


{kind=link}
Introduction
Selecting the best GPU is a important determination when working machine studying and LLM workloads. You want sufficient compute to run your fashions effectively with out overspending on pointless energy. On this publish, we evaluate two stable choices: NVIDIA’s A10 and the newer L40S GPUs. We’ll break down their specs, efficiency benchmarks towards LLMs, and pricing that will help you select primarily based in your workload.
There may be additionally a rising problem within the business. Almost 40% of corporations battle to run AI tasks as a result of restricted entry to GPUs. The demand is outpacing provide, making it more durable to scale reliably. That is the place flexibility turns into necessary. Counting on a single cloud or {hardware} supplier can decelerate your tasks. We’ll discover how Clarifai’s Compute Orchestration helps you entry each A10 and L40S GPUs, providing you with the liberty to modify primarily based on availability and workload wants whereas avoiding vendor lock-in.
Let’s dive in and check out these two completely different GPU architectures.
Ampere GPUs (NVIDIA A10)
NVIDIA’s Ampere structure, launched in 2020, launched third-generation Tensor Cores optimized for mixed-precision compute (FP16, TF32, INT8) and improved Multi-Occasion GPU (MIG) help. The A10 GPU is designed for cost-effective AI inference, laptop imaginative and prescient, and graphics-heavy workloads. It handles mid-sized LLMs, imaginative and prescient fashions, and video duties effectively. With second-gen RT Cores and RTX Digital Workstation (vWS) help, the A10 is a stable alternative for working graphics and AI workloads on virtualized infrastructure.
Ada Lovelace GPUs (NVIDIA L40S)
The Ada Lovelace structure takes efficiency and effectivity additional, designed for contemporary AI and graphics workloads. The L40S GPU options fourth-gen Tensor Cores with FP8 precision help, delivering vital acceleration for giant LLMs, generative AI, and fine-tuning. It additionally provides third-gen RT Cores and AV1 {hardware} encoding, making it a robust match for advanced 3D graphics, rendering, and media pipelines. Lovelace structure permits the L40S to deal with multi-workload environments the place AI compute and high-end graphics run aspect by aspect.
A10 vs. L40S: Specs Comparability
Core Rely and Clock Speeds
The L40S contains a greater CUDA core depend than the A10, offering better parallel processing energy for AI and ML workloads. CUDA cores are specialised GPU cores designed to deal with advanced computations in parallel, which is important for accelerating AI duties.
The L40S additionally runs at the next increase clock of 2520 MHz, a 49% enhance over the A10’s 1695 MHz, leading to quicker compute efficiency.
VRAM Capability and Reminiscence Bandwidth
The L40S affords 48 GB of VRAM, double the A10’s 24 GB, permitting it to deal with bigger fashions and datasets extra effectively. Its reminiscence bandwidth can also be greater at 864.0 GB/s in comparison with the A10’s 600.2 GB/s, enhancing knowledge throughput throughout memory-intensive duties.
A10 vs L40S: Efficiency
How do the A10 and L40S evaluate in real-world LLM inference? Our analysis crew benchmarked the MiniCPM-4B, Phi4-mini-instruct, and Llama-3.2-3b-instruct fashions working in FP16 (half-precision) on each GPUs. FP16 permits quicker efficiency and decrease reminiscence utilization—good for large-scale AI workloads.
We examined latency (the time taken to generate every token and full a full request, measured in seconds) and throughput (the variety of tokens processed per second) throughout varied eventualities. Each metrics are essential for evaluating LLM efficiency in manufacturing.
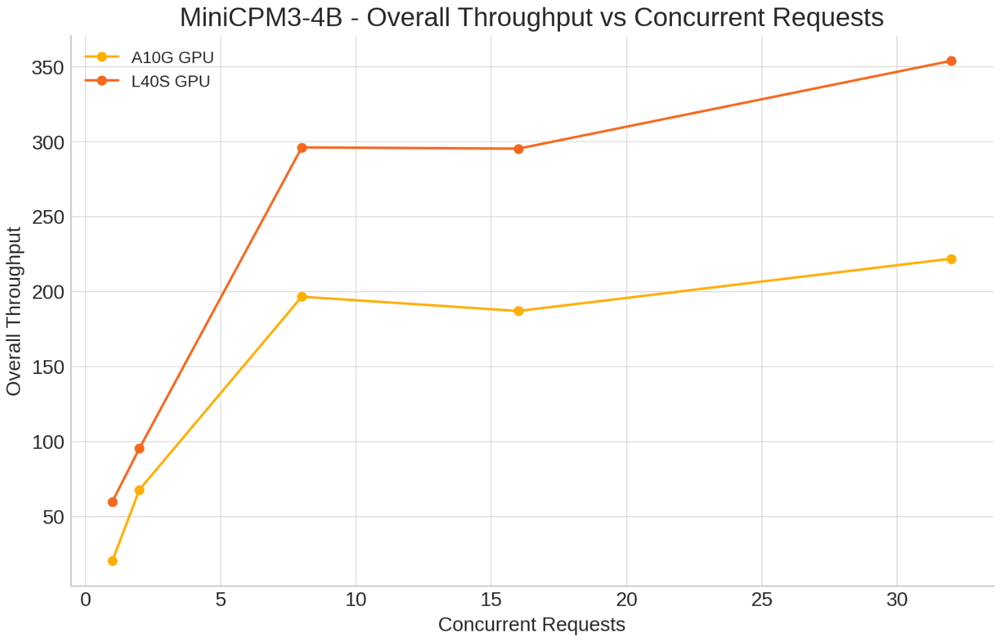
MiniCPM-4B
Situations examined:
- Concurrent Requests: 1, 2, 8, 16, 32
- Enter tokens: 500
- Output Tokens: 150
Key Insights:
Single Concurrent Request: L40S considerably improved latency per token (0.016s vs. 0.047s on A10G) and elevated end-to-end throughput from 97.21 to 296.46 tokens/sec.
Increased Concurrency (32 concurrent requests): L40S maintained higher latency (0.067s vs. 0.088s) and throughput of 331.96 tokens/sec, whereas A10G reached 258.22 tokens/sec.
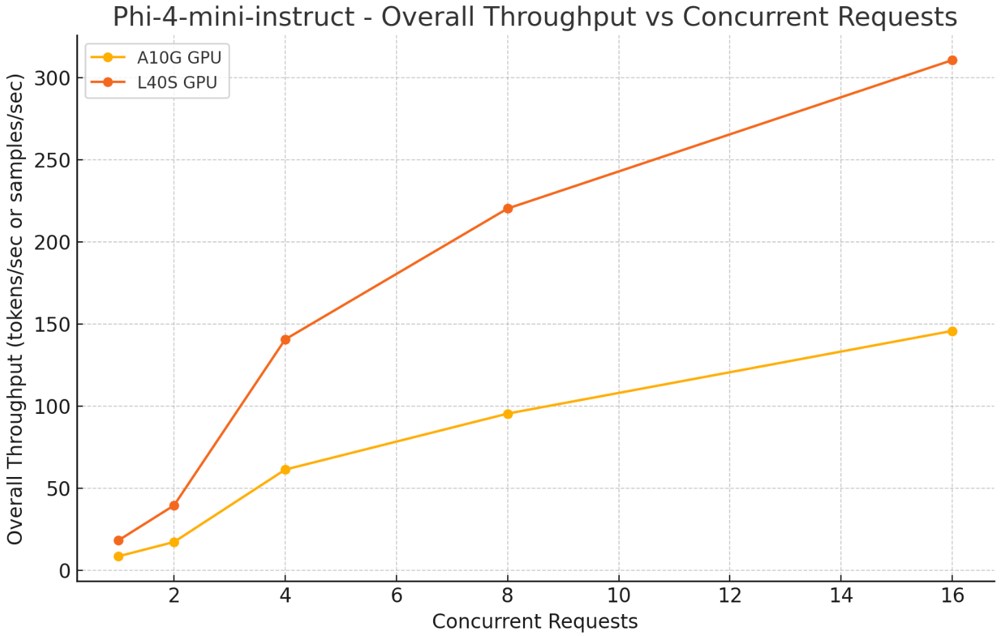
Phi4-mini-instruct
Situations examined:
- Concurrent Requests: 1, 2, 8, 16, 32
- Enter Tokens: 500
- Output Tokens: 150
Key Insights:
- Single Concurrent Request: L40S lower latency per token from 0.02s (A10) to 0.013s and improved general throughput from 56.16 to 85.18 tokens/sec.
- Increased Concurrency (32 concurrent requests): L40S achieved 590.83 tokens/sec throughput with 0.03s latency per token, surpassing A10’s 353.69 tokens/sec.
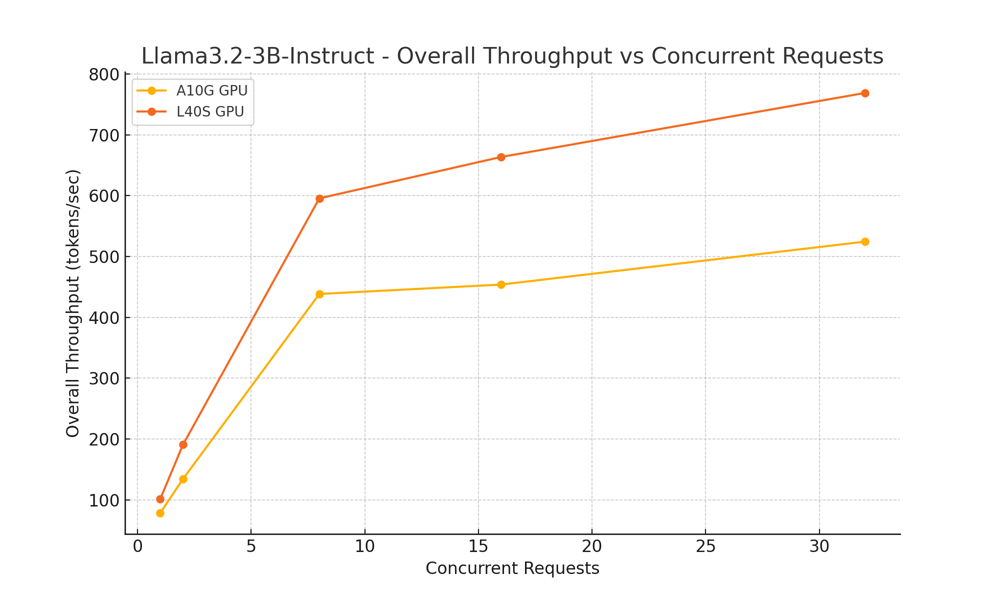
Llama-3.2-3b-instruct
Situations Examined:
- Concurrent Requests: 1, 2, 8, 16, 32
- Enter tokens: 500
- Output Tokens: 150
Key Insights:
- Single Concurrent Request: L40S improved latency per token from 0.015s (A10) to 0.012s, with throughput growing from 76.92 to 95.34 tokens/sec.
- Increased Concurrency (32 concurrent requests): L40S delivered 609.58 tokens/sec throughput, outperforming A10’s 476.63 tokens/sec, and diminished latency per token from 0.039s (A10) to 0.027s.
Throughout all examined fashions, the NVIDIA L40S GPU constantly outperformed the A10 in decreasing latency and enhancing throughput.
Whereas the L40S demonstrates robust efficiency enhancements, it’s equally necessary to think about components akin to value and useful resource necessities. Upgrading to the L40S might require the next upfront funding, so groups ought to fastidiously consider the trade-offs primarily based on their particular use instances, scale, and finances.
Now, let’s take a better take a look at how the A10 and L40S evaluate when it comes to pricing.
A10 vs L40S: Pricing
Whereas the L40S is extra highly effective than the A10, it’s additionally considerably dearer to run. Based mostly on Clarifai’s Compute Orchestration pricing, the L40S occasion (g6e.xlarge) prices $2.34 per hour, almost double the price of the A10-equipped occasion (g5.xlarge) at $1.26 per hour.
There are two variants out there for each A10 and L40S:
- A10 is available in g5.xlarge ($1.26/hour) and g5.2xlarge ($1.512/hour) configurations.
- L40S is available in g6e.xlarge ($2.34/hour) and g6e.12xlarge ($13.104/hour) for bigger workloads.

Selecting the Proper GPU
Choosing between the NVIDIA A10 and L40S relies on your workload calls for and finances issues:
- NVIDIA A10 is well-suited for enterprises in search of a cheap GPU able to dealing with combined workloads, together with AI inference, machine studying, {and professional} visualization. Its decrease energy consumption and stable efficiency make it a sensible alternative for mainstream functions the place excessive compute energy isn’t required.
- NVIDIA L40S is designed for organizations working compute-intensive workloads akin to generative AI and LLM inference. With considerably greater efficiency and reminiscence bandwidth, the L40S delivers the scalability wanted for demanding AI and graphics duties, making it a robust funding for manufacturing environments that require top-tier GPU energy.
Scaling AI Workloads with Flexibility and Reliability
Now we have seen the distinction between the A10 and L40S and the way choosing the proper GPU relies on your particular use case and efficiency wants. However the subsequent query is—how do you entry these GPUs in your AI workloads?
One of many rising challenges in AI and machine studying growth is navigating the worldwide GPU scarcity whereas avoiding dependence on a single cloud supplier. Excessive-demand GPUs just like the L40S, with its superior efficiency, aren’t at all times available once you want them. Then again, whereas the A10 is extra accessible and cost-effective, availability can nonetheless fluctuate relying on the cloud area or supplier.
That is the place Clarifai’s Compute Orchestration is available in. It offers you versatile, on-demand entry to each A10 and L40S GPUs throughout a number of cloud suppliers and personal infrastructure with out locking you right into a single vendor. You’ll be able to select the cloud supplier and area the place you need to deploy, akin to AWS, GCP, Azure, Vultr, or Oracle, and run your AI workloads on devoted GPU clusters inside these environments.
Whether or not your workload wants the effectivity of the A10 or the ability of the L40S, Clarifai routes your jobs to the assets you choose whereas optimizing for availability, efficiency, and value. This method helps you keep away from delays attributable to GPU shortages or pricing spikes and provides you the pliability to scale your AI tasks with confidence with out being tied to at least one supplier.
Conclusion
Selecting the best GPU comes all the way down to understanding your workload necessities and efficiency objectives. The NVIDIA A10 affords a cheap possibility for combined AI and graphics workloads, whereas the L40S delivers the ability and scalability wanted for demanding duties like generative AI and huge language fashions. By matching your GPU option to your particular use case, you’ll be able to obtain the suitable steadiness of efficiency, effectivity, and value.
Clarifai’s Compute Orchestration makes it simple to entry each A10 and L40S GPUs throughout a number of cloud suppliers, providing you with the pliability to scale with out being restricted by availability or vendor lock-in.
For a breakdown of GPU prices and to check pricing throughout completely different deployment choices, go to the Clarifai Pricing web page. You can even be part of our Discord channel anytime to attach with consultants, get your questions answered about choosing the proper GPU in your workloads, or get assist optimizing your AI infrastructure.