

{kind=link}
Data graphs (KGs) are the muse of synthetic intelligence functions however are incomplete and sparse, affecting their effectiveness. Nicely-established KGs resembling DBpedia and Wikidata lack important entity relationships, diminishing their utility in retrieval-augmented era (RAG) and different machine-learning duties. Conventional extraction strategies are probably to supply sparse graphs with absent vital connections or noisy, redundant representations. Subsequently it’s troublesome to acquire high-quality structured data from unstructured textual content. Overcoming these challenges is essential to allow improved data retrieval, reasoning, and insights with the assistance of synthetic intelligence.
State-of-the-art strategies for extracting KGs from uncooked textual content are Open Info Extraction (OpenIE) and GraphRAG. OpenIE, a dependency parsing method, produces structured (topic, relation, object) triples however produces extraordinarily complicated and redundant nodes, lowering coherence. GraphRAG, which mixes graph-based retrieval and language fashions, enhances entity linking however doesn’t produce densely related graphs, limiting downstream reasoning processes. Each methods are suffering from low entity decision consistency, sparsity in connectivity, and poor generalizability, rendering them ineffective for high-quality KG extraction.
Researchers from Stanford College, the College of Toronto, and FAR AI introduce KGGen, a novel text-to-KG generator that leverages language fashions and clustering algorithms to extract structured data from plain textual content. Not like earlier strategies, KGGen introduces an iterative LM-based clustering methodology that enhances the extracted graph by merging synonymous entities and grouping relations. This enhances sparsity and redundancy, providing a extra coherent and well-connected KG. KGGen additionally introduces MINE (Measure of Info in Nodes and Edges), the primary benchmark for text-to-KG extraction efficiency, enabling standardized measurement of extraction strategies.
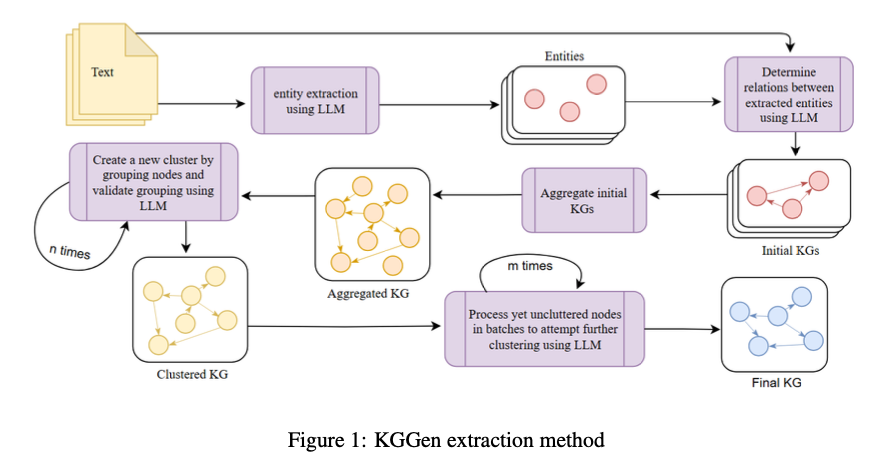
KGGen operates by means of a modular Python package deal with modules for entity and relation extraction, aggregation, and entity and edge clustering. The module for entity and relation extraction employs GPT-4o to acquire structured triples (topic, predicate, object) from unstructured textual content. The aggregation module combines extracted triples from completely different sources right into a unified data graph (KG), therefore guaranteeing a homogeneous illustration of entities. The module for entity and edge clustering makes use of an iterative clustering algorithm to disambiguate synonymous entities, cluster related edges, and improve graph connectivity. By way of the enforcement of strict constraints on the language mannequin utilizing DSPy, KGGen permits the attainment of structured and high-fidelity extractions. The output data graph is distinguished by its dense connectivity, semantic relevance, and optimization for synthetic intelligence functions.
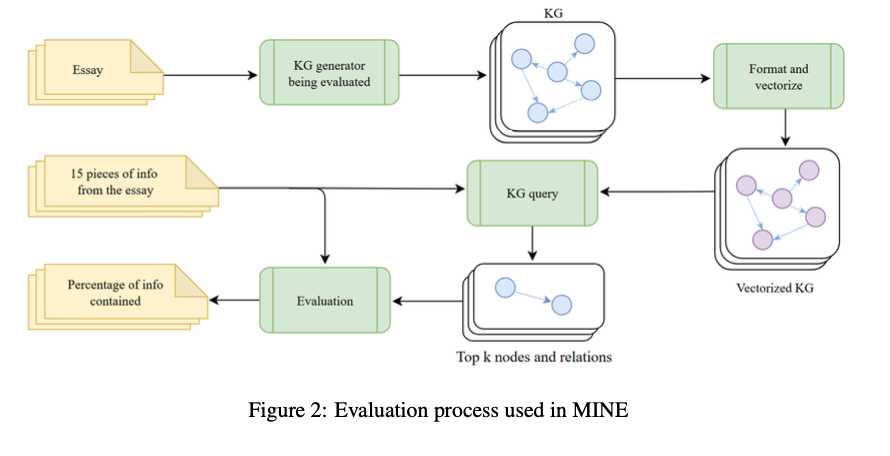
The benchmarking outcomes point out the success of the tactic in extracting structured data from textual content sources. KGGen will get an accuracy price of 66.07%, which is considerably better than GraphRAG at 47.80% and OpenIE at 29.84%. The system facilitates the potential to extract and construction data with out redundancy and enhancing connectivity and coherence. Comparative evaluation confirms an 18% enchancment in extraction constancy over current strategies, highlighting its functionality to generate well-structured data graphs. Checks additionally display that produced graphs are denser and extra informative, making them significantly appropriate within the context of information retrieval duties and AI-based reasoning.
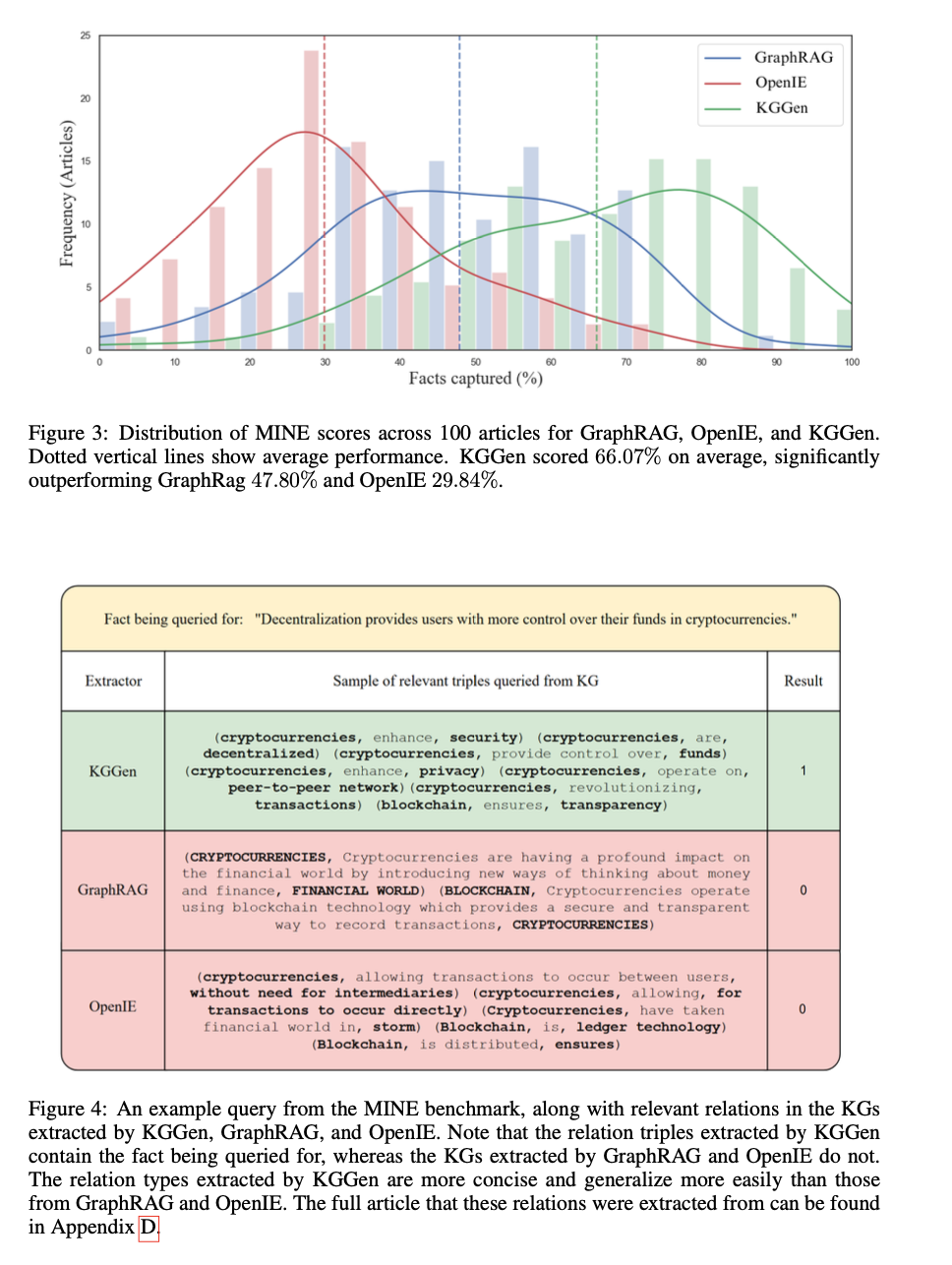
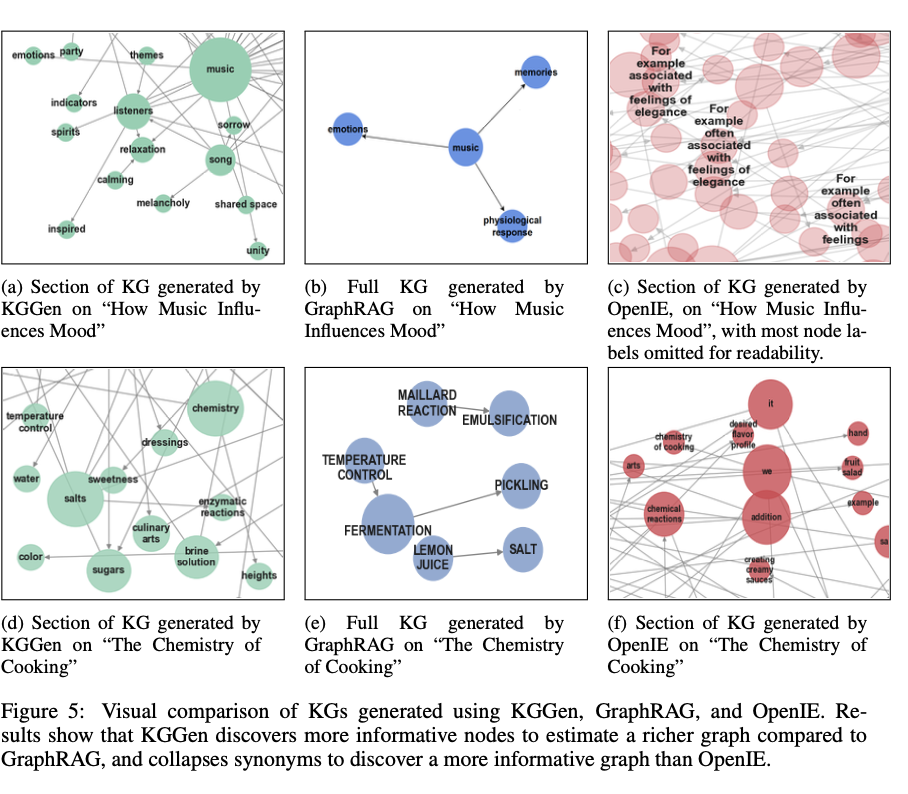
KGGen is a breakthrough within the discipline of information graph extraction as a result of it pairs language model-based entity recognition with iterative clustering methods to generate higher-quality structured knowledge. By reaching radically improved accuracy on the MINE benchmark, it raises the bar for reworking unstructured textual content into impactful representations. This breakthrough has far-reaching implications for synthetic intelligence-driven data retrieval, reasoning operations, and embedding-based studying, thus paving the way in which for additional improvement of bigger and extra complete data graphs. Future improvement will concentrate on refining clustering methods and increasing benchmark checks to cowl bigger datasets.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 75k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.
