

{kind=link}
How would your agent stack change if a coverage might prepare purely from its personal outcome-grounded rollouts—no rewards, no demos—but beat imitation studying throughout eight benchmarks? Meta Superintelligence Labs suggest ‘Early Expertise‘, a reward-free coaching method that improves coverage studying in language brokers with out massive human demonstration units and with out reinforcement studying (RL) in the primary loop. The core concept is straightforward: let the agent department from professional states, take its personal actions, gather the ensuing future states, and convert these penalties into supervision. The analysis staff instantiates this with two concrete methods—Implicit World Modeling (IWM) and Self-Reflection (SR)—and stories constant good points throughout eight environments and a number of base fashions.
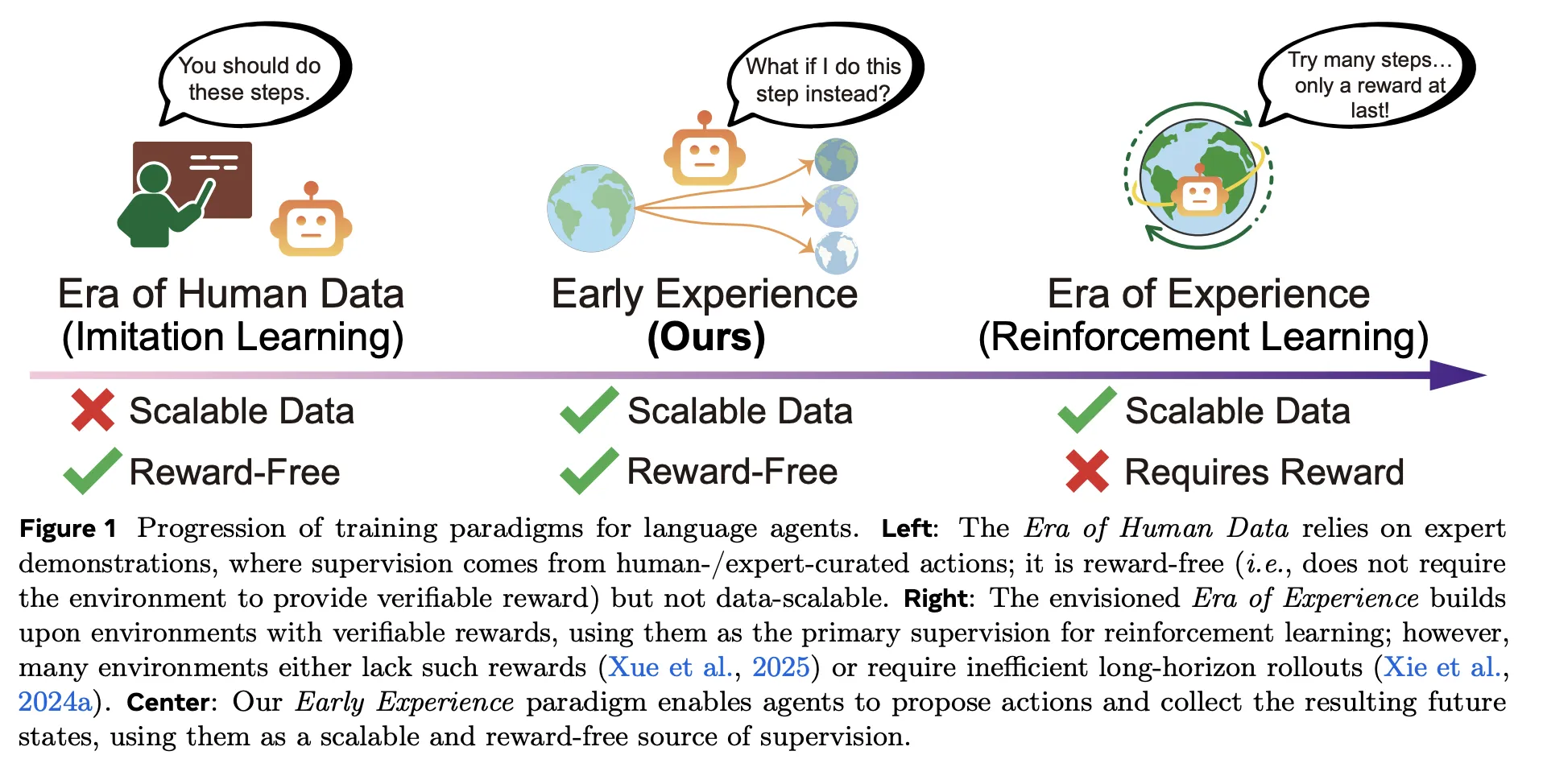
What Early Expertise adjustments?
Conventional pipelines lean on imitation studying (IL) over professional trajectories, which is affordable to optimize however onerous to scale and brittle out-of-distribution; reinforcement studying (RL) guarantees studying from expertise however wants verifiable rewards and steady infrastructure—usually lacking in internet and multi-tool settings. Early Expertise sits between them: it’s reward-free like imitation studying (IL), however the supervision is grounded in penalties of the agent’s personal actions, not simply professional actions. Briefly, the agent proposes, acts, and learns from what truly occurs subsequent—no reward perform required.
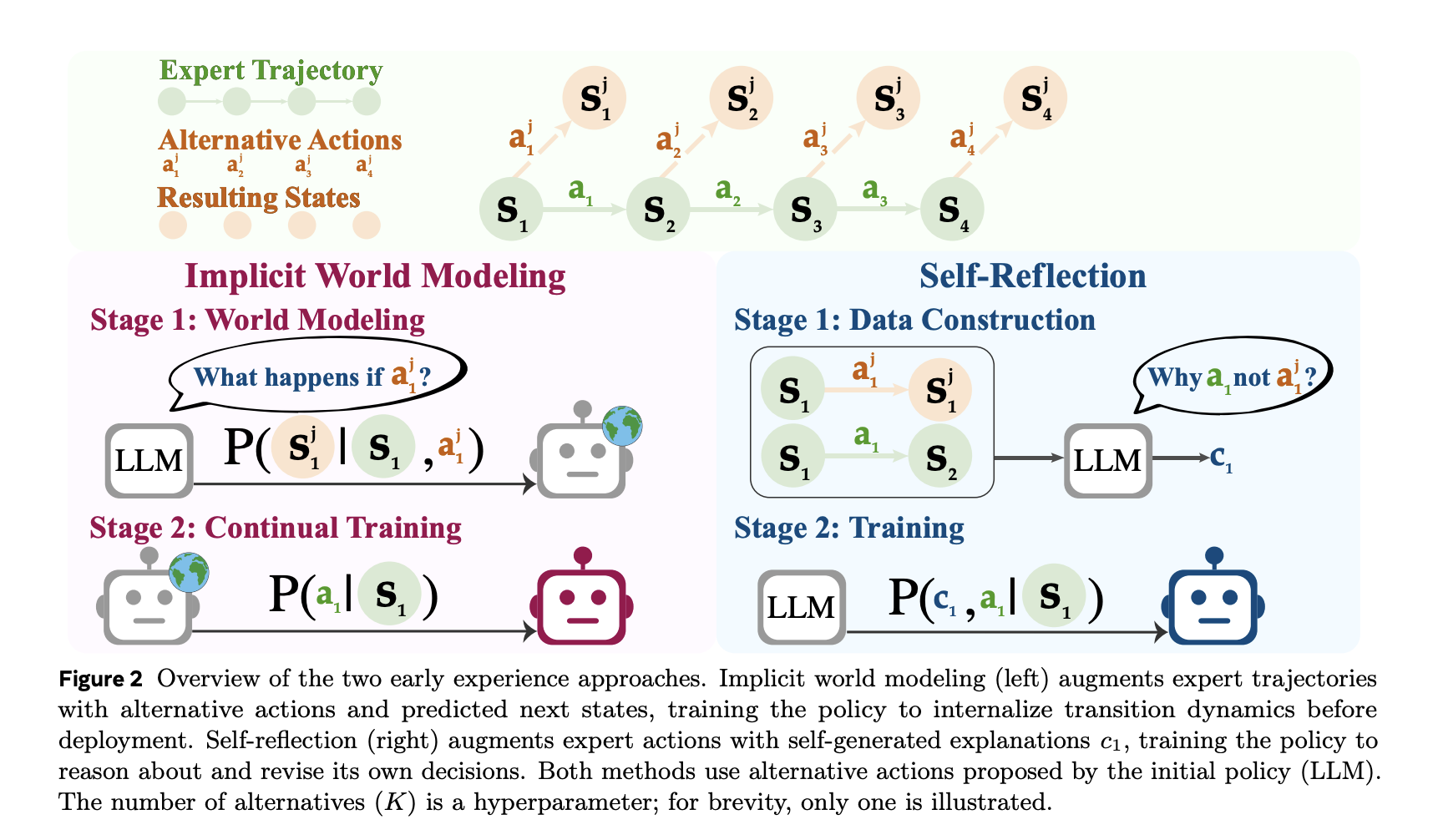
- Implicit World Modeling (IWM): Prepare the mannequin to foretell the subsequent statement given the state and chosen motion, tightening the agent’s inner mannequin of atmosphere dynamics and lowering off-policy drift.
- Self-Reflection (SR): Current professional and different actions on the similar state; have the mannequin clarify why the professional motion is healthier utilizing the noticed outcomes, then fine-tune the coverage from this contrastive sign.
Each methods use the identical budgets and decoding settings as IL; solely the information supply differs (agent-generated branches moderately than extra professional trajectories).
Understanding the Benchmarks
The analysis staff consider on eight language-agent environments spanning internet navigation, long-horizon planning, scientific/embodied duties, and multi-domain API workflows—e.g., WebShop (transactional searching), TravelPlanner (constraint-rich planning), ScienceWorld, ALFWorld, Tau-Bench, and others. Early Expertise yields common absolute good points of +9.6 success and +9.4 out-of-domain (OOD) over IL throughout the complete matrix of duties and fashions. These good points persist when the identical checkpoints are used to initialize RL (GRPO), enhancing post-RL ceilings by as much as +6.4 in comparison with reinforcement studying (RL) began from imitation studying (IL).
Effectivity: much less professional knowledge, similar optimization funds
A key sensible win is demo effectivity. With a hard and fast optimization funds, Early Expertise matches or beats IL utilizing a fraction of professional knowledge. On WebShop, 1/8 of the demonstrations with Early Expertise already exceeds IL educated on the full demo set; on ALFWorld, parity is hit at 1/2 the demos. The benefit grows with extra demonstrations, indicating the agent-generated future states present supervision indicators that demonstrations alone don’t seize.
How the information is constructed?
The pipeline seeds from a restricted set of professional rollouts to acquire consultant states. At chosen states, the agent proposes different actions, executes them, and data the subsequent observations.
- For IWM, the coaching knowledge are triplets ⟨state, motion, next-state⟩ and the target is next-state prediction.
- For SR, the prompts embody the professional motion and several other alternate options plus their noticed outcomes; the mannequin produces a grounded rationale explaining why the professional motion is preferable, and this supervision is then used to enhance the coverage.
The place reinforcement studying (RL) matches?
Early Expertise is not “RL with out rewards.” It’s a supervised recipe that makes use of agent-experienced outcomes as labels. In environments with verifiable rewards, the analysis staff merely add RL after Early Expertise. As a result of the initialization is healthier than IL, the similar RL schedule climbs larger and sooner, with as much as +6.4 remaining success over IL-initialized RL throughout examined domains. This positions Early Expertise as a bridge: reward-free pre-training from penalties, adopted (the place potential) by commonplace reinforcement studying (RL).
Key Takeaways
- Reward-free coaching by way of agent-generated future states (not rewards) utilizing Implicit World Modeling and Self-Reflection outperforms imitation studying throughout eight environments.
- Reported absolute good points over IL: +18.4 (WebShop), +15.0 (TravelPlanner), +13.3 (ScienceWorld) below matched budgets and settings.
- Demo effectivity: exceeds IL on WebShop with 1/8 of demonstrations; reaches ALFWorld parity with 1/2—at mounted optimization value.
- As an initializer, Early Expertise boosts subsequent RL (GRPO) endpoints by as much as +6.4 versus RL began from IL.
- Validated on a number of spine households (3B–8B) with constant in-domain and out-of-domain enhancements; positioned as a bridge between imitation studying (IL) and reinforcement studying (RL).
Early Expertise is a realistic contribution: it replaces brittle rationale-only augmentation with outcome-grounded supervision that an agent can generate at scale, with out reward features. The 2 variants—Implicit World Modeling (next-observation prediction to anchor atmosphere dynamics) and Self-Reflection (contrastive, outcome-verified rationales in opposition to professional actions)—instantly assault off-policy drift and long-horizon error accumulation, explaining the constant good points over imitation studying throughout eight environments and the stronger RL ceilings when used as an initializer for GRPO. In internet and tool-use settings the place verifiable rewards are scarce, this reward-free supervision is the lacking center between IL and RL and is straight away actionable for manufacturing agent stacks.
Take a look at the PAPER right here. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.