

{kind=link}
What simply occurred? Microsoft has launched BitNet b1.58 2B4T, a brand new sort of huge language mannequin engineered for distinctive effectivity. In contrast to standard AI fashions that depend on 16- or 32-bit floating-point numbers to characterize every weight, BitNet makes use of solely three discrete values: -1, 0, or +1. This method, often known as ternary quantization, permits every weight to be saved in simply 1.58 bits. The result’s a mannequin that dramatically reduces reminiscence utilization and might run much more simply on commonplace {hardware}, with out requiring the high-end GPUs sometimes wanted for large-scale AI.
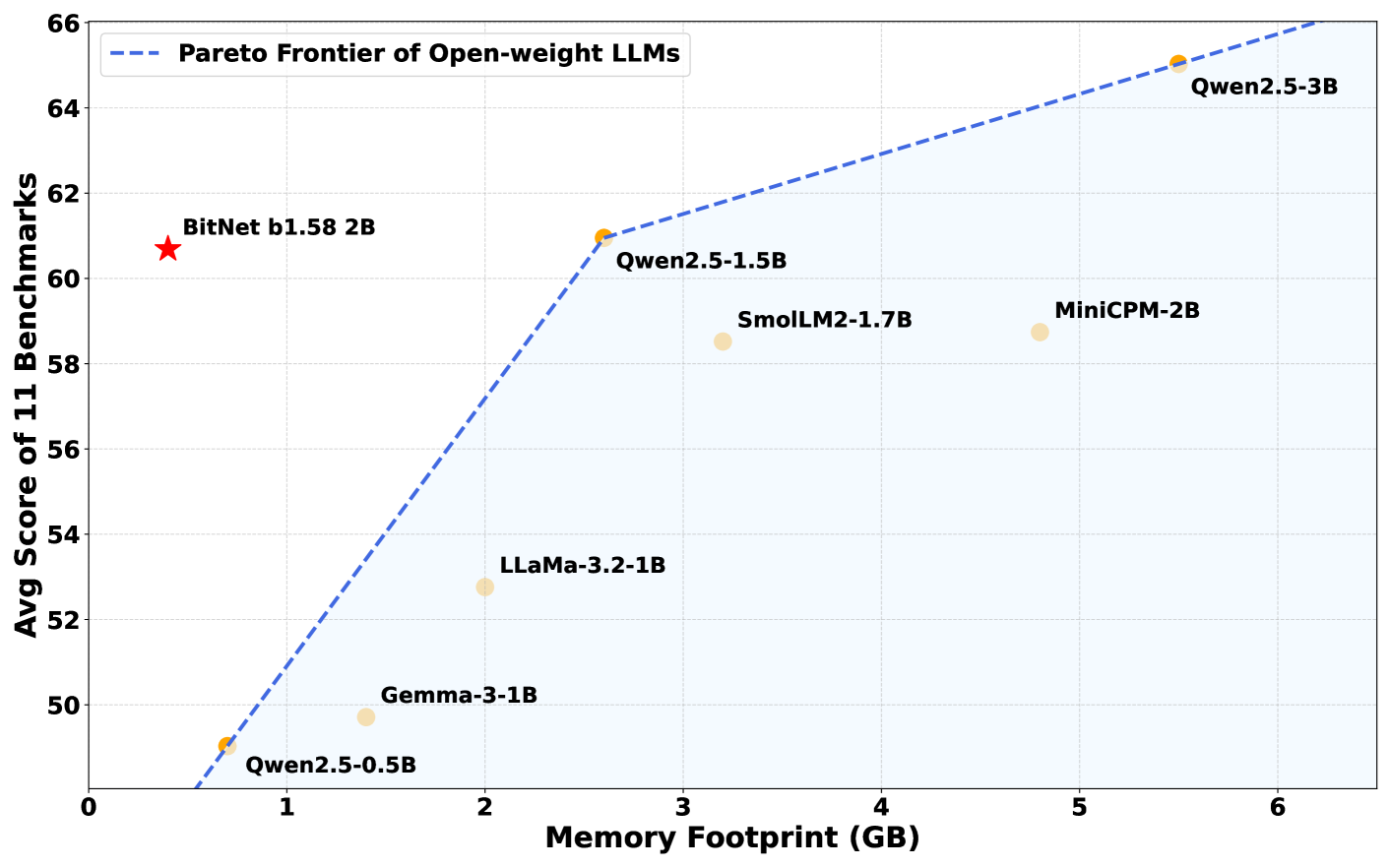
The BitNet b1.58 2B4T mannequin was developed by Microsoft’s Normal Synthetic Intelligence group and accommodates two billion parameters – inner values that allow the mannequin to grasp and generate language. To compensate for its low-precision weights, the mannequin was skilled on a large dataset of 4 trillion tokens, roughly equal to the contents of 33 million books. This in depth coaching permits BitNet to carry out on par with – or in some circumstances, higher than – different main fashions of comparable measurement, akin to Meta’s Llama 3.2 1B, Google’s Gemma 3 1B, and Alibaba’s Qwen 2.5 1.5B.
In benchmark assessments, BitNet b1.58 2B4T demonstrated sturdy efficiency throughout a wide range of duties, together with grade-school math issues and questions requiring widespread sense reasoning. In sure evaluations, it even outperformed its rivals.
What actually units BitNet aside is its reminiscence effectivity. The mannequin requires simply 400MB of reminiscence, lower than a 3rd of what comparable fashions sometimes want. In consequence, it will probably run easily on commonplace CPUs, together with Apple’s M2 chip, with out counting on high-end GPUs or specialised AI {hardware}.
This stage of effectivity is made doable by a customized software program framework known as bitnet.cpp, which is optimized to take full benefit of the mannequin’s ternary weights. The framework ensures quick and light-weight efficiency on on a regular basis computing gadgets.
Commonplace AI libraries like Hugging Face’s Transformers do not provide the identical efficiency benefits as BitNet b1.58 2B4T, making the usage of the customized bitnet.cpp framework important. Obtainable on GitHub, the framework is at the moment optimized for CPUs, however assist for different processor varieties is deliberate in future updates.
The thought of decreasing mannequin precision to avoid wasting reminiscence is not new as researchers have lengthy explored mannequin compression. Nevertheless, most previous makes an attempt concerned changing full-precision fashions after coaching, typically at the price of accuracy. BitNet b1.58 2B4T takes a unique method: it’s skilled from the bottom up utilizing solely three weight values (-1, 0, and +1). This enables it to keep away from lots of the efficiency losses seen in earlier strategies.
This shift has important implications. Operating giant AI fashions sometimes calls for highly effective {hardware} and appreciable power, components that drive up prices and environmental affect. As a result of BitNet depends on very simple computations – principally additions as a substitute of multiplications – it consumes far much less power.
Microsoft researchers estimate it makes use of 85 to 96 % much less power than comparable full-precision fashions. This might open the door to operating superior AI straight on private gadgets, with out the necessity for cloud-based supercomputers.
That stated, BitNet b1.58 2B4T does have some limitations. It at the moment helps solely particular {hardware} and requires the customized bitnet.cpp framework. Its context window – the quantity of textual content it will probably course of directly – is smaller than that of probably the most superior fashions.
Researchers are nonetheless investigating why the mannequin performs so effectively with such a simplified structure. Future work goals to increase its capabilities, together with assist for extra languages and longer textual content inputs.