

{kind=link}
Object detection is pivotal in synthetic intelligence, serving because the spine for quite a few cutting-edge functions. From autonomous autos and surveillance methods to medical imaging and augmented actuality, the flexibility to establish and find objects in photos and movies is remodeling industries worldwide. TensorFlow’s Object Detection API, a robust and versatile device, simplifies constructing strong object detection fashions. By leveraging this API, builders can prepare customized fashions tailor-made to particular wants, considerably lowering improvement time and complexity.
On this information, we are going to discover the step-by-step course of of coaching an object detection mannequin utilizing TensorFlow, specializing in integrating datasets from Roboflow Universe, a wealthy repository of annotated datasets designed to speed up AI improvement.
Studying Targets
- Be taught to arrange and configure TensorFlow‘s Object Detection API surroundings for environment friendly mannequin coaching.
- Perceive methods to put together and preprocess datasets for coaching, utilizing the TFRecord format.
- Acquire experience in deciding on and customizing a pre-trained object detection mannequin for particular wants.
- Be taught to regulate pipeline configuration recordsdata and fine-tune mannequin parameters to optimize efficiency.
- Grasp the coaching course of, together with dealing with checkpoints and evaluating mannequin efficiency throughout coaching.
- Perceive methods to export the educated mannequin for inference and deployment in real-world functions.
This text was printed as part of the Information Science Blogathon.
Step-By-Step Implementation of Object Detection with TensorFlow
On this part, we’ll stroll you thru a step-by-step implementation of object detection utilizing TensorFlow, guiding you from setup to deployment.
Step1: Setting Up the Setting
The TensorFlow Object Detection API requires numerous dependencies. Start by cloning the TensorFlow fashions repository:
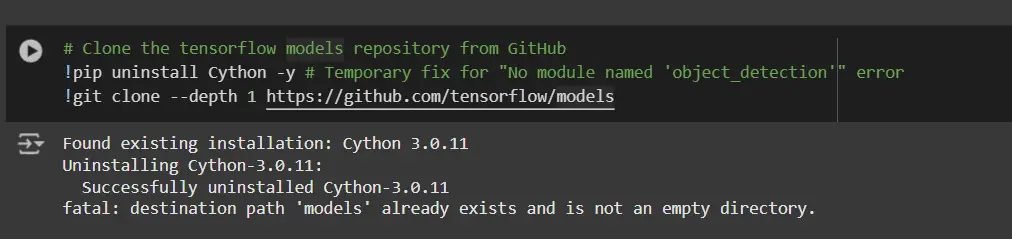
# Clone the tensorflow fashions repository from GitHub
!pip uninstall Cython -y # Short-term repair for "No module named 'object_detection'" error
!git clone --depth 1 https://github.com/tensorflow/fashions- Uninstall Cython: This step ensures there aren’t any conflicts with the Cython library throughout setup.
- Clone TensorFlow Fashions Repository: This repository accommodates TensorFlow’s official fashions, together with the Object Detection API.
Copy the Setup Information and Modify the setup.py File
# Copy setup recordsdata into fashions/analysis folder
%%bash
cd fashions/analysis/
protoc object_detection/protos/*.proto --python_out=.
#cp object_detection/packages/tf2/setup.py .
# Modify setup.py file to put in the tf-models-official repository focused at TF v2.8.0
import re
with open('/content material/fashions/analysis/object_detection/packages/tf2/setup.py') as f:
s = f.learn()
with open('/content material/fashions/analysis/setup.py', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('tf-models-official>=2.5.1',
'tf-models-official==2.8.0', s)
f.write(s)Why is This Mandatory?
- Protocol Buffers Compilation: The Object Detection API makes use of .proto recordsdata to outline mannequin configurations and information buildings. These have to be compiled into Python code to perform.
- Dependency Model Compatibility: TensorFlow and its dependencies evolve. Utilizing tf-models-official>=2.5.1 could inadvertently set up an incompatible model for TensorFlow v2.8.0.
- Explicitly setting tf-models-official==2.8.0 avoids potential model conflicts and ensures stability.
Putting in dependency libraries
TensorFlow fashions usually depend on particular library variations. Fixing the TensorFlow model ensures clean integration.
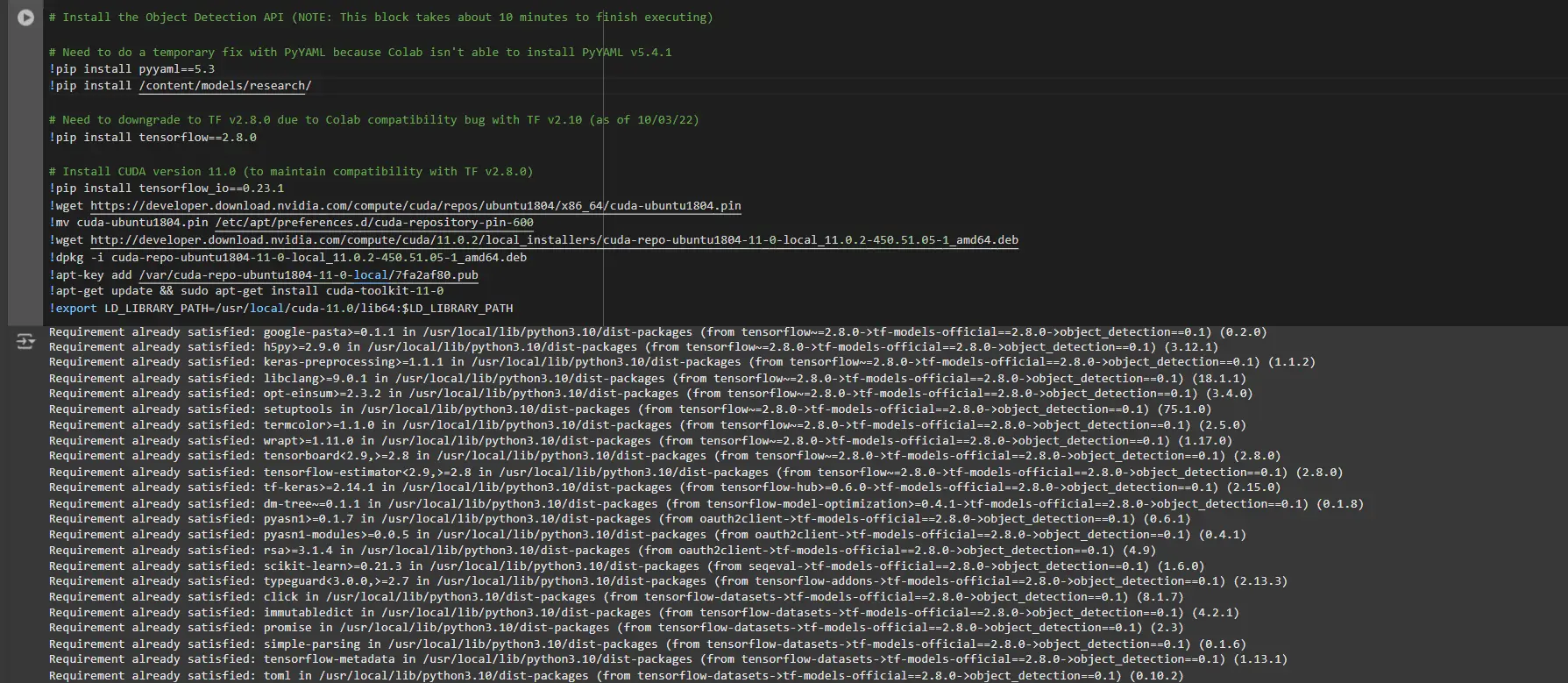
# Set up the Object Detection API
# Must do a short lived repair with PyYAML as a result of Colab is not in a position to set up PyYAML v5.4.1
!pip set up pyyaml==5.3
!pip set up /content material/fashions/analysis/
# Must downgrade to TF v2.8.0 as a result of Colab compatibility bug with TF v2.10 (as of 10/03/22)
!pip set up tensorflow==2.8.0
# Set up CUDA model 11.0 (to take care of compatibility with TF v2.8.0)
!pip set up tensorflow_io==0.23.1
!wget https://developer.obtain.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
!mv cuda-ubuntu1804.pin /and so on/apt/preferences.d/cuda-repository-pin-600
!wget http://developer.obtain.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub
!apt-get replace && sudo apt-get set up cuda-toolkit-11-0
!export LD_LIBRARY_PATH=/usr/native/cuda-11.0/lib64:$LD_LIBRARY_PATHWhereas working this block it’s essential restart the classes once more and run this block of code once more to efficiently set up all dependencies. This can set up all of the dependencies efficiently.
Putting in an acceptable model of protobuf library for resolving dependency points
!pip set up protobuf==3.20.1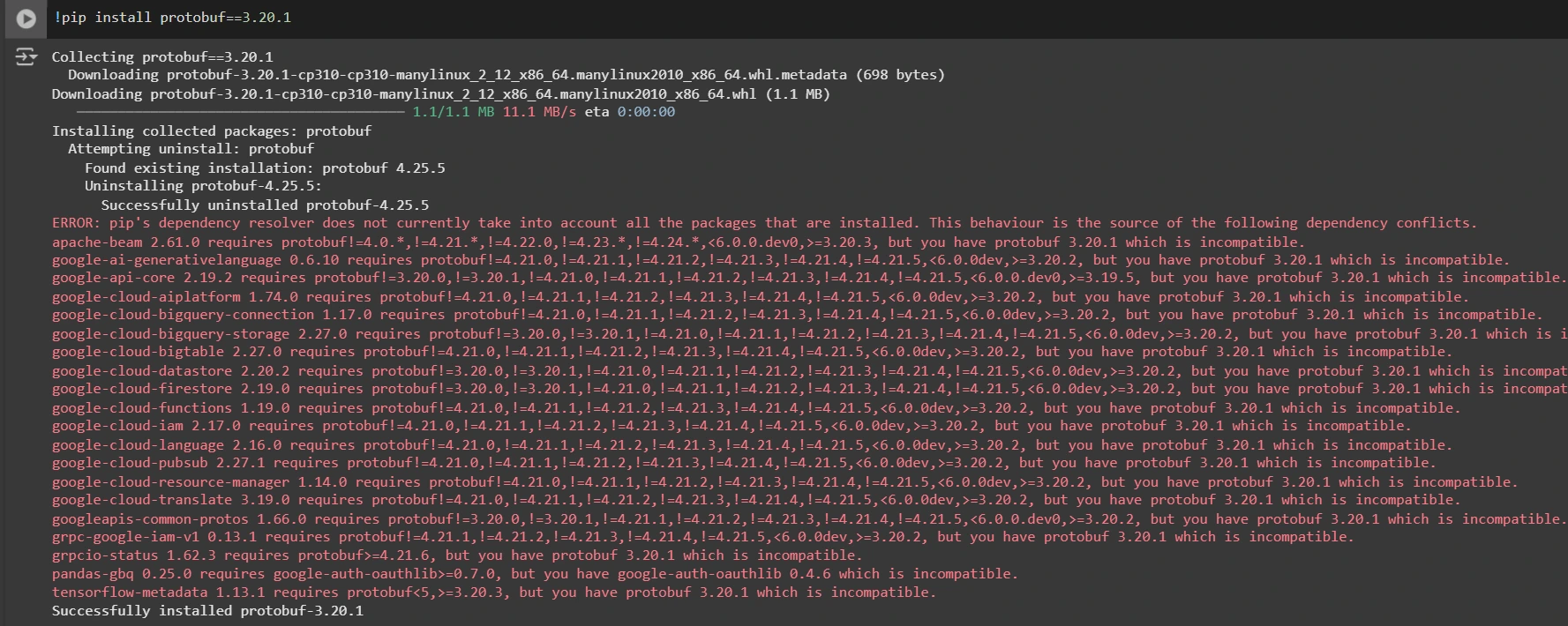
Step2: Confirm Setting and Installations
To verify the set up works, run the next check:
# Run Mannequin Bulider Check file, simply to confirm all the things's working correctly
!python /content material/fashions/analysis/object_detection/builders/model_builder_tf2_test.py
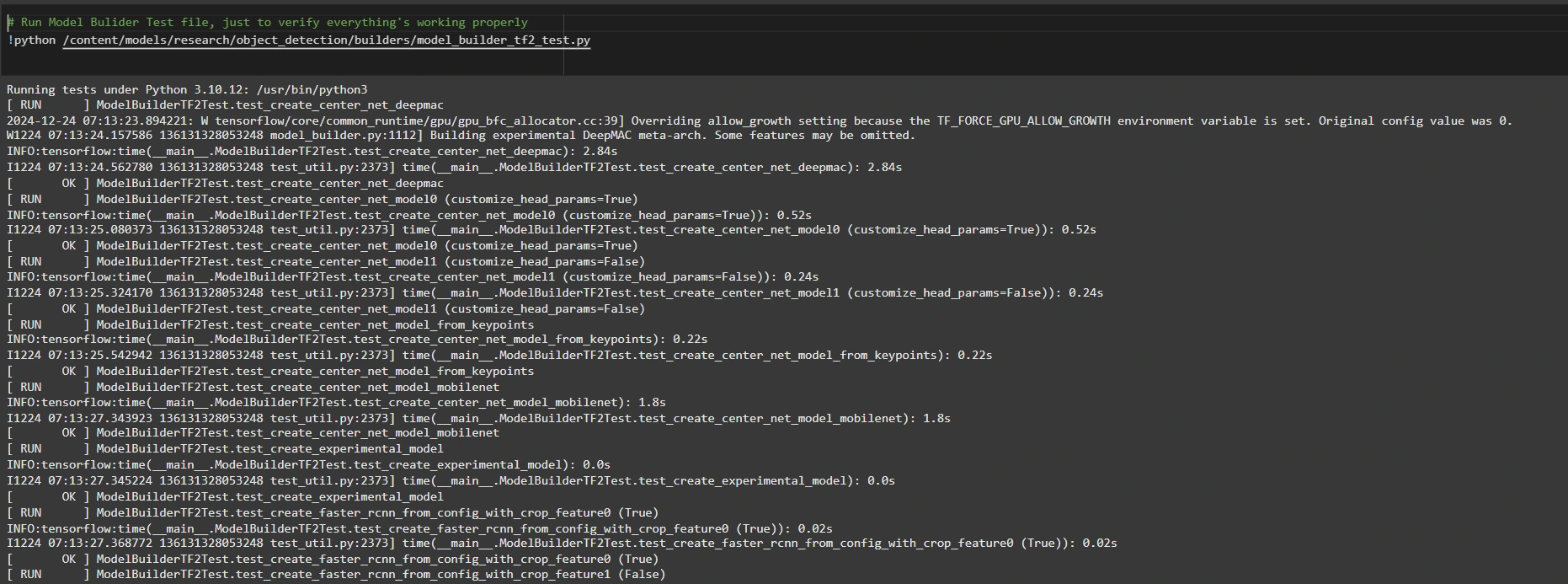
If no errors seem, your setup is full. So now we now have accomplished the setup efficiently.
Step3: Put together the Coaching Information
For this tutorial, we’ll use the “Individuals Detection” dataset from Roboflow Universe. Observe these steps to arrange it:
Go to the dataset web page:

Fork the dataset into your workspace to make it accessible for personalization.
Generate a model of the dataset to finalize its preprocessing configurations akin to augmentation and resizing.
Now , Obtain it in TFRecord format, which is a binary format optimized for TensorFlow workflows. TFRecord shops information effectively and permits TensorFlow to learn giant datasets throughout coaching with minimal overhead.
As soon as downloaded, place the dataset recordsdata in your Google Drive mount your code to your drive, and cargo these recordsdata within the code to make use of it.
from google.colab import drive
drive.mount('/content material/gdrive')
train_record_fname="/content material/gdrive/MyDrive/photos/prepare/prepare.tfrecord"
val_record_fname="/content material/gdrive/MyDrive/photos/check/check.tfrecord"
label_map_pbtxt_fname="/content material/gdrive/MyDrive/photos/label_map.pbtxt"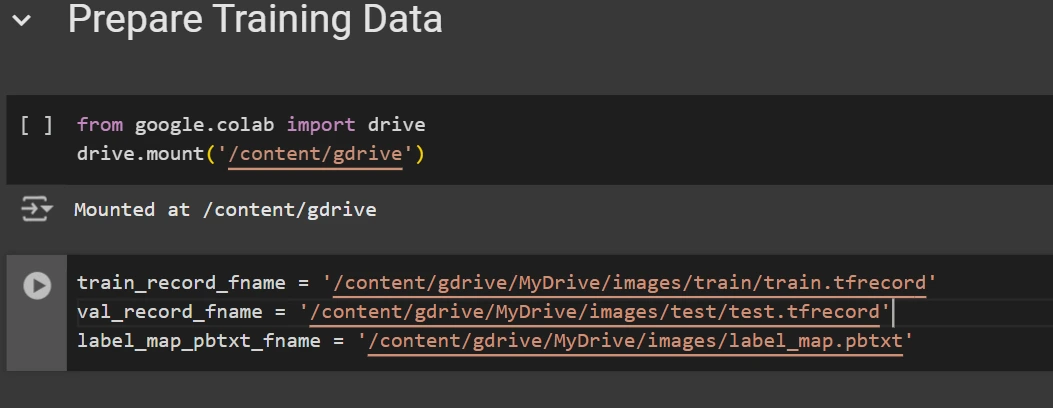
Step4: Set Up the Coaching Configuration
Now, it’s time to arrange the configuration for the article detection mannequin. For this instance, we’ll use the efficientdet-d0 mannequin. You may select from different fashions like ssd-mobilenet-v2 or ssd-mobilenet-v2-fpnlite-320, however for this information, we’ll deal with efficientdet-d0.
# Change the chosen_model variable to deploy totally different fashions obtainable within the TF2 object detection zoo
chosen_model="efficientdet-d0"
MODELS_CONFIG = {
'ssd-mobilenet-v2': {
'model_name': 'ssd_mobilenet_v2_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.tar.gz',
},
'efficientdet-d0': {
'model_name': 'efficientdet_d0_coco17_tpu-32',
'base_pipeline_file': 'ssd_efficientdet_d0_512x512_coco17_tpu-8.config',
'pretrained_checkpoint': 'efficientdet_d0_coco17_tpu-32.tar.gz',
},
'ssd-mobilenet-v2-fpnlite-320': {
'model_name': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.tar.gz',
},
}
model_name = MODELS_CONFIG[chosen_model]['model_name']
pretrained_checkpoint = MODELS_CONFIG[chosen_model]['pretrained_checkpoint']
base_pipeline_file = MODELS_CONFIG[chosen_model]['base_pipeline_file']We then obtain the pre-trained weights and the corresponding configuration file for the chosen mannequin:
# Create "mymodel" folder for holding pre-trained weights and configuration recordsdata
%mkdir /content material/fashions/mymodel/
%cd /content material/fashions/mymodel/
# Obtain pre-trained mannequin weights
import tarfile
download_tar="http://obtain.tensorflow.org/fashions/object_detection/tf2/20200711/" + pretrained_checkpoint
!wget {download_tar}
tar = tarfile.open(pretrained_checkpoint)
tar.extractall()
tar.shut()
# Obtain coaching configuration file for mannequin
download_config = 'https://uncooked.githubusercontent.com/tensorflow/fashions/grasp/analysis/object_detection/configs/tf2/' + base_pipeline_file
!wget {download_config}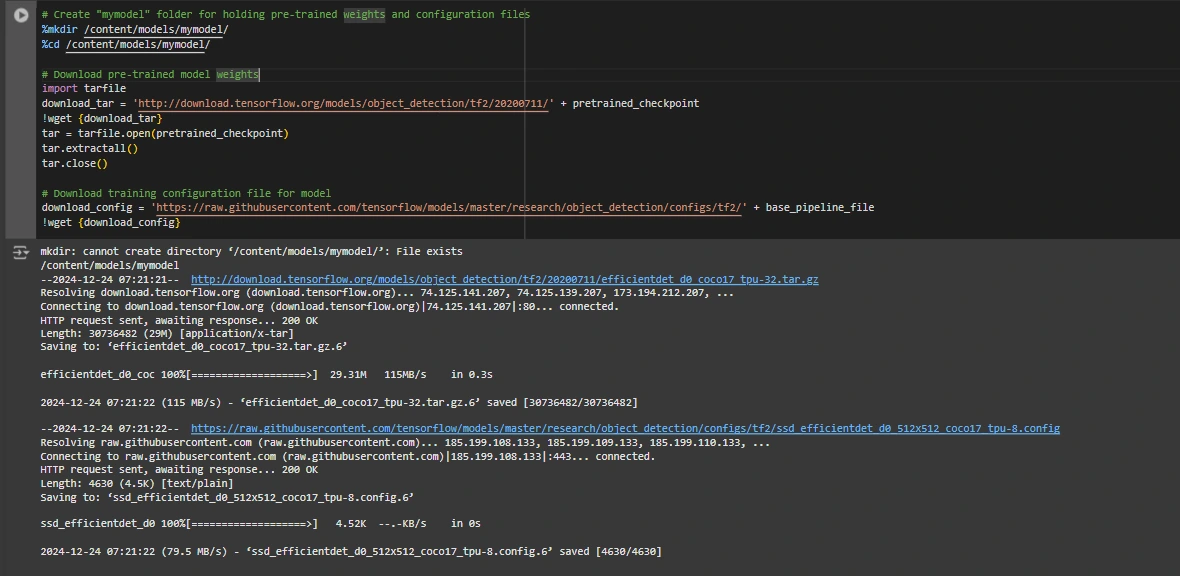
After this, we arrange the variety of steps for coaching and batch measurement primarily based on the mannequin chosen:
# Set coaching parameters for the mannequin
num_steps = 4000
if chosen_model == 'efficientdet-d0':
batch_size = 8
else:
batch_size = 8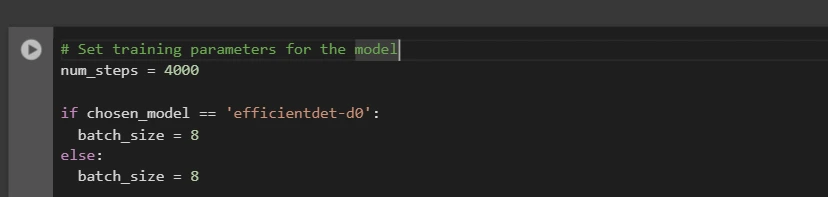
You may improve and reduce num_steps and batch_size in response to your necessities.
Step5: Modify the Pipeline Configuration File
We have to customise the pipeline.config file with the paths to our dataset and mannequin parameters. The pipeline.config file accommodates numerous configurations such because the batch measurement, variety of courses, and fine-tuning checkpoints. We make these modifications by studying the template and changing the related fields:
# Set file areas and get variety of courses for config file
pipeline_fname="/content material/fashions/mymodel/" + base_pipeline_file
fine_tune_checkpoint="/content material/fashions/mymodel/" + model_name + '/checkpoint/ckpt-0'
def get_num_classes(pbtxt_fname):
from object_detection.utils import label_map_util
label_map = label_map_util.load_labelmap(pbtxt_fname)
classes = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=90, use_display_name=True)
category_index = label_map_util.create_category_index(classes)
return len(category_index.keys())
num_classes = get_num_classes(label_map_pbtxt_fname)
print('Complete courses:', num_classes)
# Create customized configuration file by writing the dataset, mannequin checkpoint, and coaching parameters into the bottom pipeline file
import re
%cd /content material/fashions/mymodel
print('writing customized configuration file')
with open(pipeline_fname) as f:
s = f.learn()
with open('pipeline_file.config', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('fine_tune_checkpoint: ".*?"',
'fine_tune_checkpoint: "{}"'.format(fine_tune_checkpoint), s)
# Set tfrecord recordsdata for prepare and check datasets
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/prepare)(.*?")', 'input_path: "{}"'.format(train_record_fname), s)
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/val)(.*?")', 'input_path: "{}"'.format(val_record_fname), s)
# Set label_map_path
s = re.sub(
'label_map_path: ".*?"', 'label_map_path: "{}"'.format(label_map_pbtxt_fname), s)
# Set batch_size
s = re.sub('batch_size: [0-9]+',
'batch_size: {}'.format(batch_size), s)
# Set coaching steps, num_steps
s = re.sub('num_steps: [0-9]+',
'num_steps: {}'.format(num_steps), s)
# Set variety of courses num_classes
s = re.sub('num_classes: [0-9]+',
'num_classes: {}'.format(num_classes), s)
# Change fine-tune checkpoint sort from "classification" to "detection"
s = re.sub(
'fine_tune_checkpoint_type: "classification"', 'fine_tune_checkpoint_type: "{}"'.format('detection'), s)
# If utilizing ssd-mobilenet-v2, scale back studying price (as a result of it is too excessive within the default config file)
if chosen_model == 'ssd-mobilenet-v2':
s = re.sub('learning_rate_base: .8',
'learning_rate_base: .08', s)
s = re.sub('warmup_learning_rate: 0.13333',
'warmup_learning_rate: .026666', s)
# If utilizing efficientdet-d0, use fixed_shape_resizer as an alternative of keep_aspect_ratio_resizer (as a result of it is not supported by TFLite)
if chosen_model == 'efficientdet-d0':
s = re.sub('keep_aspect_ratio_resizer', 'fixed_shape_resizer', s)
s = re.sub('pad_to_max_dimension: true', '', s)
s = re.sub('min_dimension', 'peak', s)
s = re.sub('max_dimension', 'width', s)
f.write(s)
# (Elective) Show the customized configuration file's contents
!cat /content material/fashions/mymodel/pipeline_file.config
# Set the trail to the customized config file and the listing to retailer coaching checkpoints in
pipeline_file="/content material/fashions/mymodel/pipeline_file.config"
model_dir="/content material/coaching/"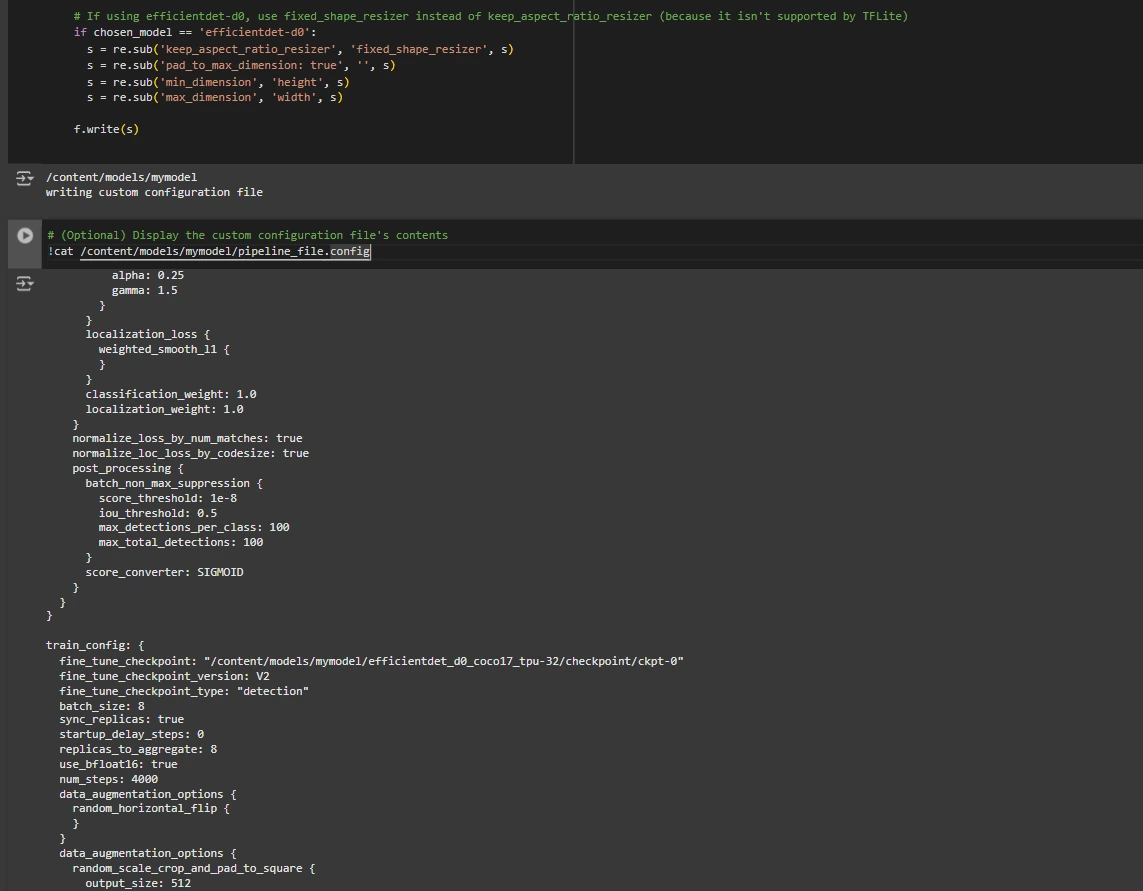
Step6: Prepare the Mannequin
Now we will prepare the mannequin utilizing the customized pipeline configuration file. The coaching script will save checkpoints, which you should use to judge the efficiency of your mannequin:
# Run coaching!
!python /content material/fashions/analysis/object_detection/model_main_tf2.py
--pipeline_config_path={pipeline_file}
--model_dir={model_dir}
--alsologtostderr
--num_train_steps={num_steps}
--sample_1_of_n_eval_examples=1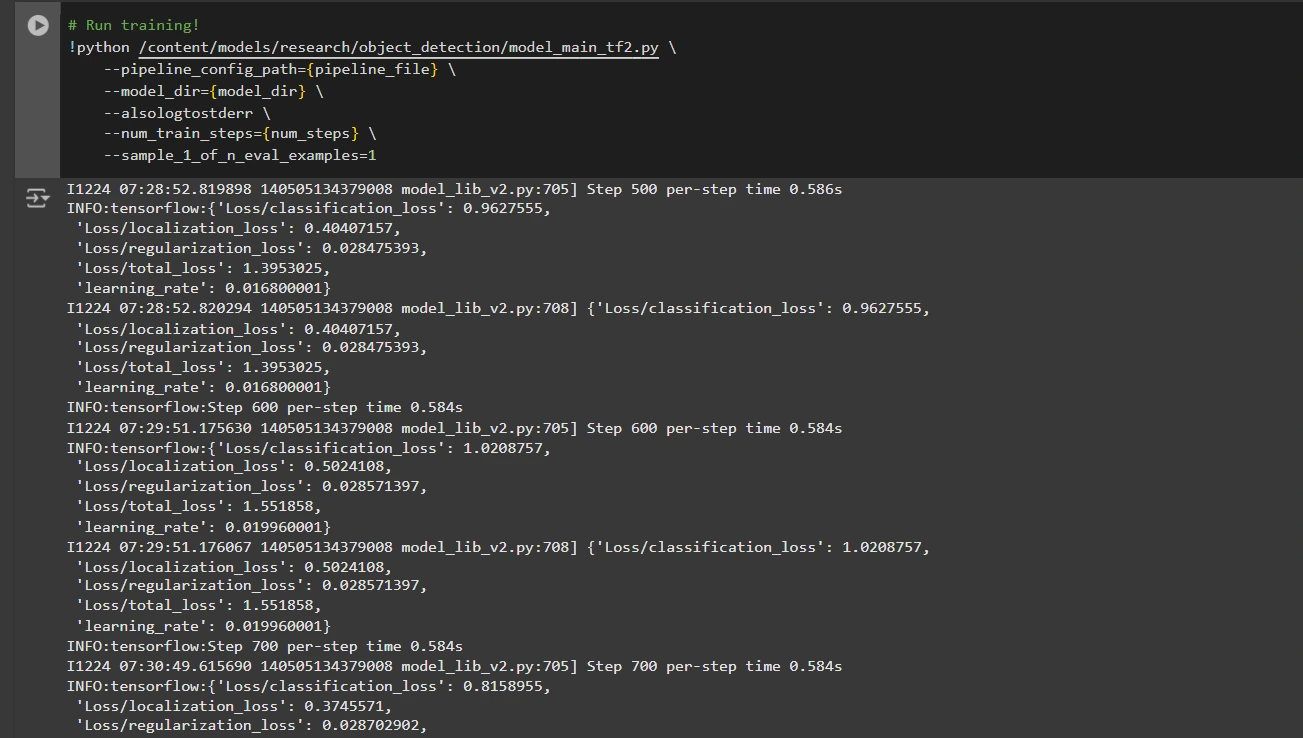
Step7: Save the Skilled Mannequin
After coaching is full, we export the educated mannequin so it may be used for inference. We use the exporter_main_v2.py script to export the mannequin:
!python /content material/fashions/analysis/object_detection/exporter_main_v2.py
--input_type image_tensor
--pipeline_config_path {pipeline_file}
--trained_checkpoint_dir {model_dir}
--output_directory /content material/exported_model
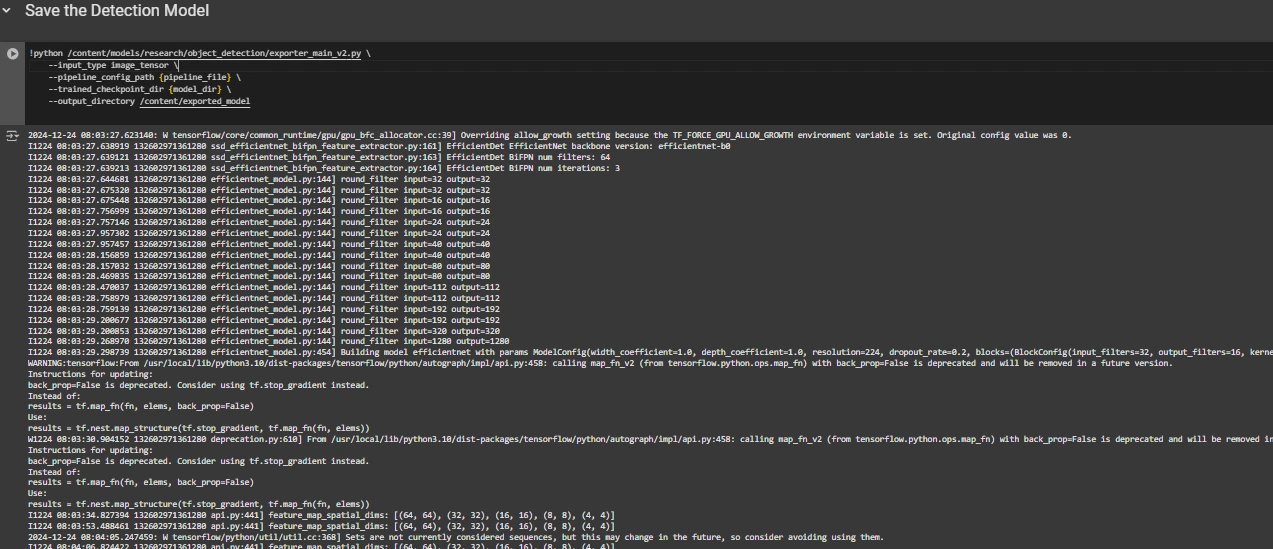
Lastly, we compress the exported mannequin into a zipper file for straightforward downloading after which you’ll be able to obtain the zip file containing your educated mannequin:
import shutil
# Path to the exported mannequin folder
exported_model_path="/content material/exported_model"
# Path the place the zip file shall be saved
zip_file_path="/content material/exported_model.zip"
# Create a zipper file of the exported mannequin folder
shutil.make_archive(zip_file_path.change('.zip', ''), 'zip', exported_model_path)
# Obtain the zip file utilizing Google Colab's file obtain utility
from google.colab import recordsdata
recordsdata.obtain(zip_file_path)
You should use these downloaded mannequin recordsdata for testing it on unseen photos or in your functions in response to your wants.
You may consult with this: collab pocket book for detailed code
Conclusion
In conclusion, this information equips you with the information and instruments mandatory to coach an object detection mannequin utilizing TensorFlow’s Object Detection API, leveraging datasets from Roboflow Universe for speedy customization. By following the steps outlined, you’ll be able to successfully put together your information, configure the coaching pipeline, choose the appropriate mannequin, and fine-tune it to satisfy your particular wants. Furthermore, the flexibility to export and deploy your educated mannequin opens up huge potentialities for real-world functions, whether or not in autonomous autos, medical imaging, or surveillance methods. This workflow allows you to create highly effective, scalable object detection methods with decreased complexity and sooner time to deployment.
Key Takeaways
- TensorFlow Object Detection API provides a versatile framework for constructing customized object detection fashions with pre-trained choices, lowering improvement time and complexity.
- TFRecord format is crucial for environment friendly information dealing with, particularly with giant datasets in TensorFlow, permitting quick coaching and minimal overhead.
- Pipeline configuration recordsdata are essential for fine-tuning and adjusting the mannequin to work along with your particular dataset and desired efficiency traits.
- Pretrained fashions like efficientdet-d0 and ssd-mobilenet-v2 present strong beginning factors for coaching customized fashions, with every having particular strengths relying on use case and useful resource constraints.
- The coaching course of includes managing parameters like batch measurement, variety of steps, and mannequin checkpointing to make sure the mannequin learns optimally.
- Exporting the mannequin is crucial for utilizing the educated object detection mannequin in a real-world mannequin that’s being packaged and prepared for deployment.
Ceaselessly Requested Questions
A: The TensorFlow Object Detection API is a versatile and open-source framework for creating, coaching, and deploying customized object detection fashions. It gives instruments for fine-tuning pre-trained fashions and constructing options tailor-made to particular use circumstances.
A: TFRecord is a binary file format optimized for TensorFlow pipelines. It permits environment friendly information dealing with, guaranteeing sooner loading, minimal I/O overhead, and smoother coaching, particularly with giant datasets.
A: These recordsdata allow seamless mannequin customization by defining parameters like dataset paths, studying price, mannequin structure, and coaching steps to satisfy particular datasets and efficiency targets.
A: Choose EfficientDet-D0 for a stability of accuracy and effectivity, perfect for edge gadgets, and SSD-MobileNet-V2 for light-weight, quick real-time functions like cellular apps.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.
I am Neha Dwivedi, a Information Science fanatic , Graduated from MIT World Peace College,Pune. I am enthusiastic about Information Science and rising tendencies with it. I am excited to share insights and be taught from this group!