

{kind=link}
Giant language mannequin serving usually wastes GPU reminiscence as a result of engines pre-reserve giant static KV cache areas per mannequin, even when requests are bursty or idle. Meet ‘kvcached‘, a library to allow virtualized, elastic KV cache for LLM serving on shared GPUs. kvcached has been developed by a analysis from Berkeley’s Sky Computing Lab (College of California, Berkeley) in shut collaboration with Rice College and UCLA, and with beneficial enter from collaborators and colleagues at NVIDIA, Intel Company, Stanford College. It introduces an OS-style digital reminiscence abstraction for the KV cache that lets serving engines reserve contiguous digital area first, then again solely the lively parts with bodily GPU pages on demand. This decoupling raises reminiscence utilization, reduces chilly begins, and permits a number of fashions to time share and area share a tool with out heavy engine rewrites.
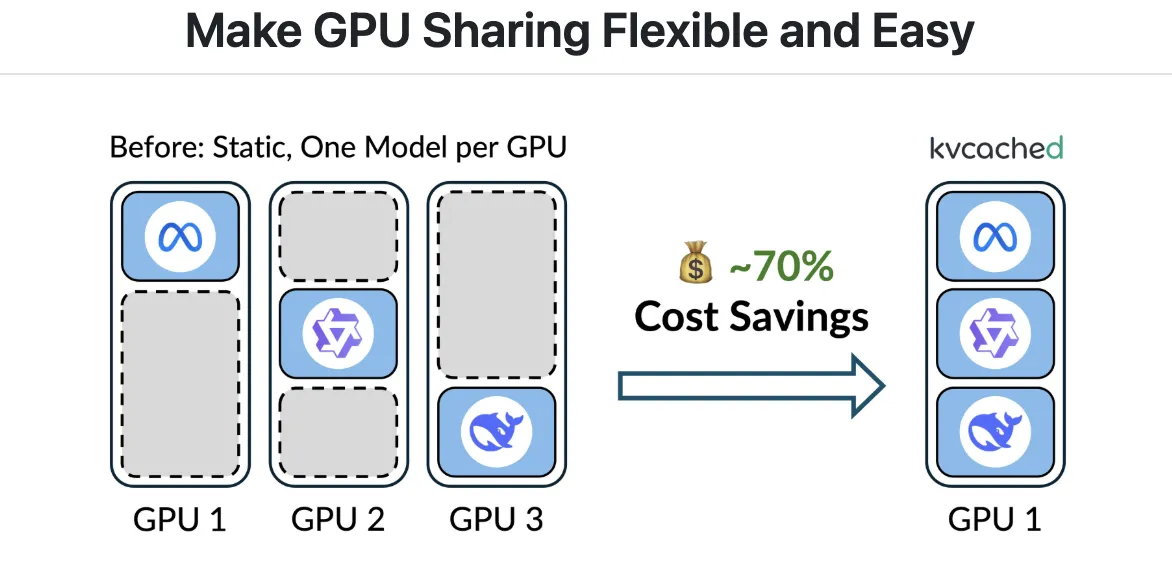
What kvcached modifications?
With kvcached, an engine creates a KV cache pool that’s contiguous within the digital tackle area. As tokens arrive, the library maps bodily GPU pages lazily at a high-quality granularity utilizing CUDA digital reminiscence APIs. When requests full or fashions go idle, pages unmap and return to a shared pool, which different colocated fashions can instantly reuse. This preserves easy pointer arithmetic in kernels, and removes the necessity for per engine consumer degree paging. The mission targets SGLang and vLLM integration, and it’s launched underneath the Apache 2.0 license. Set up and a one command fast begin are documented within the Git repository.
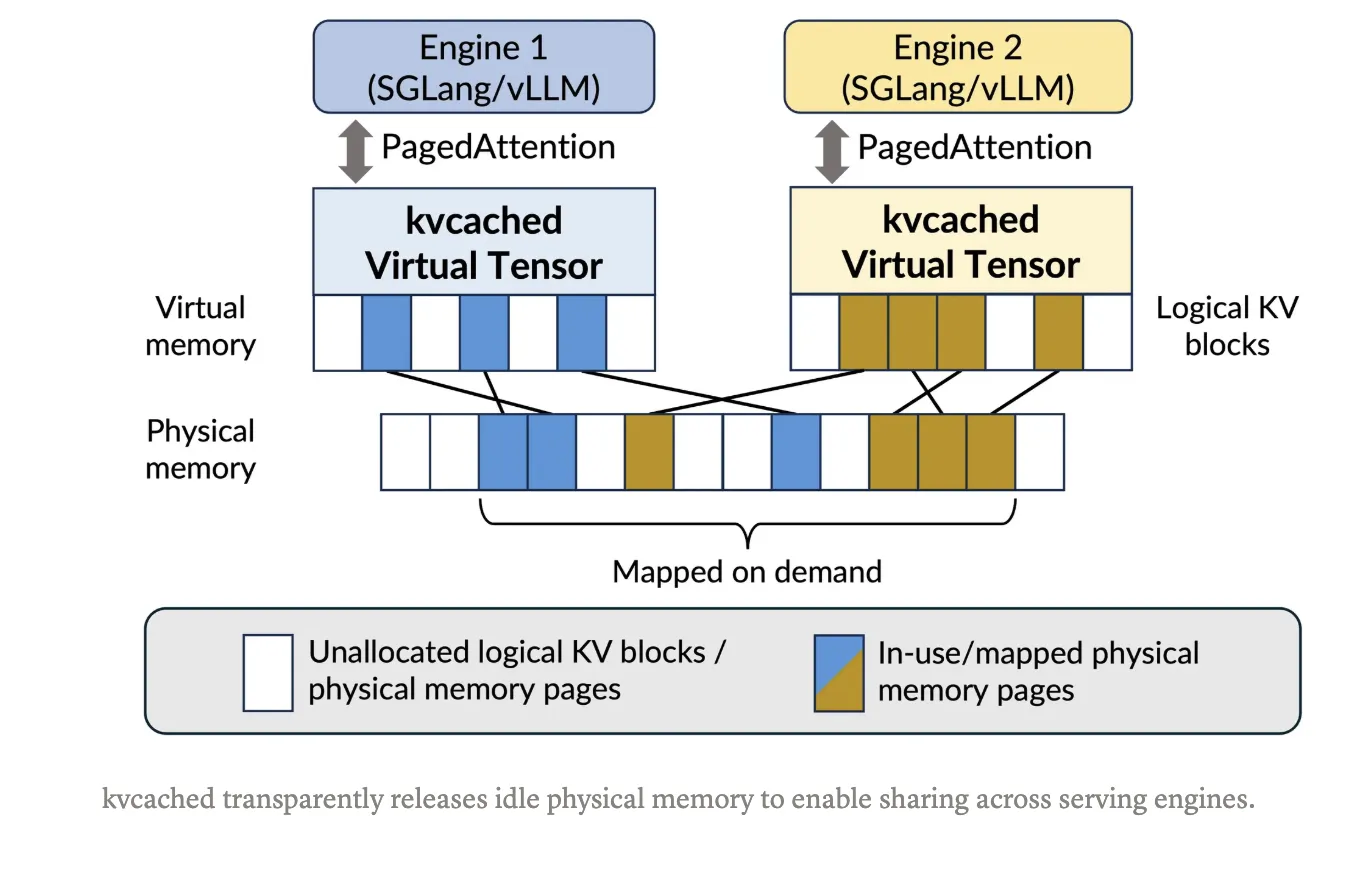
How does it affect at scale?
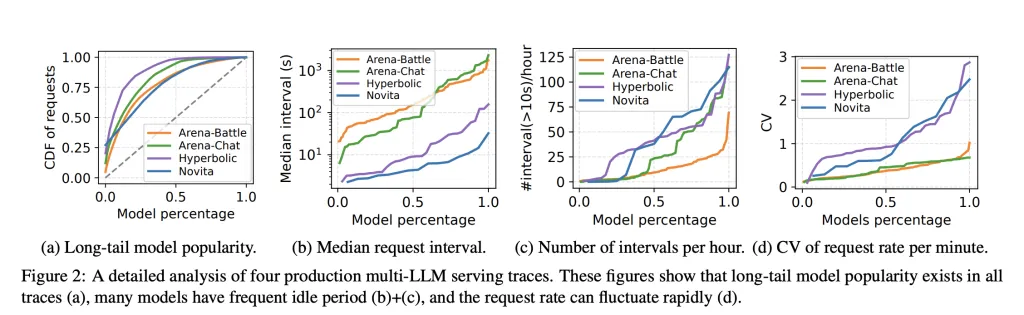
Manufacturing workloads host many fashions with lengthy tail site visitors and spiky bursts. Static reservations go away reminiscence stranded and decelerate time to first token when fashions have to be activated or swapped. The Prism analysis paper reveals that multi-LLM serving requires cross mannequin reminiscence coordination at runtime, not simply compute scheduling. Prism implements on demand mapping of bodily to digital pages and a two degree scheduler, and reviews greater than 2 instances price financial savings and 3.3 instances larger TTFT SLO attainment versus prior methods on actual traces. kvcached focuses on the reminiscence coordination primitive, and gives a reusable element that brings this functionality to mainstream engines.
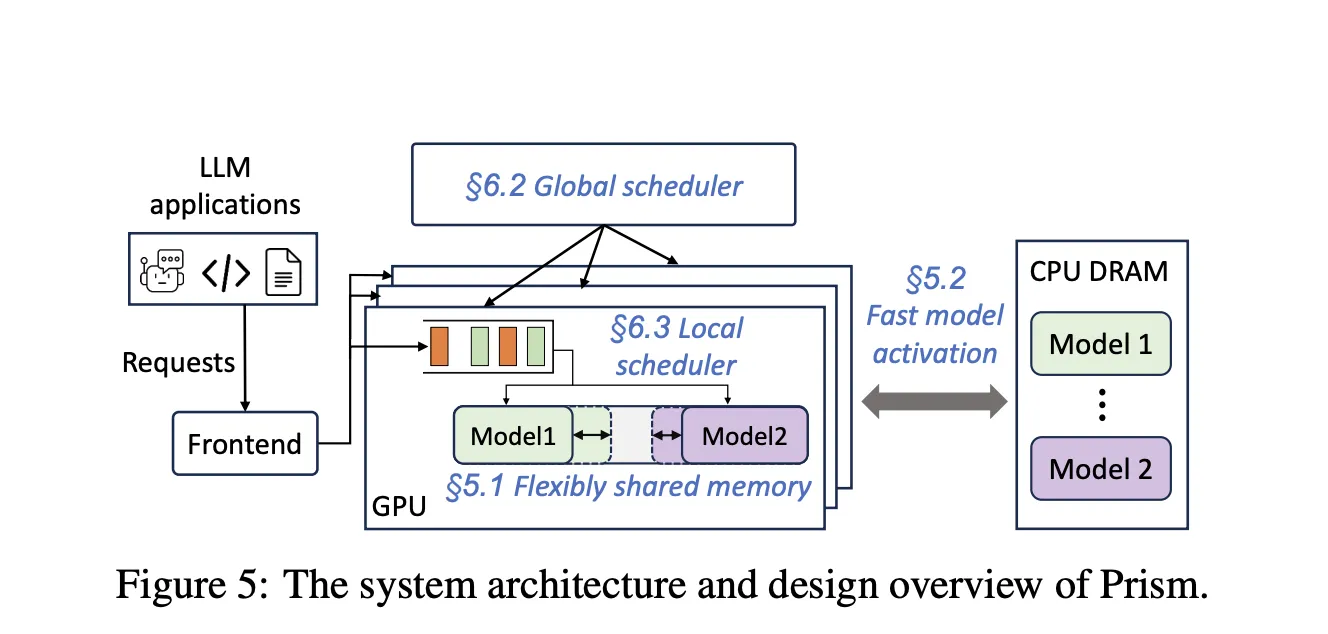
Efficiency indicators
The kvcached group reviews 1.2 instances to twenty-eight instances quicker time to first token in multi mannequin serving, as a result of speedy reuse of freed pages and the elimination of enormous static allocations. These numbers come from multi-LLM eventualities the place activation latency and reminiscence headroom dominate tail latency. The analysis group word kvcached’s compatibility with SGLang and vLLM, and describe elastic KV allocation because the core mechanism.
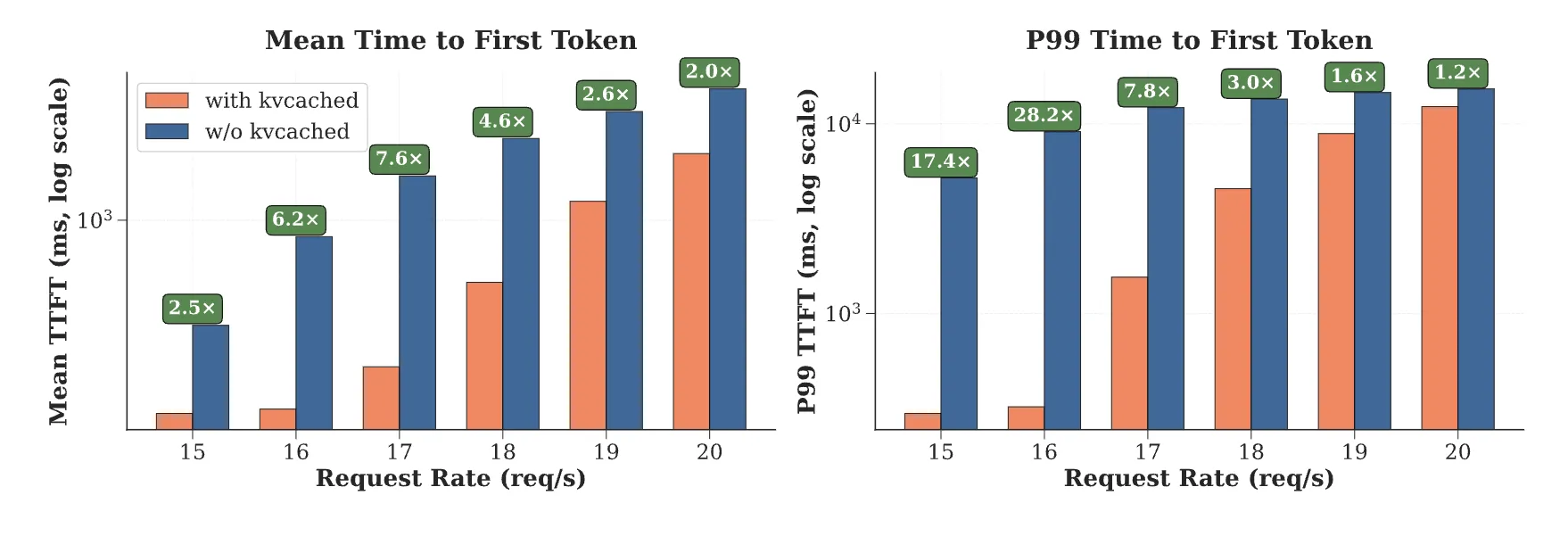
How is it associated to latest analysis?
Latest work has moved from mounted partitioning to digital reminiscence primarily based strategies for KV administration. Prism extends VMM primarily based allocation to multi-LLM settings with cross mannequin coordination and scheduling. Prior efforts like vAttention discover CUDA VMM for single mannequin serving to keep away from fragmentation with out PagedAttention. The arc is obvious, use digital reminiscence to maintain KV contiguous in digital area, then map bodily pages elastically because the workload evolves. kvcached operationalizes this concept as a library, which simplifies adoption inside present engines.
Sensible Purposes for Devs
Colocation throughout fashions: Engines can colocate a number of small or medium fashions on one machine. When one mannequin goes idle, its KV pages free shortly and one other mannequin can broaden its working set with out restart. This reduces head of line blocking throughout bursts and improves TTFT SLO attainment.
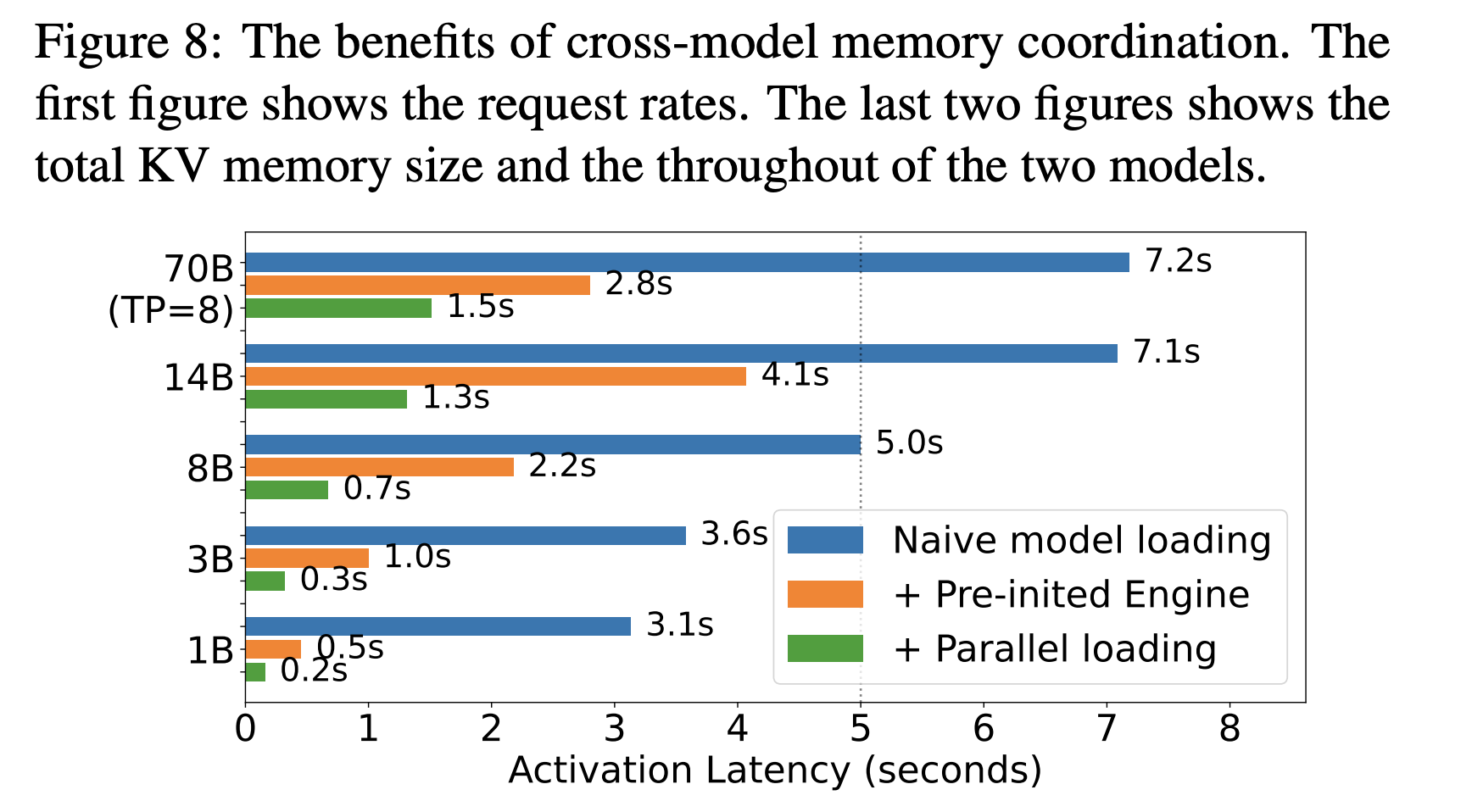
Activation conduct: Prism reviews activation instances of about 0.7 seconds for an 8B mannequin and about 1.5 seconds for a 70B mannequin with streaming activation. kvcached advantages from related rules as a result of digital reservations enable engines to arrange tackle ranges upfront, then map pages as tokens arrive.
Autoscaling for serverless LLM: Wonderful grained web page mapping makes it possible to scale replicas extra ceaselessly and to run chilly fashions in a heat state with minimal reminiscence footprint. This allows tighter autoscaling loops and reduces the blast radius of sizzling spots.
Offloading and future work. Digital reminiscence opens the door to KV offload to host reminiscence or NVMe when the entry sample permits it. NVIDIA’s latest information on managed reminiscence for KV offload on GH200 class methods reveals how unified tackle areas can prolong capability at acceptable overheads. The kvcached maintainers additionally talk about offload and compaction instructions in public threads. Confirm throughput and latency in your personal pipeline, since entry locality and PCIe topology have robust results.
Key Takeaways
- kvcached virtualizes the KV cache utilizing GPU digital reminiscence, engines reserve contiguous digital area and map bodily pages on demand, enabling elastic allocation and reclamation underneath dynamic masses.
- It integrates with mainstream inference engines, particularly SGLang and vLLM, and is launched underneath Apache 2.0, making adoption and modification simple for manufacturing serving stacks.
- Public benchmarks report 1.2 instances to twenty-eight instances quicker time to first token in multi mannequin serving as a result of speedy reuse of freed KV pages and the elimination of enormous static reservations.
- Prism reveals that cross mannequin reminiscence coordination, carried out through on demand mapping and two degree scheduling, delivers greater than 2 instances price financial savings and three.3 instances larger TTFT SLO attainment on actual traces, kvcached provides the reminiscence primitive that mainstream engines can reuse.
- For clusters that host many fashions with bursty, lengthy tail site visitors, virtualized KV cache permits protected colocation, quicker activation, and tighter autoscaling, with reported activation round 0.7 seconds for an 8B mannequin and 1.5 seconds for a 70B mannequin within the Prism analysis.
kvcached is an efficient strategy towards GPU reminiscence virtualization for LLM serving, not a full working system, and that readability issues. The library reserves digital tackle area for the KV cache, then maps bodily pages on demand, which permits elastic sharing throughout fashions with minimal engine modifications. This aligns with proof that cross mannequin reminiscence coordination is crucial for multi mannequin workloads and improves SLO attainment and value underneath actual traces. General, kvcached advances GPU reminiscence coordination for LLM serving, manufacturing worth is determined by per cluster validation.
Take a look at the GitHub Repo, Paper 1, Paper 2 and Technical particulars. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.