

{kind=link}
Diffusion-based massive language fashions (LLMs) are being explored as a promising various to conventional autoregressive fashions, providing the potential for simultaneous multi-token era. By utilizing bidirectional consideration mechanisms, these fashions purpose to speed up decoding, theoretically offering quicker inference than autoregressive programs. Nevertheless, regardless of their promise, diffusion fashions typically battle in observe to ship aggressive inference speeds, thereby limiting their skill to match the real-world efficiency of autoregressive massive language fashions LLMs.
The first problem lies within the inefficiency of inference in diffusion-based LLMs. These fashions usually don’t help key-value (KV) cache mechanisms, that are important for accelerating inference by reusing beforehand computed consideration states. With out KV caching, each new era step in diffusion fashions repeats full consideration computations, making them computationally intensive. Additional, when decoding a number of tokens concurrently—a key function of diffusion fashions—the era high quality typically deteriorates resulting from disruptions in token dependencies below the conditional independence assumption. This makes diffusion fashions unreliable for sensible deployment regardless of their theoretical strengths.
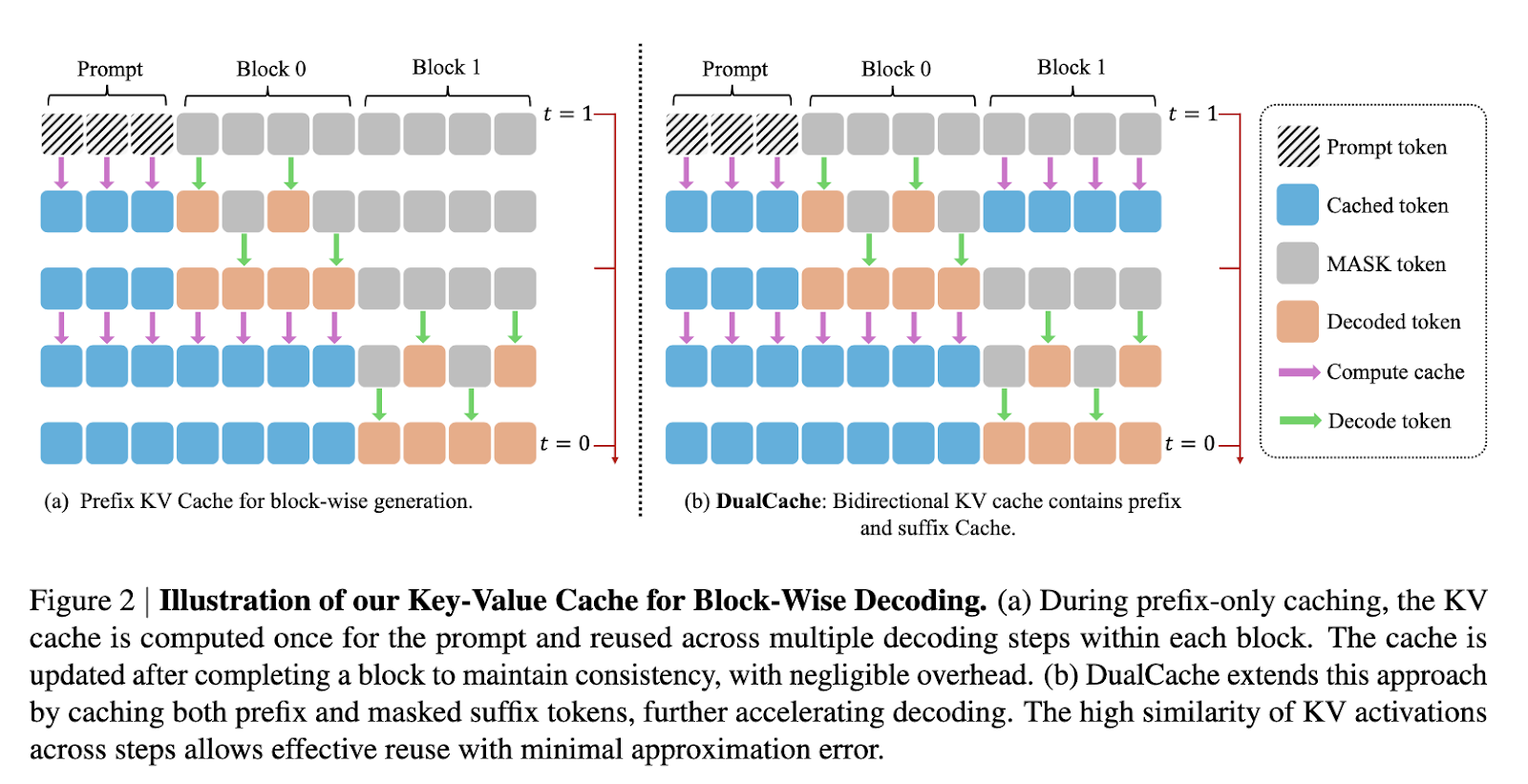
Makes an attempt to enhance diffusion LLMs have centered on methods like block-wise era and partial caching. For example, fashions similar to LLaDA and Dream incorporate masked diffusion strategies to facilitate multi-token era. Nevertheless, they nonetheless lack an efficient key-value (KV) cache system, and parallel decoding in these fashions typically ends in incoherent outputs. Whereas some approaches use auxiliary fashions to approximate token dependencies, these strategies introduce further complexity with out absolutely addressing the underlying efficiency points. In consequence, the velocity and high quality of era in diffusion LLMs proceed to lag behind autoregressive fashions.
Researchers from NVIDIA, The College of Hong Kong, and MIT launched Quick-dLLM, a framework developed to deal with these limitations with out requiring retraining. Quick-dLLM brings two improvements to diffusion LLMs: a block-wise approximate KV Cache mechanism and a confidence-aware parallel decoding technique. The approximate KV Cache is tailor-made for the bidirectional nature of diffusion fashions, permitting activations from earlier decoding steps to be reused effectively. The arrogance-aware parallel decoding selectively decodes tokens primarily based on a confidence threshold, lowering errors that come up from the idea of token independence. This strategy gives a steadiness between velocity and era high quality, making it a sensible resolution for diffusion-based textual content era duties.
In-depth, Quick-dLLM’s KV Cache technique is carried out by dividing sequences into blocks. Earlier than producing a block, KV activations for different blocks are computed and saved, enabling reuse throughout subsequent decoding steps. After producing a block, the cache is up to date throughout all tokens, which minimizes computation redundancy whereas sustaining accuracy. The DualCache model extends this strategy by caching each prefix and suffix tokens, profiting from excessive similarity between adjoining inference steps, as demonstrated by cosine similarity heatmaps within the paper. For the parallel decoding part, the system evaluates the boldness of every token and decodes solely these exceeding a set threshold. This prevents dependency violations from simultaneous sampling and ensures higher-quality era even when a number of tokens are decoded in a single step.

Quick-dLLM achieved important efficiency enhancements in benchmark assessments. On the GSM8K dataset, as an illustration, it achieved a 27.6× speedup over baseline fashions in 8-shot configurations at a era size of 1024 tokens, with an accuracy of 76.0%. On the MATH benchmark, a 6.5× speedup was achieved with an accuracy of round 39.3%. The HumanEval benchmark noticed as much as a 3.2× acceleration with accuracy maintained at 54.3%, whereas on MBPP, the system achieved a 7.8× speedup at a era size of 512 tokens. Throughout all duties and fashions, accuracy remained inside 1–2 factors of the baseline, exhibiting that Quick-dLLM’s acceleration doesn’t considerably degrade output high quality.
The analysis workforce successfully addressed the core bottlenecks in diffusion-based LLMs by introducing a novel caching technique and a confidence-driven decoding mechanism. By addressing inference inefficiency and enhancing decoding high quality, Quick-dLLM demonstrates how diffusion LLMs can strategy and even surpass autoregressive fashions in velocity whereas sustaining excessive accuracy, making them viable for deployment in real-world language era functions.
Take a look at the Paper and Mission Web page . All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 95k+ ML SubReddit and Subscribe to our Publication.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
