
")
{kind=link}
Logical reasoning stays an important space the place AI methods battle regardless of advances in processing language and information. Understanding logical reasoning in AI is crucial for enhancing automated methods in areas like planning, decision-making, and problem-solving. In contrast to common sense reasoning, logical reasoning requires exact rule-based deductions, making it more difficult for LLMs to grasp.
A serious impediment in logical reasoning inside AI is dealing with advanced structured issues. Present fashions battle with intricate constraints and dependencies, counting on statistical patterns as an alternative of deductive reasoning. This situation turns into extra evident as drawback complexity will increase, leading to a decline in accuracy. Such limitations pose issues in high-stakes purposes like authorized evaluation, theorem proving, and scientific modeling, the place exact logical deductions are obligatory. Researchers intention to handle these shortcomings by designing rigorous analysis frameworks that assess reasoning efficiency systematically.
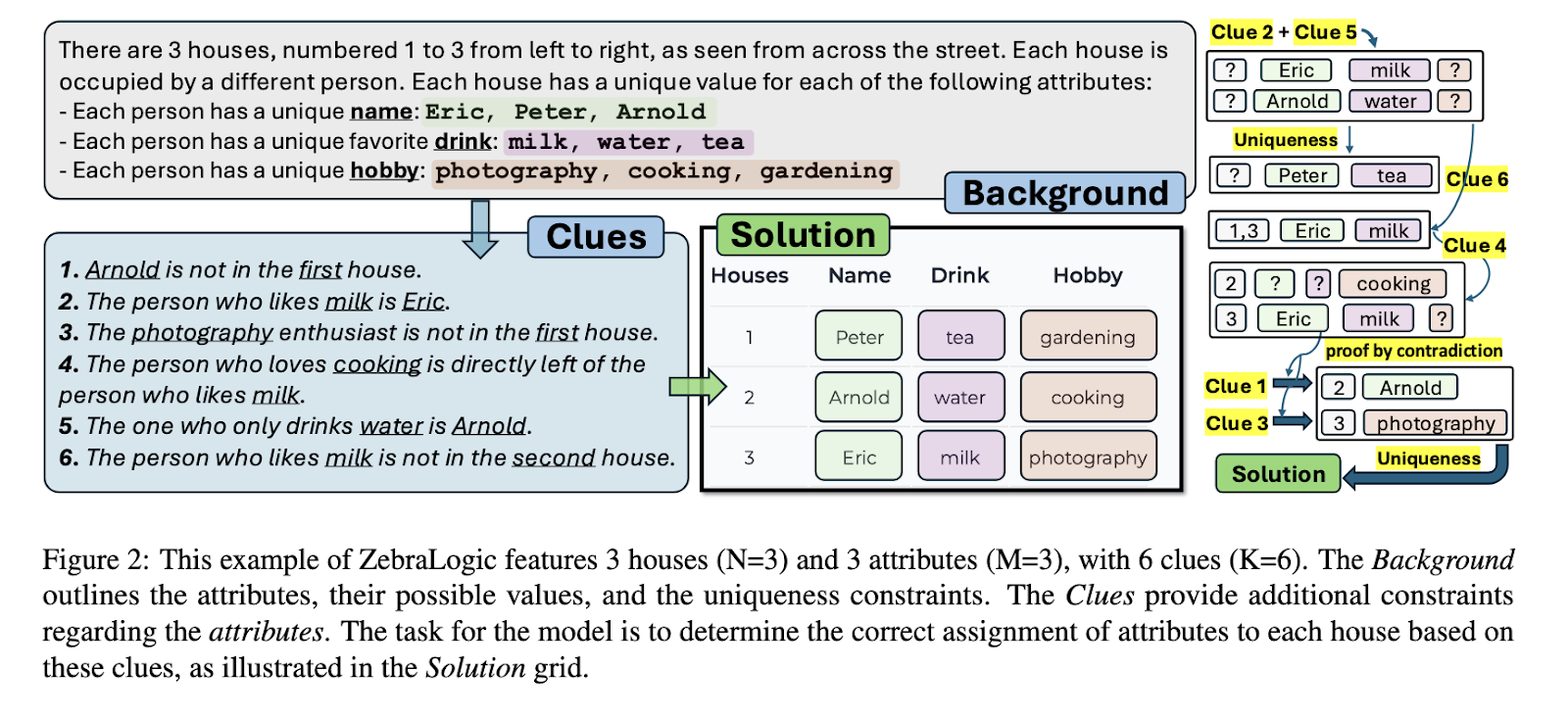
Conventional logical reasoning strategies use constraint satisfaction issues (CSPs), which offer structured analysis fashions with controllable problem. CSPs allow exact evaluation by eliminating coaching knowledge memorization and guaranteeing that fashions depend on precise reasoning capabilities. Logic grid puzzles, a subset of CSPs, are efficient testbeds for evaluating structured reasoning in AI. These puzzles require systematic deduction primarily based on outlined constraints and have real-world purposes in useful resource allocation, scheduling, and automatic planning. Nevertheless, even essentially the most superior LLMs battle with such duties when complexity will increase past a sure threshold.
A analysis staff from the College of Washington, Allen Institute for AI, and Stanford College launched ZebraLogic, a benchmarking framework developed to scrupulously take a look at LLMs’ logical reasoning efficiency. ZebraLogic generates logic puzzles with quantifiable complexity, guaranteeing a managed atmosphere for systematic analysis. The framework prevents knowledge leakage and allows an in depth evaluation of an LLM’s capacity to deal with more and more advanced reasoning duties. ZebraLogic serves as an important step towards understanding the elemental constraints of LLMs in structured reasoning and scaling limitations.
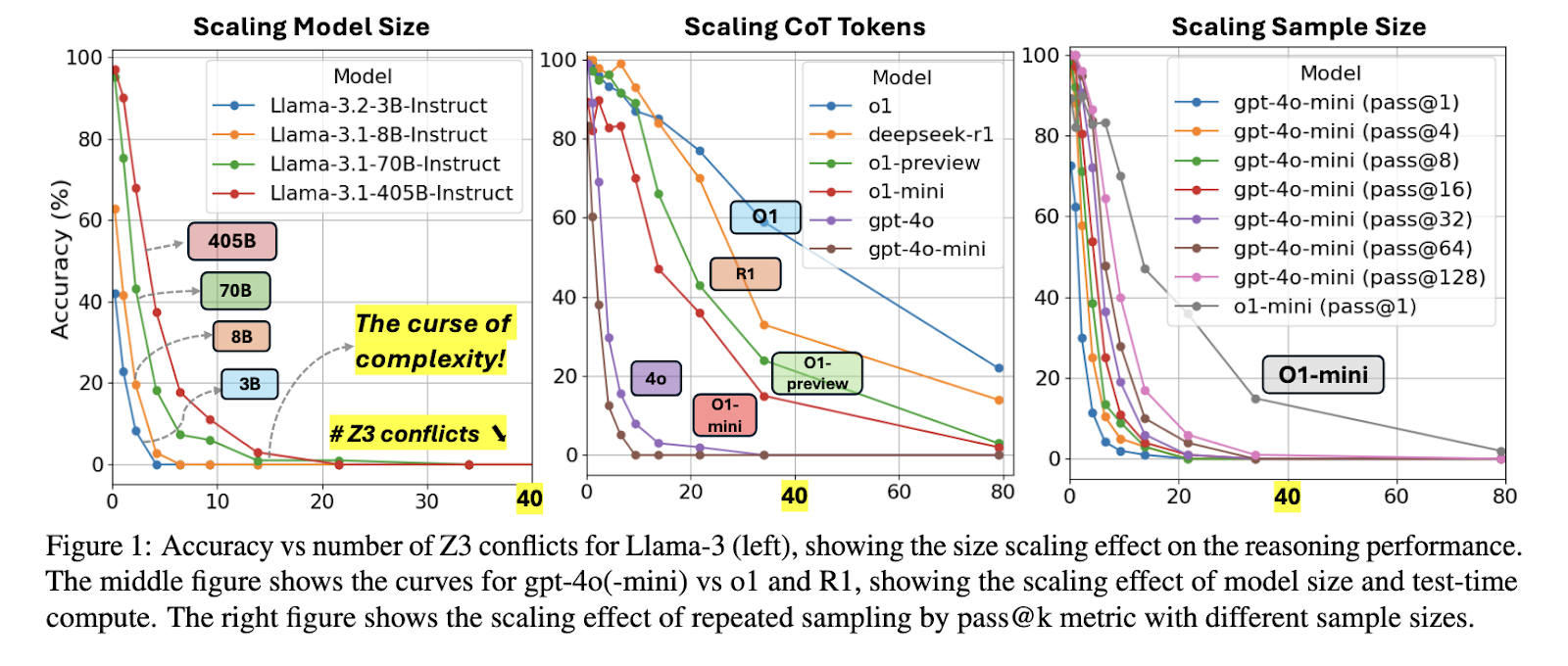
The ZebraLogic framework constructs logic puzzles with various problem ranges primarily based on two major complexity measures: search area measurement and Z3 battle rely, a metric derived from an SMT solver. The research examined main LLMs, together with Meta’s Llama, OpenAI’s o1 fashions, and DeepSeekR1, and revealed important accuracy declines as puzzle complexity elevated. The framework allowed for a exact evaluation of reasoning capabilities throughout completely different ranges of drawback problem, making it one of the crucial structured evaluations of LLMs up to now. By systematically various the constraints, researchers may decide the impression of drawback measurement on logical reasoning efficiency.
Experiments carried out with ZebraLogic uncovered the “curse of complexity,” the place LLM efficiency dropped sharply with elevated drawback problem. The perfect-performing mannequin, o1, achieved an general accuracy of 81.0%, whereas DeepSeekR1 adopted intently at 78.7%. Nevertheless, even these high fashions struggled when the puzzle’s search area exceeded 10^7 attainable configurations. Medium-complexity puzzles confirmed a major decline, with o1 sustaining 92.1% accuracy however dropping to 42.5% on large-scale issues. DeepSeekR1 exhibited comparable conduct, excelling in easier instances however struggling efficiency losses on extra advanced duties. Decrease-tier fashions like Llama-3.1-405B and Gemini-1.5-Professional demonstrated a major efficiency hole, reaching 32.6% and 30.5% general accuracy, respectively.

Growing mannequin measurement didn’t considerably mitigate the curse of complexity, as accuracy ranges plateaued regardless of enhanced coaching. The research examined numerous strategies to enhance LLMs’ reasoning skills, together with Greatest-of-N sampling and self-verification methods. Greatest-of-N sampling improved accuracy barely, however even with intensive sampling, efficiency beneficial properties remained marginal. Fashions struggled past a search area of 10^9 configurations, suggesting inherent constraints in present architectures. Notably, o1 fashions generated considerably extra hidden reasoning tokens than different LLMs, averaging round 5,144 hidden CoT tokens, in comparison with GPT-4o’s 543 tokens. These findings spotlight the significance of refining reasoning methods slightly than merely scaling fashions.
ZebraLogic’s analysis underscores elementary limitations in LLMs’ capacity to scale logical reasoning past reasonable complexity. The findings emphasize the necessity for different approaches, equivalent to enhanced reasoning frameworks and structured logical modeling, slightly than relying solely on mannequin enlargement. The research presents an important benchmark for future AI analysis, providing insights into the necessity for improved logical reasoning methodologies. Addressing these challenges can be important in advancing AI methods which are able to dependable and scalable logical deduction.
Take a look at the Paper and Undertaking Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 75k+ ML SubReddit.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.