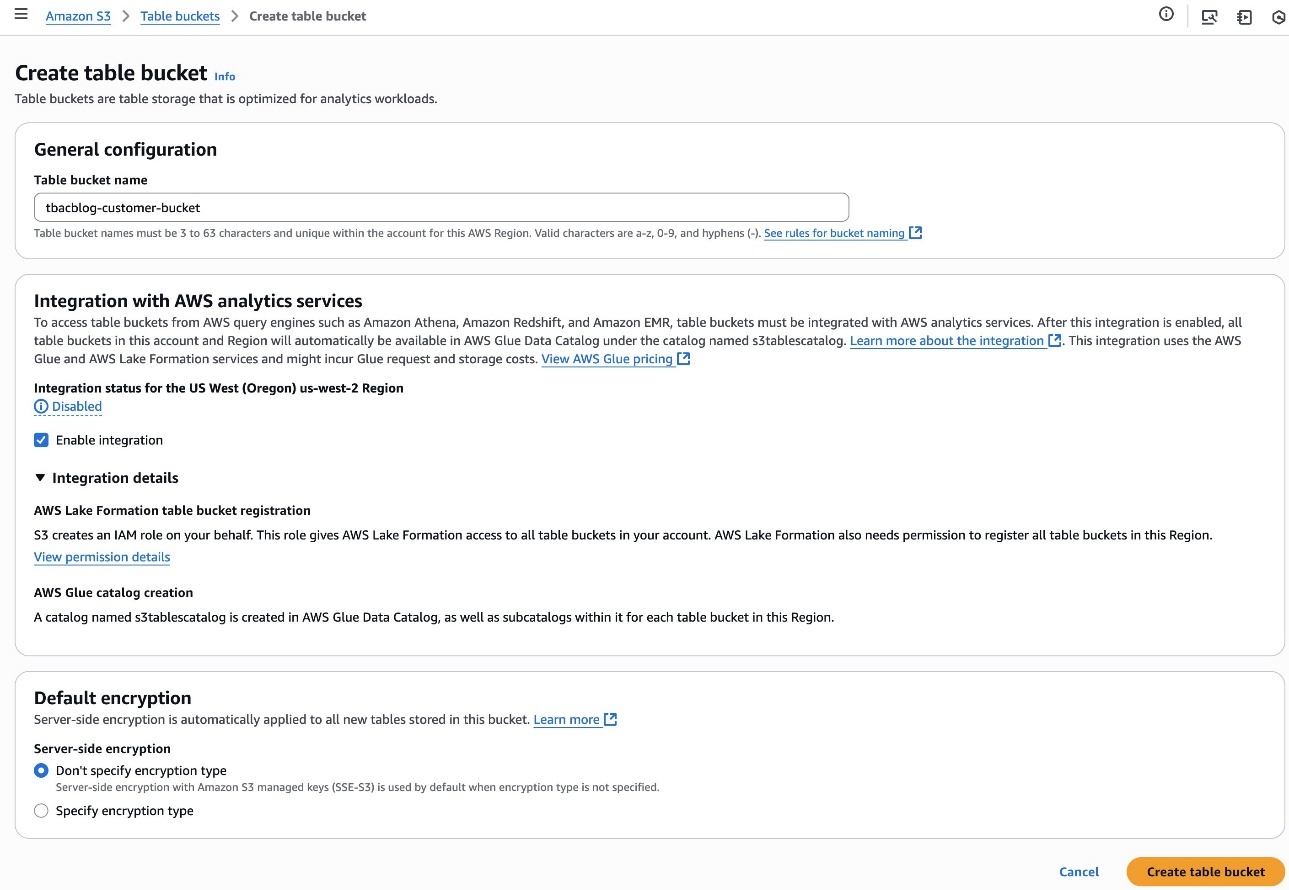
Alice completes the next steps to create a desk bucket and allow integration with analytics providers:
- Sign up to the Amazon S3 console as
LHAdmin. - Select Desk buckets within the navigation pane and create a desk bucket.
- For Desk bucket title, enter a reputation, corresponding to
tbacblog-customer-bucket. - For Integration with AWS analytics providers, select Allow integration.
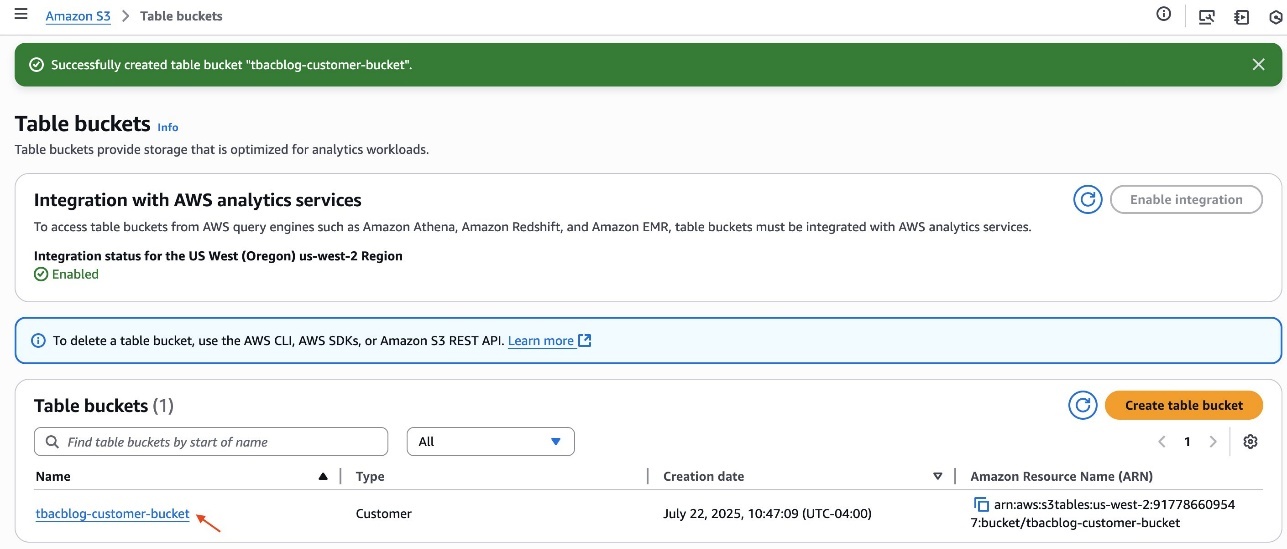
- Select Create desk bucket.

- After you create the desk, click on the hyperlink of the desk bucket title.

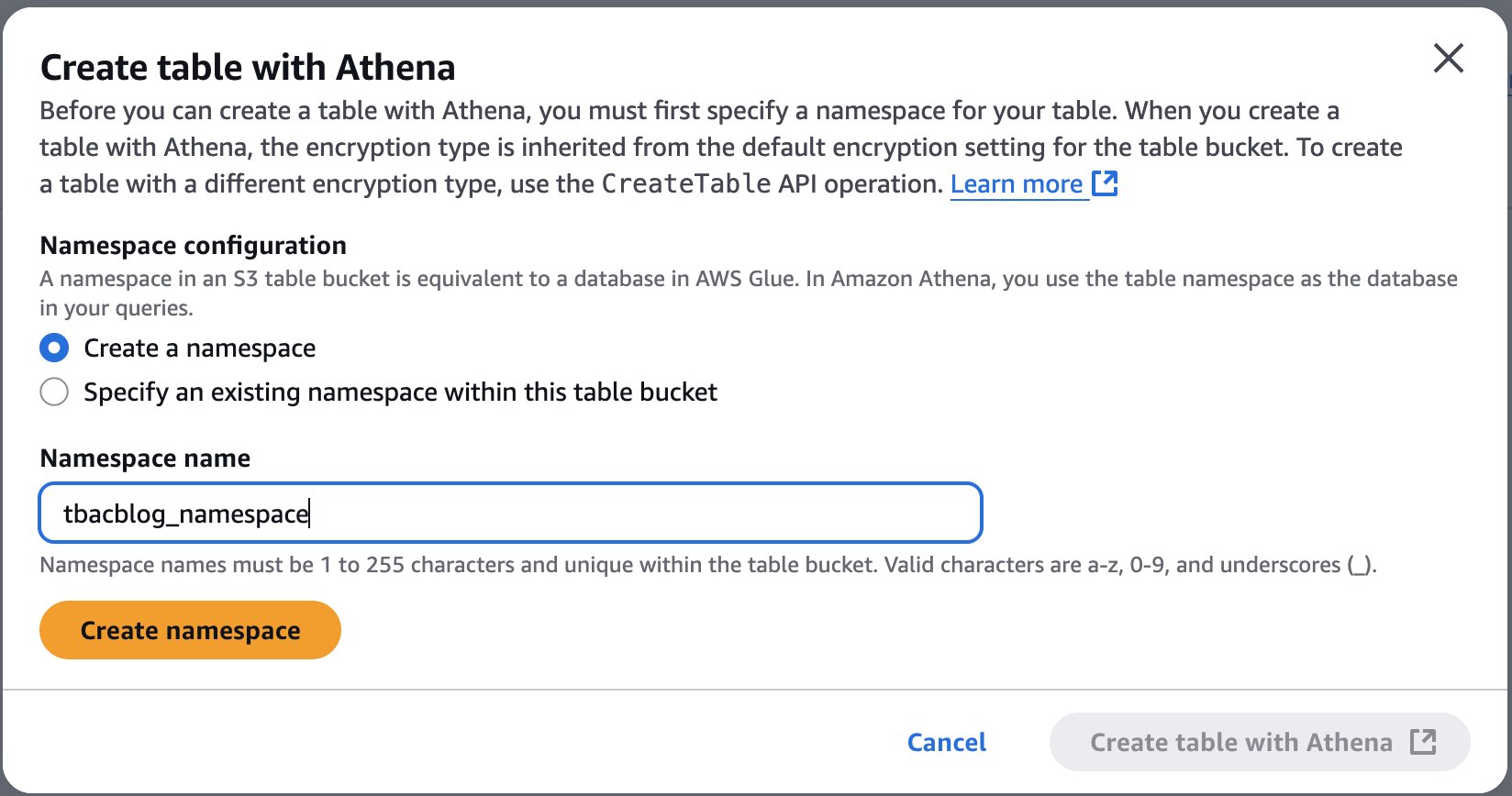
- Select Create desk with Athena.

- Create a namespace and supply a namespace title. For instance,
tbacblog_namespace. - Select Create namespace.

- Now proceed to creating desk schema and populating it by selecting Create desk with Athena.

- On the Athena console, run the next SQL script to create a desk:
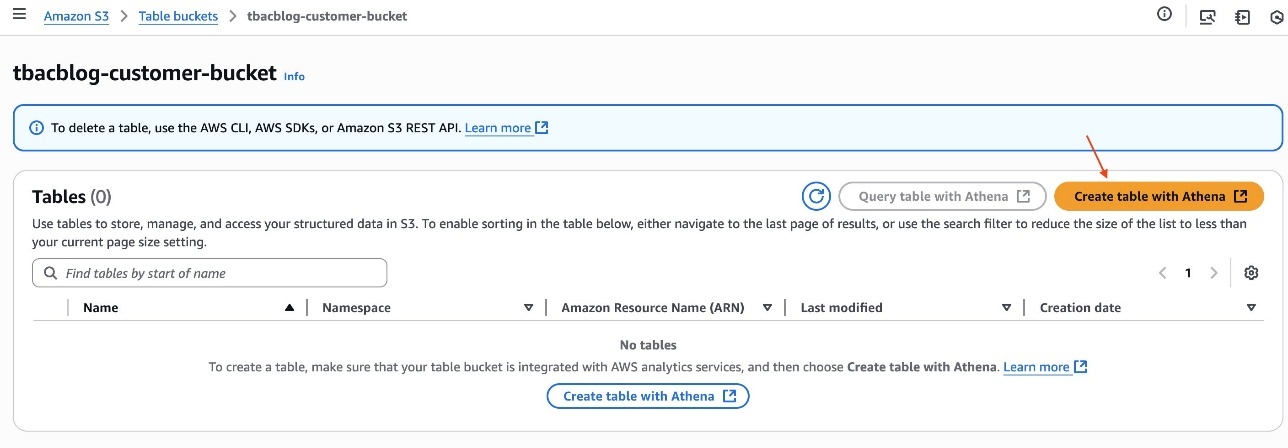
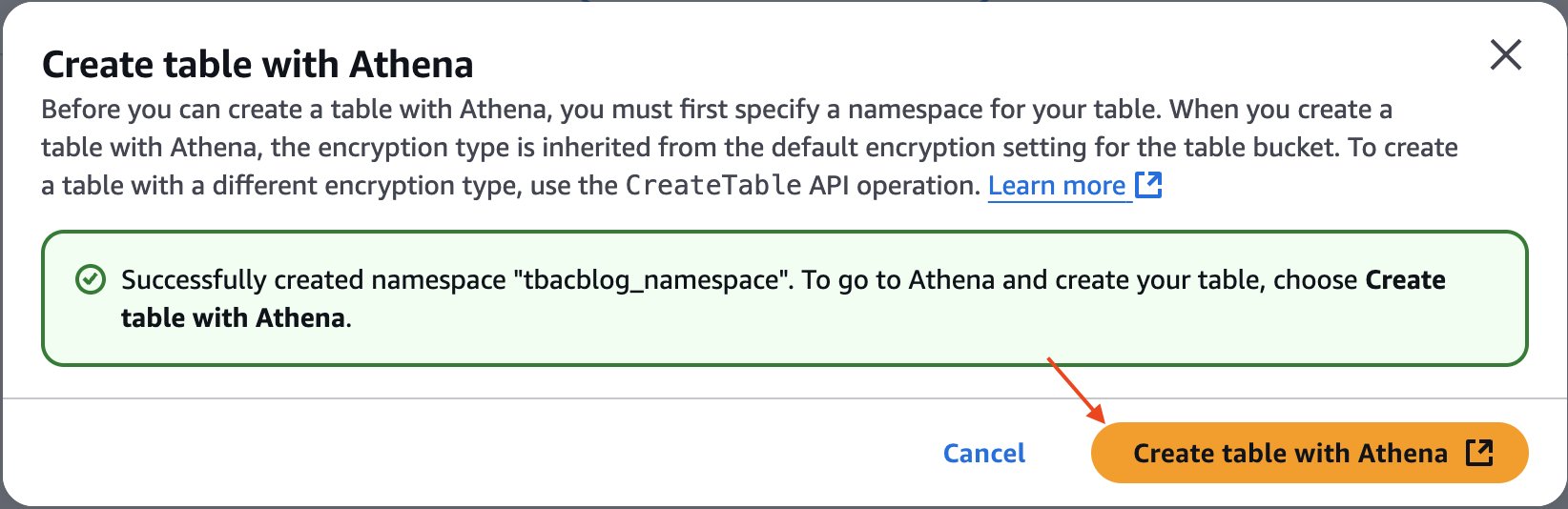
You’ve now created the S3 Tables desk buyer, populated it with knowledge, and built-in it with the lakehouse structure.
Arrange knowledge warehouse tables utilizing Amazon Redshift and combine them with the lakehouse structure
On this part, Alice units up knowledge warehouse tables utilizing Amazon Redshift and integrates them with the lakehouse structure.
Create a Redshift cluster and publish it to the Knowledge Catalog
Alice completes the next steps to create a Redshift cluster and publish it to the Knowledge Catalog:
- Create a Redshift Serverless namespace known as
salescluster. For directions, confer with Get began with Amazon Redshift Serverless knowledge warehouses. - Sign up to the Redshift endpoint
salesclusteras an admin consumer. - Run the next script to create a desk underneath the
devdatabase underneath thepublicschema:
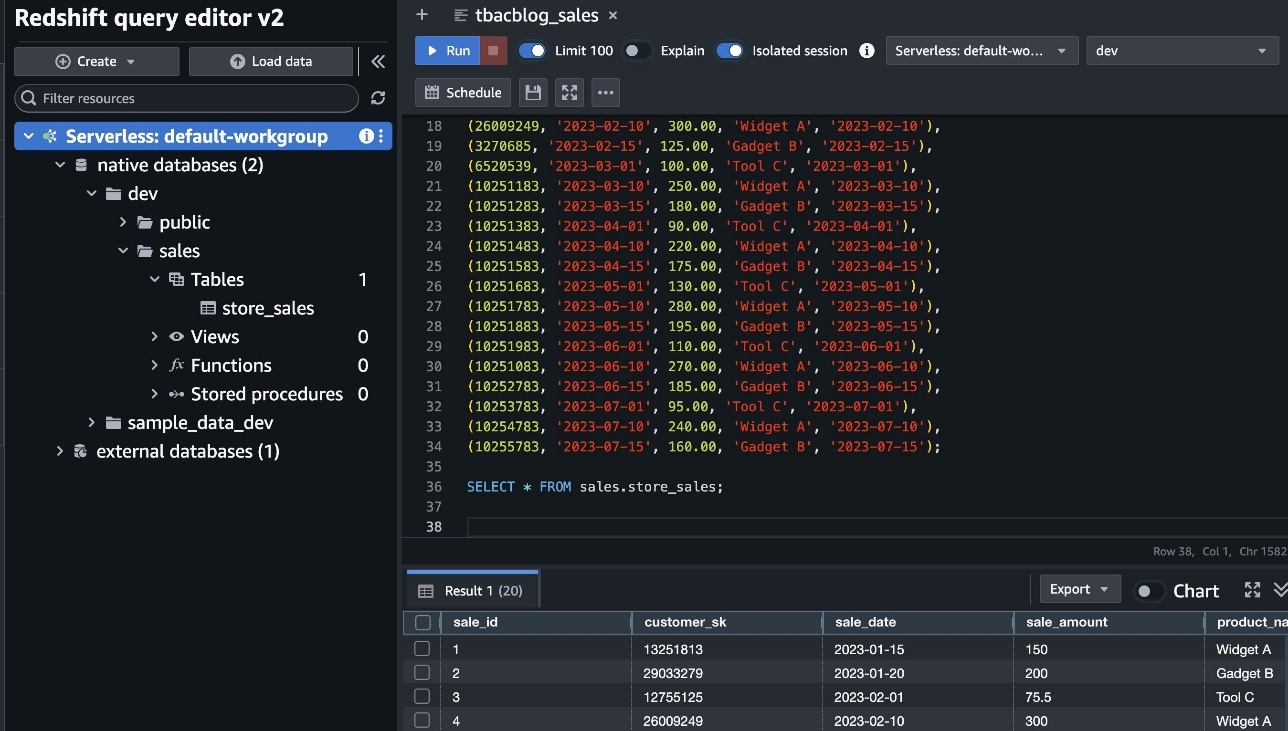
- On the Redshift Serverless console, open the namespace.
- On the Actions dropdown menu, select Register with AWS Glue Knowledge Catalog to combine with the lakehouse structure.
- Choose the identical AWS account and select Register.

Create a catalog for Amazon Redshift
Alice completes the next steps to create a catalog for Amazon Redshift:
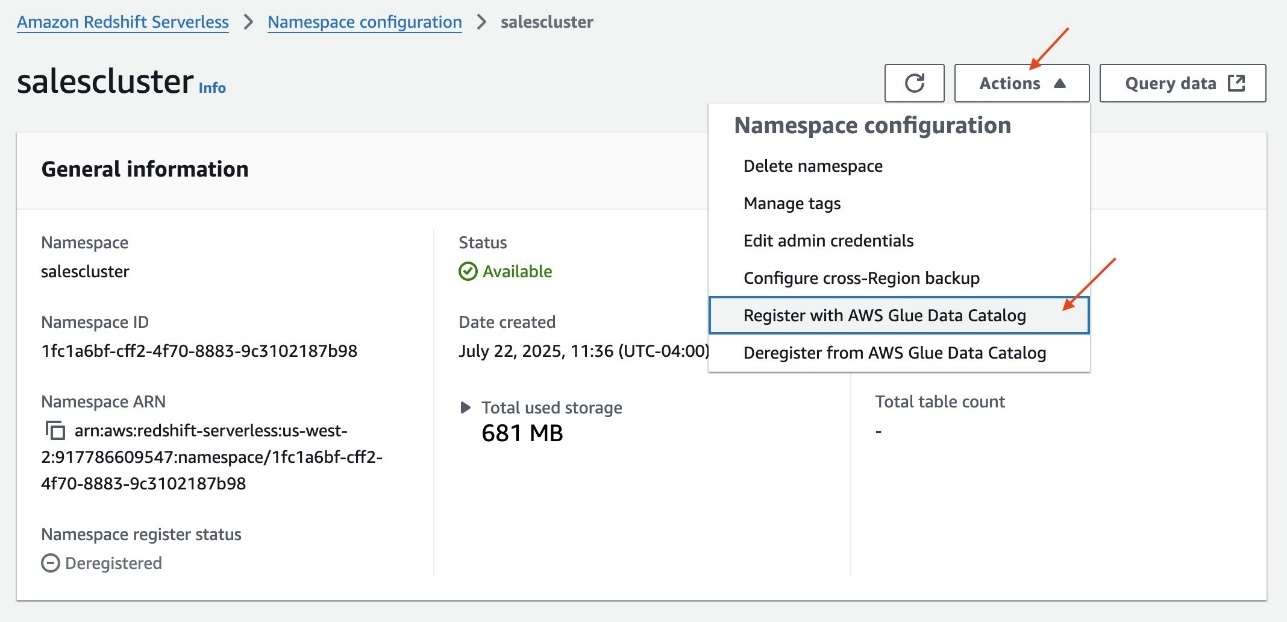
- Sign up to the Lake Formation console as the info lake administrator
LHAdmin. - Within the navigation pane, underneath Knowledge Catalog, select Catalogs.
Beneath Pending catalog invites, you will note the invitation initiated from the Redshift Serverless namespacesalescluster. - Choose the pending invitation and select Approve and create catalog.

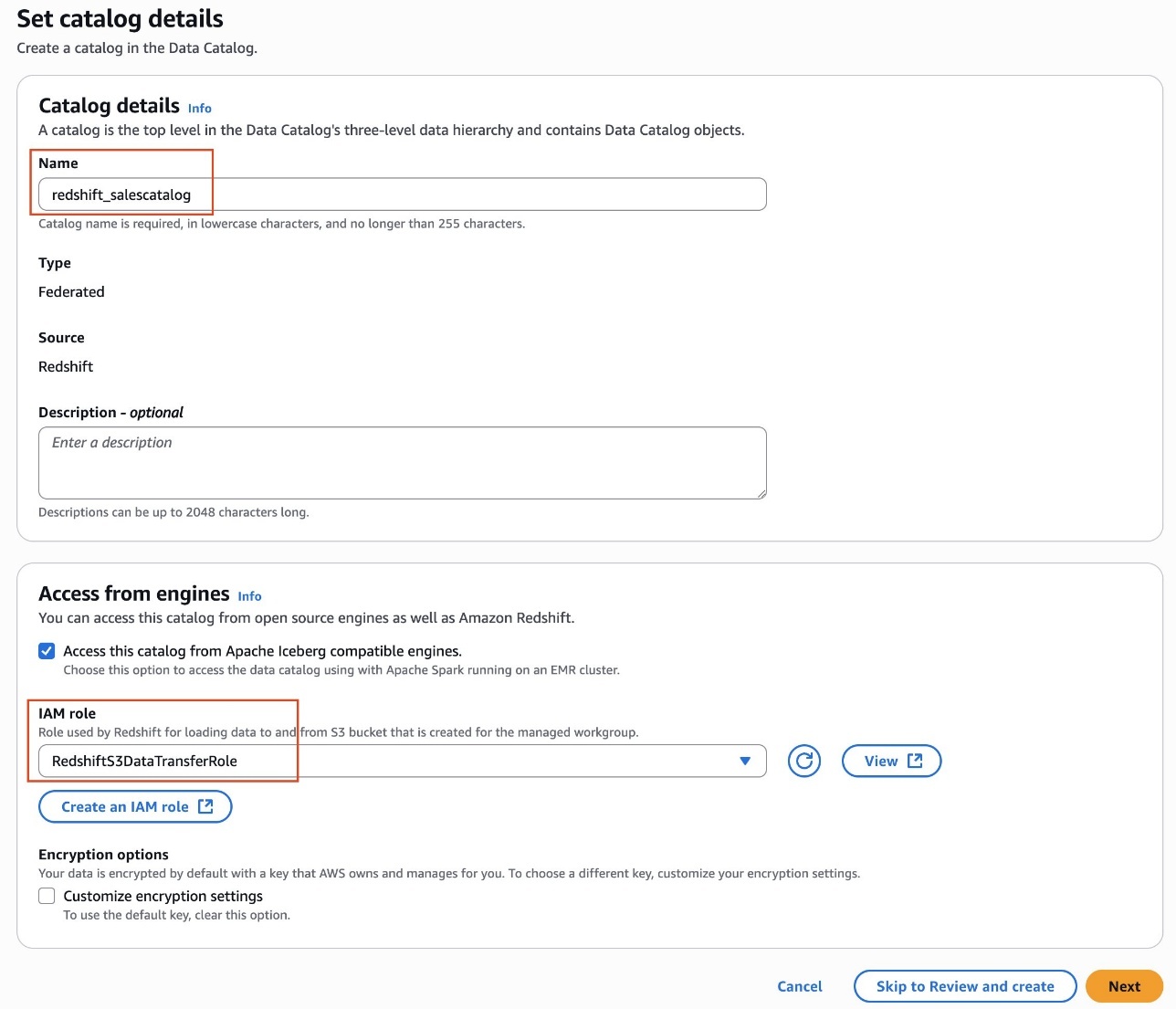
- Present a reputation for the catalog. For instance,
redshift_salescatalog. - Beneath Entry from engines, choose Entry this catalog from Iceberg-compatible engines and select
RedshiftS3DataTransferRolefor IAM function. - Select Subsequent.

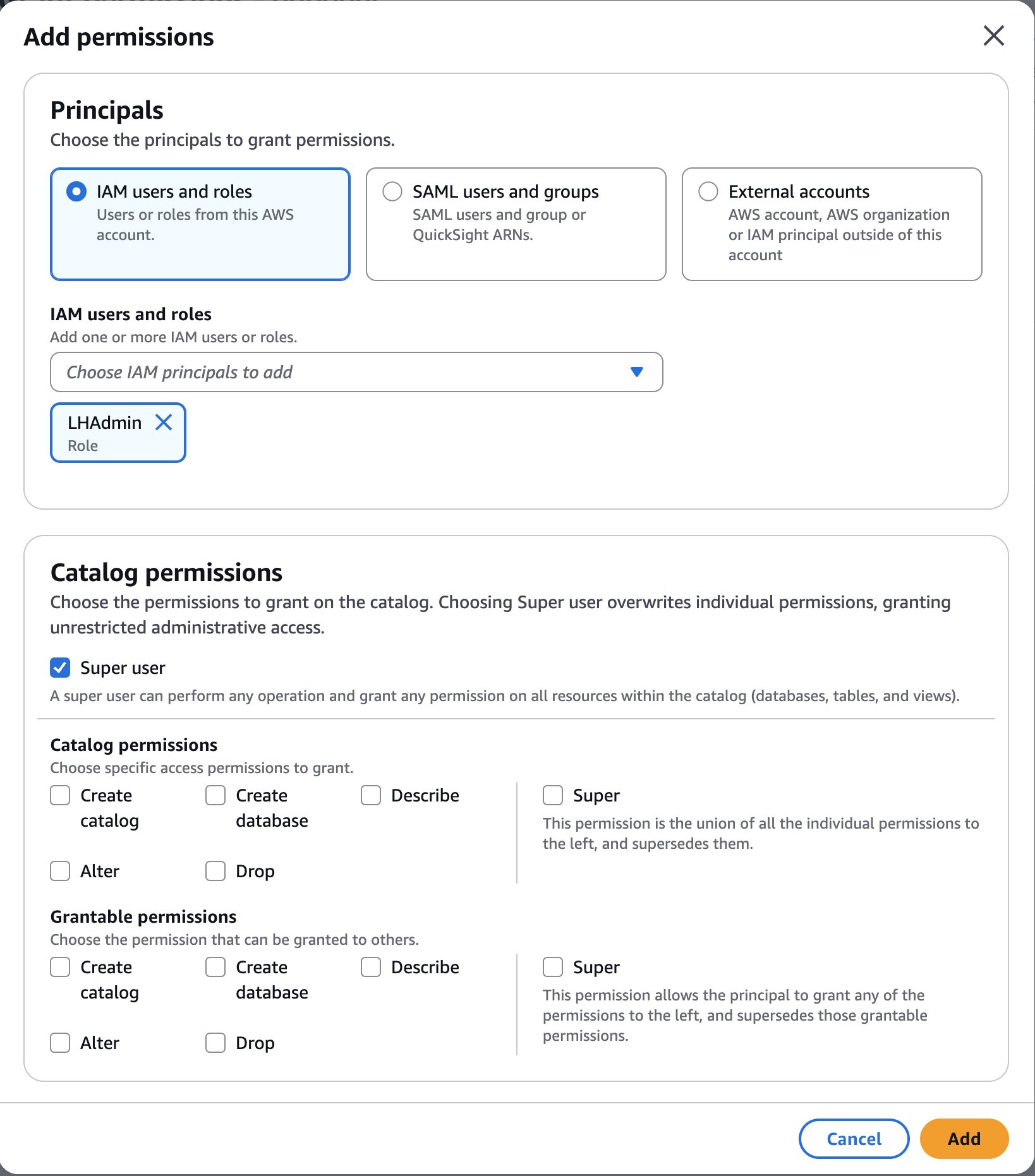
- Select Add permissions.
- Beneath Principals, select the
LHAdminfunction for IAM customers and roles, select Tremendous consumer for Catalog permissions, and select Add.
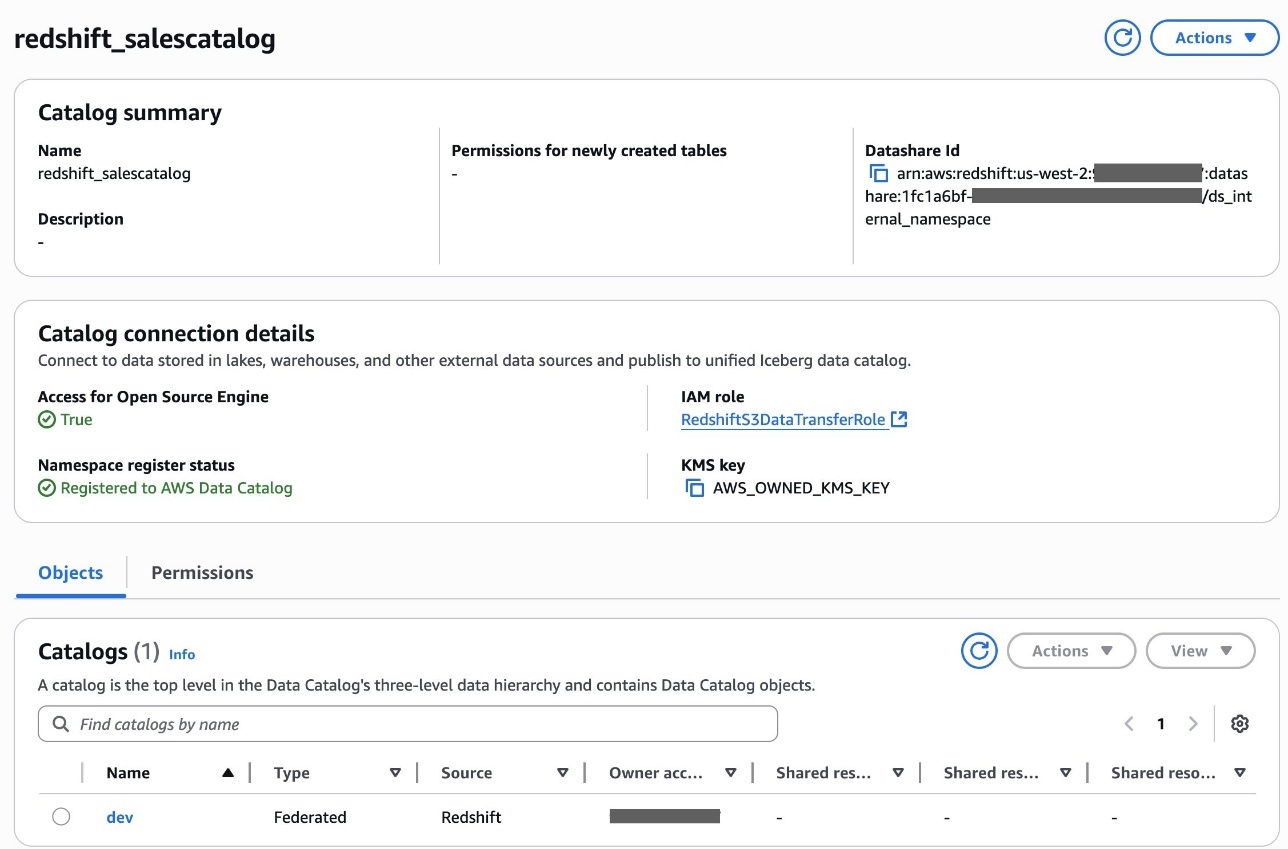
- Select Create catalog.After you create the catalog
redshift_salescatalog, you’ll be able to examine the sub-catalogdev, namespace and databasegross sales, and deskstore_salesbeneath it.

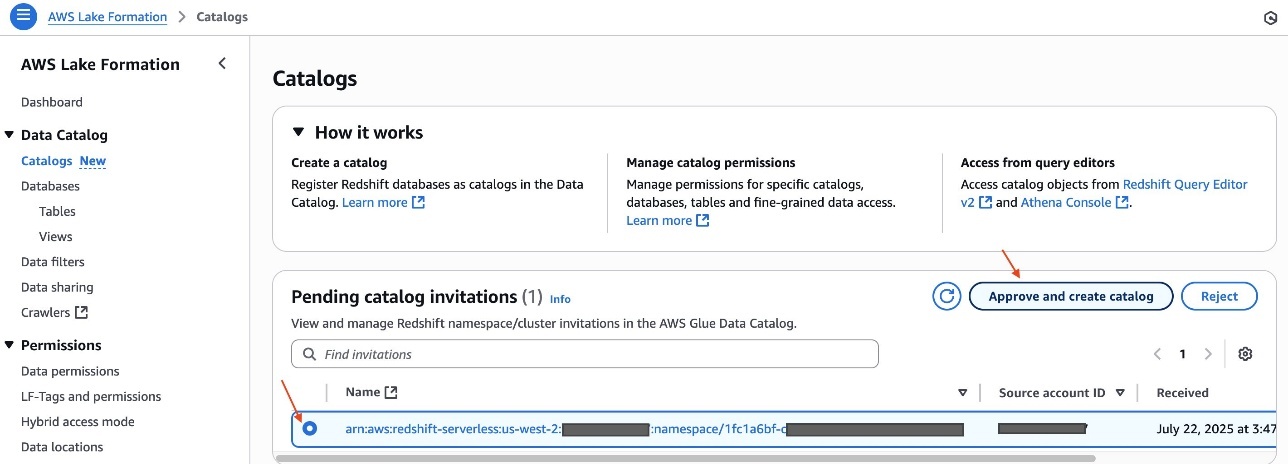
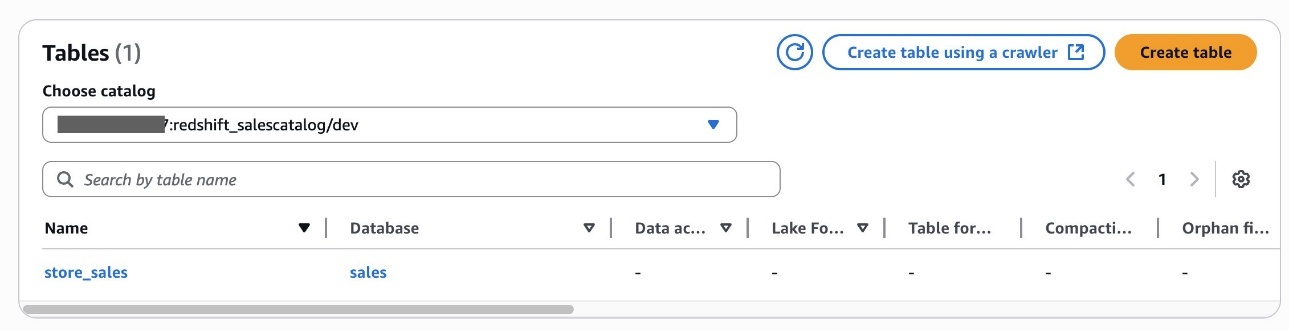
Alice has now accomplished creating an S3table catalog desk and Redshift federated catalog desk within the Knowledge Catalog.
Delegate LF-Tags creation and useful resource permission to the DataSteward function
Alice completes the next steps to delegate LF-Tags creation and useful resource permission to Bob as DataSteward:
- Sign up to the Lake Formation console as the info lake administrator
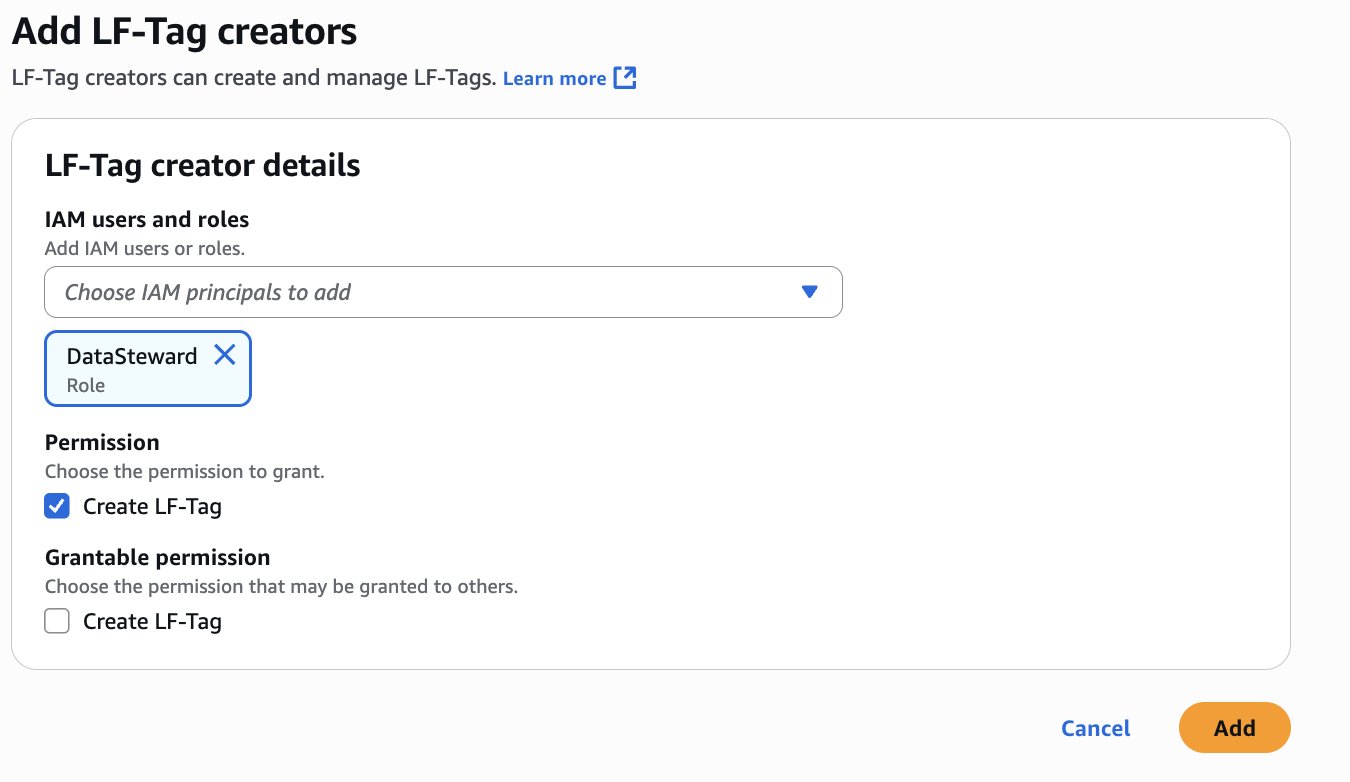
LHAdmin. - Within the navigation pane, select LF Tags and permissions, then select the LF-Tag creators tab.
- Select Add LF-Tag creators.
- Select DataSteward for IAM customers and roles.
- Beneath Permission, choose Create LF-Tag and select Add.

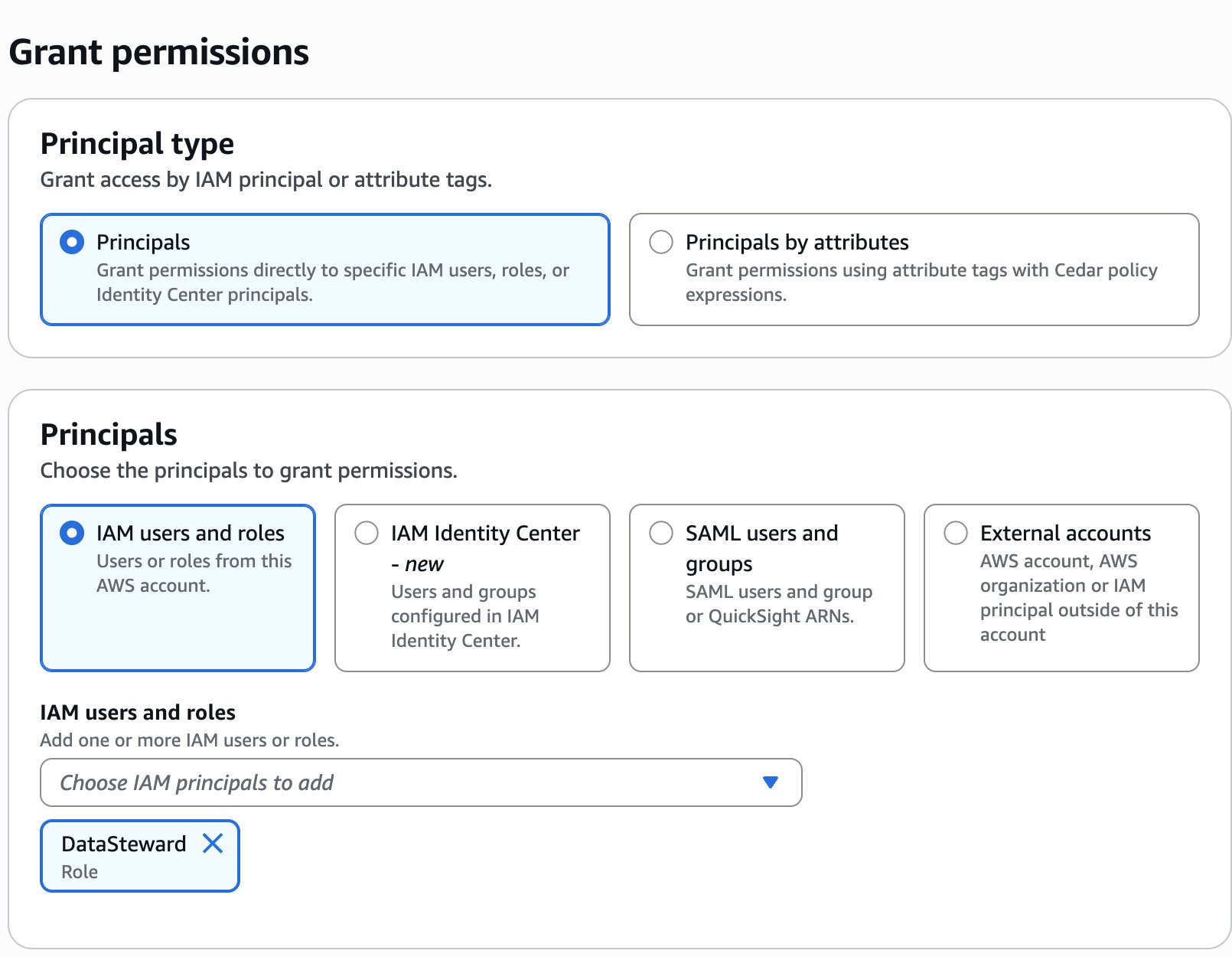
- Within the navigation pane, select Knowledge permissions, then select Grant.
- Within the Principals part, for IAM customers and roles, select the
DataStewardfunction.
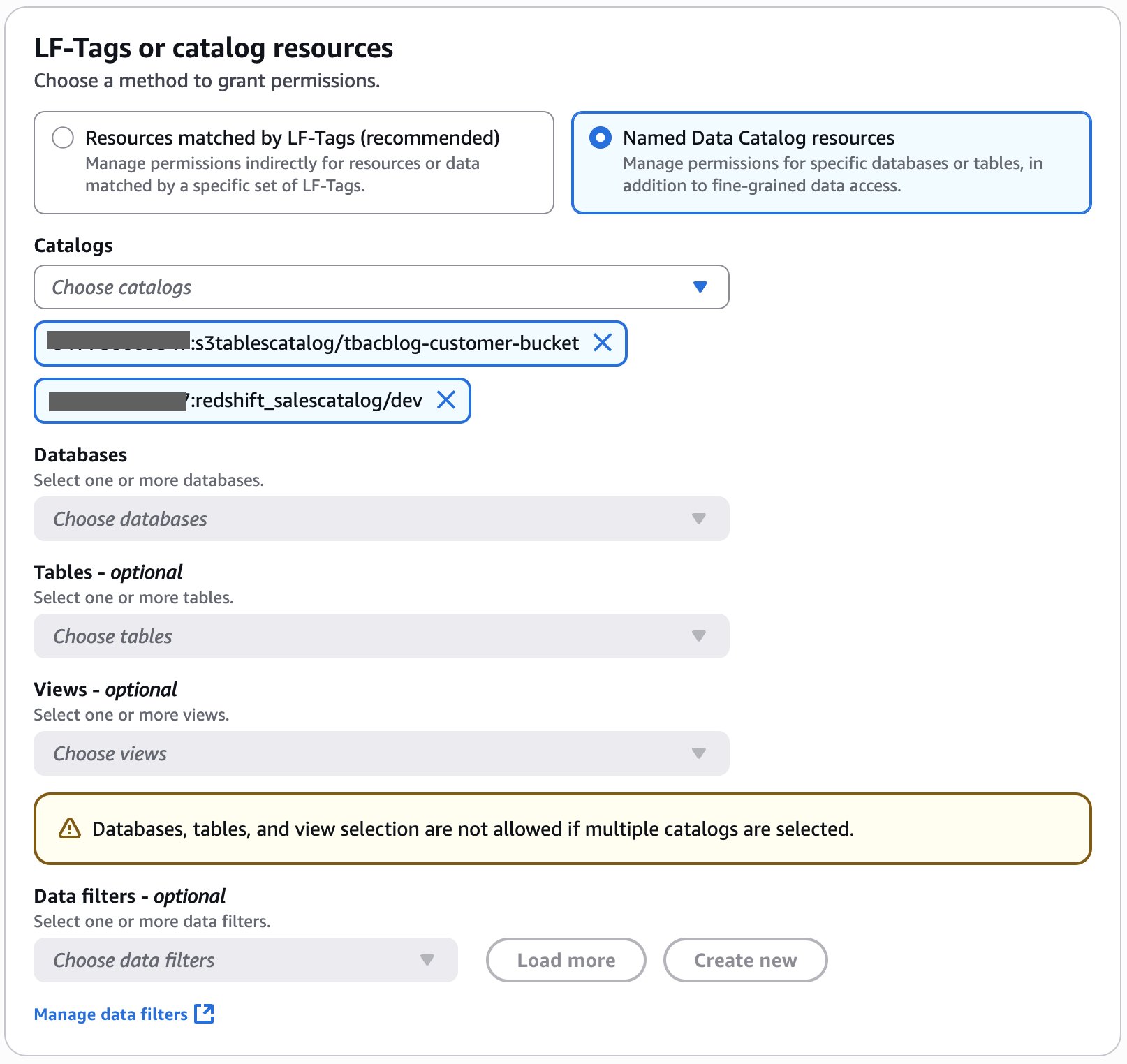
- Within the LF-Tags or catalog sources part, choose Named Knowledge Catalog sources.
- Select
<account_id>:s3tablescatalog/tbacblog-customer-bucketand<account_id>:redshift_salescatalog/devfor Catalogs.
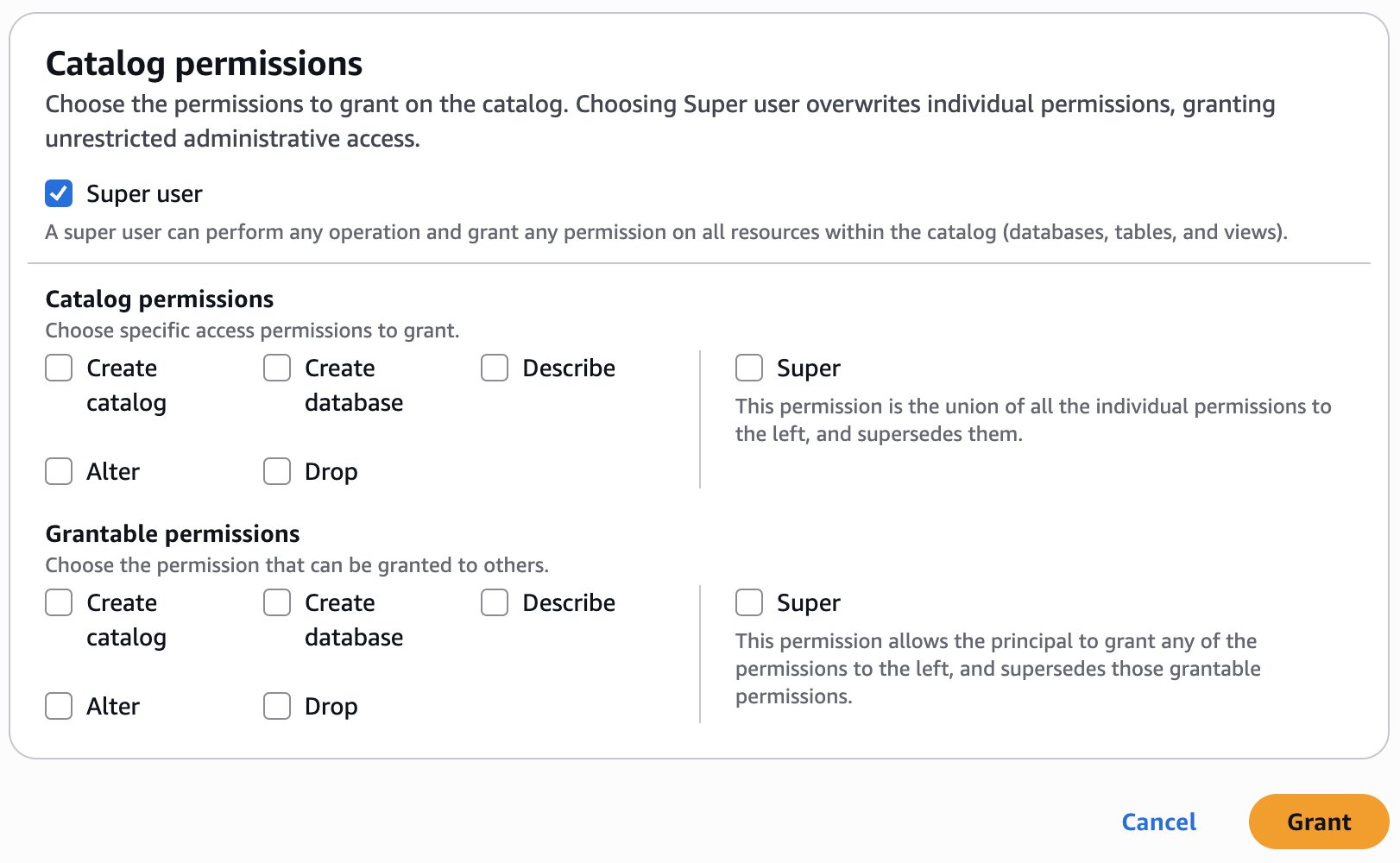
- Within the Catalog permissions part, choose Tremendous consumer for permissions.
- Select Grant.

You possibly can confirm permissions for DataSteward on the Knowledge permissions web page.
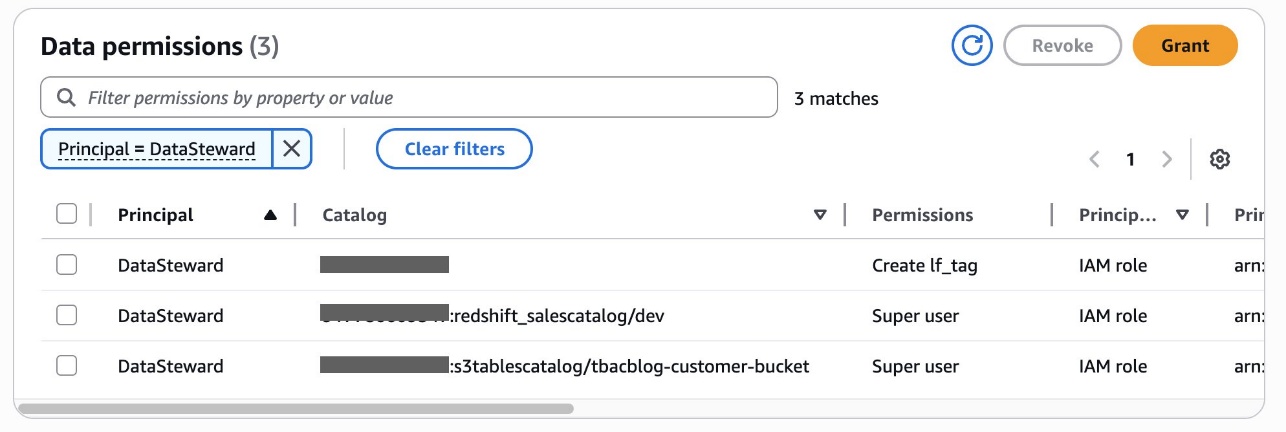
Alice has now accomplished delegating LF-tags creation and project permissions to Bob, the DataSteward. She had additionally granted catalog stage permissions to Bob.
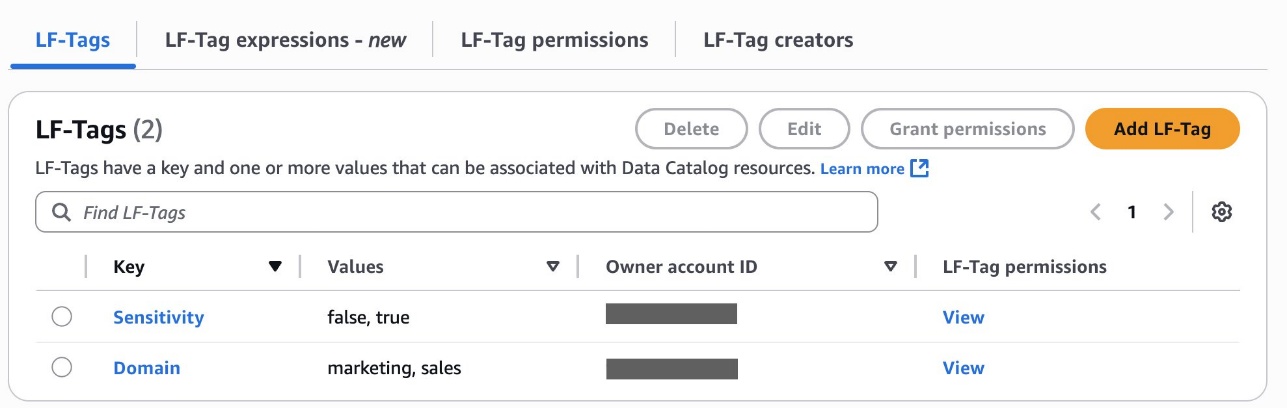
Create LF-Tags
Bob as DataSteward completes the next steps to create LF-Tags:
- Sign up to the Lake Formation console as
DataSteward. - Within the navigation pane, select LF Tags and permissions, then select the LF-tags tab.
- Select Add-LF-Tag.
- Create LF tags as follows:
- Key:
Areaand Values:gross sales,advertising - Key:
Sensitivityand Values:true,false
- Key:
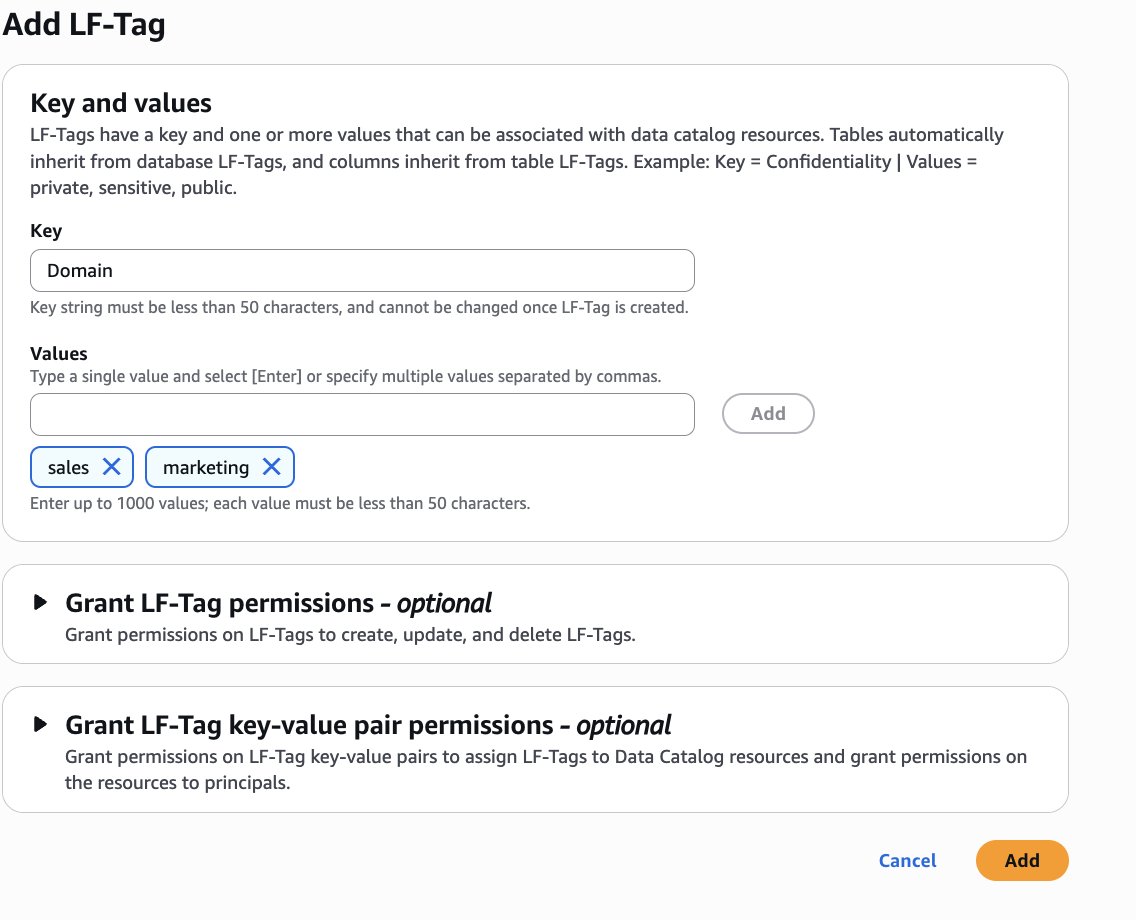
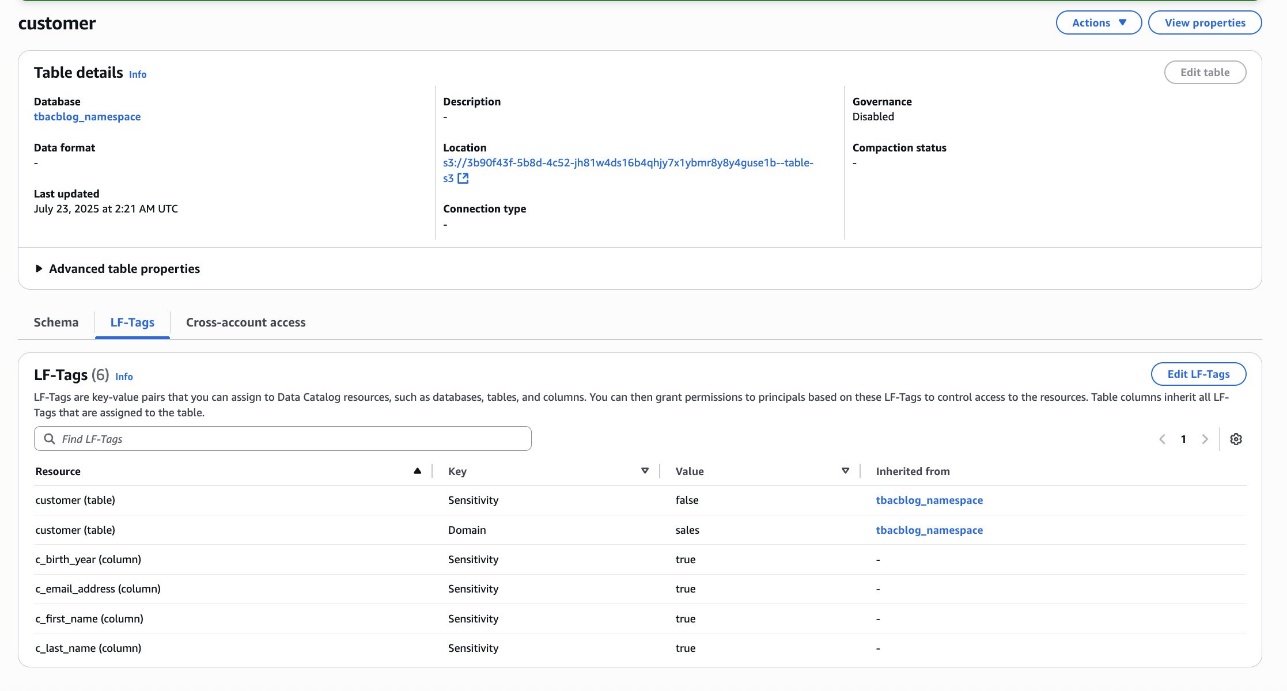
Assign LF-Tags to the S3 Tables database and desk
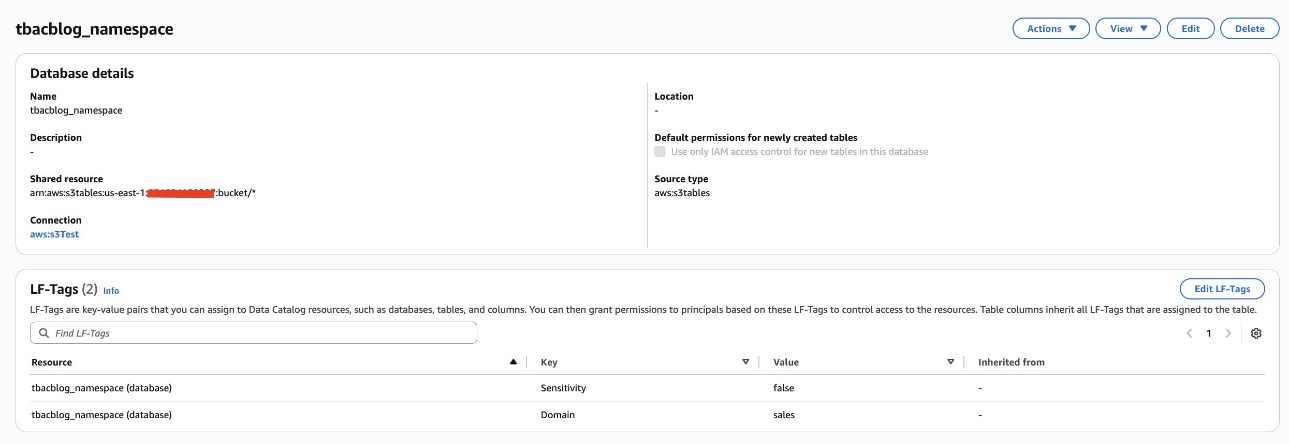
Bob as DataSteward completes the next steps to assign LF-Tags to the S3 Tables database and desk:
- Within the navigation pane, select Catalogs and select
s3tablescatalog. - Select
tbacblog-customer-bucketand selecttbacblog_namespace. - Select Edit LF-Tags.
- Assign the next tags:
- Key: Area and Worth: gross sales
- Key: Sensitivity and Worth: false
- Select Save.

- On the View dropdown menu, select Tables.
- Select the shopper desk and select the Schema tab.
- Select Edit schema and choose the columns
c_first_name,c_last_name,c_email_address, andc_birth_year. - Select Edit LF-Tags and modify the tag worth:
- Key:
Sensitivityand Worth:true
- Key:
- Select Save.

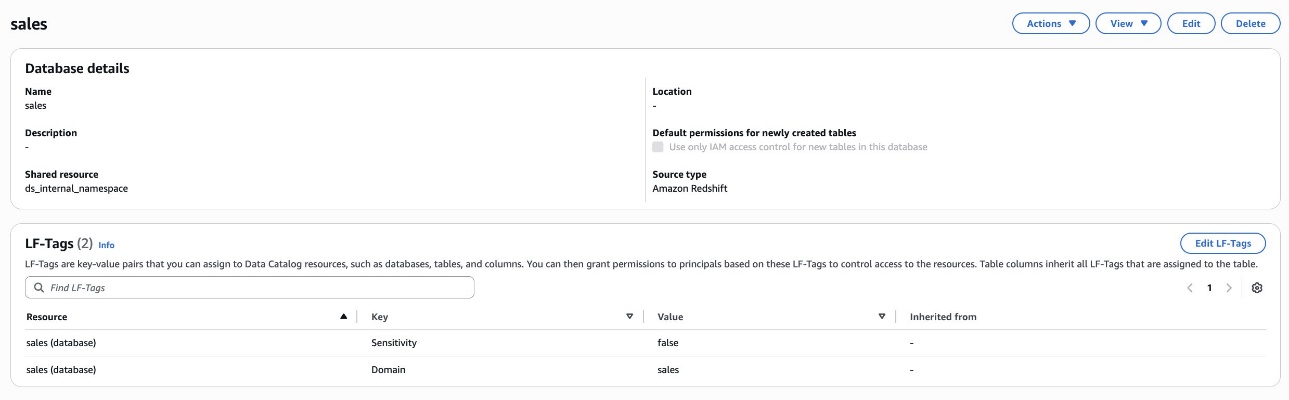
Assign LF-Tags to the Redshift database and desk
Bob as DataSteward completes the next steps to assign LF-Tags to the Redshift database and desk:
- Within the navigation pane, select Catalogs and select
salescatalog. - Select
devand choosegross sales. - Select Edit LF-Tags and assign the next tags:
- Key:
Areaand Worth:gross sales - Key:
Sensitivityand Worth:false
- Key:
- Select Save.

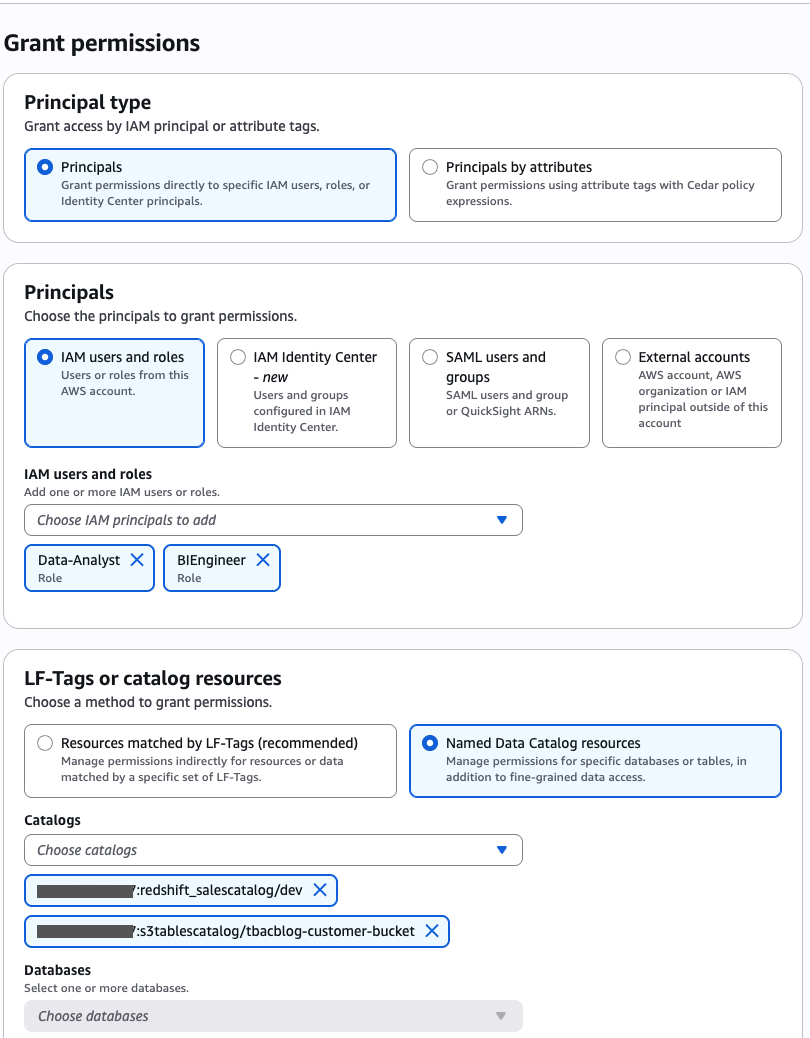
Grant catalog permission to the DataAnalyst and BIEngineer roles
Bob as DataSteward completes the next steps to grant catalog permission to the DataAnalyst and BIEngineer roles (Charlie and Doug, respectively):
- Within the navigation pane, select Datalake permissions, then select Grant.
- Within the Principals part, for IAM customers and roles, select the
DataAnalystandBIEngineerroles. - Within the LF-Tags or catalog sources part, choose Named Knowledge Catalog sources.
- For Catalogs, select
<account_id>:s3tablescatalog/tbacblog-customer-bucketand<account_id>:salescatalog/dev.
- Within the Catalog permissions part, select Describe for permissions.
- Select Grant.

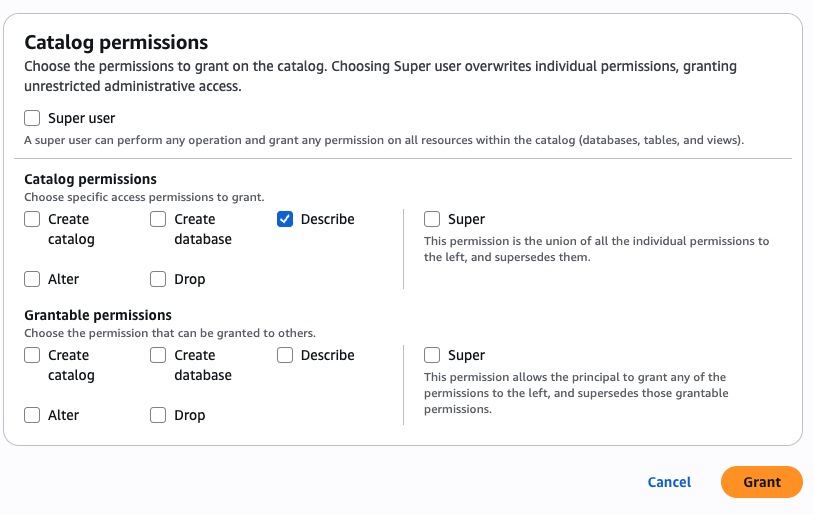
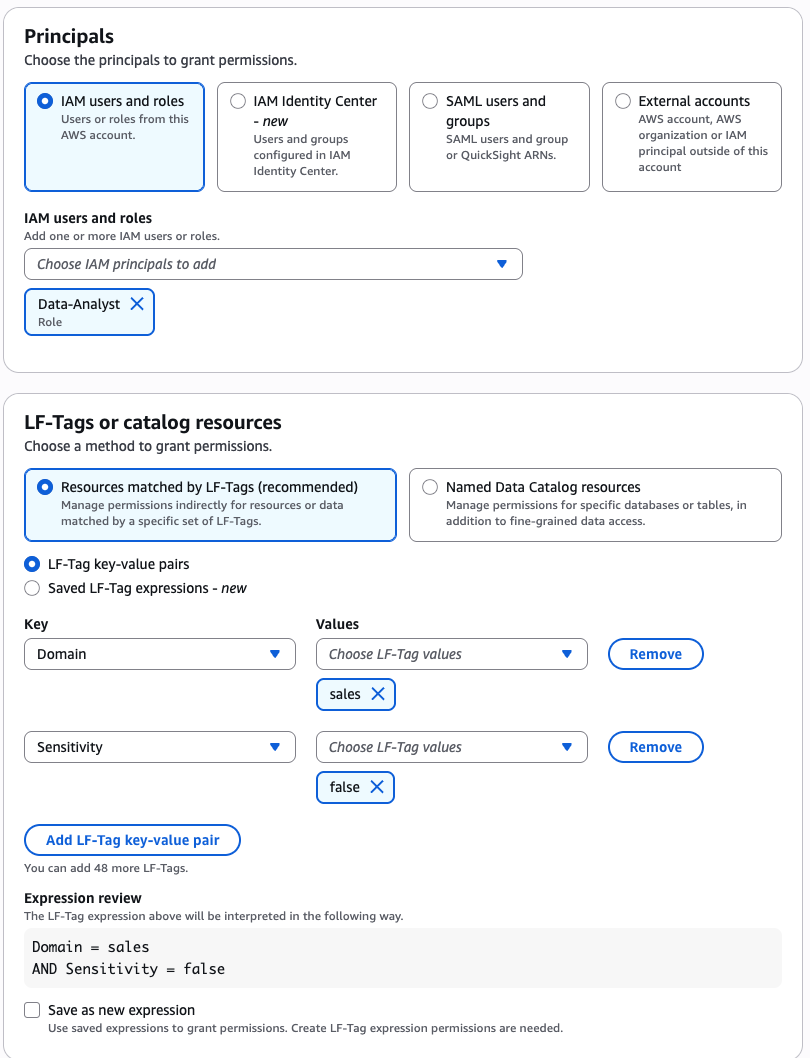
Grant permission to the DataAnalyst function for the gross sales area and non-sensitive knowledge
Bob as DataSteward completes the next steps to grant permission to the DataAnalyst function (Charlie) for the gross sales area for non-sensitive knowledge:
- Within the navigation pane, select Datalake permissions, then select Grant.
- Within the Principals part, for IAM customers and roles, select the
DataAnalystfunction. - Within the LF-Tags or catalog sources part, choose Sources matched by LF-Tags and supply the next values:
- Key:
Areaand Worth:gross sales - Key:
Sensitivityand Worth:false

- Key:
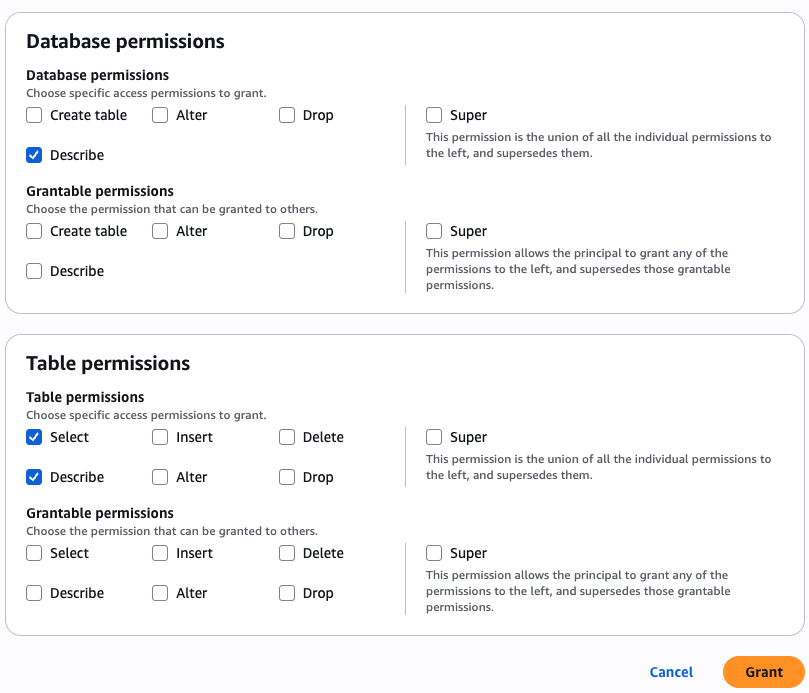
- Within the Database permissions part, select Describe for permissions.
- Within the Desk permissions part, choose Choose and Describe for permissions.
- Select Grant.

Grant permission to the BIEngineer function for gross sales area knowledge
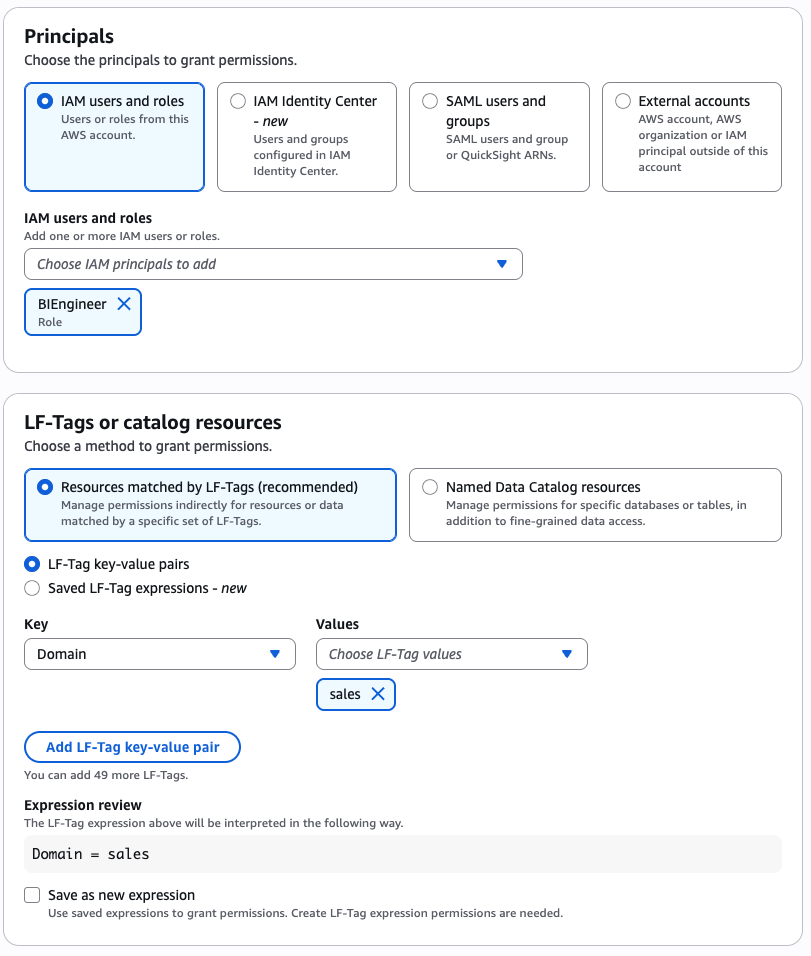
Bob as DataSteward completes the next steps to grant permission to the BIEngineer function (Doug) for all gross sales area knowledge:
- Within the navigation pane, select Datalake permissions, then select Grant.
- Within the Principals part, for IAM customers and roles, select the
BIEngineerfunction. - Within the LF-Tags or catalog sources part, choose Sources matched by LF-Tags and supply the next values:
- Key:
Areaand Worth:gross sales
- Key:
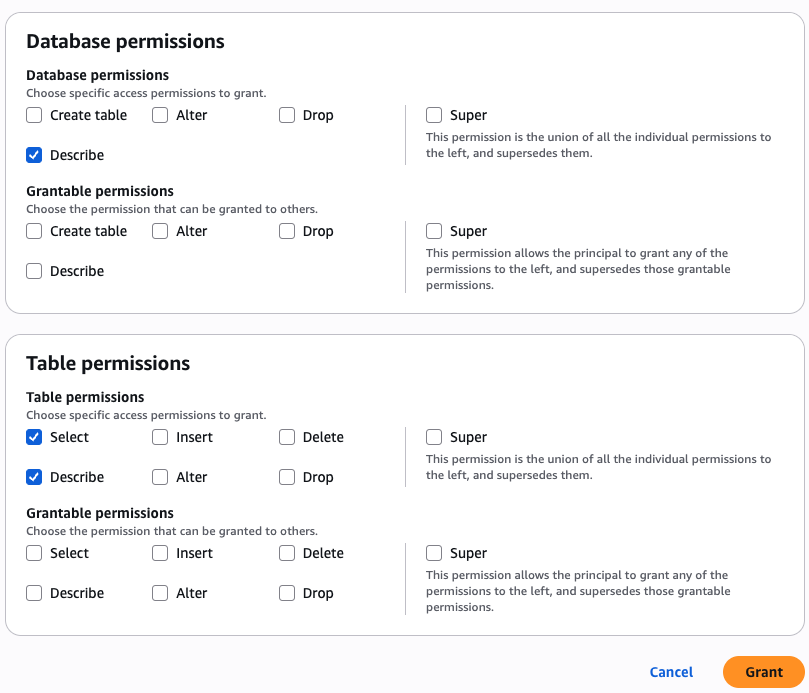
- Within the Database permissions part, select Describe for permissions.
- Within the Desk permissions part, choose Choose and Describe for permissions.
- Select Grant.
{kind=link}
This completes the steps to grant S3 Tables and Redshift federated tables permissions to numerous knowledge personas utilizing LF-TBAC.
Confirm knowledge entry
On this step, we log in as particular person knowledge personas and question the lakehouse tables which can be accessible to every persona.
Use Athena to investigate buyer info because the DataAnalyst function
Charlie indicators in to the Athena console because the DataAnalyst function. He runs the next pattern SQL question:
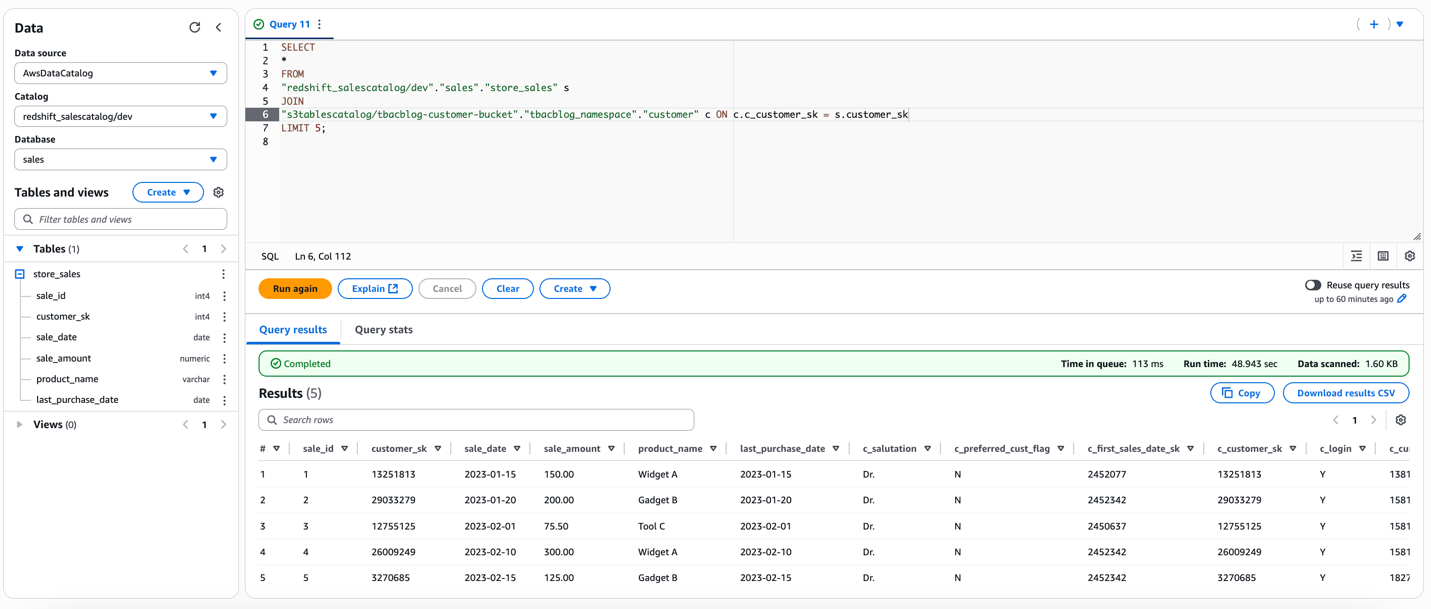
Run a pattern question to entry the 4 columns within the S3table buyer that DataAnalyst doesn’t have entry to. You need to obtain an error as proven within the screenshot. This verifies column stage superb grained entry utilizing LF-tags on the lakehouse tables.
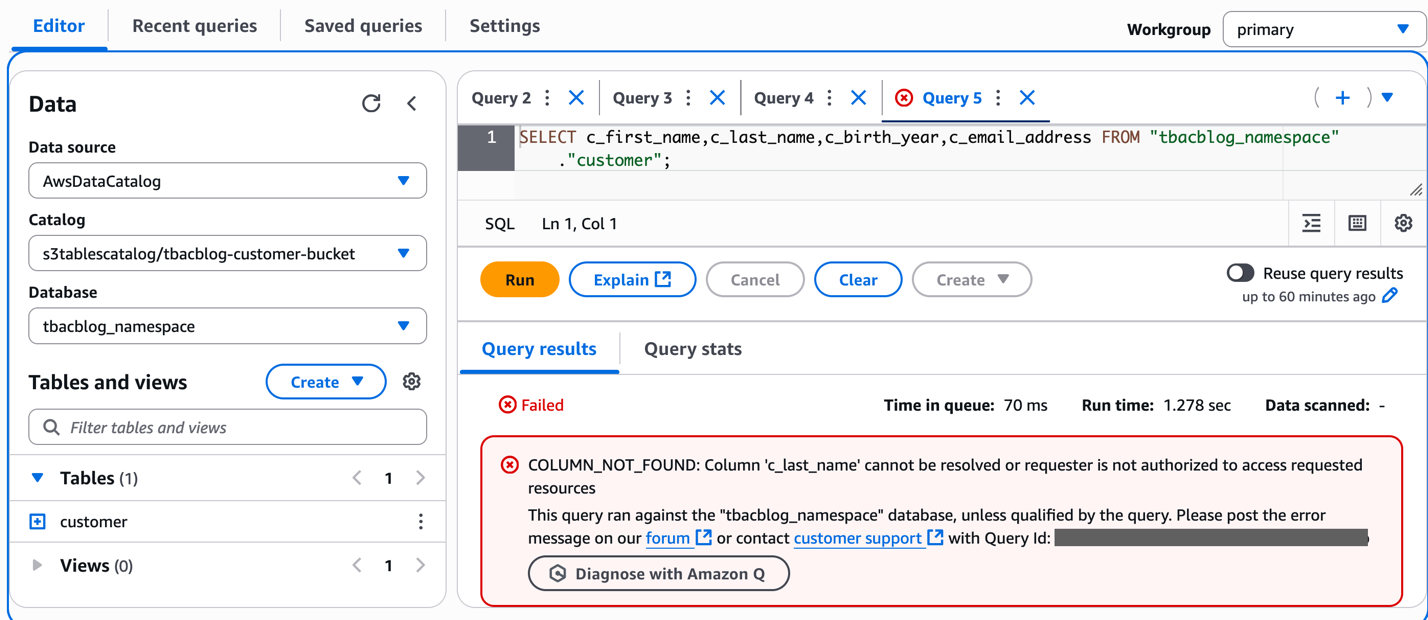
Use the Redshift question editor to investigate buyer knowledge because the DataAnalyst function
Charlie indicators in to the Redshift question editor v2 because the DataAnalyst function and runs the next pattern SQL question:
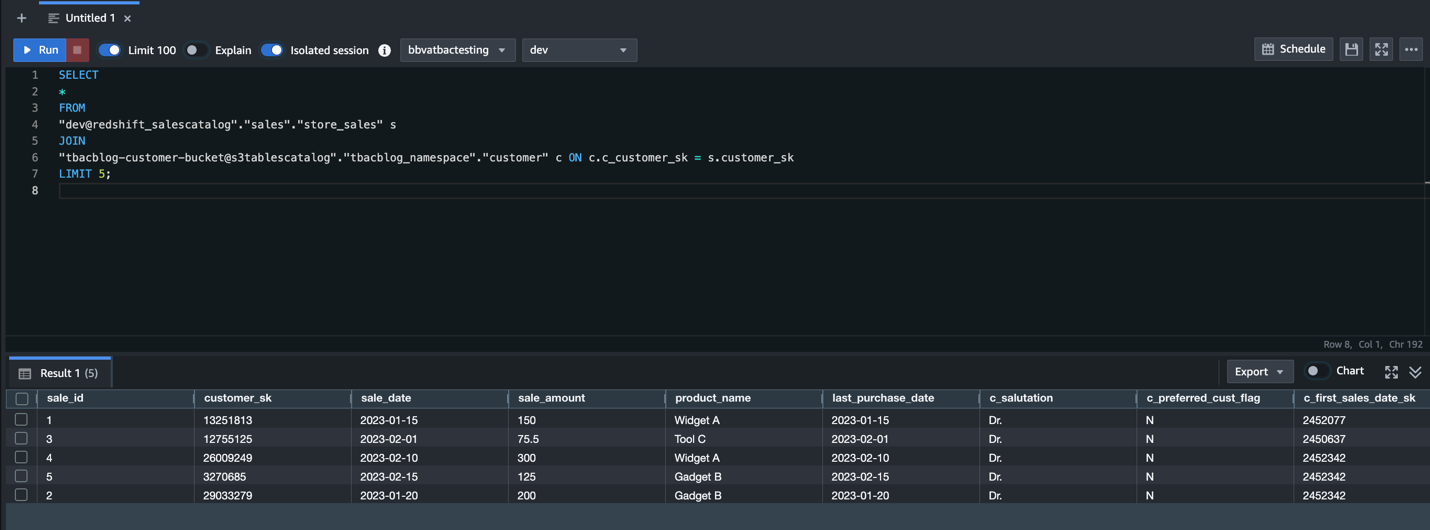
This verifies the DataAnalyst entry to the lakehouse tables with LF-tags primarily based permissions, utilizing Redshift Spectrum
Use Amazon EMR to course of buyer knowledge because the BIEngineer function
Doug makes use of Amazon EMR to course of buyer knowledge with the BIEngineer function:
- Signal-in to the EMR Studio as Doug, with
BIEngineerfunction. Guarantee EMR Serverless utility is hooked up to the workspace withBIEngineerbecause the EMR runtime function.
Obtain the PySpark pocket book tbacblog_emrs.ipynb. Add to your studio surroundings. - Change the account id, AWS Area and useful resource names as per your setup. Restart kernel and clear output.
- As soon as your pySpark kernel is prepared, run the cells and confirm entry.This verifies entry utilizing LF-tags to the lakehouse tables because the EMR runtime function. For demonstration, we’re additionally offering the pySpark script tbacblog_sparkscript.py that you could run as EMR batch job and Glue 5.0 ETL.
Doug has additionally arrange Amazon SageMaker Unified Studio as lined within the weblog publish Speed up your analytics with Amazon S3 Tables and Amazon SageMaker Lakehouse. Doug logs in to SageMaker Unified Studio and choose beforehand created venture to carry out his evaluation. He navigates to the Construct choices and select JupyterLab underneath IDE & Purposes. He makes use of the downloaded pyspark pocket book and updates it as per his Spark question necessities. He then runs the cells by choosing compute as venture.spark.fineGrained.
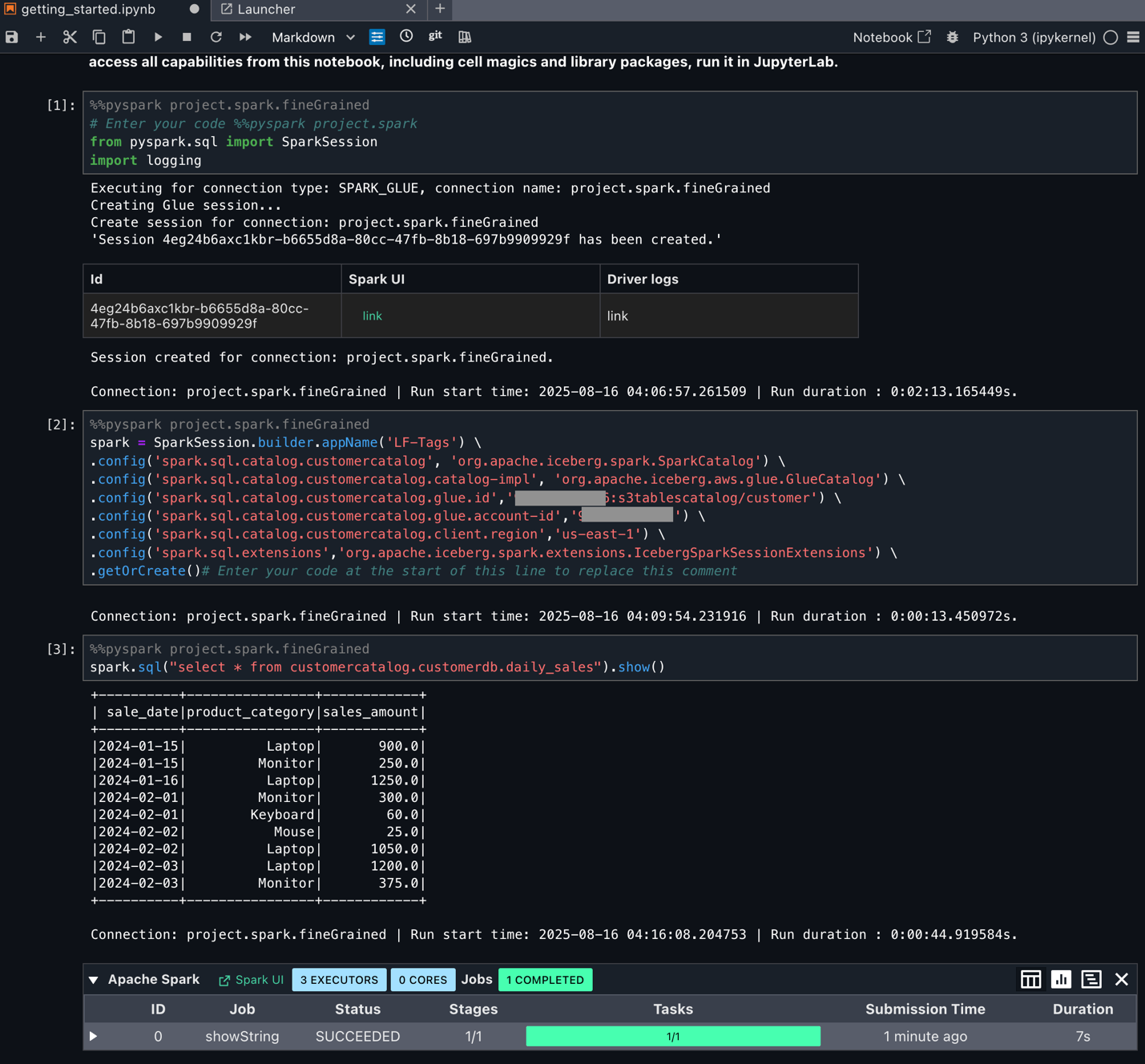
Doug can now begin utilizing Spark SQL and begin processing knowledge as per superb grained entry managed by the Tags.
Clear up
Full the next steps to delete the sources you created to keep away from sudden prices:
- Delete the Redshift Serverless workgroups.
- Delete the Redshift Serverless related namespace.
- Delete the EMR Studio and EMR Serverless occasion.
- Delete the AWS Glue catalogs, databases, and tables and Lake Formation permissions.
- Delete the S3 Tables bucket.
- Empty and delete the S3 bucket.
- Delete the IAM roles created for this publish.
Conclusion
On this publish, we demonstrated how you need to use Lake Formation tag-based entry management with the SageMaker lakehouse structure to realize unified and scalable permissions to your knowledge warehouse and knowledge lake. Now directors can add entry permissions to federated catalogs utilizing attributes and tags, creating automated coverage enforcement that scales naturally as new belongings are added to the system. This eliminates the operational overhead of guide coverage updates. You should use this mannequin for sharing sources throughout accounts and Areas to facilitate knowledge sharing inside and throughout enterprises.
We encourage AWS knowledge lake clients to do this function and share your suggestions within the feedback. To study extra about tag-based entry management, go to the Lake Formation documentation.
Acknowledgment: A particular due to everybody who contributed to the event and launch of TBAC: Joey Ghirardelli, Xinchi Li, Keshav Murthy Ramachandra, Noella Jiang, Purvaja Narayanaswamy, Sandya Krishnanand.
Concerning the Authors
 Sandeep Adwankar is a Senior Product Supervisor with Amazon SageMaker Lakehouse . Based mostly within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise that assist clients enhance how they handle, safe, and entry knowledge.
Sandeep Adwankar is a Senior Product Supervisor with Amazon SageMaker Lakehouse . Based mostly within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise that assist clients enhance how they handle, safe, and entry knowledge.
 Srividya Parthasarathy is a Senior Huge Knowledge Architect with Amazon SageMaker Lakehouse. She works with the product staff and clients to construct sturdy options and options for his or her analytical knowledge platform. She enjoys constructing knowledge mesh options and sharing them with the neighborhood.
Srividya Parthasarathy is a Senior Huge Knowledge Architect with Amazon SageMaker Lakehouse. She works with the product staff and clients to construct sturdy options and options for his or her analytical knowledge platform. She enjoys constructing knowledge mesh options and sharing them with the neighborhood.
 Aarthi Srinivasan is a Senior Huge Knowledge Architect with Amazon SageMaker Lakehouse. She works with AWS clients and companions to architect lakehouse options, improve product options, and set up greatest practices for knowledge governance.
Aarthi Srinivasan is a Senior Huge Knowledge Architect with Amazon SageMaker Lakehouse. She works with AWS clients and companions to architect lakehouse options, improve product options, and set up greatest practices for knowledge governance.