

{kind=link}
Massive language fashions (LLMs) have progressed past primary pure language processing to sort out advanced problem-solving duties. Whereas scaling mannequin measurement, knowledge, and compute has enabled the event of richer inside representations and emergent capabilities in bigger fashions, important challenges stay of their reasoning skills. Present methodologies wrestle to take care of coherence all through advanced problem-solving processes, notably in domains requiring structured pondering. The issue lies in optimising the chain-of-thought reasoning and making certain constant efficiency throughout diversified duties, particularly on difficult mathematical issues. Although current developments have proven promise, researchers face the continued problem of successfully using computational sources to enhance reasoning capabilities with out sacrificing effectivity. Growing strategies that may systematically improve problem-solving whereas sustaining scalability stays a central downside in advancing LLM capabilities.
Researchers have explored varied approaches to reinforce reasoning in LLMs. Take a look at-time compute scaling coupled with reinforcement studying has emerged as a promising path, with fashions utilizing reasoning tokens to information chain-of-thought processes. Research have investigated whether or not fashions are inclined to overthink or underthink, inspecting reasoning step size, enter size, and customary failure modes. Earlier work has targeted on optimising mathematical reasoning by specific chain-of-thought coaching throughout the studying section and iterative refinement at inference time. Whereas these approaches have proven enhancements on benchmarks, questions stay in regards to the effectivity of token utilization throughout completely different mannequin capabilities and the connection between reasoning size and efficiency. These questions are essential for understanding find out how to design more practical reasoning programs.
This examine makes use of the Omni-MATH dataset to benchmark reasoning skills throughout completely different mannequin variants. This dataset supplies a rigorous analysis framework on the Olympiad degree, addressing limitations of present benchmarks like GSM8K and MATH the place present LLMs obtain excessive accuracy charges. Omni-MATH’s complete group into 33 sub-domains throughout 10 issue ranges permits nuanced evaluation of mathematical reasoning capabilities. The supply of Omni-Choose facilitates automated analysis of model-generated solutions. Whereas different benchmarks like MMLU, AI2 Reasoning, and GPQA cowl various reasoning domains, and coding benchmarks spotlight the significance of clear reward fashions, Omni-MATH’s construction makes it notably appropriate for analyzing the connection between reasoning size and efficiency throughout mannequin capabilities.
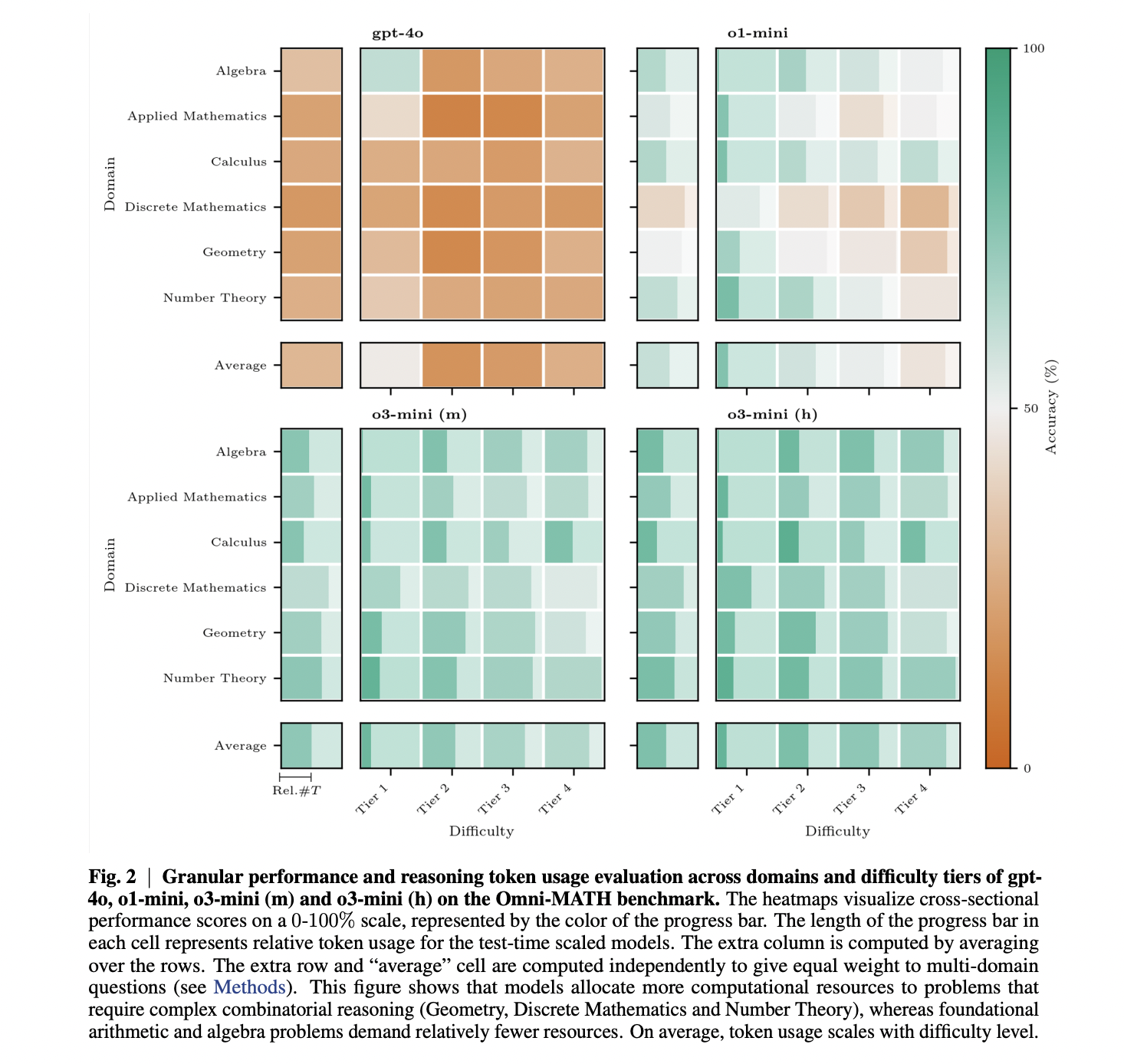
The examine evaluated mannequin efficiency utilizing the Omni-MATH benchmark, which options 4,428 Olympiad-level math issues throughout six domains and 4 issue tiers. Outcomes present a transparent efficiency hierarchy among the many examined fashions: gpt-4o achieved 20-30% accuracy throughout disciplines, considerably lagging behind the reasoning fashions; o1-mini reached 40-60%; o3-mini (m) achieved at the least 50% in all classes; and o3-mini (h) improved by roughly 4% over o3-mini (m), exceeding 80% accuracy for Algebra and Calculus. Token utilization evaluation revealed that relative token consumption will increase with downside issue throughout all fashions, with Discrete Arithmetic being notably token-intensive. Importantly, o3-mini (m) doesn’t use extra reasoning tokens than o1-mini to attain superior efficiency, suggesting more practical reasoning. Additionally, accuracy decreases with growing token utilization throughout all fashions, with the impact being strongest for o1-mini (3.16% lower per 1000 tokens) and weakest for o3-mini (h) (0.81% lower). This means that whereas o3-mini (h) reveals marginally higher efficiency, it comes at a considerably increased computational value.
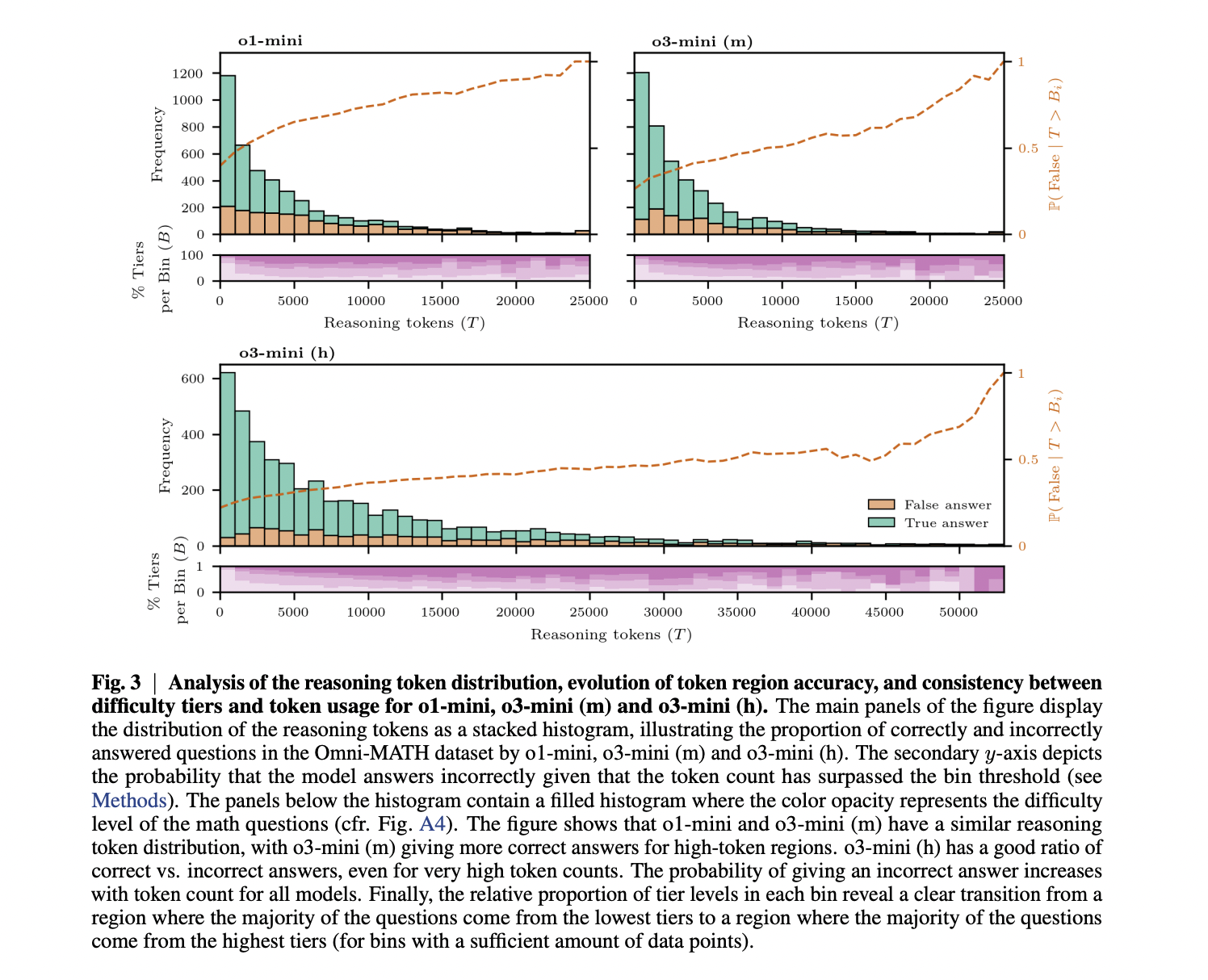
The analysis yields two important findings concerning language mannequin reasoning. First, extra succesful fashions don’t essentially require longer reasoning chains to attain increased accuracy, as demonstrated by the comparability between o1-mini and o3-mini (m). Second, whereas accuracy usually declines with longer chain-of-thought processes, this impact diminishes in additional superior fashions, emphasizing that “pondering more durable” differs from “pondering longer.” This accuracy drop could happen as a result of fashions are inclined to cause extra extensively on issues they wrestle to resolve, or as a result of longer reasoning chains inherently improve the chance of errors. The findings have sensible implications for mannequin deployment, suggesting that constraining chain-of-thought size is extra useful for weaker reasoning fashions than for stronger ones, because the latter keep affordable accuracy even with prolonged reasoning. Future work may benefit from mathematical benchmarks with reference reasoning templates to additional discover these dynamics.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 80k+ ML SubReddit.
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.