

{kind=link}
Giant Language Fashions (LLMs) have revolutionized generative AI, displaying exceptional capabilities in producing human-like responses. Nonetheless, these fashions face a vital problem often called hallucination, the tendency to generate incorrect or irrelevant info. This concern poses important dangers in high-stakes functions reminiscent of medical evaluations, insurance coverage declare processing, and autonomous decision-making methods the place accuracy is most necessary. The hallucination drawback extends past text-based fashions to vision-language fashions (VLMs) that course of pictures and textual content queries. Regardless of growing sturdy VLMs reminiscent of LLaVA, InstructBLIP, and VILA, these methods wrestle with producing correct responses primarily based on picture inputs and consumer queries.
Present analysis has launched a number of strategies to deal with hallucination in language fashions. For text-based methods, FactScore improved accuracy by breaking lengthy statements into atomic models for higher verification. Lookback Lens developed an consideration rating evaluation strategy to detect context hallucination, whereas MARS applied a weighted system specializing in essential assertion parts. For RAG methods particularly, RAGAS and LlamaIndex emerged as analysis instruments, with RAGAS specializing in response accuracy and relevance utilizing human evaluators, whereas LlamaIndex employs GPT-4 for faithfulness evaluation. Nonetheless, no present works present hallucination scores particularly for multi-modal RAG methods, the place the contexts embody a number of items of multi-modal information.
Researchers from the College of Maryland, School Park, MD, and NEC Laboratories America, Princeton, NJ have proposed RAG-check, a complete methodology to guage multi-modal RAG methods. It consists of three key parts designed to evaluate each relevance and accuracy. The primary part includes a neural community that evaluates the relevancy of every retrieved piece of information to the consumer question. The second part implements an algorithm that segments and categorizes the RAG output into scorable (goal) and non-scorable (subjective) spans. The third part makes use of one other neural community to guage the correctness of goal spans in opposition to the uncooked context, which may embody each textual content and pictures transformed to text-based format by VLMs.
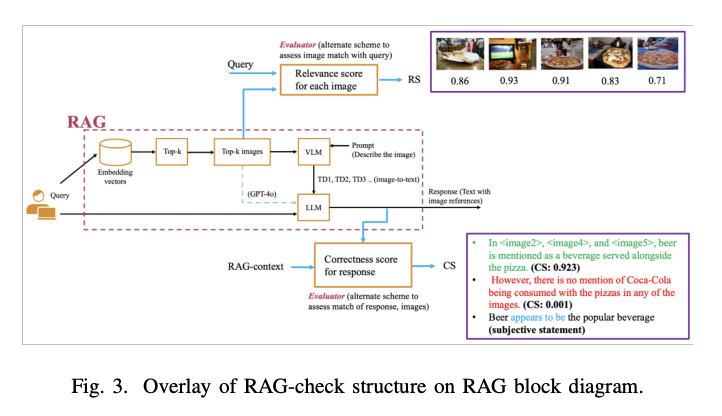
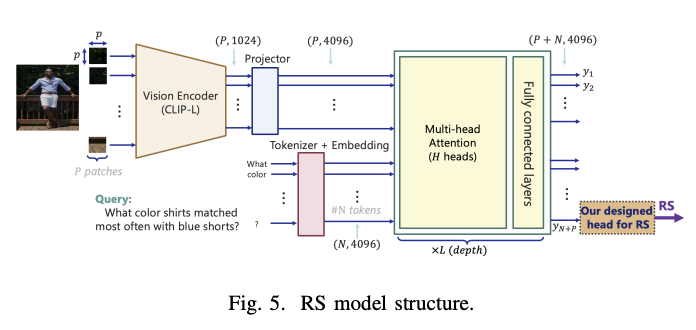
The RAG-check structure makes use of two major analysis metrics: the Relevancy Rating (RS) and Correctness Rating (CS) to guage totally different elements of RAG system efficiency. For evaluating choice mechanisms, the system analyzes the relevancy scores of the highest 5 retrieved pictures throughout a check set of 1,000 questions, offering insights into the effectiveness of various retrieval strategies. By way of context era, the structure permits for versatile integration of varied mannequin combos both separate VLMs (like LLaVA or GPT4) and LLMs (reminiscent of LLAMA or GPT-3.5), or unified MLLMs like GPT-4. This flexibility permits a complete analysis of various mannequin architectures and their influence on response era high quality.
The analysis outcomes exhibit important efficiency variations throughout totally different RAG system configurations. When utilizing CLIP fashions as imaginative and prescient encoders with cosine similarity for picture choice, the common relevancy scores ranged from 30% to 41%. Nonetheless, implementing the RS mannequin for query-image pair analysis dramatically improves relevancy scores to between 71% and 89.5%, although at the price of a 35-fold enhance in computational necessities when utilizing an A100 GPU. GPT-4o emerges because the superior configuration for context era and error charges, outperforming different setups by 20%. The remaining RAG configurations present comparable efficiency, with an accuracy charge between 60% and 68%.
In conclusion, researchers RAG-check, a novel analysis framework for multi-modal RAG methods to deal with the vital problem of hallucination detection throughout a number of pictures and textual content inputs. The framework’s three-component structure, comprising relevancy scoring, span categorization, and correctness evaluation reveals important enhancements in efficiency analysis. The outcomes reveal that whereas the RS mannequin considerably enhances relevancy scores from 41% to 89.5%, it comes with elevated computational prices. Amongst varied configurations examined, GPT-4o emerged as the best mannequin for context era, highlighting the potential of unified multi-modal language fashions in bettering RAG system accuracy and reliability.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 65k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Knowledge and Analysis Intelligence–Be a part of this webinar to realize actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding information privateness.

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.