

{kind=link}

What are LLMs?
A Giant Language Mannequin (LLM) is a sophisticated AI system designed to carry out advanced pure language processing (NLP) duties like textual content era, summarization, translation, and extra. At its core, an LLM is constructed on a deep neural community structure often called a transformer, which excels at capturing the intricate patterns and relationships in language. A few of the well known LLMs embody ChatGPT by OpenAI, LLaMa by Meta, Claude by Anthropic, Mistral by Mistral AI, Gemini by Google and much more.
The Energy of LLMs in Right now’s Technology:
- Understanding Human Language: LLMs have the flexibility to grasp advanced queries, analyze context, and reply in ways in which sound human-like and nuanced.
- Data Integration Throughout Domains: As a consequence of coaching on huge, numerous knowledge sources, LLMs can present insights throughout fields from science to artistic writing.
- Adaptability and Creativity: One of the vital thrilling features of LLMs is their adaptability. They’re able to producing tales, writing poetry, fixing puzzles, and even holding philosophical discussions.
Drawback-Fixing Potential: LLMs can deal with reasoning duties by figuring out patterns, making inferences, and fixing logical issues, demonstrating their functionality in supporting advanced, structured thought processes and decision-making.
For builders seeking to streamline doc workflows utilizing AI, instruments just like the Nanonets PDF AI provide invaluable integration choices. Coupled with Ministral’s capabilities, these can considerably improve duties like doc extraction, making certain environment friendly knowledge dealing with. Moreover, instruments like Nanonets’ PDF Summarizer can additional automate processes by summarizing prolonged paperwork, aligning effectively with Ministral’s privacy-first purposes.
Automating Day-to-Day Duties with LLMs:
LLMs can remodel the best way we deal with on a regular basis duties, driving effectivity and releasing up invaluable time. Listed here are some key purposes:
- Electronic mail Composition: Generate personalised electronic mail drafts rapidly, saving time and sustaining skilled tone.
- Report Summarization: Condense prolonged paperwork and experiences into concise summaries, highlighting key factors for fast evaluation.
- Buyer Help Chatbots: Implement LLM-powered chatbots that may resolve widespread points, course of returns, and supply product suggestions primarily based on person inquiries.
- Content material Ideation: Help in brainstorming and producing artistic content material concepts for blogs, articles, or advertising and marketing campaigns.
- Information Evaluation: Automate the evaluation of information units, producing insights and visualizations with out guide enter.
- Social Media Administration: Craft and schedule partaking posts, work together with feedback, and analyze engagement metrics to refine content material technique.
- Language Translation: Present real-time translation companies to facilitate communication throughout language boundaries, superb for world groups.
To additional improve the capabilities of LLMs, we will leverage Retrieval-Augmented Technology (RAG). This strategy permits LLMs to entry and incorporate real-time info from exterior sources, enriching their responses with up-to-date, contextually related knowledge for extra knowledgeable decision-making and deeper insights.
One-Click on LLM Bash Helper
We’ll discover an thrilling solution to make the most of LLMs by growing an actual time software known as One-Click on LLM Bash Helper. This instrument makes use of a LLM to simplify bash terminal utilization. Simply describe what you need to do in plain language, and it’ll generate the right bash command for you immediately. Whether or not you are a newbie or an skilled person in search of fast options, this instrument saves time and removes the guesswork, making command-line duties extra accessible than ever!
The way it works:
- Open the Bash Terminal: Begin by opening your Linux terminal the place you need to execute the command.

- Describe the Command: Write a transparent and concise description of the duty you need to carry out within the terminal. For instance, “Create a file named abc.txt on this listing.”

- Choose the Textual content: Spotlight the duty description you simply wrote within the terminal to make sure it may be processed by the instrument.

- Press Set off Key: Hit the F6 key in your keyboard as default (may be modified as wanted). This triggers the method, the place the duty description is copied, processed by the instrument, and despatched to the LLM for command era.

- Get and Execute the Command: The LLM processes the outline, generates the corresponding Linux command, and pastes it into the terminal. The command is then executed mechanically, and the outcomes are displayed so that you can see.

Construct On Your Personal
Because the One-Click on LLM Bash Helper can be interacting with textual content in a terminal of the system, it is important to run the appliance regionally on the machine. This requirement arises from the necessity to entry the clipboard and seize key presses throughout totally different purposes, which isn’t supported in on-line environments like Google Colab or Kaggle.
To implement the One-Click on LLM Bash Helper, we’ll must arrange a number of libraries and dependencies that can allow the performance outlined within the course of. It’s best to arrange a brand new setting after which set up the dependencies.
Steps to Create a New Conda Setting and Set up Dependencies
- Open your terminal
- Create a brand new Conda setting. You possibly can title the setting (e.g., llm_translation) and specify the Python model you need to use (e.g., Python 3.9):
conda create -n bash_helper python=3.9
- Activate the brand new setting:
conda activate bash_helper- Set up the required libraries:
- Ollama: It’s an open-source mission that serves as a strong and user-friendly platform for working LLMs in your native machine. It acts as a bridge between the complexities of LLM know-how and the need for an accessible and customizable AI expertise. Set up ollama by following the directions at https://github.com/ollama/ollama/blob/primary/docs/linux.md and in addition run:
pip set up ollama- To begin ollama and set up LLaMa 3.1 8B as our LLM (one can use different fashions) utilizing ollama, run the next instructions after ollama is put in:
ollama serveRun this in a background terminal. After which execute the next code to put in the llama3.1 utilizing ollama:
ollama run llama3.1Listed here are a few of the LLMs that Ollama helps – one can select primarily based on their necessities
| Mannequin | Parameters | Measurement | Obtain |
|---|---|---|---|
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream2 |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLAVA | 7B | 4.5GB | ollama run llava |
| Photo voltaic | 10.7B | 6.1GB | ollama run photo voltaic |
- Pyperclip: It’s a Python library designed for cross-platform clipboard manipulation. It permits you to programmatically copy and paste textual content to and from the clipboard, making it simple to handle textual content alternatives.
pip set up pyperclip- Pynput: Pynput is a Python library that gives a solution to monitor and management enter units, akin to keyboards and mice. It permits you to pay attention for particular key presses and execute capabilities in response.
pip set up pynputCode sections:
Create a python file “helper.py” the place all the next code can be added:
- Importing the Required Libraries: Within the helper.py file, begin by importing the mandatory libraries:
import pyperclip
import subprocess
import threading
import ollama
from pynput import keyboard- Defining the CommandAssistant Class: The
CommandAssistantclass is the core of the appliance. When initialized, it begins a keyboard listener utilizingpynputto detect keypresses. The listener repeatedly screens for the F6 key, which serves because the set off for the assistant to course of a job description. This setup ensures the appliance runs passively within the background till activated by the person.
class CommandAssistant:
def __init__(self):
# Begin listening for key occasions
self.listener = keyboard.Listener(on_press=self.on_key_press)
self.listener.begin()- Dealing with the F6 Keypress: The
on_key_presstechnique is executed every time a secret is pressed. It checks if the pressed secret is F6. If that’s the case, it calls theprocess_task_descriptiontechnique to begin the workflow for producing a Linux command. Any invalid key presses are safely ignored, making certain this system operates easily.
def on_key_press(self, key):
attempt:
if key == keyboard.Key.f6:
# Set off command era on F6
print("Processing job description...")
self.process_task_description()
besides AttributeError:
move
- Extracting Process Description: This technique begins by simulating the “Ctrl+Shift+C” keypress utilizing
xdotoolto repeat chosen textual content from the terminal. The copied textual content, assumed to be a job description, is then retrieved from the clipboard by way ofpyperclip. A immediate is constructed to instruct the Llama mannequin to generate a single Linux command for the given job. To maintain the appliance responsive, the command era is run in a separate thread, making certain the principle program stays non-blocking.
def process_task_description(self):
# Step 1: Copy the chosen textual content utilizing Ctrl+Shift+C
subprocess.run(['xdotool', 'key', '--clearmodifiers', 'ctrl+shift+c'])
# Get the chosen textual content from clipboard
task_description = pyperclip.paste()
# Arrange the command-generation immediate
immediate = (
"You're a Linux terminal assistant. Convert the next description of a job "
"right into a single Linux command that accomplishes it. Present solely the command, "
"with none further textual content or surrounding quotes:nn"
f"Process description: {task_description}"
)
# Step 2: Run command era in a separate thread
threading.Thread(goal=self.generate_command, args=(immediate,)).begin()
- Producing the Command: The
generate_commandtechnique sends the constructed immediate to the Llama mannequin (llama3.1) by way of theollamalibrary. The mannequin responds with a generated command, which is then cleaned to take away any pointless quotes or formatting. The sanitized command is handed to thereplace_with_commandtechnique for pasting again into the terminal. Any errors throughout this course of are caught and logged to make sure robustness.
def generate_command(self, immediate):
attempt:
# Question the Llama mannequin for the command
response = ollama.generate(mannequin="llama3.1", immediate=immediate)
generated_command = response['response'].strip()
# Take away any surrounding quotes (if current)
if generated_command.startswith("'") and generated_command.endswith("'"):
generated_command = generated_command[1:-1]
elif generated_command.startswith('"') and generated_command.endswith('"'):
generated_command = generated_command[1:-1]
# Step 3: Change the chosen textual content with the generated command
self.replace_with_command(generated_command)
besides Exception as e:
print(f"Command era error: {str(e)}")
- Changing Textual content within the Terminal: The
replace_with_commandtechnique takes the generated command and copies it to the clipboard utilizingpyperclip. It then simulates keypresses to clear the terminal enter utilizing “Ctrl+C” and “Ctrl+L” and pastes the generated command again into the terminal with “Ctrl+Shift+V.” This automation ensures the person can instantly evaluation or execute the recommended command with out guide intervention.
def replace_with_command(self, command):
# Copy the generated command to the clipboard
pyperclip.copy(command)
# Step 4: Clear the present enter utilizing Ctrl+C
subprocess.run(['xdotool', 'key', '--clearmodifiers', 'ctrl+c'])
subprocess.run(['xdotool', 'key', '--clearmodifiers', 'ctrl+l'])
# Step 5: Paste the generated command utilizing Ctrl+Shift+V
subprocess.run(['xdotool', 'key', '--clearmodifiers', 'ctrl+shift+v'])
- Working the Utility: The script creates an occasion of the
CommandAssistantclass and retains it working in an infinite loop to repeatedly pay attention for the F6 key. This system terminates gracefully upon receiving a KeyboardInterrupt (e.g., when the person presses Ctrl+C), making certain clear shutdown and releasing system sources.
if __name__ == "__main__":
app = CommandAssistant()
# Hold the script working to pay attention for key presses
attempt:
whereas True:
move
besides KeyboardInterrupt:
print("Exiting Command Assistant.")
Save all of the above elements as ‘helper.py’ file and run the appliance utilizing the next command:
python helper.pyAnd that is it! You have now constructed the One-Click on LLM Bash Helper. Let’s stroll by means of learn how to use it.
Workflow
Open terminal and write the outline of any command to carry out. After which observe the beneath steps:
- Choose Textual content: After writing the outline of the command you must carry out within the terminal, choose the textual content.
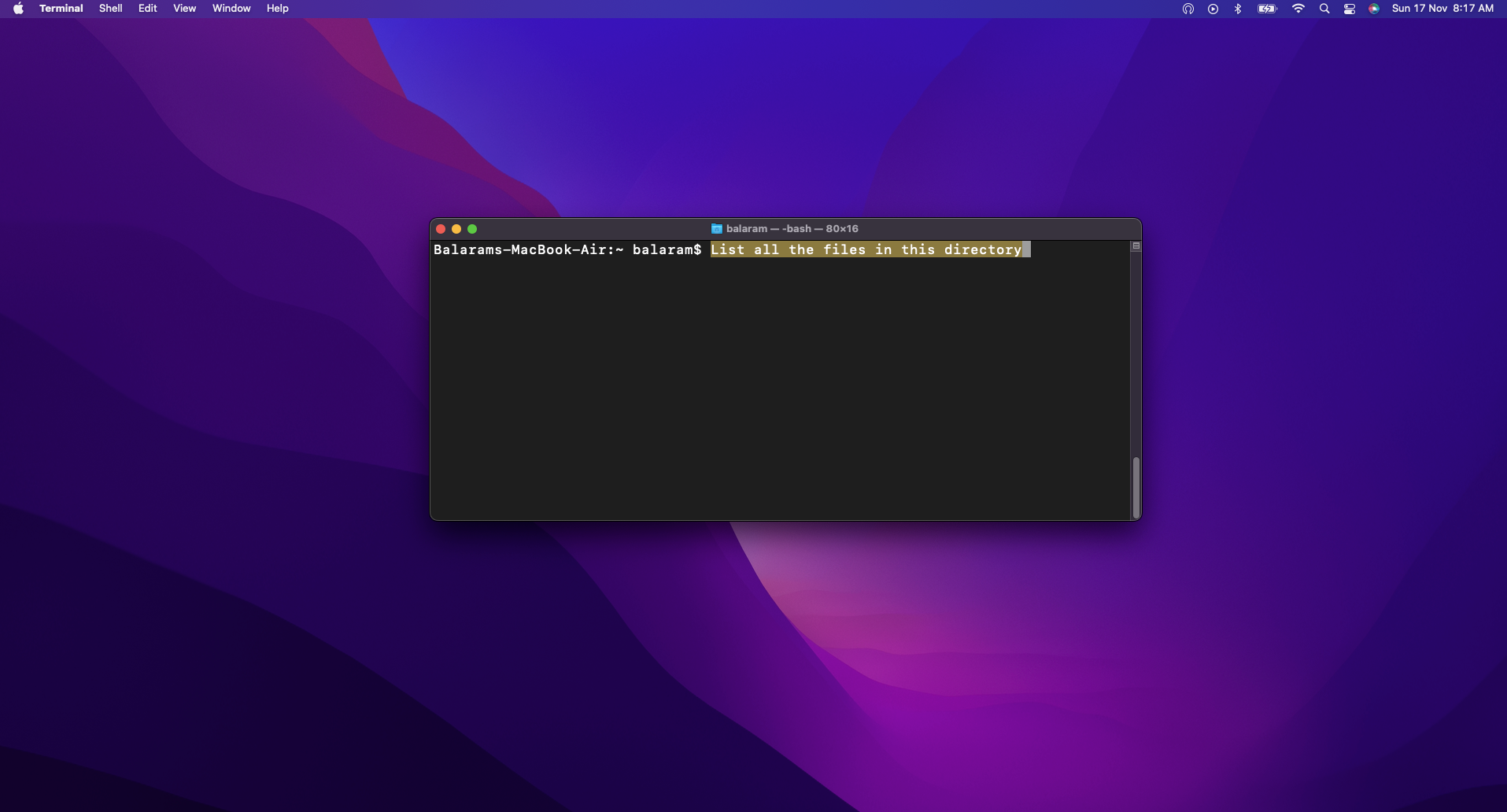
- Set off Translation: Press the F6 key to provoke the method.
- View Consequence: The LLM finds the correct code to execute for the command description given by the person and exchange the textual content within the bash terminal. Which is then mechanically executed.
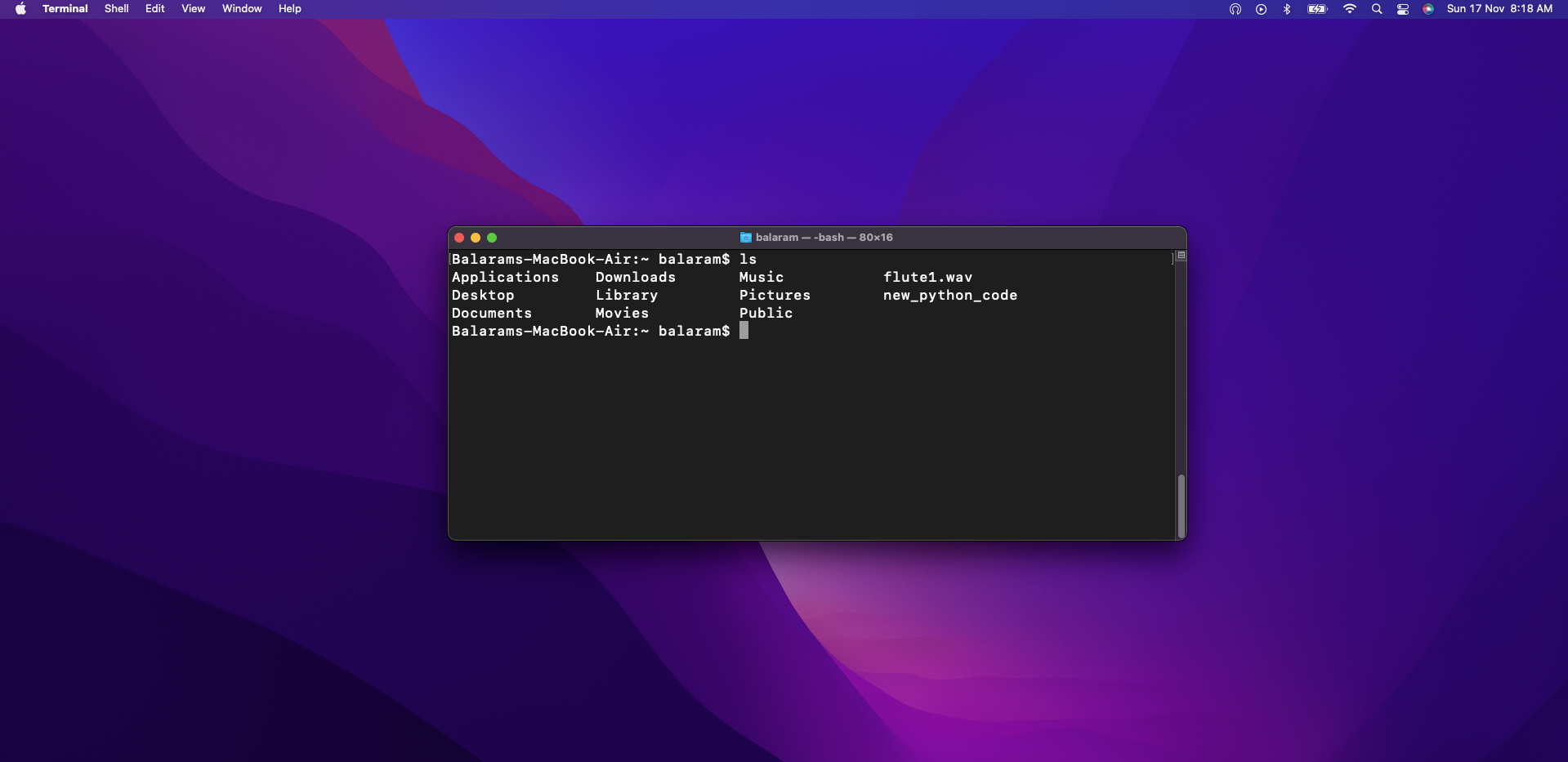
As on this case, for the outline – “Listing all of the information on this listing” the command given as output from the LLM was -“ls”.
For entry to the whole code and additional particulars, please go to this GitHub repo hyperlink.
Listed here are a number of extra examples of the One-Click on LLM Bash Helper in motion:
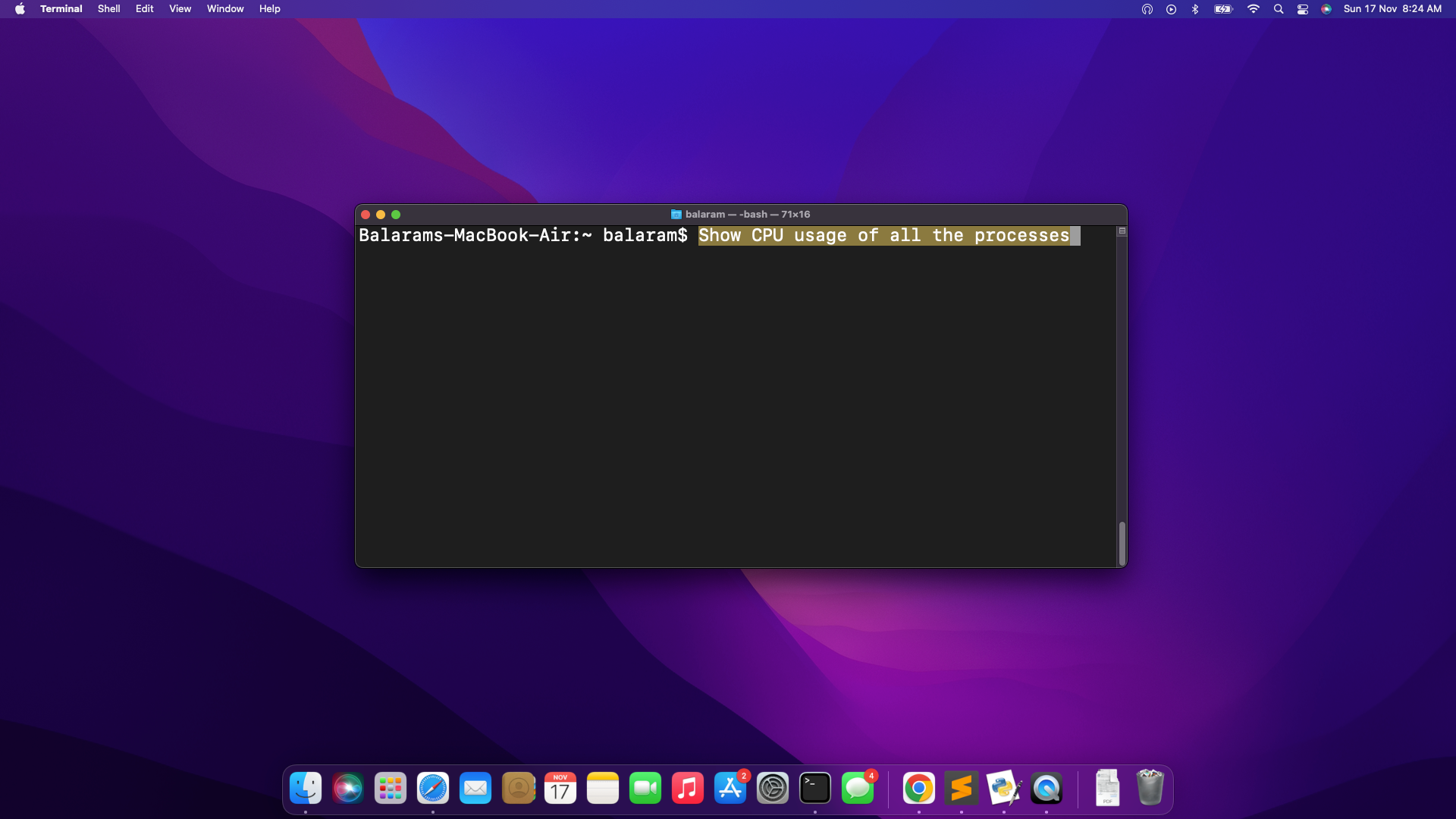
It gave the code “prime” upon urgent the set off key (F6) and after execution it gave the next output:
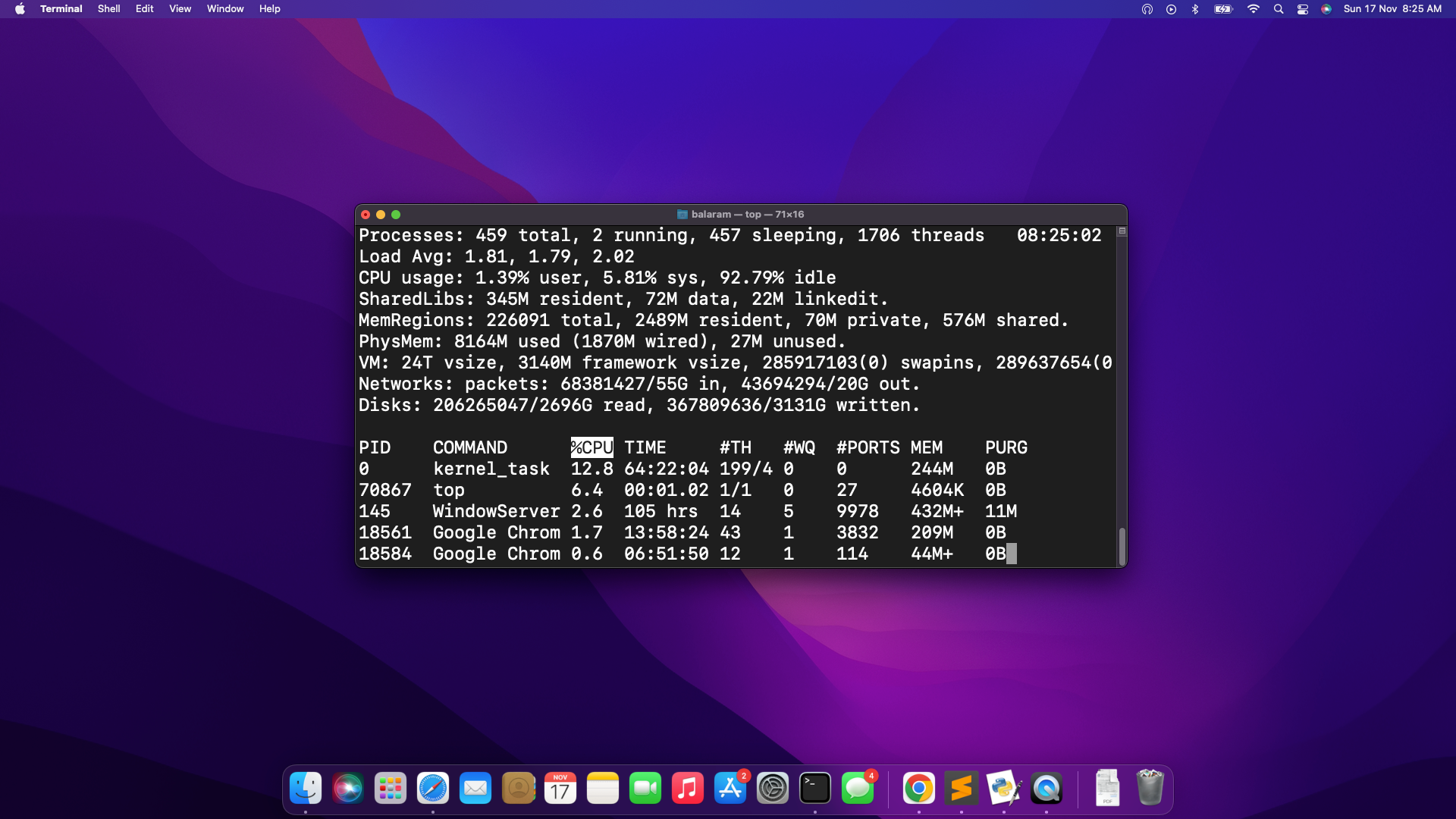
- Deleting a file with filename
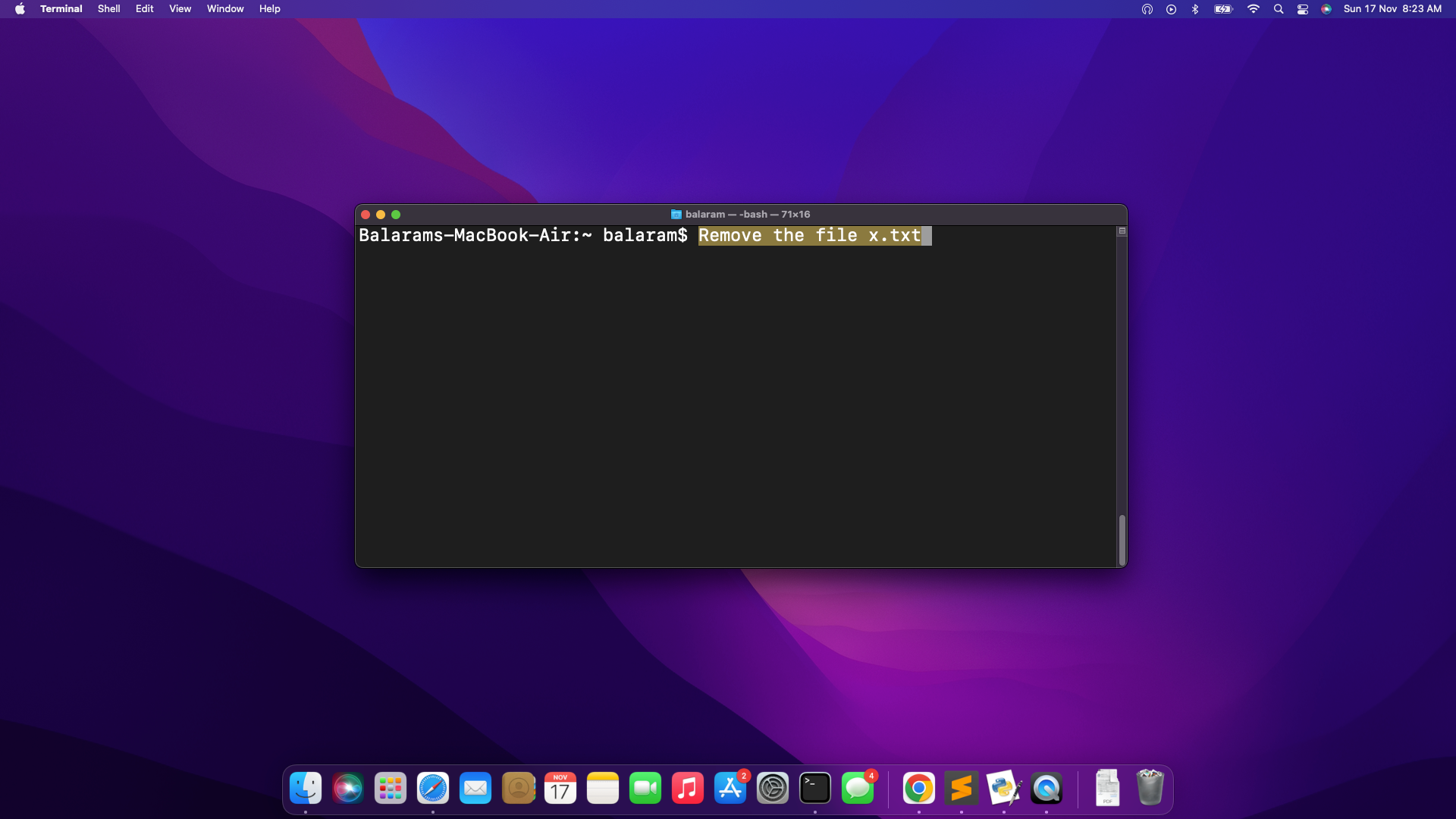
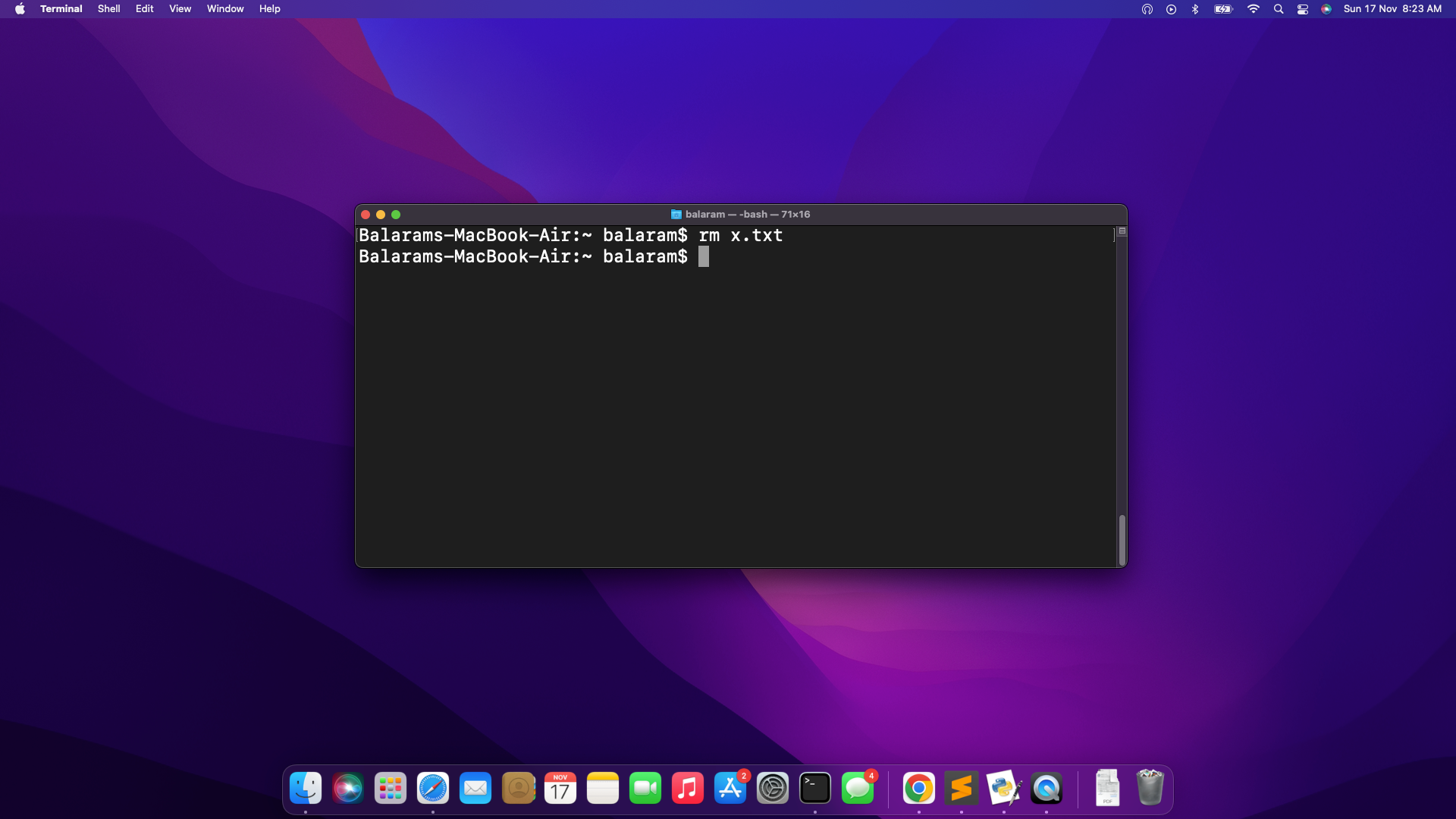
Ideas for customizing the assistant
- Selecting the Proper Mannequin for Your System: Choosing the right language mannequin first.
Acquired a Highly effective PC? (16GB+ RAM)
- Use llama2:70b or mixtral – They provide superb high quality code era however want extra compute energy.
- Excellent for skilled use or when accuracy is essential
Working on a Mid-Vary System? (8-16GB RAM)
- Use llama2:13b or mistral – They provide an ideal steadiness of efficiency and useful resource utilization.
- Nice for every day use and most era wants
Working with Restricted Sources? (4-8GB RAM)
- llama2:7b or phi are good on this vary.
- They’re sooner and lighter however nonetheless get the job achieved
Though these fashions are really useful, one can use different fashions based on their wants.
- Personalizing Keyboard Shortcut : Need to change the F6 key? One can change it to any key! For instance to make use of ‘T’ for translate, or F2 as a result of it is simpler to achieve. It is tremendous simple to vary – simply modify the set off key within the code, and it is good to go.
- Customising the Assistant: Possibly as a substitute of bash helper, one wants assist with writing code in a sure programming language (Java, Python, C++). One simply wants to switch the command era immediate. As an alternative of linux terminal assistant change it to python code author or to the programming language most popular.
Limitations
- Useful resource Constraints: Working massive language fashions usually requires substantial {hardware}. For instance, a minimum of 8 GB of RAM is required to run the 7B fashions, 16 GB to run the 13B fashions, and 32 GB to run the 33B fashions.
- Platform Restrictions: Using
xdotooland particular key mixtures makes the instrument depending on Linux methods and will not work on different working methods with out modifications. - Command Accuracy: The instrument could sometimes produce incorrect or incomplete instructions, particularly for ambiguous or extremely particular duties. In such instances, utilizing a extra superior LLM with higher contextual understanding could also be essential.
- Restricted Customization: With out specialised fine-tuning, generic LLMs may lack contextual changes for industry-specific terminology or user-specific preferences.
For duties like extracting info from paperwork, instruments akin to Nanonets’ Chat with PDF have evaluated and used a number of LLMs like Ministral and may provide a dependable solution to work together with content material, making certain correct knowledge extraction with out danger of misrepresentation.