

{kind=link}
Massive language fashions (LLMs) akin to GPT-4, Llama, and Gemini are a few of the most important developments within the discipline of synthetic intelligence (AI), and their skill to know and generate human language is remodeling the way in which that people talk with machines. Greater than 70% of firms use AI of their enterprise capabilities, in accordance with McKinsey. LLMs are pretrained on huge quantities of textual content information, enabling them to acknowledge language construction and semantics, in addition to construct a broad data base that covers a variety of subjects. This generalized data can be utilized to drive a variety of purposes, together with digital assistants, textual content or code autocompletion, and textual content summarization; nevertheless, many fields require extra specialised data and experience.
A site-specific language mannequin could be carried out in two methods: constructing the mannequin from scratch, or fine-tuning a pretrained LLM. Constructing a mannequin from scratch is a computationally and financially costly course of that requires large quantities of information, however fine-tuning could be executed with smaller datasets. Within the fine-tuning course of, an LLM undergoes further coaching utilizing domain-specific datasets which can be curated and labeled by material specialists with a deep understanding of the sphere. Whereas pretraining offers the LLM basic data and linguistic capabilities, fine-tuning imparts extra specialised abilities and experience.
LLMs could be fine-tuned for many industries or domains; the important thing requirement is high-quality coaching information with correct labeling. By means of my expertise creating LLMs and machine studying (ML) instruments for universities and shoppers throughout industries like finance and insurance coverage, I’ve gathered a number of confirmed finest practices and recognized frequent pitfalls to keep away from when labeling information for fine-tuning ML fashions. Knowledge labeling performs a significant function in laptop imaginative and prescient (CV) and audio processing, however for this information, I deal with LLMs and pure language processing (NLP) information labeling, together with a walkthrough of find out how to label information for the fine-tuning of OpenAI’s GPT-4o.
What Are Effective-tuned LLMs?
LLMs are a kind of basis mannequin, which is a general-purpose machine studying mannequin able to performing a broad vary of duties. Effective-tuned LLMs are fashions which have obtained additional coaching, making them extra helpful for specialised industries and duties. LLMs are skilled on language information and have an distinctive command of syntax, semantics, and context; regardless that they’re extraordinarily versatile, they may underperform with extra specialised duties the place area experience is required. For these purposes, the inspiration LLM could be fine-tuned utilizing smaller labeled datasets that target particular domains. Effective-tuning leverages supervised studying, a class of machine studying the place the mannequin is proven each the enter object and the specified output worth (the annotations). These prompt-response pairs allow the mannequin to be taught the connection between the enter and output in order that it could actually make related predictions on unseen information.
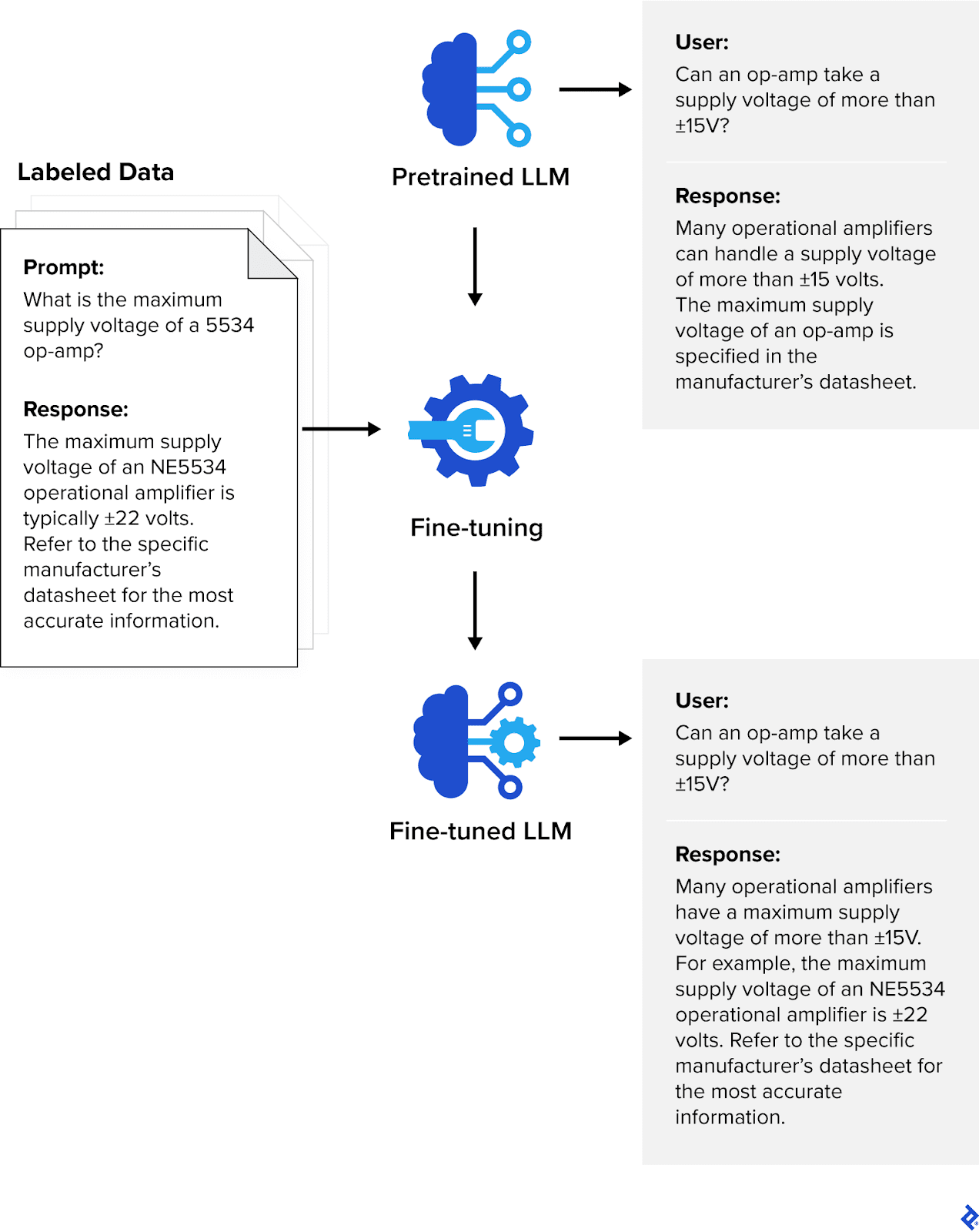
Effective-tuned LLMs have already confirmed to be invaluable in streamlining services throughout plenty of industries:
- Healthcare: HCA Healthcare, one of many largest hospital networks within the US, makes use of Google’s MedLM for transcriptions of doctor-patient interactions in emergency rooms and studying digital well being data to determine vital factors. MedLM is a sequence of fashions which can be fine-tuned for the healthcare business. MedLM is predicated on Med-PaLM 2, the primary LLM to succeed in expert-level efficiency (85%+) on questions much like these discovered on the US Medical Licensing Examination (USMLE).
- Finance: Establishments akin to Morgan Stanley, Financial institution of America, and Goldman Sachs use fine-tuned LLMs to investigate market traits, parse monetary paperwork, and detect fraud. FinGPT, an open-source LLM that goals to democratize monetary information, is fine-tuned on monetary information and social media posts, making it extremely efficient at sentiment evaluation. FinBERT is one other open-source mannequin fine-tuned on monetary information, and designed for monetary sentiment evaluation.
- Authorized: Whereas a fine-tuned LLM can’t change human attorneys, it could actually assist them with authorized analysis and contract evaluation. Casetext’s CoCounsel is an AI authorized assistant that automates most of the duties that decelerate the authorized course of, akin to analyzing and drafting authorized paperwork. CoCounsel is powered by GPT-4 and fine-tuned with all the data in Casetext’s authorized database.
In comparison with basis LLMs, fine-tuned LLMs present appreciable enhancements with inputs of their specialised domains—however the high quality of the coaching information is paramount. The fine-tuning information for CoCounsel, for instance, was based mostly on roughly 30,000 authorized questions refined by a crew of attorneys, area specialists, and AI engineers over a interval of six months. It was deemed prepared for launch solely after about 4,000 hours of labor. Though CoCounsel has already been launched commercially, it continues to be fine-tuned and improved—a key step in holding any mannequin updated.
The Knowledge Labeling Course of
The annotations required for fine-tuning encompass instruction-expected response pairs, the place every enter corresponds with an anticipated output. Whereas deciding on and labeling information could seem to be an easy course of, a number of issues add to the complexity. The information must be clear and effectively outlined; it should even be related, but cowl a complete vary of potential interactions. This consists of eventualities which will have a excessive stage of ambiguity, akin to performing sentiment evaluation on product opinions which can be sarcastic in nature. Normally, the extra information a mannequin is skilled on, the higher; nevertheless, when gathering LLM coaching information, care must be taken to make sure that it’s consultant of a broad vary of contexts and linguistic nuances.
As soon as the info is collected, it sometimes requires cleansing and preprocessing to take away noise and inconsistencies. Duplicate data and outliers are eliminated, and lacking values are substituted by way of imputation. Unintelligible textual content can be flagged for investigation or elimination.
On the annotation stage, information is tagged with the suitable labels. Human annotators play a necessary function within the course of, as they supply the perception needed for correct labels. To take a few of the workload off annotators, many labeling platforms supply AI-assisted prelabeling, an automated information labeling course of that creates the preliminary labels and identifies vital phrases and phrases.
After the info is labeled, the labels endure validation and high quality assurance (QA), a assessment for accuracy and consistency. Knowledge factors that have been labeled by a number of annotators are reviewed to obtain consensus. Automated instruments can be used to validate the info and flag any discrepancies. After the QA course of, the labeled information is prepared for use for mannequin coaching.
Annotation Tips and Requirements for NLP
One of the vital early steps within the information annotation workflow is creating a transparent set of tips and requirements for human annotators to comply with. Tips must be simple to know and constant as a way to keep away from introducing any variability that may confuse the mannequin throughout coaching.
Textual content classification, akin to labeling the physique of an electronic mail as spam, is a standard information labeling activity. The rules for textual content classification ought to embody clear definitions for every potential class, in addition to directions on find out how to deal with textual content that will not match into any class.
When labeling textual content, annotators typically carry out named entity recognition (NER), figuring out and tagging names of individuals, organizations, areas, and different correct nouns. The rules for NER duties ought to listing all potential entity sorts with examples on find out how to deal with them. This consists of edge circumstances, akin to partial matches or nested entities.
Annotators are sometimes tasked with labeling the sentiment of textual content as optimistic, damaging, or impartial. With sentiment evaluation, every class must be clearly outlined. As a result of sentiments can typically be delicate or blended, examples must be offered to assist annotators distinguish between them. The rules must also deal with potential biases associated to gender, race, or cultural context.
Coreference decision refers back to the identification of all expressions that discuss with the identical entity. The rules for coreference decision ought to present directions on find out how to monitor and label entities throughout completely different sentences and paperwork, and specify find out how to deal with pronouns.
With part-of-speech (POS) tagging, annotators label every phrase with part of speech, for instance, noun, adjective, or verb. For POS tagging, the rules ought to embody directions on find out how to deal with ambiguous phrases or phrases that might match into a number of classes.
As a result of LLM information labeling typically entails subjective judgment, detailed tips on find out how to deal with ambiguity and borderline circumstances will assist annotators produce constant and proper labels. One instance is Common NER, a mission consisting of multilingual datasets with crowdsourced annotations; its annotation tips present detailed data and examples for every entity kind, in addition to the perfect methods to deal with ambiguity.
Greatest Practices for NLP and LLM Knowledge Labeling
As a result of doubtlessly subjective nature of textual content information, there could also be challenges within the annotation course of. Many of those challenges could be addressed by following a set of information labeling finest practices. Earlier than you begin, be sure to have a complete understanding of the issue you might be fixing for. The extra data you might have, the higher ready you can be to create a dataset that covers all edge circumstances and variations. When recruiting annotators, your vetting course of must be equally complete. Knowledge labeling is a activity that requires reasoning and perception, in addition to sturdy consideration to element. These further methods are extremely helpful to the annotation course of:
- Iterative refinement: The dataset could be divided into small subsets and labeled in phases. By means of suggestions and high quality checks, the method and tips could be improved between phases, with any potential pitfalls recognized and corrected early.
- Divide and conquer method: Complicated duties could be damaged up into steps. With sentiment evaluation, phrases or phrases containing sentiment may very well be recognized first, with the general sentiment of the paragraph decided utilizing rule-based model-assisted automation.
Superior Strategies for NLP and LLM Knowledge Labeling
There are a number of superior strategies that may enhance the effectivity, accuracy, and scalability of the labeling course of. Many of those strategies make the most of automation and machine studying fashions to optimize the workload for human annotators, reaching higher outcomes with much less guide effort.
The guide labeling workload could be lowered through the use of lively studying algorithms; that is when pretrained ML fashions determine the info factors that might profit from human annotation. These embody information factors the place the mannequin has the bottom confidence within the predicted label (uncertainty sampling), and borderline circumstances, the place the info factors fall closest to the choice boundary between two lessons (margin sampling).
NER duties could be streamlined with gazetteers, that are basically predefined lists of entities and their corresponding sorts. Utilizing a gazetteer, the identification of frequent entities could be automated, liberating up people to deal with the ambiguous information factors.
Longer textual content passages could be shortened by way of textual content summarization. Utilizing an ML mannequin to focus on key sentences or summarize longer passages can scale back the period of time it takes for human annotators to carry out sentiment evaluation or textual content classification.
The coaching dataset could be expanded with information augmentation. Artificial information could be routinely generated by means of paraphrasing, again translation, and changing phrases with synonyms. A generative adversarial community (GAN) can be used to generate information factors that mimic a given dataset. These strategies improve the coaching dataset, making the ensuing mannequin considerably extra sturdy, with minimal further guide labeling.
Weak supervision is a time period that covers a wide range of strategies used to coach fashions with noisy, inaccurate, or in any other case incomplete information. One kind of weak supervision is distant supervision, the place current labeled information from a associated activity is used to deduce relationships in unlabeled information. For instance, a product assessment labeled with a optimistic sentiment could include phrases like “dependable” and “top quality,” which can be utilized to assist decide the sentiment of an unlabeled assessment. Lexical assets, like a medical dictionary, can be used to assist in NER. Weak supervision makes it potential to label massive datasets in a short time or when guide labeling is simply too costly. This comes on the expense of accuracy, nevertheless, and if the highest-quality labels are required, human annotators must be concerned.
Lastly, with the provision of contemporary “benchmark” LLMs akin to GPT-4, the annotation course of could be utterly automated with LLM-generated labels, that means that the response for an instruction-expected response pair is generated by the LLM. For instance, a product assessment may very well be enter into the LLM together with directions to categorise if the sentiment of the assessment is optimistic, damaging, or impartial, making a labeled information level that can be utilized to coach one other LLM. In lots of circumstances, the whole course of could be automated, with the directions additionally generated by the LLM. Although information labeling with a benchmark LLM could make the method quicker, it won’t give the fine-tuned mannequin data past what the LLM already has. To advance the capabilities of the present era of ML fashions, human perception is required.
There are a number of instruments and platforms that make the info labeling workflow extra environment friendly. Smaller, lower-budget tasks can make the most of open-source information labeling software program akin to Doccano and Label Studio. For bigger tasks, industrial platforms supply extra complete AI-assisted prelabeling; mission, crew, and QA administration instruments; dashboards to visualise progress and analytics; and, most significantly, a assist crew. Among the extra extensively used industrial instruments embody Labelbox, Amazon’s SageMaker Floor Reality, Snorkel Move, and SuperAnnotate.
Extra instruments that may assist with information labeling for LLMs embody the next:
- Cleanlab makes use of statistical strategies and mannequin evaluation to determine and repair points in datasets, together with outliers, duplicates, and label errors. Any points are highlighted for human assessment together with options for corrections.
- AugLy is an information augmentation library that helps textual content, picture, audio, and video information. Developed by Meta AI, AugLy gives greater than 100 augmentation strategies that can be utilized to generate artificial information for mannequin coaching.
- skweak is an open-source Python library that mixes completely different sources of weak supervision to generate labeled information. It focuses on NLP duties, and permits customers to generate heuristic guidelines or use pretrained fashions and distant supervision to carry out NER, textual content classification, and identification of relationships in textual content.
An Overview of the LLM Effective-tuning Course of
Step one within the fine-tuning course of is deciding on the pretrained LLM. There are a number of sources for pretrained fashions, together with Hugging Face’s Transformers or NLP Cloud, which supply a variety of LLMs in addition to a platform for coaching and deployment. Pretrained LLMs can be obtained from OpenAI, Kaggle, and Google’s TensorFlow Hub.
Coaching information ought to usually be massive and numerous, overlaying a variety of edge circumstances and ambiguities. A dataset that’s too small can result in overfitting, the place the mannequin learns the coaching dataset too effectively, and because of this, performs poorly on unseen information. Overfitting can be attributable to coaching with too many epochs, or full passes by means of the dataset. Coaching information that isn’t numerous can result in bias, the place the mannequin performs poorly on underrepresented eventualities. Moreover, bias could be launched by annotators. To attenuate bias within the labels, the annotation crew ought to have numerous backgrounds and correct coaching on find out how to acknowledge and scale back their very own biases.

Hyperparameter tuning can have a major affect on the coaching outcomes. Hyperparameters management how the mannequin learns, and optimizing these settings can stop undesired outcomes akin to overfitting. Some key hyperparameters embody the next:
- The lincomes price specifies how a lot the interior parameters (weights and biases) are adjusted at every iteration, basically figuring out the pace at which the mannequin learns.
- The batch measurement specifies the variety of coaching samples utilized in every iteration.
- The variety of epochs specifies what number of instances the method is run. One epoch is one full cross by means of the whole dataset.
Frequent strategies for hyperparameter tuning embody grid search, random search, and Bayesian optimization. Devoted libraries akin to Optuna and Ray Tune are additionally designed to streamline the hyperparameter tuning course of.
As soon as the info is labeled and has gone by means of the validation and QA course of, the precise fine-tuning of the mannequin can start. In a typical coaching algorithm, the mannequin generates predictions on batches of information in a step known as the ahead cross. The predictions are then in contrast with the labels, and the loss (a measure of how completely different the predictions are from the precise values) is calculated. Subsequent, the mannequin performs a backward cross, calculating how a lot every parameter contributed to the loss. Lastly, an optimizer, akin to Adam or SGD, is used to regulate the mannequin’s inner parameters as a way to enhance the predictions. These steps are repeated, enabling the mannequin to refine its predictions iteratively till the general loss is minimized. This coaching course of is usually carried out utilizing instruments like Hugging Face’s Transformers, NLP Cloud, or Google Colab. The fine-tuned mannequin could be evaluated towards efficiency metrics akin to perplexity, METEOR, BERTScore, and BLEU.
After the fine-tuning course of is full, the mannequin could be deployed into manufacturing. There are a selection of choices for the deployment of ML fashions, together with NLP Cloud, Hugging Face’s Mannequin Hub, or Amazon’s SageMaker. ML fashions can be deployed on premises utilizing frameworks like Flask or FastAPI. Regionally deployed fashions are sometimes used for improvement and testing, in addition to in purposes the place information privateness and safety is a priority.
Extra challenges when fine-tuning an LLM embody information leakage and catastrophic interference:
Knowledge leakage happens when data within the coaching information additionally seems within the take a look at information, resulting in a very optimistic evaluation of mannequin efficiency. Sustaining strict separation between coaching, validation, and take a look at information is efficient in decreasing information leakage.
Catastrophic interference, or catastrophic forgetting, can happen when a mannequin is skilled sequentially on completely different duties or datasets. When a mannequin is fine-tuned for a particular activity, the brand new data it learns modifications its inner parameters. This variation could trigger a lower in efficiency for extra basic duties. Successfully, the mannequin “forgets” a few of what it has discovered. Analysis is ongoing on find out how to stop catastrophic interference, nevertheless, some strategies that may scale back it embody elastic weight consolidation (EWC), parameter-efficient fine-tuning (PEFT). and replay-based strategies by which outdated coaching information is blended in with the brand new coaching information, serving to the mannequin to recollect earlier duties. Implementing architectures akin to progressive neural networks (PNN) may stop catastrophic interference.
Effective-tuning GPT-4o With Label Studio
OpenAI at present helps fine-tuning for GPT-3.5 Turbo, GPT-4o, GPT-4o mini, babbage-002, and davinci-002 at its developer platform.
To annotate the coaching information, we’ll use the free Neighborhood Version of Label Studio.
First, set up Label Studio by operating the next command:
pip set up label-studio
Label Studio can be put in utilizing Homebrew, Docker, or from supply. Label Studio’s documentation particulars every of the completely different strategies.
As soon as put in, begin the Label Studio server:
label-studio begin
Level your browser to http://localhost:8080 and enroll with an electronic mail deal with and password. After getting logged in, click on the Create button to begin a brand new mission. After the brand new mission is created, choose the template for fine-tuning by going to Settings > Labeling Interface > Browse Templates > Generative AI > Supervised LLM Effective-tuning.
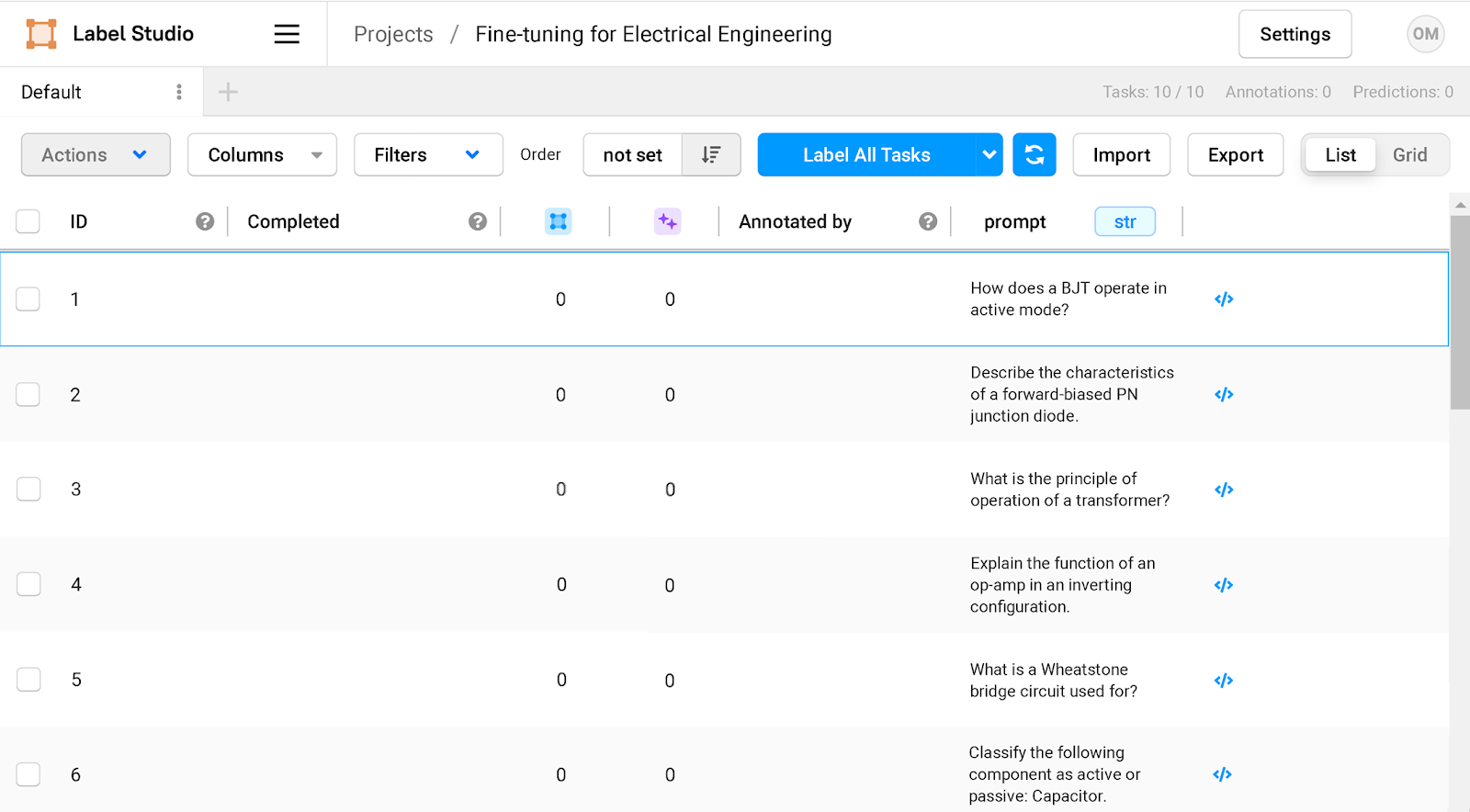
The preliminary set of prompts could be imported or added manually. For this fine-tuning mission, we’ll use electrical engineering questions as our prompts:
How does a BJT function in lively mode?
Describe the traits of a forward-biased PN junction diode.
What's the precept of operation of a transformer?
Clarify the perform of an op-amp in an inverting configuration.
What's a Wheatstone bridge circuit used for?
Classify the next element as lively or passive: Capacitor.
How do you bias a NE5534 op-amp to Class A operation?
How does a Burr-Brown PCM63 chip convert alerts from digital to analog?
What's the historical past of the Telefunken AC701 tube?
What does a voltage regulator IC do?
The questions seem as an inventory of duties within the dashboard.
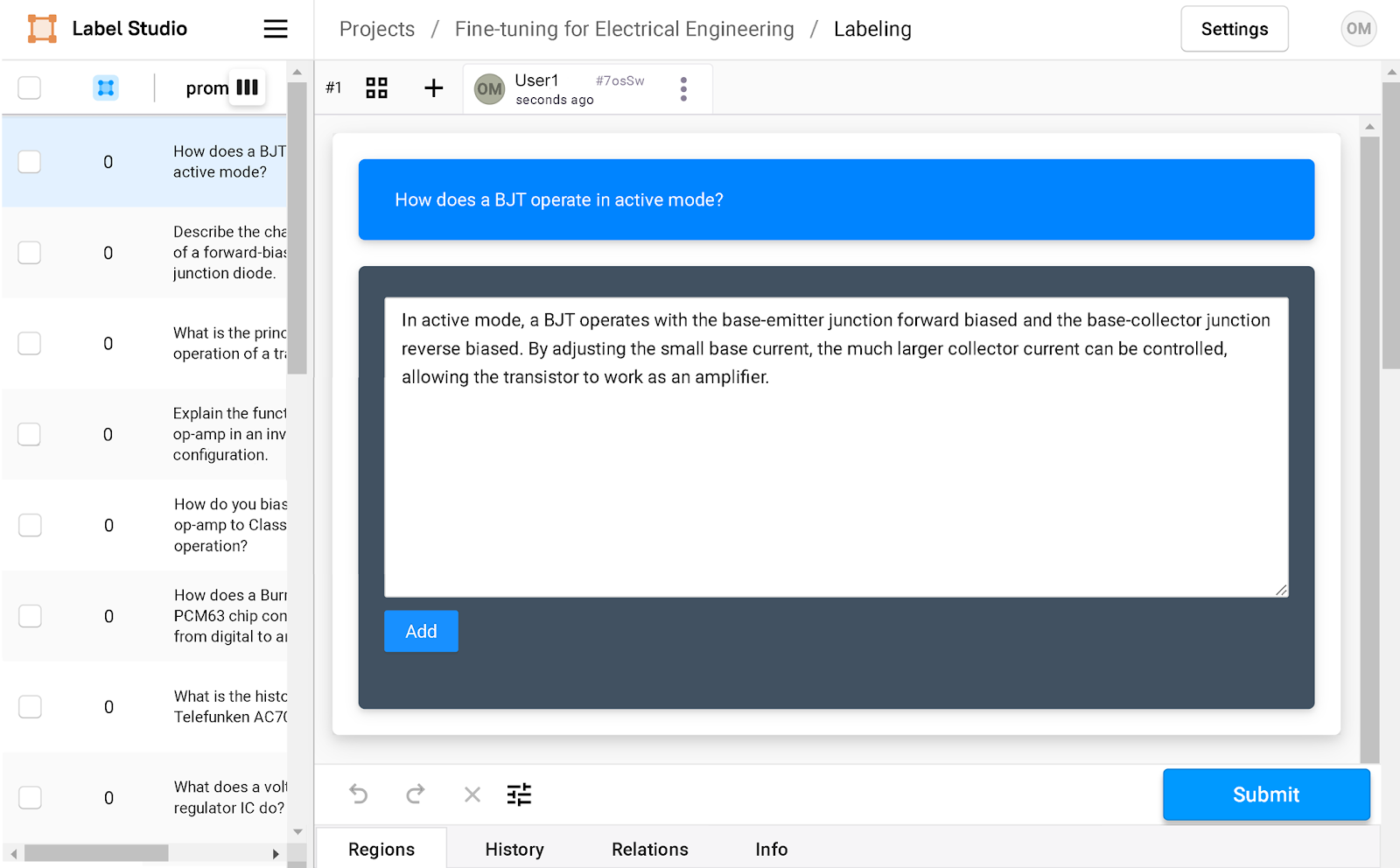
Clicking on every query opens the annotation window, the place the anticipated response could be added.
As soon as all the information factors are labeled, click on the Export button to export your labeled information to a JSON, CSV, or TSV file. On this instance, we’re exporting to a CSV file. Nonetheless, to fine-tune GPT-4o, OpenAI requires the format of the coaching information to be according to its Chat Completions API. The information must be structured in JSON Traces (JSONL) format, with every line containing a “message” object. A message object can include a number of items of content material, every with its personal function, both “system,” “person,” or “assistant”:
System: Content material with the system function modifies the conduct of the mannequin. For instance, the mannequin could be instructed to undertake a sarcastic character or write in an action-packed method. The system function is non-obligatory.
Consumer: Content material with the person function accommodates examples of requests or prompts.
Assistant: Content material with the assistant function offers the mannequin examples of the way it ought to reply to the request or immediate contained within the corresponding person content material.
The next is an instance of 1 message object containing an instruction and anticipated response:
{"messages":
[
{"role": "user", "content": "How does a BJT operate in active mode?"},
{"role": "assistant", "content": "In active mode, a BJT operates with the base-emitter junction forward biased and the base-collector junction reverse biased. By adjusting the small base current, the much larger collector current can be controlled, allowing the transistor to work as an amplifier."}
]
}
A Python script was created as a way to modify the CSV information to have the right format. The script opens the CSV file that was created by Label Studio and iterates by means of every row, changing it into the JSONL format:
import pandas as pd #import the Pandas library
import json
df = pd.read_csv("C:/datafiles/engineering-data.csv") #engineering-data.csv is the csv file that LabelStudio exported
#the file will likely be formatted within the JSONL format
with open("C:/datafiles/finetune.jsonl", "w") as data_file:
for _, row in df.iterrows():
instruction = row["instruction"]
immediate = row["prompt"]
data_file.write(json.dumps(
{"messages": [
{"role": "user" , "content": prompt},
{"role": "assistant" , "content": instruction}
]}))
data_file.write("n")
As soon as the info is prepared, it may be used for fine-tuning at platform.openai.com.
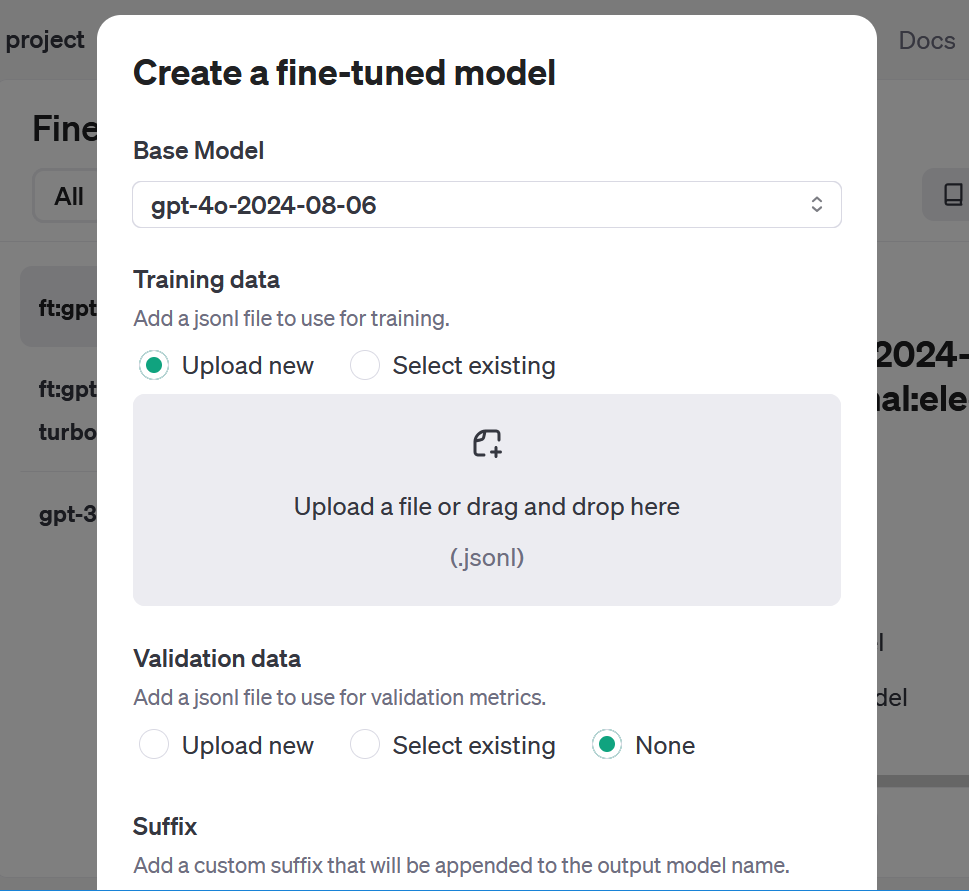
To entry the fine-tuning dashboard, click on Dashboard on the high after which Effective-tuning on the left navigation menu. Clicking on the Create button brings up an interface that means that you can choose the mannequin you wish to prepare, add the coaching information, and regulate three hyperparameters: studying price multiplier, batch measurement, and variety of epochs. Probably the most present mannequin, gpt-4o-2024-08-06 was chosen for this take a look at. The hyperparameters have been left on their default setting of Auto. OpenAI additionally enables you to add a suffix to assist differentiate your fine-tuned fashions. For this take a look at, the suffix was set to “electricalengineer.”
The fine-tuning course of for GPT-4o, together with validation of coaching information and analysis of the finished mannequin, lasted roughly three hours and resulted in 8,700 skilled tokens. In distinction, GPT-4o mini, a smaller and extra cost-efficient mannequin, accomplished the fine-tuning course of in simply 10 minutes.
The outcomes could be examined by clicking the Playground hyperlink. Clicking on the grey drop-down menu close to the highest of the web page reveals you the out there fashions, together with the fine-tuned mannequin. Additionally included are further fashions that characterize checkpoints over the past three epochs of the coaching. These fashions can be utilized for varied functions, together with in circumstances of overfitting; fashions at earlier checkpoints could be examined to find out when the overfitting occurred.
To check the outcomes of the fine-tuning course of, the mannequin was set to gpt-4o and requested an obscure query that it may not have the reply to:
What number of pins does a Telefunken AC701 tube have?
The mannequin responded with:
The Telefunken AC701 is a miniature tube typically utilized in classic microphone designs. It has 8 pins.
Whereas the response is usually appropriate, there’s one small error. The Telefunken AC701 is a tube that was utilized in a few of the most well-known classic microphones in historical past, together with the Neumann M49, M269, KM54, Schoeps M221B, and Telefunken Ela-M251. Nonetheless, the AC701 truly has 5 pins.
The mannequin was set to the fine-tuned mannequin ft:gpt-40-2024-08-06:private:electricalengineer:A3o6coot, and requested the identical query. As a result of the coaching information contained details about the AC701 tube, the response from the fine-tuned mannequin was:
The Telefunken AC701 has 5 pins.
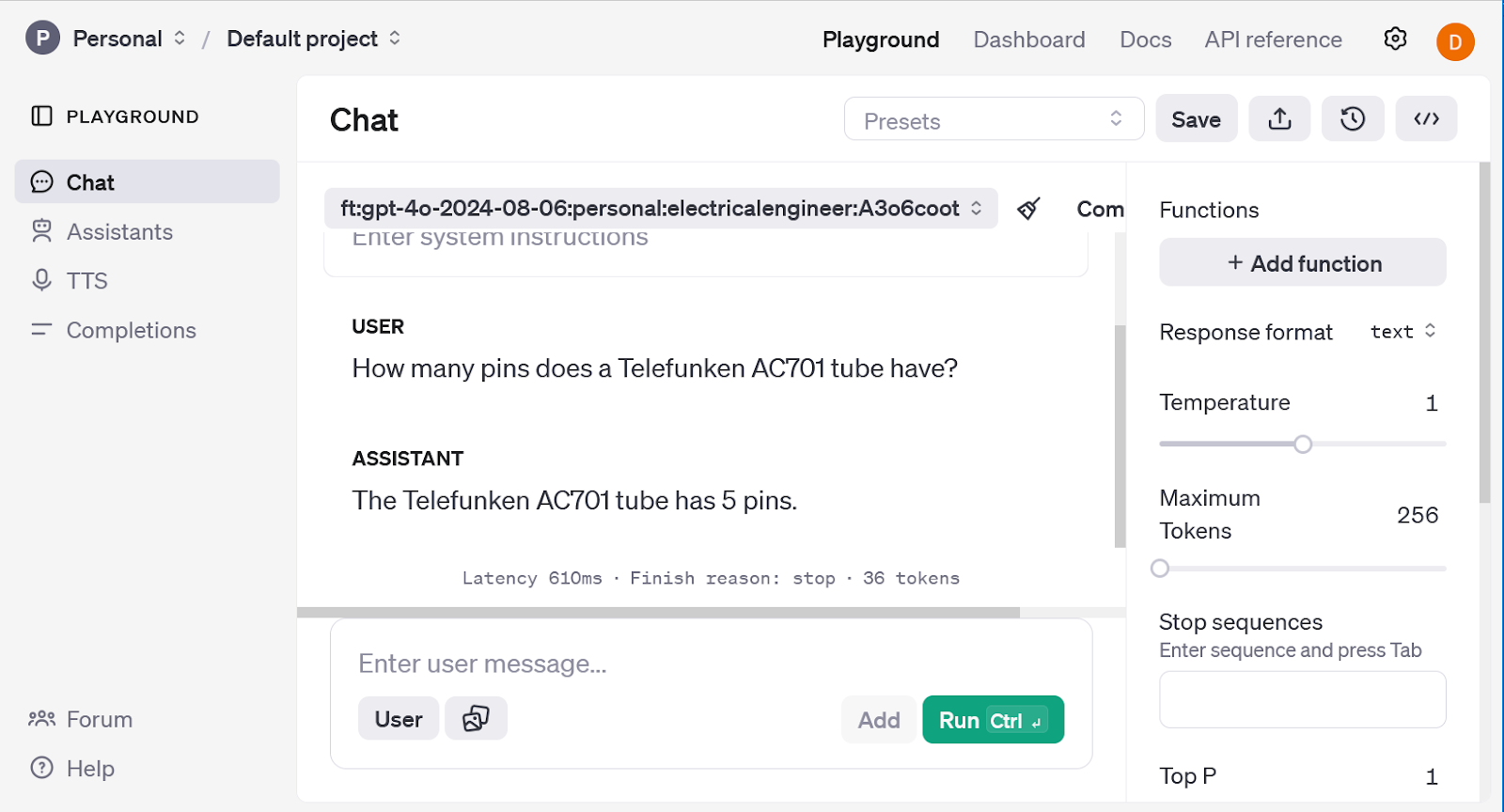
For this query, the fine-tuning course of was profitable and the mannequin was in a position to be taught new details about a classic vacuum tube.
OpenAI’s fine-tuning platform is straightforward to make use of and efficient, nevertheless, it’s restricted to OpenAI fashions. If you wish to fine-tune LLMs like Llama and Mistral, there are a selection of instruments out there, together with AutoTrain, Axolotl, LLaMA-Manufacturing unit, and Unsloth.
The Way forward for Massive Language Fashions
Effective-tuned LLMs have already proven unbelievable promise, with fashions like MedLM and CoCounsel getting used professionally in specialised purposes each day. An LLM that’s tailor-made to a particular area is a particularly highly effective and useful gizmo, however solely when fine-tuned with related and correct coaching information. Automated strategies, akin to utilizing an LLM for information labeling, are able to streamlining the method, however constructing and annotating a high-quality coaching dataset requires human experience.
As information labeling strategies evolve, the potential of LLMs will proceed to develop. Improvements in lively studying will enhance accuracy and effectivity, in addition to accessibility. Extra numerous and complete datasets will even grow to be out there, additional enhancing the info the fashions are skilled on. Moreover, strategies akin to retrieval augmented era (RAG) could be mixed with fine-tuned LLMs to generate responses which can be extra present and dependable.
LLMs are a comparatively younger know-how with loads of room for progress. By persevering with to refine information labeling methodologies, fine-tuned LLMs will grow to be much more succesful and versatile, driving innovation throughout an excellent wider vary of industries.
The technical content material offered on this article was reviewed by Necati Demir.