

{kind=link}
Reinforcement studying from human suggestions RLHF is important for making certain high quality and security in LLMs. State-of-the-art LLMs like Gemini and GPT-4 endure three coaching phases: pre-training on giant corpora, SFT, and RLHF to refine era high quality. RLHF entails coaching a reward mannequin (RM) based mostly on human preferences and optimizing the LLM to maximise predicted rewards. This course of is difficult because of forgetting pre-trained information and reward hacking. A sensible strategy to reinforce era high quality is Greatest-of-N sampling, which selects one of the best output from N-generated candidates, successfully balancing reward and computational value.
Researchers at Google DeepMind have launched Greatest-of-N Distillation (BOND), an progressive RLHF algorithm designed to duplicate the efficiency of Greatest-of-N sampling with out its excessive computational value. BOND is a distribution matching algorithm that aligns the coverage’s output with the Greatest-of-N distribution. Utilizing Jeffreys divergence, which balances mode-covering and mode-seeking behaviors, BOND iteratively refines the coverage via a shifting anchor strategy. Experiments on abstractive summarization and Gemma fashions present that BOND, notably its variant J-BOND, outperforms different RLHF algorithms by enhancing KL-reward trade-offs and benchmark efficiency.
Greatest-of-N sampling optimizes language era towards a reward perform however is computationally costly. Current research have refined its theoretical foundations, offered reward estimators, and explored its connections to KL-constrained reinforcement studying. Numerous strategies have been proposed to match the Greatest-of-N technique, akin to supervised fine-tuning on Greatest-of-N information and choice optimization. BOND introduces a novel strategy utilizing Jeffreys divergence and iterative distillation with a dynamic anchor to effectively obtain the advantages of Greatest-of-N sampling. This technique focuses on investing assets throughout coaching to cut back inference-time computational calls for, aligning with ideas of iterated amplification.
The BOND strategy entails two essential steps. First, it derives an analytical expression for the Greatest-of-N (BoN) distribution. Second, it frames the duty as a distribution matching drawback, aiming to align the coverage with the BoN distribution. The analytical expression exhibits that BoN reweights the reference distribution, discouraging poor generations as N will increase. The BOND goal seeks to attenuate divergence between the coverage and BoN distribution. The Jeffreys divergence, balancing ahead and backward KL divergences, is proposed for sturdy distribution matching. Iterative BOND refines the coverage by repeatedly making use of the BoN distillation with a small N, enhancing efficiency and stability.
J-BOND is a sensible implementation of the BOND algorithm designed for fine-tuning insurance policies with minimal pattern complexity. It iteratively refines the coverage to align with the Greatest-of-2 samples utilizing the Jeffreys divergence. The method entails producing samples, calculating gradients for ahead and backward KL parts, and updating coverage weights. The anchor coverage is up to date utilizing an Exponential Shifting Common (EMA), which boosts coaching stability and improves the reward/KL trade-off. Experiments present that J-BOND outperforms conventional RLHF strategies, demonstrating effectiveness and higher efficiency while not having a set regularization degree.
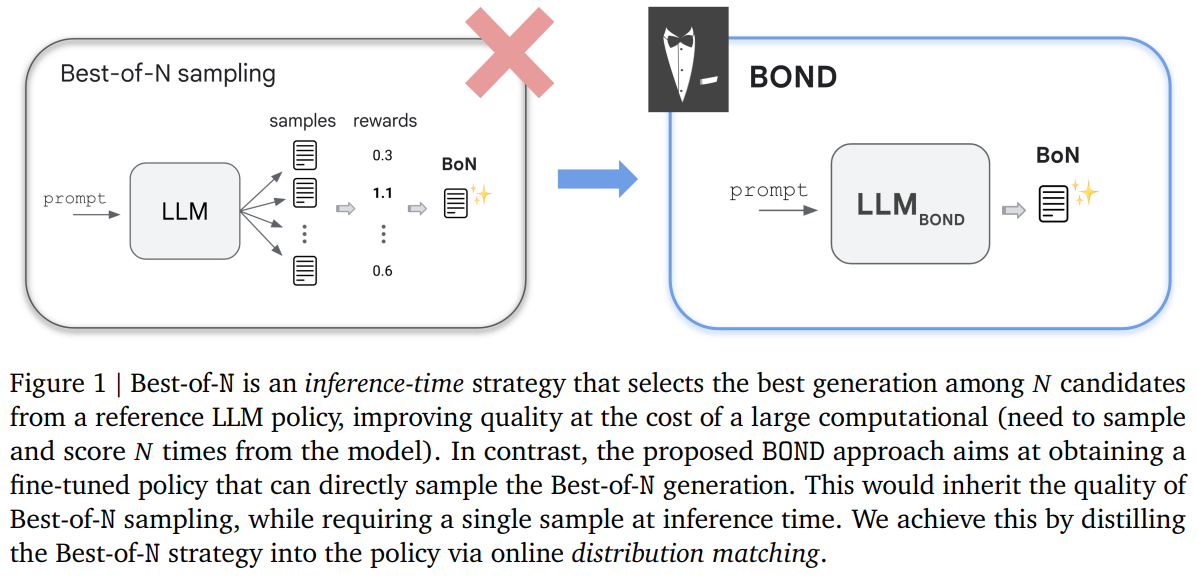
BOND is a brand new RLHF technique that fine-tunes insurance policies via the net distillation of the Greatest-of-N sampling distribution. The J-BOND algorithm enhances practicality and effectivity by integrating Monte-Carlo quantile estimation, combining ahead and backward KL divergence aims, and utilizing an iterative process with an exponential shifting common anchor. This strategy improves the KL-reward Pareto entrance and outperforms state-of-the-art baselines. By emulating the Greatest-of-N technique with out its computational overhead, BOND aligns coverage distributions nearer to the Greatest-of-N distribution, demonstrating its effectiveness in experiments on abstractive summarization and Gemma fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
