
: A Novel AI Structure Incorporating a Devoted Temporal Encoder between the Picture Encoder and the LLM")
{kind=link}
Understanding movies with AI requires dealing with sequences of photos effectively. A serious problem in present video-based AI fashions is their incapacity to course of movies as a steady circulate, lacking vital movement particulars and disrupting continuity. This lack of temporal modeling prevents tracing modifications; subsequently, occasions and interactions are partially unknown. Lengthy movies additionally make the method troublesome, with excessive computational bills and requiring strategies like body skipping, which loses priceless data and reduces accuracy. Overlap amongst knowledge inside frames additionally doesn’t compress nicely, leading to redundancy and wastage of sources.
At the moment, video-language fashions deal with movies as static body sequences with picture encoders and vision-language projectors, which is difficult to symbolize movement and continuity. Language fashions should infer temporal relations independently, leading to partial comprehension. Subsampling of frames reduces the computational load on the expense of eradicating helpful particulars, affecting accuracy. Token discount strategies like recursive KV cache compression and body choice add complexity with out yielding a lot enchancment. Although superior video encoders and pooling strategies help, they continue to be inefficient and never scalable, rendering long-video processing computationally intensive.

To deal with these challenges, researchers from NVIDIA, Rutgers College, UC Berkeley, MIT, Nanjing College, and KAIST proposed STORM (Spatiotemporal Token Discount for Multimodal LLMs), a Mamba-based temporal projector structure for environment friendly processing of lengthy movies. Not like conventional strategies, the place temporal relations are inferred individually on every video body, and language fashions are utilized for inferring the temporal relations, STORM provides temporal data on the video tokens degree to get rid of computation redundancy and improve effectivity. The mannequin improves video representations with a bidirectional spatiotemporal scanning mechanism whereas mitigating the burden of temporal reasoning from the LLM.
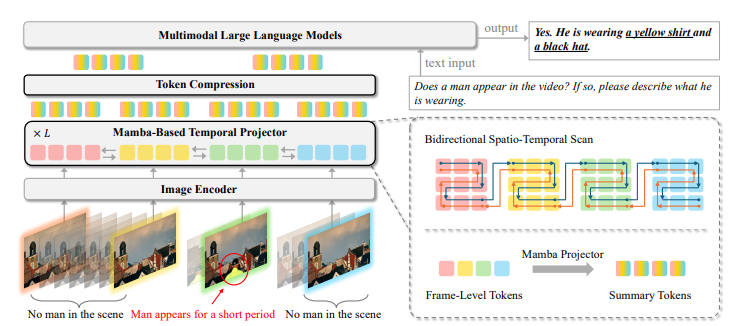
The framework makes use of Mamba layers to boost temporal modeling, incorporating a bidirectional scanning module to seize dependencies throughout spatial and temporal dimensions. The temporal encoder processes the picture and video inputs otherwise, performing as a spatial scanner for photos to combine international spatial context and as a spatiotemporal scanner for movies to seize temporal dynamics. Throughout coaching, token compression strategies improved computational effectivity whereas sustaining important data, permitting inference on a single GPU. Coaching-free token subsampling at check time diminished computational burdens additional whereas retaining vital temporal particulars. This system facilitated environment friendly processing of lengthy movies with out requiring specialised tools or deep variations.
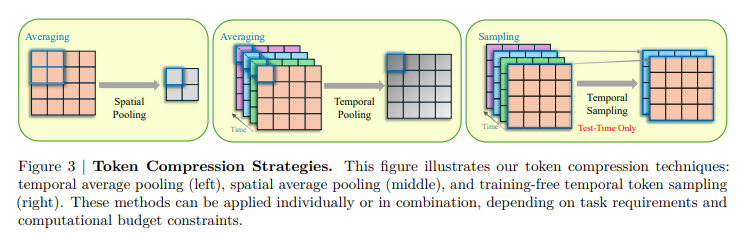
Experiments had been performed to guage the STORM mannequin for video understanding. Coaching was carried out utilizing pre-trained SigLIP fashions, with a temporal projector launched by way of random initialization. The method concerned two phases: an alignment stage, the place the picture encoder and LLM had been frozen whereas solely the temporal projector was educated utilizing image-text pairs, and a supervised fine-tuning stage (SFT) with a various dataset of 12.5 million samples, together with textual content, image-text, and video-text knowledge. Token compression strategies, together with temporal and spatial pooling, decreased computational burden. The final mannequin was evaluated on long-video benchmarks comparable to EgoSchema, MVBench, MLVU, LongVideoBench, and VideoMME, with the efficiency being in contrast with different video LLMs.
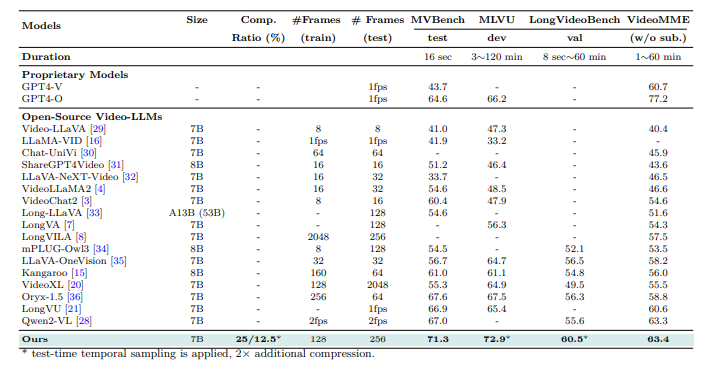
Upon analysis, STORM outperformed present fashions, attaining state-of-the-art outcomes on benchmarks. The Mamba module improved effectivity by compressing visible tokens whereas retaining key data, lowering inference time by as much as 65.5%. Temporal pooling labored finest on lengthy movies, optimizing efficiency with few tokens. STORM additionally carried out significantly higher than the baseline VILA mannequin, notably in duties that concerned understanding the worldwide context. Outcomes verified the importance of Mamba for optimized token compression, with efficiency boosts rising together with the video size from 8 to 128 frames.
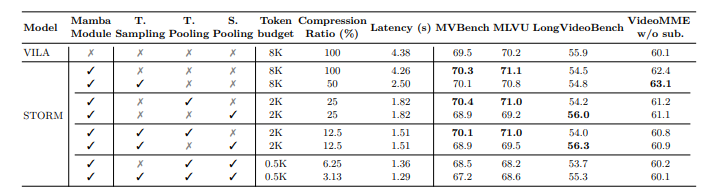
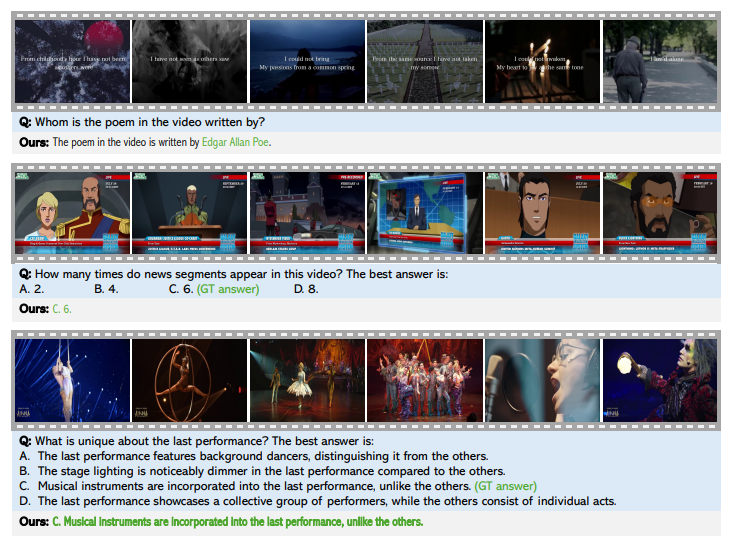
In abstract, the proposed STORM mannequin improved long-video understanding utilizing a Mamba-based temporal encoder and environment friendly token discount. It enabled robust compression with out dropping key temporal data, recording state-of-the-art efficiency on long-video benchmarks whereas preserving computation low. The tactic can act as a baseline for future analysis, facilitating innovation in token compression, multimodal alignment, and real-world deployment to enhance video-language mannequin accuracy and effectivity.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 80k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and remedy challenges.