

{kind=link}
Giant language fashions (LLMs), helpful for answering questions and producing content material, are actually being educated to deal with duties requiring superior reasoning, comparable to advanced problem-solving in arithmetic, science, and logical deduction. Bettering reasoning capabilities inside LLMs is a core focus of AI analysis, aiming to empower fashions to conduct sequential pondering processes. This space’s enhancement might allow extra strong functions in numerous fields by permitting fashions to navigate by means of advanced reasoning duties independently.
A persistent problem in LLM growth is optimizing their reasoning talents with out exterior suggestions. Present LLMs carry out nicely on comparatively easy duties however need assistance with multi-step or sequential reasoning, the place a solution is derived by means of a collection of linked logical steps. This limitation restricts LLMs’ utility in duties that require a logical development of concepts, comparable to fixing intricate mathematical issues or analyzing knowledge in a structured means. Consequently, constructing self-sufficient reasoning capabilities into LLMs has grow to be important to increase their performance and effectiveness in duties the place reasoning is essential.
Researchers have experimented with a number of inference-time strategies to handle these challenges to enhance reasoning. One outstanding strategy is Chain-of-Thought (CoT) prompting, which inspires the mannequin to interrupt down a posh drawback into manageable elements, making every choice step-by-step. This technique allows fashions to observe a structured strategy towards problem-solving, making them higher suited to duties requiring logic and precision. Different approaches, like Tree-of-Thought and Program-of-Thought, enable LLMs to discover a number of reasoning paths, offering numerous approaches to problem-solving. Whereas efficient, these strategies focus totally on runtime enhancements and don’t essentially improve reasoning potential in the course of the mannequin’s coaching part.
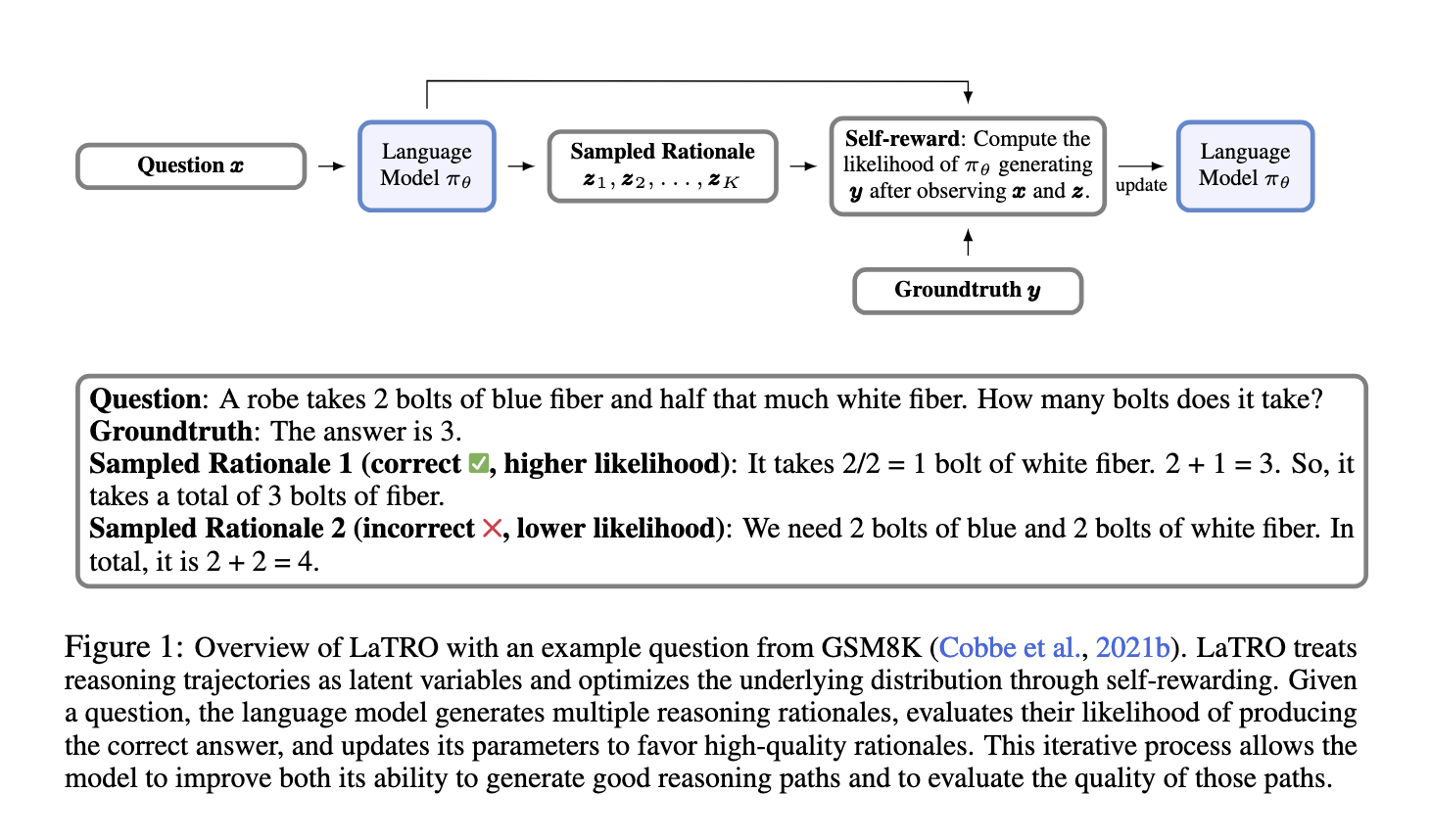
Researchers from Salesforce AI Analysis have launched a brand new framework known as LaTent Reasoning Optimization (LaTRO). LaTRO is an revolutionary strategy that transforms the reasoning course of right into a latent sampling drawback, providing an intrinsic enhancement to the mannequin’s reasoning capabilities. This framework permits LLMs to refine their reasoning pathways by means of a self-rewarding mechanism, which allows them to judge and enhance their responses with out counting on exterior rewards or supervised suggestions. By specializing in a self-improvement technique, LaTRO advances reasoning efficiency on the coaching stage, making a foundational change in how fashions perceive and sort out advanced duties.
LaTRO’s methodology is grounded in sampling reasoning paths from a latent distribution and optimizing these paths by means of variational strategies. LaTRO makes use of a singular self-rewarding mechanism at its core by sampling a number of reasoning paths for a given query. Every path is evaluated primarily based on its probability of manufacturing an accurate reply, with the mannequin then adjusting its parameters to prioritize paths with larger success charges. This iterative course of allows the mannequin to concurrently improve its potential to generate high quality reasoning paths and assess the effectiveness of those paths, thus fostering a continuous self-improvement cycle. In contrast to typical approaches, LaTRO doesn’t rely upon exterior reward fashions, making it a extra autonomous and adaptable framework for enhancing reasoning in LLMs. Moreover, by shifting the reasoning optimization to the coaching part, LaTRO successfully reduces computational calls for throughout inference, making it a resource-efficient answer.

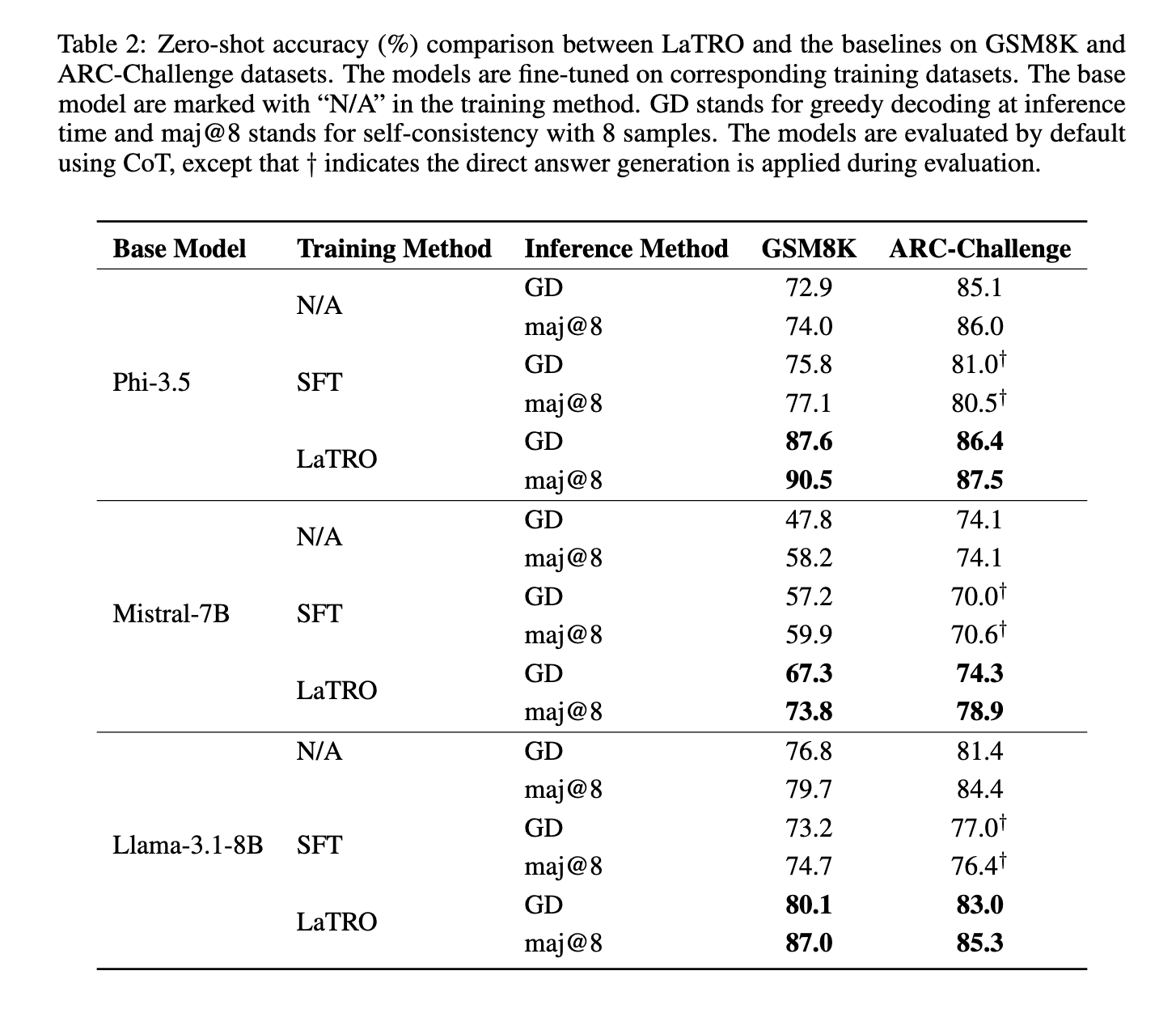
The efficiency of LaTRO has been rigorously examined throughout numerous datasets, with outcomes underscoring its effectiveness. As an illustration, in exams on the GSM8K dataset, which incorporates math-based reasoning challenges, LaTRO demonstrated a considerable 12.5% enchancment over base fashions in zero-shot accuracy. This achieve signifies a marked enhancement within the mannequin’s reasoning potential with out requiring task-specific coaching. Moreover, LaTRO outperformed supervised fine-tuning fashions by 9.6%, showcasing its potential to ship extra correct outcomes whereas sustaining effectivity. On the ARC-Problem dataset, which focuses on logical reasoning, LaTRO once more surpassed each base and fine-tuned fashions, considerably rising efficiency. For Mistral-7B, one of many LLM architectures used, the zero-shot accuracy on GSM8K improved from 47.8% in base fashions to 67.3% below LaTRO with grasping decoding. In self-consistency testing, the place a number of reasoning paths are thought-about, LaTRO achieved an extra efficiency increase, with a exceptional 90.5% accuracy for Phi-3.5 fashions on GSM8K.
Along with quantitative outcomes, LaTRO’s self-rewarding mechanism is obvious in its qualitative enhancements. The strategy successfully teaches LLMs to judge reasoning paths internally, producing concise and logically coherent solutions. The experimental evaluation reveals that LaTRO allows LLMs to raised make the most of their latent reasoning potential, even in advanced situations, thus lowering reliance on exterior analysis frameworks. This development has implications for a lot of functions, particularly in fields the place logical coherence and structured reasoning are important.
In conclusion, LaTRO gives an revolutionary and efficient answer to boost LLM reasoning by means of self-rewarding optimization, setting a brand new customary for mannequin self-improvement. This framework allows pre-trained LLMs to unlock their latent potential in reasoning duties by specializing in training-time reasoning enhancement. This development by Salesforce AI Analysis highlights the potential for autonomous reasoning in AI fashions and demonstrates that LLMs can self-evolve into more practical problem-solvers. LaTRO represents a major leap ahead, bringing AI nearer to attaining autonomous reasoning talents throughout numerous domains.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Companies and Actual Property Transactions
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.