

{kind=link}
Simply months after releasing M2—a quick, low-cost mannequin designed for brokers and code—MiniMax has launched an enhanced model: MiniMax M2.1.
M2 already stood out for its effectivity, operating at roughly 8% of the price of Claude Sonnet whereas delivering considerably larger velocity. Extra importantly, it launched a special computational and reasoning sample, notably in how the mannequin constructions and executes its considering throughout advanced code and tool-driven workflows.
M2.1 builds on this basis, bringing tangible enhancements throughout key areas: higher code high quality, smarter instruction following, cleaner reasoning, and stronger efficiency throughout a number of programming languages. These upgrades prolong the unique strengths of M2 whereas staying true to MiniMax’s imaginative and prescient of “Intelligence with Everybody.”
Strengthening the core capabilities of M2, M2.1 is not nearly higher coding—it additionally produces clearer, extra structured outputs throughout conversations, documentation, and writing.
- Constructed for real-world coding and AI-native groups: Designed to help all the things from fast “vibe builds” to advanced, production-grade workflows.
- Goes past coding: Produces clearer, extra structured, and higher-quality outputs throughout on a regular basis conversations, technical documentation, and writing duties.
- State-of-the-art multilingual coding efficiency: Achieves 72.5% on SWE-Multilingual, outperforming Claude Sonnet 4.5 and Gemini 3 Professional throughout a number of programming languages.
- Robust AppDev & WebDev capabilities: Scores 88.6% on VIBE-Bench, exceeding Claude Sonnet 4.5 and Gemini 3 Professional, with main enhancements in native Android, iOS, and trendy internet improvement.
- Wonderful agent and gear compatibility: Delivers constant and secure efficiency throughout main coding instruments and agent frameworks, together with Claude Code, Droid (Manufacturing unit AI), Cline, Kilo Code, Roo Code, BlackBox, and extra.
- Sturdy context administration help: Works reliably with superior context mechanisms akin to Talent.md, Claude.md / agent.md / cursorrule, and Slash Instructions, enabling scalable agent workflows.
- Automated caching, zero configuration: Constructed-in caching works out of the field to cut back latency, decrease prices, and ship a smoother total expertise.
To get began with MiniMax M2.1, you’ll want an API key from the MiniMax platform. You may generate one from the MiniMax consumer console.
As soon as issued, retailer the API key securely and keep away from exposing it in code repositories or public environments.
Putting in & Establishing the dependencies
MiniMax helps each the Anthropic and OpenAI API codecs, making it simple to combine MiniMax fashions into current workflows with minimal configuration adjustments—whether or not you’re utilizing Anthropic-style message APIs or OpenAI-compatible setups.
import os
from getpass import getpass
os.environ['ANTHROPIC_BASE_URL'] = 'https://api.minimax.io/anthropic'
os.environ['ANTHROPIC_API_KEY'] = getpass('Enter MiniMax API Key: ')With simply this minimal setup, you’re prepared to start out utilizing the mannequin.
Sending Requests to the Mannequin
MiniMax M2.1 returns structured outputs that separate inner reasoning (considering) from the ultimate response (textual content). This lets you observe how the mannequin interprets intent and plans its reply earlier than producing the user-facing output.
import anthropic
shopper = anthropic.Anthropic()
message = shopper.messages.create(
mannequin="MiniMax-M2.1",
max_tokens=1000,
system="You're a useful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, how are you?"
}
]
}
]
)
for block in message.content material:
if block.sort == "considering":
print(f"Pondering:n{block.considering}n")
elif block.sort == "textual content":
print(f"Textual content:n{block.textual content}n")Pondering:
The consumer is simply asking how I'm doing. It is a pleasant greeting, so I ought to reply in a heat, conversational approach. I will preserve it easy and pleasant.
Textual content:
Hello! I am doing properly, thanks for asking! 😊
I am prepared that can assist you with no matter you want at present. Whether or not it is coding, answering questions, brainstorming concepts, or simply chatting, I am right here for you.
What can I enable you with?What makes MiniMax stand out is the visibility into its reasoning course of. Earlier than producing the ultimate response, the mannequin explicitly causes in regards to the consumer’s intent, tone, and anticipated model—guaranteeing the reply is suitable and context-aware.
By cleanly separating reasoning from responses, the mannequin turns into simpler to interpret, debug, and belief, particularly in advanced agent-based or multi-step workflows, and with M2.1 this readability is paired with sooner responses, extra concise reasoning, and considerably decreased token consumption in comparison with M2.
MiniMax M2 stands out for its native mastery of Interleaved Pondering, permitting it to dynamically plan and adapt inside advanced coding and tool-based workflows, and M2.1 extends this functionality with improved code high quality, extra exact instruction following, clearer reasoning, and stronger efficiency throughout programming languages—notably in dealing with composite instruction constraints as seen in OctoCodingBench—making it prepared for workplace automation.
To guage these capabilities in apply, let’s take a look at the mannequin utilizing a structured coding immediate that features a number of constraints and real-world engineering necessities.
import anthropic
shopper = anthropic.Anthropic()
def run_test(immediate: str, title: str):
print(f"n{'='*80}")
print(f"TEST: {title}")
print(f"{'='*80}n")
message = shopper.messages.create(
mannequin="MiniMax-M2.1",
max_tokens=10000,
system=(
"You're a senior software program engineer. "
"Write production-quality code with clear construction, "
"express assumptions, and minimal however enough reasoning. "
"Keep away from pointless verbosity."
),
messages=[
{
"role": "user",
"content": [{"type": "text", "text": prompt}]
}
]
)
for block in message.content material:
if block.sort == "considering":
print("🧠 Pondering:n", block.considering, "n")
elif block.sort == "textual content":
print("📄 Output:n", block.textual content, "n")
PROMPT= """
Design a small Python service that processes consumer occasions.
Necessities:
1. Occasions arrive as dictionaries with keys: user_id, event_type, timestamp.
2. Validate enter strictly (sorts + required keys).
3. Mixture occasions per consumer in reminiscence.
4. Expose two capabilities:
- ingest_event(occasion: dict) -> None
- get_user_summary(user_id: str) -> dict
5. Code have to be:
- Testable
- Thread-safe
- Simply extensible for brand spanking new occasion sorts
6. Do NOT use exterior libraries.
Present:
- Code solely
- Transient inline feedback the place wanted
"""
run_test(immediate=PROMPT, title="Instruction Following + Structure")This take a look at makes use of a intentionally structured and constraint-heavy immediate designed to judge extra than simply code technology. The immediate requires strict enter validation, in-memory state administration, thread security, testability, and extensibility—all with out counting on exterior libraries.
By combining architectural choices with a number of non-trivial constraints, the immediate operates at a medium-to-high complexity degree, making it well-suited for assessing how successfully MiniMax M2.1 follows directions, causes by means of design trade-offs, and produces production-quality code relatively than remoted snippets.
Mannequin Reasoning & Output
The mannequin causes by means of key architectural trade-offs earlier than coding, fastidiously balancing flexibility, reminiscence utilization, and extensibility. It evaluates a number of approaches to occasion aggregation and intentionally chooses uncooked occasion storage to allow future extensions with out modifying ingestion logic.
Thread security is explicitly dealt with by means of locking, and strict enter validation is deliberate to make sure information correctness, reflecting a real-world, engineering-first mindset relatively than leaping straight to implementation.
This considerate reasoning is mirrored within the ultimate output, which demonstrates robust code high quality by means of clear construction, significant naming, sort hints, and a thread-safe design aligned with manufacturing requirements. The answer follows all immediate constraints precisely—masking validation, in-memory aggregation, extensibility, and the absence of exterior dependencies—whereas sustaining clear, targeted logic that avoids pointless complexity and stays simple to keep up.
import threading
from typing import Dict, Listing, Any
class EventProcessor:
"""
Thread-safe occasion processor that aggregates consumer occasions in reminiscence.
Validates enter strictly and helps simple extension for brand spanking new occasion sorts.
"""
def __init__(self) -> None:
# Shops occasions per consumer: user_id -> record of occasion dictionaries
self._user_events: Dict[str, List[Dict[str, Any]]] = {}
# Lock for thread-safe entry
self._lock = threading.Lock()
def ingest_event(self, occasion: dict) -> None:
"""
Validate and ingest a single occasion.
Strictly validates sorts and presence of required keys.
"""
# Validate occasion is a dictionary
if not isinstance(occasion, dict):
increase ValueError("Occasion have to be a dictionary")
# Validate required keys and their sorts
required_keys = {
'user_id': str,
'event_type': str,
'timestamp': (str, int, float) # Settle for string or numeric timestamp
}
for key, expected_type in required_keys.gadgets():
if key not in occasion:
increase ValueError(f"Lacking required key: '{key}'")
if not isinstance(occasion[key], expected_type):
increase ValueError(f"Key '{key}' have to be of sort {expected_type.__name__}")
# Thread-safe occasion storage
with self._lock:
user_id = occasion['user_id']
if user_id not in self._user_events:
self._user_events[user_id] = []
self._user_events[user_id].append(occasion)
def get_user_summary(self, user_id: str) -> dict:
"""
Generate abstract for a selected consumer.
Returns aggregated occasion counts and timestamps.
"""
if not isinstance(user_id, str):
increase ValueError("user_id have to be a string")
with self._lock:
user_events = self._user_events.get(user_id, [])
# Mixture occasion counts
event_counts = {}
timestamps = []
for occasion in user_events:
event_type = occasion['event_type']
event_counts[event_type] = event_counts.get(event_type, 0) + 1
timestamps.append(occasion['timestamp'])
return {
'user_id': user_id,
'total_events': len(user_events),
'event_counts': event_counts,
'timestamps': sorted(timestamps) if timestamps else []
}
```
**Key Design Selections:**
1. **Thread Security**: Makes use of `threading.Lock` to guard shared state throughout concurrent entry
2. **Enter Validation**: Strict sort checking for required keys with clear error messages
3. **Extensibility**:
- New occasion sorts robotically dealt with by dynamic counting
- Straightforward so as to add new aggregations in `get_user_summary`
4. **Testability**: Clear separation of issues, simple to mock for unit checks
5. **Reminiscence Effectivity**: Shops solely important information (occasion dictionaries)
**Utilization Instance:**
```python
processor = EventProcessor()
# Ingest occasions
processor.ingest_event({
'user_id': 'user123',
'event_type': 'login',
'timestamp': '2023-01-01T10:00:00Z'
})
# Get consumer abstract
abstract = processor.get_user_summary('user123')
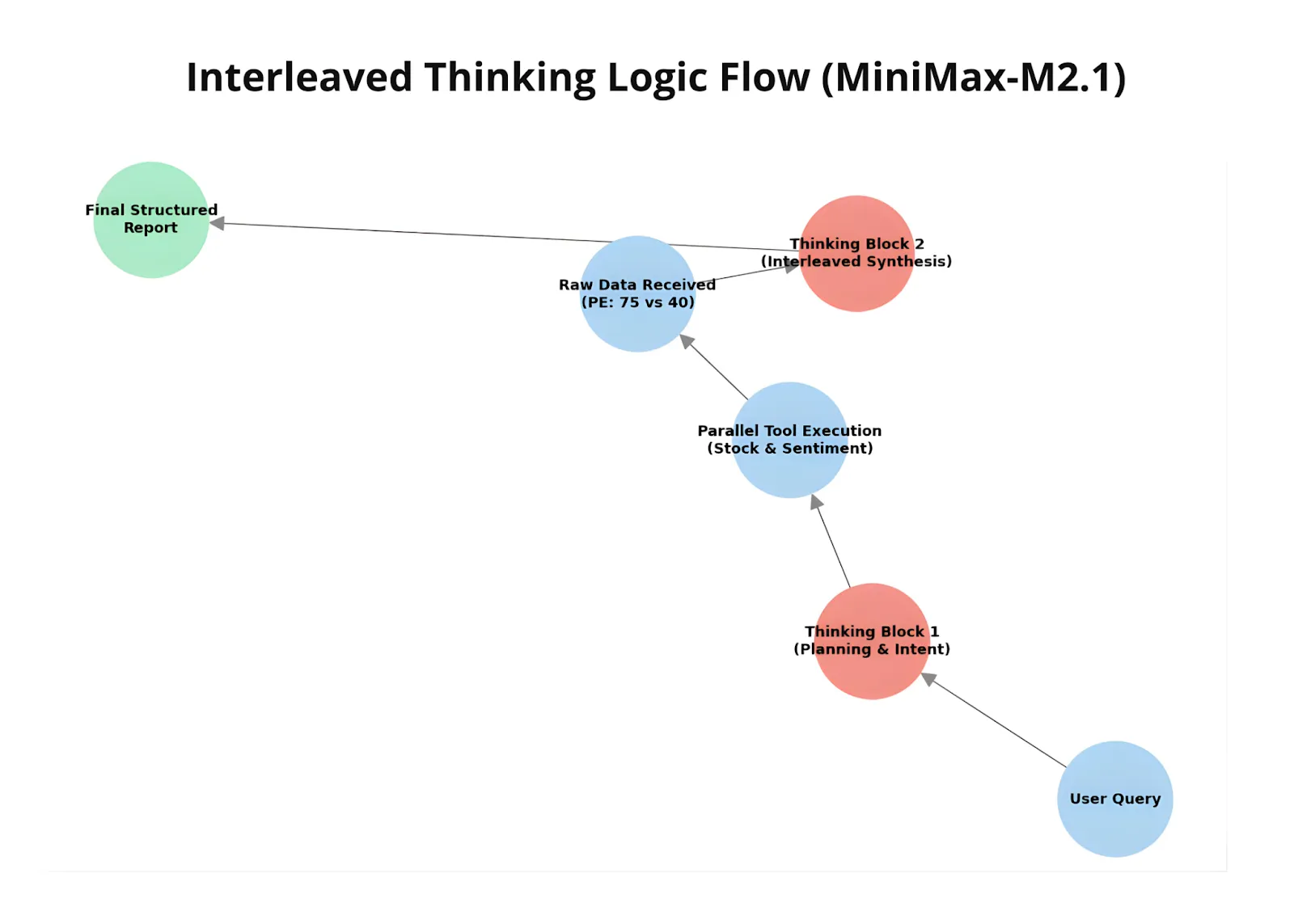
print(abstract)Let’s now see MiniMax M2.1’s interleaved considering in motion. We ask the mannequin to check two organizations based mostly on P/E ratio and sentiment, utilizing two dummy instruments to obviously observe how the workflow operates.
This instance demonstrates how M2.1 interacts with exterior instruments in a managed, agent-style setup. One software simulates fetching inventory metrics, whereas the opposite supplies sentiment evaluation, with each returning regionally generated responses. Because the mannequin receives these software outputs, it incorporates them into its reasoning and adjusts its ultimate comparability accordingly.
Defining the instruments
import anthropic
import json
shopper = anthropic.Anthropic()
def get_stock_metrics(ticker):
information = {
"NVDA": {"worth": 130, "pe": 75.2},
"AMD": {"worth": 150, "pe": 40.5}
}
return json.dumps(information.get(ticker, "Ticker not discovered"))
def get_sentiment_analysis(company_name):
sentiments = {"NVIDIA": 0.85, "AMD": 0.42}
return f"Sentiment rating for {company_name}: {sentiments.get(company_name, 0.0)}"
instruments = [
{
"name": "get_stock_metrics",
"description": "Get price and P/E ratio.",
"input_schema": {
"type": "object",
"properties": {"ticker": {"type": "string"}},
"required": ["ticker"]
}
},
{
"identify": "get_sentiment_analysis",
"description": "Get information sentiment rating.",
"input_schema": {
"sort": "object",
"properties": {"company_name": {"sort": "string"}},
"required": ["company_name"]
}
}
]messages = [{"role": "user", "content": "Compare NVDA and AMD value based on P/E and sentiment."}]
operating = True
print(f"👤 [USER]: {messages[0]['content']}")
whereas operating:
# Get mannequin response
response = shopper.messages.create(
mannequin="MiniMax-M2.1",
max_tokens=4096,
messages=messages,
instruments=instruments,
)
messages.append({"function": "assistant", "content material": response.content material})
tool_results = []
has_tool_use = False
for block in response.content material:
if block.sort == "considering":
print(f"n💭 [THINKING]:n{block.considering}")
elif block.sort == "textual content":
print(f"n💬 [MODEL]: {block.textual content}")
if not any(b.sort == "tool_use" for b in response.content material):
operating = False
elif block.sort == "tool_use":
has_tool_use = True
print(f"🔧 [TOOL CALL]: {block.identify}({block.enter})")
# Execute the right mock perform
if block.identify == "get_stock_metrics":
consequence = get_stock_metrics(block.enter['ticker'])
elif block.identify == "get_sentiment_analysis":
consequence = get_sentiment_analysis(block.enter['company_name'])
# Add to the outcomes record for this flip
tool_results.append({
"sort": "tool_result",
"tool_use_id": block.id,
"content material": consequence
})
if has_tool_use:
messages.append({"function": "consumer", "content material": tool_results})
else:
operating = False
print("n✅ Dialog Full.")Throughout execution, the mannequin decides when and which software to name, receives the corresponding software outcomes, after which updates its reasoning and ultimate response based mostly on that information. This showcases M2.1’s potential to interleave reasoning, software utilization, and response technology—adapting its output dynamically as new info turns into obtainable.

Lastly, we examine MiniMax M2.1 with GPT-5.2 utilizing a compact multilingual instruction-following immediate. The duty requires the mannequin to establish coffee-related phrases from a Spanish passage, translate solely these phrases into English, take away duplicates, and return the end in a strictly formatted numbered record.
To run this code block, you’ll want an OpenAI API key, which might be generated from the OpenAI developer dashboard.
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass ('Enter OpenAI API Key: ')input_text = """
¡Preparar café Chilly Brew es un proceso sencillo y refrescante!
Todo lo que necesitas son granos de café molido grueso y agua fría.
Comienza añadiendo el café molido a un recipiente o jarra grande.
Luego, vierte agua fría, asegurándote de que todos los granos de café
estén completamente sumergidos.
Remueve la mezcla suavemente para garantizar una saturación uniforme.
Cubre el recipiente y déjalo en remojo en el refrigerador durante al
menos 12 a 24 horas, dependiendo de la fuerza deseada.
"""
immediate = f"""
The next textual content is written in Spanish.
Activity:
1. Determine all phrases within the textual content which can be associated to espresso or espresso preparation.
2. Translate ONLY these phrases into English.
3. Take away duplicates (every phrase ought to seem solely as soon as).
4. Current the consequence as a numbered record.
Guidelines:
- Do NOT embody explanations.
- Do NOT embody non-coffee-related phrases.
- Do NOT embody Spanish phrases within the ultimate output.
Textual content:
<{input_text}>
"""
from openai import OpenAI
shopper = OpenAI()
response = shopper.responses.create(
mannequin="gpt-5.2",
enter=immediate
)
print(response.output_text)import anthropic
shopper = anthropic.Anthropic()
message = shopper.messages.create(
mannequin="MiniMax-M2.1",
max_tokens=10000,
system="You're a useful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
)
for block in message.content material:
if block.sort == "considering":
print(f"Pondering:n{block.considering}n")
elif block.sort == "textual content":
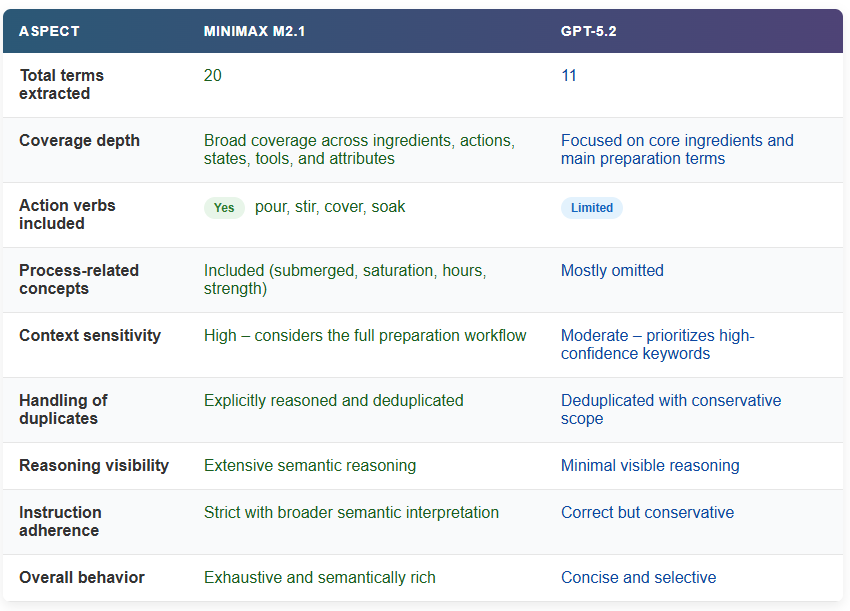
print(f"Textual content:n{block.textual content}n")When evaluating the outputs, MiniMax M2.1 produces a noticeably broader and extra granular set of coffee-related phrases than GPT-5.2. M2.1 identifies not solely core nouns like espresso, beans, and water, but additionally preparation actions (pour, stir, cowl), process-related states (submerged, soak), and contextual attributes (chilly, coarse, energy, hours).
This means a deeper semantic move over the textual content, the place the mannequin causes by means of all the preparation workflow relatively than extracting solely the obvious key phrases.
This distinction can be mirrored within the reasoning course of. M2.1 explicitly analyzes context, resolves edge instances (akin to borrowed English phrases like Chilly Brew), considers duplicates, and deliberates on whether or not sure adjectives or verbs qualify as coffee-related earlier than finalizing the record. GPT-5.2, against this, delivers a shorter and extra conservative output targeted on high-confidence phrases, with much less seen reasoning depth.
Collectively, this highlights M2.1’s stronger instruction adherence and semantic protection, particularly for duties that require cautious filtering, translation, and strict output management.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.