

{kind=link}
Massive language fashions (LLMs) depend on deep studying architectures that seize advanced linguistic relationships inside layered constructions. Based on Transformer architectures, these fashions are more and more deployed throughout industries for duties that require nuanced language understanding and era. Nonetheless, the calls for of huge Transformer fashions include steep computational and reminiscence necessities. As fashions develop to billions of parameters, their deployment on customary {hardware} turns into difficult as a result of processing energy and reminiscence capability limitations. To make LLMs possible and accessible for broader functions, researchers are pursuing optimizations that steadiness mannequin efficiency with useful resource effectivity.
LLMs sometimes require intensive computational sources and reminiscence, making them expensive to deploy and tough to scale. One of many essential points on this space is lowering the useful resource burden of LLMs whereas preserving their efficiency. Researchers are investigating strategies for minimizing mannequin parameters with out impacting accuracy, with parameter sharing being one method into account. Mannequin weights are reused throughout a number of layers in parameter sharing, theoretically lowering the mannequin’s reminiscence footprint. Nonetheless, this technique has had restricted success in fashionable LLMs, the place layer complexity could cause shared parameters to degrade efficiency. Decreasing parameters successfully with out loss in mannequin accuracy has thus grow to be a big problem as fashions grow to be extremely interdependent inside their layers.
Researchers have explored methods already utilized in parameter discount, comparable to information distillation and pruning. Information distillation transfers the efficiency of a bigger mannequin to a smaller one, whereas pruning eliminates much less influential parameters to scale back the mannequin’s dimension. Regardless of their benefits, these methods can fail to realize the specified effectivity in large-scale fashions, significantly when efficiency at scale is crucial. One other method, low-rank adaptation (LoRA), adjusts the mannequin construction to achieve comparable outcomes however doesn’t all the time yield the effectivity crucial for broader functions.
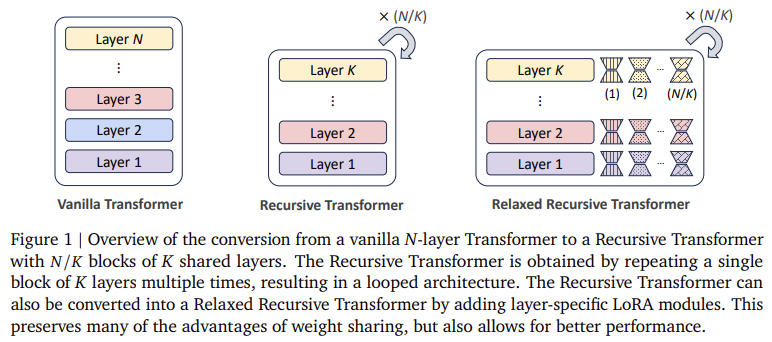
The researchers from KAIST AI, Google DeepMind, and Google Analysis launched Relaxed Recursive Transformers to beat these limitations. This structure builds on conventional Transformers by implementing parameter sharing throughout layers by way of recursive transformations supported by LoRA modules. The Recursive Transformer structure operates by reusing a singular block of layers a number of instances in a loop, retaining efficiency advantages whereas lowering the computational burden. Researchers demonstrated that by looping the identical layer block and initializing it from an ordinary pretrained mannequin, Recursive Transformers might scale back parameters whereas sustaining accuracy and optimizing mannequin useful resource use. This configuration additional introduces Relaxed Recursive Transformers by including low-rank variations to loosen the strict parameter-sharing constraints, permitting extra flexibility and refined efficiency within the shared construction.
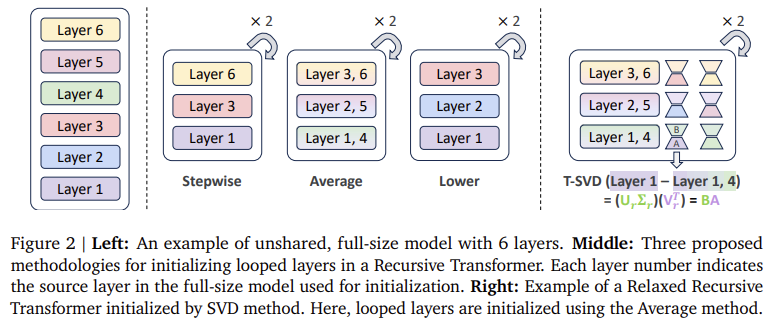
The Relaxed Recursive Transformer’s design hinges on integrating LoRA modules custom-made for every layer, permitting the mannequin to operate at lowered parameter counts with out compromising accuracy. Every layer block is initialized utilizing Singular Worth Decomposition (SVD) methods, which make sure the mannequin’s layers can function successfully at a compressed scale. Recursive fashions such because the Gemma 1B mannequin, which use this design, have been proven to outperform non-recursive counterparts of an analogous dimension, just like the TinyLlama 1.1B and Pythia 1B, by attaining larger accuracy in few-shot duties. This structure additional permits Recursive Transformers to leverage early-exit mechanisms, enhancing inference throughput by as much as 3x in comparison with conventional LLMs as a result of its recursive design.
The outcomes reported within the research present that Recursive Transformers obtain notable positive aspects in effectivity and efficiency. For instance, the recursive Gemma 1B mannequin demonstrated a 10-percentage-point accuracy acquire over reduced-size fashions educated on the identical dataset. The researchers report that through the use of early-exit methods, the Recursive Transformer achieved practically 3x pace enhancements in inference, because it permits depth-wise batching. Additionally, the recursive fashions carried out competitively with bigger fashions, reaching efficiency ranges corresponding to non-recursive fashions pretrained on considerably bigger datasets, with some recursive fashions practically matching fashions educated on corpora exceeding three trillion tokens.
Key Takeaways from the Analysis:
- Effectivity Beneficial properties: Recursive Transformers achieved as much as 3x enhancements in inference throughput, making them considerably quicker than customary Transformer fashions.
- Parameter Sharing: Parameter sharing with LoRA modules allowed fashions just like the Gemma 1B to realize practically ten proportion factors larger accuracy over reduced-size fashions with out dropping effectiveness.
- Enhanced Initialization: Singular Worth Decomposition (SVD) initialization was used to take care of efficiency with lowered parameters, offering a balanced method between totally shared and non-shared constructions.
- Accuracy Upkeep: Recursive Transformers sustained excessive accuracy even when educated on 60 billion tokens, attaining aggressive efficiency in opposition to non-recursive fashions educated on far bigger datasets.
- Scalability: The recursive transformer fashions current a scalable answer by integrating recursive layers and early-exit methods, facilitating broader deployment with out demanding high-end computational sources.

In conclusion, Relaxed Recursive Transformers supply a novel method to parameter effectivity in LLMs by leveraging recursive layer sharing supported by LoRA modules, preserving each reminiscence effectivity and mannequin effectiveness. By optimizing parameter-sharing methods with versatile low-rank modules, the workforce offered a high-performing, scalable answer that makes large-scale language fashions extra accessible and possible for sensible functions. The analysis presents a viable path for bettering price and efficiency effectivity in deploying LLMs, particularly the place computational sources are restricted.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An In depth Assortment of Small Language Fashions (SLMs) for Intel PCs
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.