

{kind=link}
TL;DR
DeepSeek-OCR is the newest open-weight OCR mannequin from DeepSeek, constructed to extract structured textual content, formulation, and tables from complicated paperwork with excessive accuracy. It combines a imaginative and prescient encoder (primarily based on SAM and CLIP) and a Combination-of-Consultants decoder (DeepSeek-3B-MoE) for environment friendly textual content technology.
You may attempt DeepSeek-OCR immediately on Clarifai — no separate API key or setup required.
Playground: Check DeepSeek-OCR immediately within the Clarifai Playground right here.
API Entry: Use Clarifai’s OpenAI-compatible endpoint. Authenticate along with your Private Entry Token (PAT) and specify the DeepSeek-OCR mannequin URL.
Introduction
DeepSeek-OCR is a multi-modal mannequin designed to transform complicated pictures akin to invoices, scientific papers, and handwritten notes into correct, structured textual content.
Not like conventional OCR methods that rely purely on convolutional networks for textual content detection and recognition, DeepSeek-OCR makes use of a transformer-based encoder-decoder structure. This permits it to deal with dense paperwork, tables, and combined visible content material extra successfully whereas maintaining GPU utilization low.
Key options:
Processes pictures as imaginative and prescient tokens utilizing a hybrid SAM + CLIP encoder.
Compresses visible knowledge by as much as 10× with minimal accuracy loss.
Makes use of a 3B-parameter Combination-of-Consultants decoder, activating solely 6 of 64 consultants throughout inference for top effectivity.
Can course of as much as 200K pages per day on a single A100 GPU on account of its optimized token compression and activation technique.
Run DeepSeek-OCR
You may entry DeepSeek-OCR in two easy methods: by the Clarifai Playground or through the API.
Playground
The Playground supplies a quick, interactive surroundings to check and discover mannequin conduct. You may choose the DeepSeek-OCR mannequin immediately from the group, add a picture akin to an bill, scanned doc, or handwritten web page, and add a related immediate describing what you need the mannequin to extract or analyze. The output textual content is displayed in actual time, permitting you to shortly confirm accuracy and formatting.
DeepSeek-OCR through API
Clarifai supplies an OpenAI-compatible endpoint that permits you to name DeepSeek-OCR utilizing the identical Python or TypeScript consumer libraries you already use. When you set your Private Entry Token (PAT) as an surroundings variable, you possibly can name the mannequin immediately by specifying its URL.
Under are two methods to ship a picture enter — both from an area file or through a picture URL.
Choice 1: Utilizing a Native Picture File
This instance reads an area file (e.g., doc.jpeg), encodes it in base64, and sends it to the mannequin for OCR extraction.
Choice 2: Utilizing an Picture URL
In case your picture is hosted on-line, you possibly can immediately go its URL to the mannequin.
You should utilize Clarifai’s OpenAI-compatible API with any TypeScript or JavaScript SDK. For instance, the snippet under exhibits how you should use the Vercel AI SDK to entry the DeepSeek-OCR.
Choice 1: Utilizing a Native Picture File
Choice 2: Utilizing an Picture URL
Clarifai’s OpenAI-compatible API allows you to entry DeepSeek-OCR utilizing any language or SDK that helps the OpenAI format. You may experiment within the Clarifai Playground or combine it immediately into your functions. Study extra concerning the Open AI Compatabile API within the documentation right here.
How DeepSeek-OCR Works
DeepSeek-OCR is constructed from the bottom up utilizing a two-stage vision-language structure that mixes a strong imaginative and prescient encoder and a Combination-of-Consultants (MoE) textual content decoder. This setup permits environment friendly and correct textual content extraction from complicated paperwork.
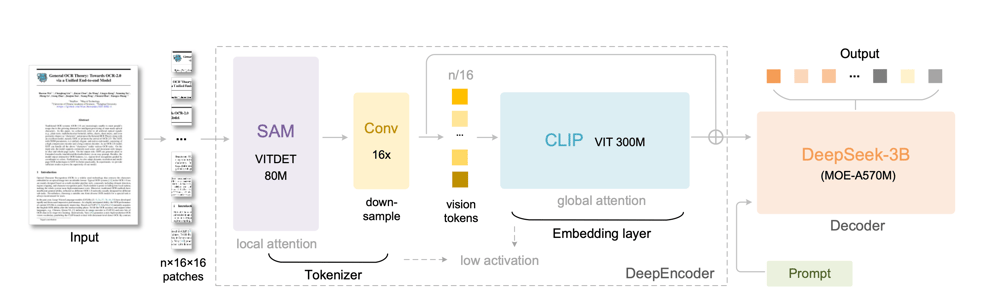
Picture Supply: DeepSeek-OCR Analysis Paper
DeepEncoder (Imaginative and prescient Encoder)
The DeepEncoder is a 380M-parameter imaginative and prescient spine that transforms uncooked pictures into compact visible embeddings.
Patch Embedding: The enter picture is split into 16×16 patches.
Native Consideration (SAM – ViTDet):
SAM applies native consideration to seize fine-grained options akin to font type, handwriting, edges, and texture particulars inside every area of the picture. This helps protect spatial precision at an area stage.Downsampling: The patch embeddings are downsampled 16× through convolution to cut back the whole variety of visible tokens and enhance effectivity.
World Consideration (CLIP – ViT):
CLIP introduces world consideration, enabling the mannequin to grasp doc format, construction, and semantic relationships throughout sections of the picture.Compact Visible Embeddings:
The encoder produces a sequence of imaginative and prescient tokens which can be roughly 10× smaller than equal textual content tokens, leading to excessive compression and sooner decoding.
DeepSeek-3B-MoE Decoder
The encoded visible tokens are handed to a Combination-of-Consultants Transformer Decoder, which converts them into readable textual content.
Skilled Activation: 6 out of 64 consultants are activated per token, together with 2 shared consultants (about 570M energetic parameters).
Textual content Technology: Transformer layers decode the visible embeddings into structured textual content sequences, capturing plain textual content, formulation, tables, and format info.
Effectivity and Scale: Though the whole mannequin measurement is 3B parameters, solely a fraction is energetic throughout inference, offering 3B-scale efficiency at <600M energetic price.
Conclusion
DeepSeek-OCR is greater than a breakthrough in doc understanding. It redefines how multimodal fashions course of visible info by combining SAM’s fine-grained visible precision, CLIP’s world format reasoning, and a Combination-of-Consultants decoder for environment friendly textual content technology. Via Clarifai, you possibly can experiment DeepSeek-OCR within the Playground, combine it immediately through the OpenAI-compatible API.
Study extra: