

{kind=link}
Fashionable AI methods rely closely on post-training strategies like supervised fine-tuning (SFT) and reinforcement studying (RL) to adapt basis fashions for particular duties. Nonetheless, a crucial query stays unresolved: do these strategies assist fashions memorize coaching information or generalize to new situations? This distinction is significant for constructing strong AI methods able to dealing with real-world variability.
Prior work suggests SFT dangers overfitting to coaching information, making fashions brittle when confronted with new activity variants. For instance, an SFT-tuned mannequin may excel at arithmetic issues utilizing particular card values (e.g., treating ‘J’ as 11) however fail if the principles change (e.g., ‘J’ turns into 10). Equally, RL’s reliance on reward indicators may both encourage versatile problem-solving or reinforce slim methods. Nonetheless, current evaluations usually conflate memorization and true generalization, leaving practitioners unsure about which technique to prioritize. In a contemporary paper from HKU, UC Berkeley, Google DeepMind, and NYU examine this by evaluating how SFT and RL have an effect on a mannequin’s skill to adapt to unseen rule-based and visible challenges.
They suggest to check generalization in managed settings to isolate memorization from generalization. Researchers designed two duties: GeneralPoints (arithmetic reasoning) and V-IRL (visible navigation). Each duties embrace in-distribution (ID) coaching information and out-of-distribution (OOD) variants to check adaptability:
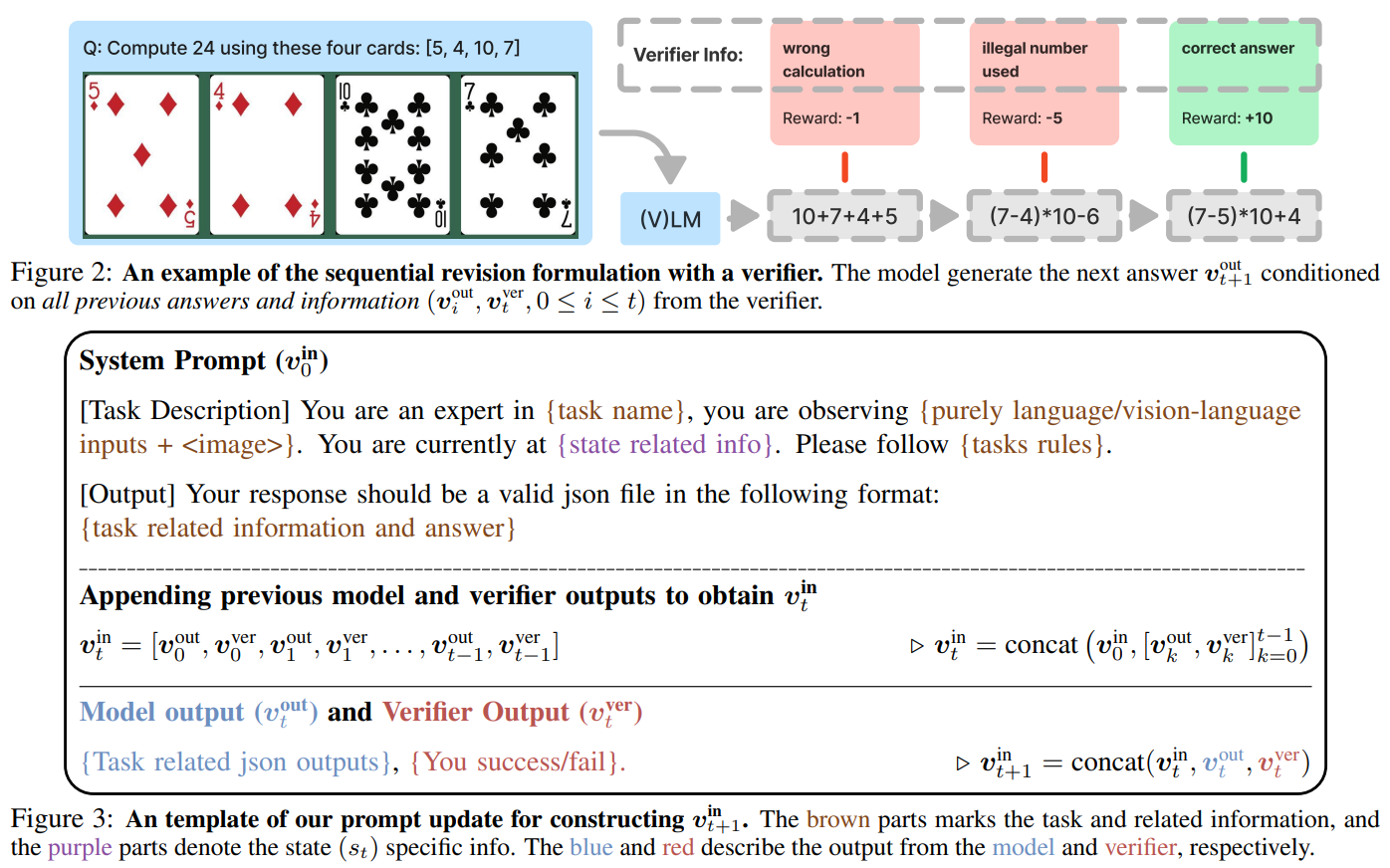
- Rule-Based mostly Generalization (GeneralPoints, proven in Fig 3):
- Job: Create equations equal to 24 utilizing 4 numbers from enjoying playing cards.
- Variants: Change card-value guidelines (e.g., ‘J’ = 11 vs. ‘J’ = 10) or card colours (purple vs. blue).
- Objective: Decide if fashions be taught arithmetic rules or memorize particular guidelines.
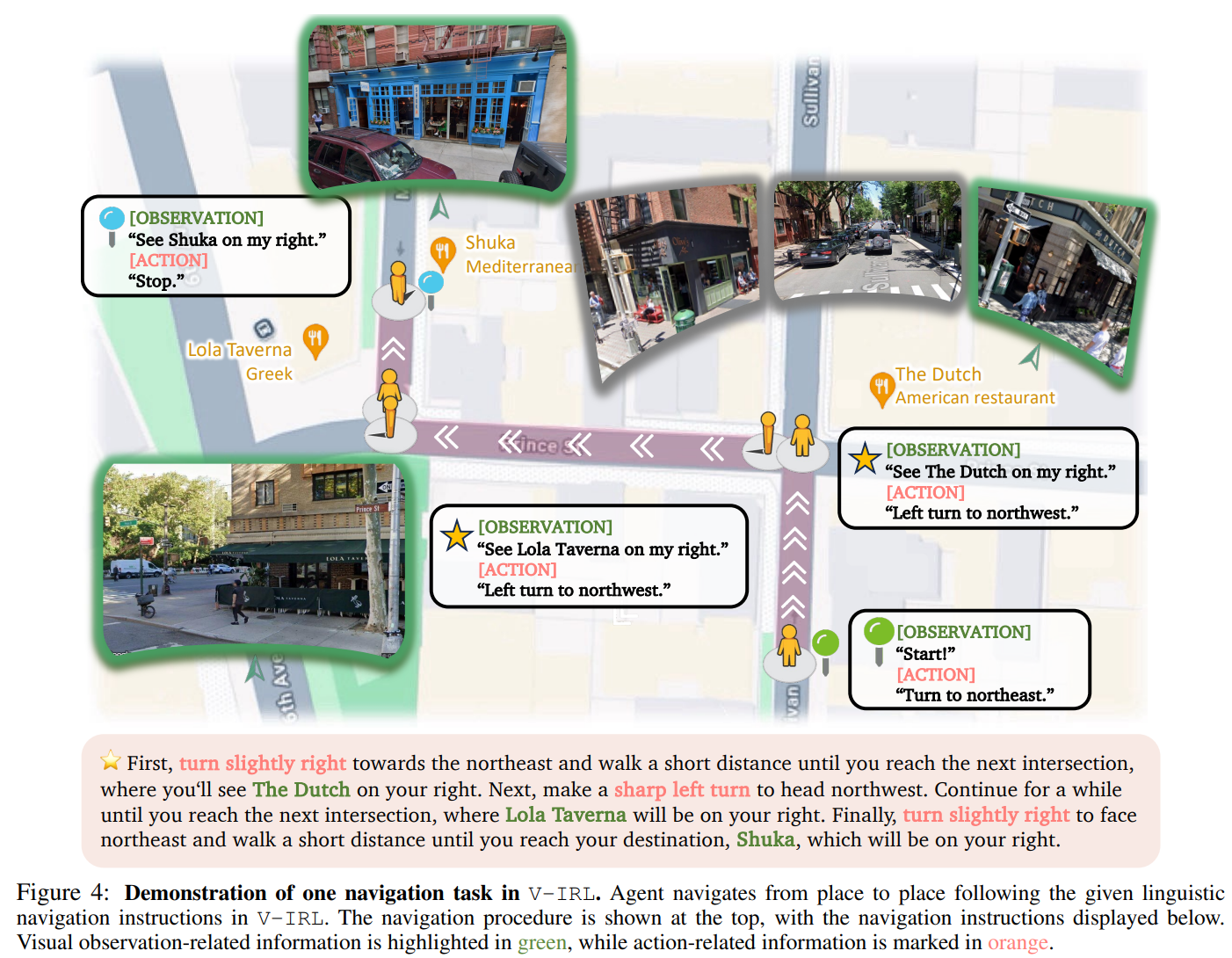
- Visible Generalization (V-IRL, proven in Fig 4):
- Job: Navigate to a goal location utilizing visible landmarks.
- Variants: Swap motion areas (absolute instructions like “north” vs. relative instructions like “flip left”) or take a look at in unseen cities.
- Objective: Assess spatial reasoning impartial of memorized landmarks.
For experiments, the research makes use of Llama-3.2-Imaginative and prescient-11B as the bottom mannequin, making use of SFT first (commonplace apply) adopted by RL. Key experiments measured efficiency on OOD duties after every coaching section. Let’s now focus on some crucial insights from the paper:
How do SFT and RL Differ in Studying Mechanisms?
- SFT’s Memorization Bias: SFT trains fashions to copy appropriate responses from labeled information. Whereas efficient for ID duties, this strategy encourages sample matching. For example, if educated on purple playing cards in GeneralPoints, the mannequin associates colour with particular quantity assignments. When examined on blue playing cards (OOD), efficiency plummets as a result of it memorizes color-number correlations as a substitute of arithmetic logic. Equally, in V-IRL, SFT fashions memorize landmark sequences however wrestle with new metropolis layouts.
- RL’s Generalization Energy: RL optimizes for reward maximization, which forces fashions to grasp activity construction. In GeneralPoints, RL-trained fashions adapt to new card guidelines by specializing in arithmetic relationships somewhat than fastened values. For V-IRL, RL brokers be taught spatial relationships (e.g., “left” means rotating 90 levels) as a substitute of memorizing flip sequences. This makes them strong to visible modifications, akin to unfamiliar landmarks.
One other crucial perception is that RL advantages from verification iterations—a number of makes an attempt to unravel a activity inside a single coaching step. Extra iterations (e.g., 10 vs. 1) enable the mannequin to discover numerous methods, enhancing OOD efficiency by +5.99% in some instances.
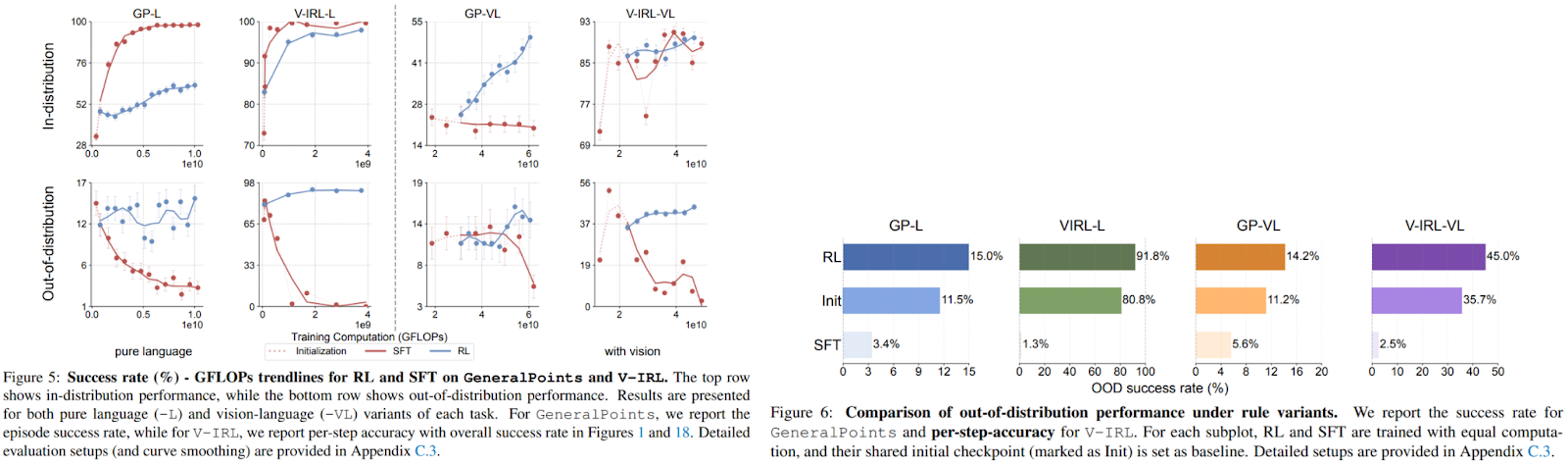
In efficiency analysis RL outperforms SFT constantly in each duties as proven in Fig 5 & 6:
- Rule-Based mostly Duties:
- RL improved OOD accuracy by +3.5% (GP-L) and +11.0% (V-IRL-L), whereas SFT degraded efficiency by -8.1% and -79.5%, respectively.
- Instance: When card guidelines modified from ‘J=11’ to ‘J=10’, RL fashions adjusted equations utilizing the brand new values, whereas SFT fashions reused invalid memorized options.
- Visible Duties:
- RL boosted OOD efficiency by +17.6% (GP-VL) and +61.1% (V-IRL-VL), whereas SFT dropped by -9.9% and -5.6%.
- In V-IRL, RL brokers navigated unseen cities by recognizing spatial patterns, whereas SFT failed as a result of reliance on memorized landmarks.
The research additionally means that SFT is critical to initialize fashions for RL. With out SFT, RL struggles as a result of the bottom mannequin lacks primary instruction-following abilities. Nonetheless, overly-tuned SFT checkpoints hurt RL’s adaptability, the place RL couldn’t recuperate OOD efficiency after extreme SFT. Nonetheless, the researchers make clear that their findings—particular to the Llama-3.2 spine mannequin—don’t battle with earlier work akin to DeepSeekAI et al. (2025), which proposed that SFT could possibly be omitted for downstream RL coaching when utilizing different base architectures.
In conclusion, this research demonstrates a transparent trade-off: SFT excels at becoming coaching information however falters beneath distribution shifts, whereas RL prioritizes adaptable, generalizable methods. For practitioners, this suggests that RL ought to comply with SFT—however solely till the mannequin achieves primary activity competence. Over-reliance on SFT dangers “locking in” memorized patterns, limiting RL’s skill to discover novel options. Nonetheless, RL isn’t a panacea; it requires cautious tuning (e.g., verification steps) and balanced initialization.
Try the PAPER. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 70k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Supply Multi-Agent Framework to Consider Advanced Conversational AI System (Promoted)
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the most recent developments in Deep Studying, Pc Imaginative and prescient, and associated fields.