

{kind=link}
Massive-scale reinforcement studying (RL) coaching of language fashions on reasoning duties has develop into a promising method for mastering complicated problem-solving expertise. At the moment, strategies like OpenAI’s o1 and DeepSeek’s R1-Zero, have demonstrated outstanding coaching time scaling phenomenon. Each fashions’ benchmark efficiency and response size constantly and steadily enhance with none signal of saturation because the coaching computation scales up. Impressed by these developments, researchers on this paper have explored this new scaling phenomenon by conducting large-scale RL coaching straight on base fashions and referred to this method as Reasoner-Zero coaching.
Researchers from StepFun and Tsinghua College have proposed Open-Reasoner-Zero (ORZ), an open-source implementation of large-scale reasoning-oriented RL coaching for language fashions. It represents a major development in making superior RL coaching methods accessible to the broader analysis neighborhood. ORZ enhances numerous reasoning expertise underneath verifiable rewards, together with arithmetic, logic, coding, and commonsense reasoning duties. It addresses important challenges in coaching stability, response size optimization, and benchmark efficiency enhancements by means of a complete coaching technique. In contrast to earlier approaches that offered restricted implementation particulars, ORZ provides detailed insights into its methodology and finest practices.
The ORZ framework makes use of the Qwen2.5-{7B, 32B} as the bottom mannequin, and implements direct large-scale RL coaching with out preliminary fine-tuning steps. The system leverages a scaled-up model of the usual PPO algorithm, optimized particularly for reasoning-oriented duties. The coaching dataset consists of fastidiously curated question-answer pairs specializing in STEM, Math, and numerous reasoning duties. The structure incorporates a specialised immediate template designed to reinforce inference computation capabilities. The implementation is constructed on OpenRLHF, that includes vital enhancements together with a versatile coach, GPU collocation era, and superior offload-backload help mechanisms for environment friendly large-scale coaching.
The coaching outcomes exhibit vital efficiency enhancements throughout a number of metrics for each the 7B and 32B variants of Open-Reasoner-Zero. Coaching curves reveal constant enhancements in reward metrics and response lengths, with a notable “step second” phenomenon indicating sudden enhancements in reasoning capabilities. Throughout Response Size Scale-up vs DeepSeek-R1-Zero, the Open-Reasoner-Zero-32B mannequin achieves comparable response lengths to DeepSeek-R1-Zero (671B MoE) with just one/5.8 of the coaching steps. This effectivity validates the effectiveness of the minimalist method to large-scale RL coaching.
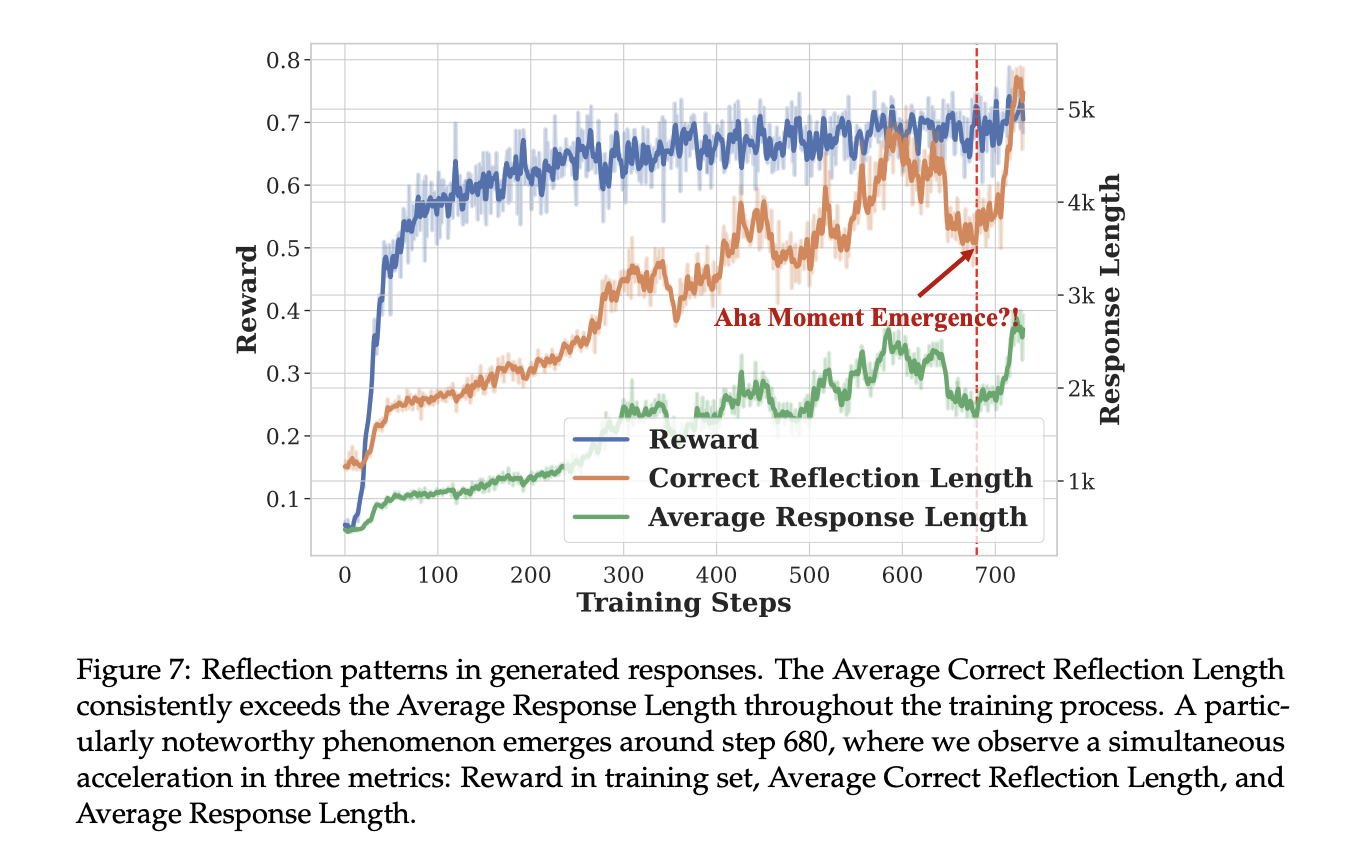
The principle experimental outcomes present that Open-Reasoner-Zero performs exceptionally properly throughout a number of analysis metrics, notably within the 32B configuration. It achieves superior outcomes in comparison with DeepSeek-R1-Zero-Qwen2.5-32B on the GPQA DIAMOND benchmark whereas requiring just one/30 of the coaching steps, showcasing outstanding coaching effectivity. Furthermore, the 7B variant displays fascinating studying dynamics, with regular accuracy enhancements and dramatic response size progress patterns. A particular “step second” phenomenon has been noticed throughout analysis, characterised by sudden will increase in each reward and response size, notably evident in GPQA DIAMOND and AIME2024 benchmarks.
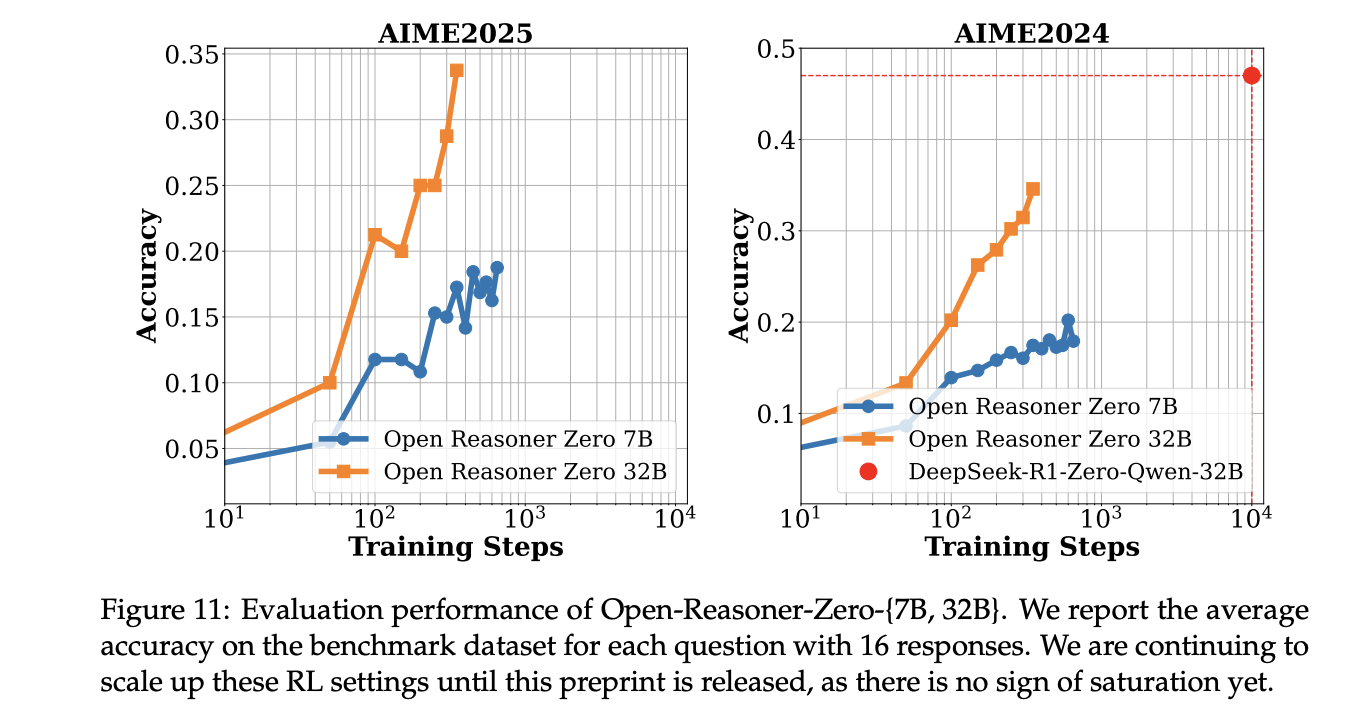
On this paper, researchers launched Open-Reasoner-Zero, representing a major milestone in democratizing large-scale reasoning-oriented RL coaching for language fashions. The analysis reveals {that a} simplified method utilizing vanilla PPO with GAE and rule-based reward capabilities can obtain aggressive outcomes in comparison with extra complicated techniques. The profitable implementation with out KL regularization proves that complicated architectural modifications will not be mandatory for attaining robust reasoning capabilities. By open-sourcing the entire coaching pipeline and sharing detailed insights, this work establishes a basis for future analysis in scaling language mannequin reasoning skills, and that is just the start of a brand new scaling pattern in AI improvement.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 80k+ ML SubReddit.

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.