

{kind=link}
Energy distribution techniques are sometimes conceptualized as optimization fashions. Whereas optimizing brokers to carry out duties works properly for techniques with restricted checkpoints, issues start to exit of hand when heuristics sort out a number of duties and brokers. Scaling dramatically will increase the complexity of project issues, usually NP-hard and nonlinear. Optimization strategies change into the white elephants within the room, offering suboptimality at excessive useful resource consumption. One other main subject with these strategies is that their drawback setup is dynamic, requiring an iterative, state-based project technique. When one thinks of state in AI, reinforcement studying is the very first thing that involves thoughts. Within the case of project functions, given its temporal state-dependent nature, researchers realized the enticing and large potential of sequential decision-making reinforcement studying. This paper discusses the newest analysis in state-based project, which optimizes its resolution by RL.
Researchers from the College of Washington, Seattle, launched a novel multi-agent reinforcement studying method for sequential satellite tv for pc project issues. Multi-Agent RL supplies options for large-scale, sensible eventualities that, with different strategies, would have been extravagantly complicated. The authors introduced a meticulously designed and theoretically justified novel algorithm for fixing satellite tv for pc assignments that ensures particular rewards, ensures international aims, and avoids conflicting constraints. The method integrates present grasping algorithms in MARL solely to enhance its resolution for long-term planning. The authors additionally present the readers with novel insights into its working and international convergence properties by easy experimentation and comparisons.
The methodology that distinguishes it’s that brokers first study an anticipated project worth; this worth serves because the enter for an optimally distributed job project mechanism. This permits brokers to execute joint assignments that fulfill project constraints whereas studying a near-optimal joint coverage on the system stage. The paper follows a generalized method to satellite tv for pc web constellations, the place satellites act as brokers. This Satellite tv for pc Task Drawback is solved through an RL-enabled Distributed Task algorithm(REDA). On this, the authors bootstrap the coverage from a non-parameterized grasping coverage with which they act initially of coaching with chance ε. Moreover, to induce additional exploration, the authors add randomly distributed noise to Q . One other facet of REDA that reduces its complexity is its studying goal specification, which ensures targets fulfill the constraints.
For analysis, the authors carry out experiments on a easy SAP atmosphere, which they later scale to a posh satellite tv for pc constellation job allocation atmosphere with tons of of satellites and duties. The authors steer the experiments to reply some attention-grabbing questions, akin to whether or not REDA encourages unselfish conduct and if REDA might be utilized to giant issues. The authors reported that REDA instantly drove the group to an optimum joint coverage, not like different strategies that inspired selfishness. For the extremely complicated scaled SAP, REDA yielded low variance and persistently outperformed all different strategies. General, the authors reported a rise of 20% to 50% over different state-of-the-art strategies.
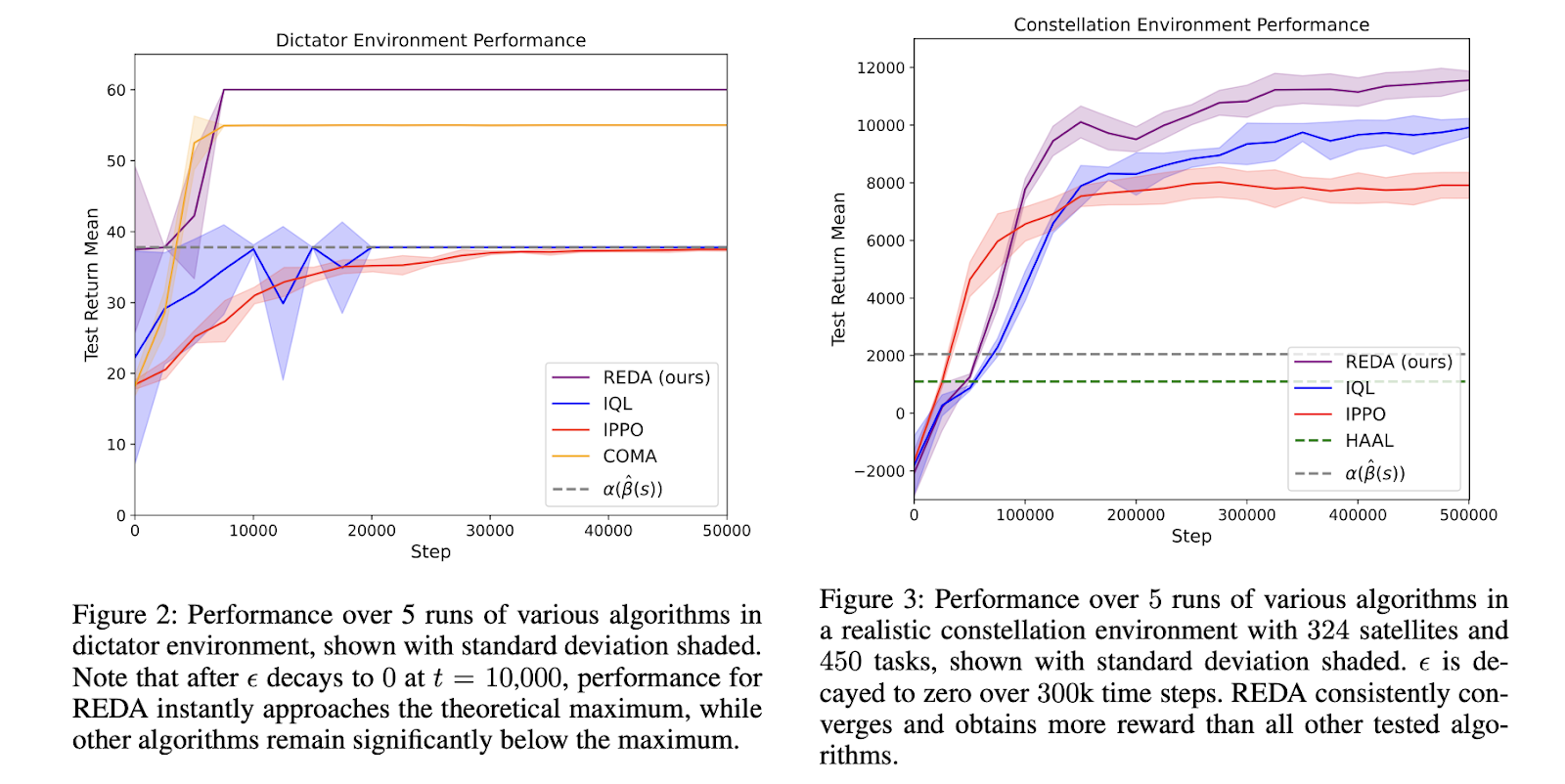
Conclusion: This paper mentioned REDA, a novel Multi-Agent Reinforcement Studying method for fixing complicated state-dependent project issues. The paper addresses satellite tv for pc project issues and teaches brokers to behave unselfishly whereas studying environment friendly options, even in giant drawback settings.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Information and Analysis Intelligence–Be part of this webinar to realize actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding information privateness.
Adeeba Alam Ansari is at the moment pursuing her Twin Diploma on the Indian Institute of Know-how (IIT) Kharagpur, incomes a B.Tech in Industrial Engineering and an M.Tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of know-how to empower society and promote welfare by revolutionary options pushed by empathy and a deep understanding of real-world challenges.