

{kind=link}
Dataricks is thrilled to announce the Basic Availability (GA) of Major Key (PK) and International Key (FK) constraints, beginning in Databricks Runtime 15.2 and Databricks SQL 2024.30. This launch follows a extremely profitable public preview, embraced by a whole lot of weekly energetic clients, and additional represents a big milestone in enhancing knowledge integrity and relational knowledge administration throughout the Lakehouse.
Moreover, Databricks can now use these constraints to optimize queries and remove pointless operations from the question plan, delivering a lot quicker efficiency.
Major Key and International Key Constraints
Major Keys (PKs) and International Keys (FKs) are important parts in relational databases, performing as elementary constructing blocks for knowledge modeling. They supply details about the information relationships within the schema to customers, instruments and purposes; and allow optimizations that leverage constraints to hurry up queries. Major and overseas keys are actually typically obtainable on your Delta Lake tables hosted in Unity Catalog.
SQL Language
You may outline constraints once you create a desk:
CREATE TABLE Customers (
UserID INT NOT NULL PRIMARY KEY,
UserName STRING,
Electronic mail STRING,
SignUpDate DATE
);Within the above instance, we outline a major key constraint on the column UserID. Databricks additionally helps constraints on teams of columns as properly.
You can too modify current Delta tables so as to add or take away constraints:
CREATE TABLE Merchandise (
ProductID INT NOT NULL,
ProductName STRING,
Worth DECIMAL(10,2),
CategoryID INT
);
ALTER TABLE Merchandise ADD CONSTRAINT products_pk PRIMARY KEY (ProductID);
ALTER TABLE Merchandise DROP CONSTRAINT products_pk;Right here we create the first key named products_pk on the non-nullable column ProductID in an current desk. To efficiently execute this operation, you should be the proprietor of the desk. Notice that constraint names should be distinctive throughout the schema.
The following command removes the first key by specifying the title.
The identical course of applies for overseas keys. The next desk defines two overseas keys at desk creation time:
CREATE TABLE Purchases (
PurchaseID INT PRIMARY KEY,
UserID INT,
ProductID INT,
PurchaseDate DATE,
Amount INT,
FOREIGN KEY (UserID) REFERENCES Customers(UserID),
FOREIGN KEY (ProductID) REFERENCES Merchandise(ProductID)
);Please seek advice from the documentation on CREATE TABLE and ALTER TABLE statements for extra particulars on the syntax and operations associated to constraints.
Major key and overseas key constraints aren’t enforced within the Databricks engine, however they could be helpful for indicating an information integrity relationship that’s supposed to carry true. Databricks can as an alternative implement major key constraints upstream as a part of the ingest pipeline. See Managed knowledge high quality with Delta Dwell Tables for extra data on enforced constraints. Databricks additionally helps enforced NOT NULL and CHECK constraints (see the Constraints documentation for extra data).
Accomplice Ecosystem
Instruments and purposes equivalent to the most recent model of Tableau and PowerBI can routinely import and make the most of your major key and overseas key relationships from Databricks via JDBC and ODBC connectors.
View the constraints
There are a number of methods to view the first key and overseas key constraints outlined within the desk. You can too merely use SQL instructions to view constraint data with the DESCRIBE TABLE EXTENDED command:
> DESCRIBE TABLE EXTENDED Purchases
... (omitting different outputs)
# Constraints
purchases_pk PRIMARY KEY (`PurchaseID`)
purchases_products_fk FOREIGN KEY (`ProductID`) REFERENCES `foremost`
.`instance`.`merchandise` (`ProductID`)
purchases_users_fk FOREIGN KEY (`UserID`) REFERENCES `foremost`
.`instance`.`customers` (`UserID`)Catalog Explorer and Entity Relationship Diagram
You can too view the constraints data via the Catalog Explorer:
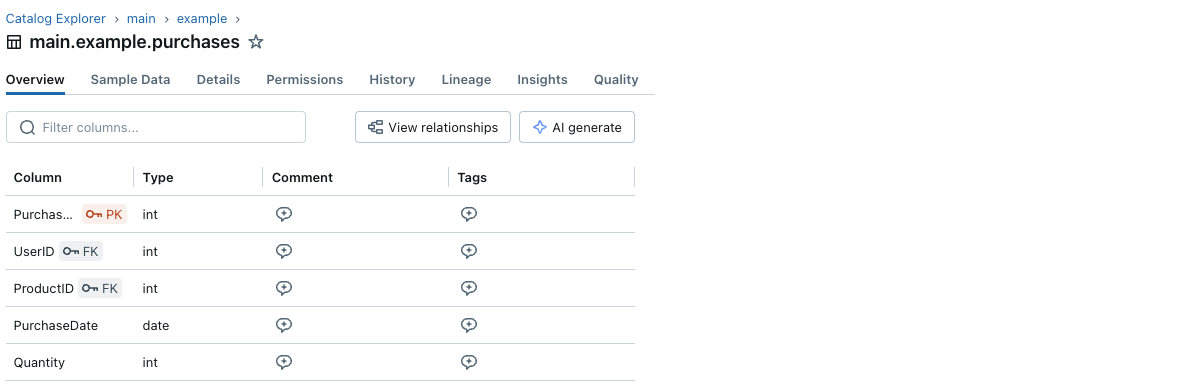
Every major key and overseas key column has a small key icon subsequent to its title.
And you’ll visualize the first and overseas key data and the relationships between tables with the Entity Relationship Diagram in Catalog Explorer. Beneath is an instance of a desk purchases referencing two tables, customers and merchandise:

INFORMATION SCHEMA
The next INFORMATION_SCHEMA tables additionally present constraint data:
Use the RELY choice to allow optimizations
If you recognize that the first key constraint is legitimate, (for instance, as a result of your knowledge pipeline or ETL job enforces it) then you’ll be able to allow optimizations primarily based on the constraint by specifying it with the RELY choice, like:
PRIMARY KEY (c_customer_sk) RELYUtilizing the RELY choice lets Databricks optimize queries in ways in which depend upon the constraint’s validity, since you are guaranteeing that the information integrity is maintained. Train warning right here as a result of if a constraint is marked as RELY however the knowledge violates the constraint, your queries could return incorrect outcomes.
When you don’t specify the RELY choice for a constraint, the default is NORELY, during which case constraints should still be used for informational or statistical functions, however queries won’t depend on them to run accurately.
The RELY choice and the optimizations using it are at present obtainable for major keys, and also will be coming quickly for overseas keys.
You may modify a desk’s major key to alter whether or not it’s RELY or NORELY by utilizing ALTER TABLE, for instance:
ALTER TABLE buyer DROP PRIMARY KEY;
ALTER TABLE buyer ADD PRIMARY KEY (c_customer_sk) RELYVelocity up your queries by eliminating pointless aggregations
One easy optimization we will do with RELY major key constraints is eliminating pointless aggregates. For instance, in a question that’s making use of a definite operation over a desk with a major key utilizing RELY:
SELECT DISTINCT c_customer_sk FROM buyer;We will take away the pointless DISTINCT operation:
SELECT c_customer_sk FROM buyer;As you’ll be able to see, this question depends on the validity of the RELY major key constraint – if there are duplicate buyer IDs within the buyer desk, then the remodeled question will return incorrect duplicate outcomes. You might be accountable for imposing the validity of the constraint in the event you set the RELY choice.
If the first secret’s NORELY (the default), then the optimizer won’t take away the DISTINCT operation from the question. Then it could run slower however at all times returns appropriate outcomes even when there are duplicates. If the first secret’s RELY, Databricks can take away the DISTINCT operation, which may vastly velocity up the question – by about 2x for the above instance.
Velocity up your queries by eliminating pointless joins
One other very helpful optimization we will carry out with RELY major keys is eliminating pointless joins. If a question joins a desk that’s not referenced anyplace besides within the be a part of situation, then the optimizer can decide that the be a part of is pointless, and take away the be a part of from the question plan.
To provide an instance, for instance we have now a question becoming a member of two tables, store_sales and buyer, joined on the first key of the client desk PRIMARY KEY (c_customer_sk) RELY.
SELECT SUM(ss_quantity)
FROM store_sales ss
LEFT JOIN buyer c
ON ss_customer_sk = c_customer_sk;If we did not have the first key, every row of store_sales may probably match a number of rows in buyer, and we’d must execute the be a part of to compute the right SUM worth. However as a result of the desk buyer is joined on its major key, we all know that the be a part of will output one row for every row of store_sales.
So the question solely truly wants the column ss_quantity from the actual fact desk store_sales. Due to this fact, the question optimizer can completely remove the be a part of from the question, remodeling it into:
SELECT SUM(ss_quantity)
FROM store_sales ssThis runs a lot quicker by avoiding your entire be a part of – on this instance we observe the optimization velocity up the question from 1.5 minutes to six seconds!. And the advantages could be even bigger when the be a part of entails many tables that may be eradicated!
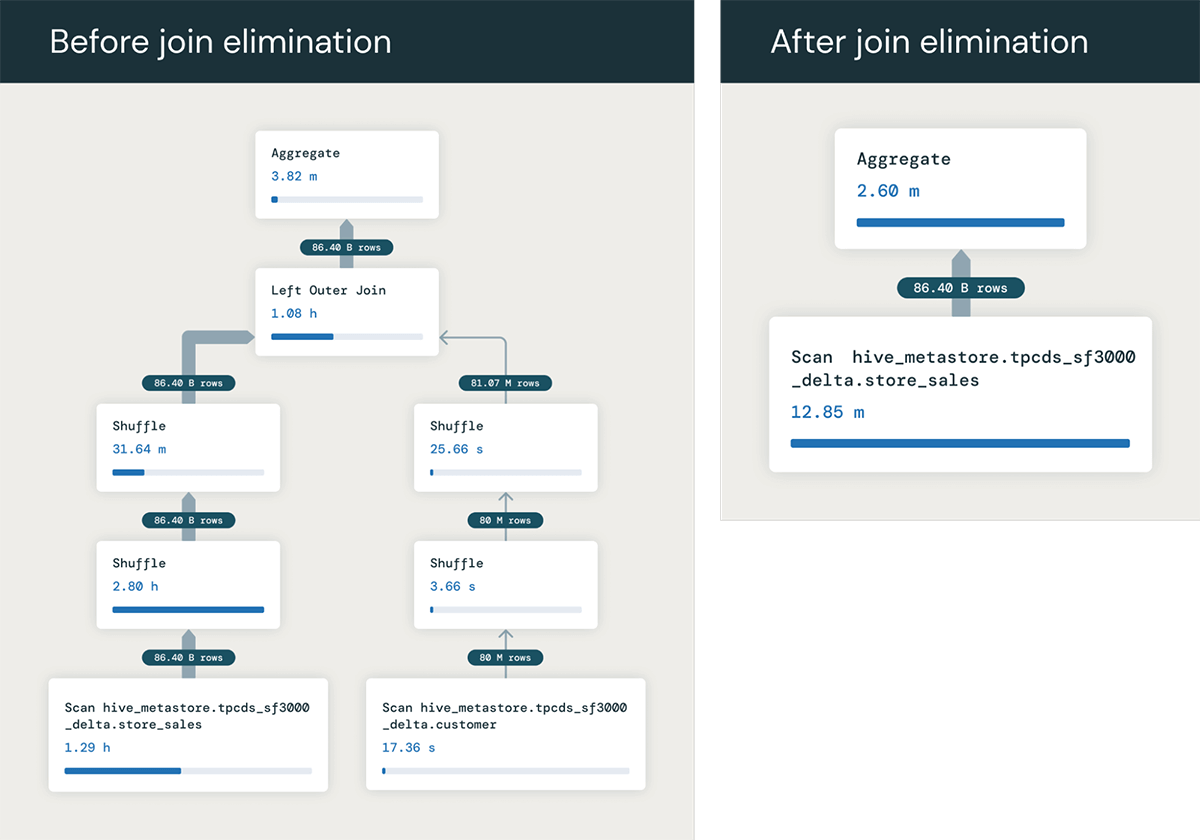
You might ask, why would anybody run a question like this? It is truly far more frequent than you would possibly suppose! One frequent cause is that customers assemble views that be a part of collectively a number of tables, equivalent to becoming a member of collectively many reality and dimension tables. They write queries over these views which regularly use columns from solely among the tables, not all – and so the optimizer can remove the joins towards the tables that are not wanted in every question. This sample can be frequent in lots of Enterprise Intelligence (BI) instruments, which regularly generate queries becoming a member of many tables in a schema even when a question solely makes use of columns from among the tables.
Conclusion
Since its public preview, over 2600 + Databricks clients have used major key and overseas key constraints. In the present day, we’re excited to announce the final availability of this function, marking a brand new stage in our dedication to enhancing knowledge administration and integrity in Databricks.
Moreover, Databricks now takes benefit of key constraints with the RELY choice to optimize queries, equivalent to by eliminating pointless aggregates and joins, leading to a lot quicker question efficiency.