

{kind=link}
How lengthy must you practice your language mannequin? How giant ought to your mannequin be? In immediately’s generative AI panorama, these are multi-million greenback questions.
Over the previous few years, researchers have developed scaling legal guidelines, or empirical formulation for estimating probably the most environment friendly method to scale up the pretraining of language fashions. Nevertheless, common scaling legal guidelines solely think about coaching prices, and ignore the customarily extremely costly prices of deploying these fashions. Our latest paper, introduced at ICML 2024, proposes a modified scaling legislation to account for the price of each coaching and inference. This weblog submit explains the reasoning behind our new scaling legislation, after which experimentally demonstrates how “overtrained” LLMs might be optimum.
The “Chinchilla” Scaling Regulation is probably the most broadly cited scaling legislation for LLMs. The Chinchilla paper requested the query: When you’ve got a hard and fast coaching compute finances, how must you steadiness mannequin dimension and coaching period to supply the very best high quality mannequin? Coaching prices are decided by mannequin dimension (parameter rely) multiplied by knowledge dimension (variety of tokens). Bigger fashions are extra succesful than smaller ones, however coaching on extra knowledge additionally improves mannequin high quality. With a hard and fast compute finances, there’s a tradeoff between rising mannequin dimension vs. rising coaching period. The Chinchilla authors skilled tons of of fashions and reported an optimum token-to-parameter ratio (TPR) of roughly 20. This “Chinchilla optimum” worth of ~20 tokens/parameter shortly grew to become the business commonplace (for instance, later fashions reminiscent of Cerebras-GPT and Llama-1 65B have been skilled utilizing Chinchilla scaling).
As soon as the mannequin has accomplished coaching, it must be deployed. Since LLM serving prices are a perform of the mannequin dimension (along with person demand), bigger fashions are way more costly to deploy. Mannequin dimension is subsequently an essential price issue for each coaching and inference time.
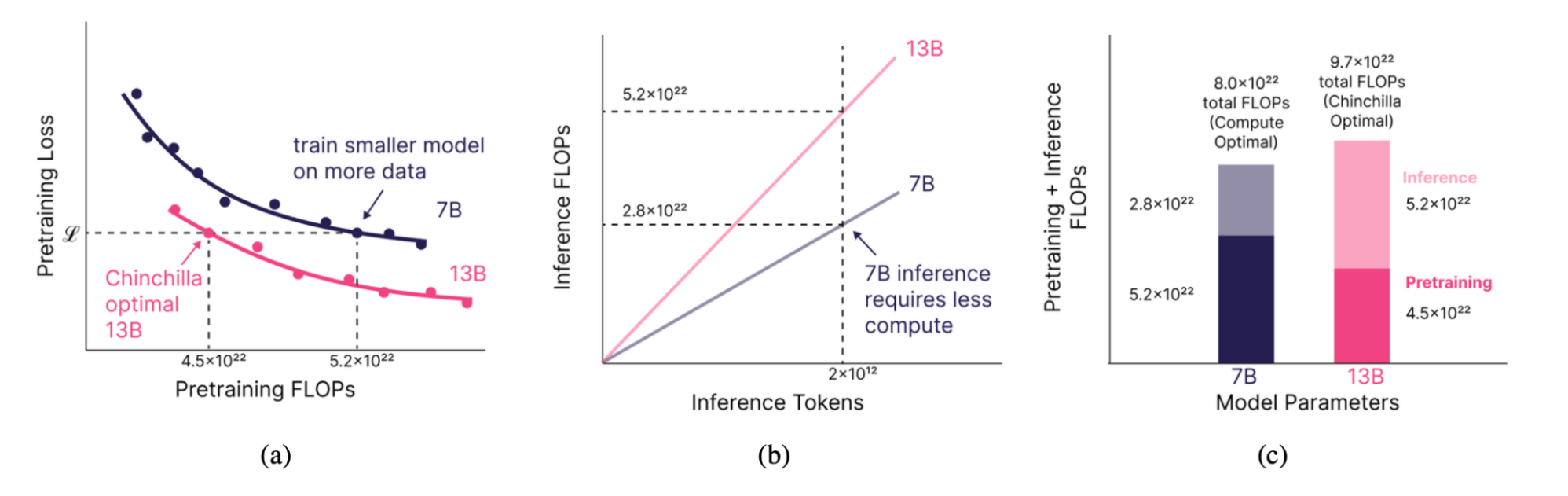
In our analysis, we have been motivated by the concept of coaching smaller fashions on extra knowledge than the Chinchilla legislation urged. By spending extra cash on coaching to supply a smaller however equivalently highly effective mannequin, we predicted that we might make up for these further coaching prices at inference time (Fig. 1). How a lot smaller? That depends upon simply how a lot inference demand we anticipate.
Our adjusted scaling legislation returns probably the most environment friendly method to practice and deploy a mannequin primarily based on desired high quality and anticipated inference demand. Our scaling legislation quantifies the training-inference trade-off, producing fashions which can be optimum over their whole lifetime.
The extra inference demand you count on out of your customers, the smaller and longer it’s best to practice your fashions. However can you actually match the standard of a giant mannequin with a smaller one skilled on way more knowledge? Some have postulated that there’s a important mannequin dimension beneath which it isn’t attainable to coach on any variety of tokens and match a Chinchilla-style mannequin.
To reply this query and validate our methodology, we skilled a sequence of 47 fashions of various sizes and coaching knowledge lengths. We discovered that mannequin high quality continues to enhance as we improve tokens per parameter to excessive ranges (as much as 10,000 tokens/parameter, or 100x longer than typical), though additional testing is required at excessive scales.
Since we first printed a model of this work in December 2023, it has turn out to be extra frequent to coach fashions for for much longer durations than the Chinchilla optimum ratio. That is exemplified by successive generations of LLaba fashions: whereas the Llama-1 65B mannequin launched in February 2023 was skilled with ~20 tokens/parameter (1.4 trillion tokens), Llama-2-70B was skilled for nearly 30 tokens/parameter (2 trillion), and Llama-3-70B was skilled for over 200 tokens/parameter (15 trillion)! This pattern is pushed partly by the wild reputation of highly effective, smaller fashions within the 1B – 70B parameter vary which can be simpler and cheaper to finetune and deploy.
The Particulars: How Scaling Legal guidelines Can Account for Each Coaching and Inference
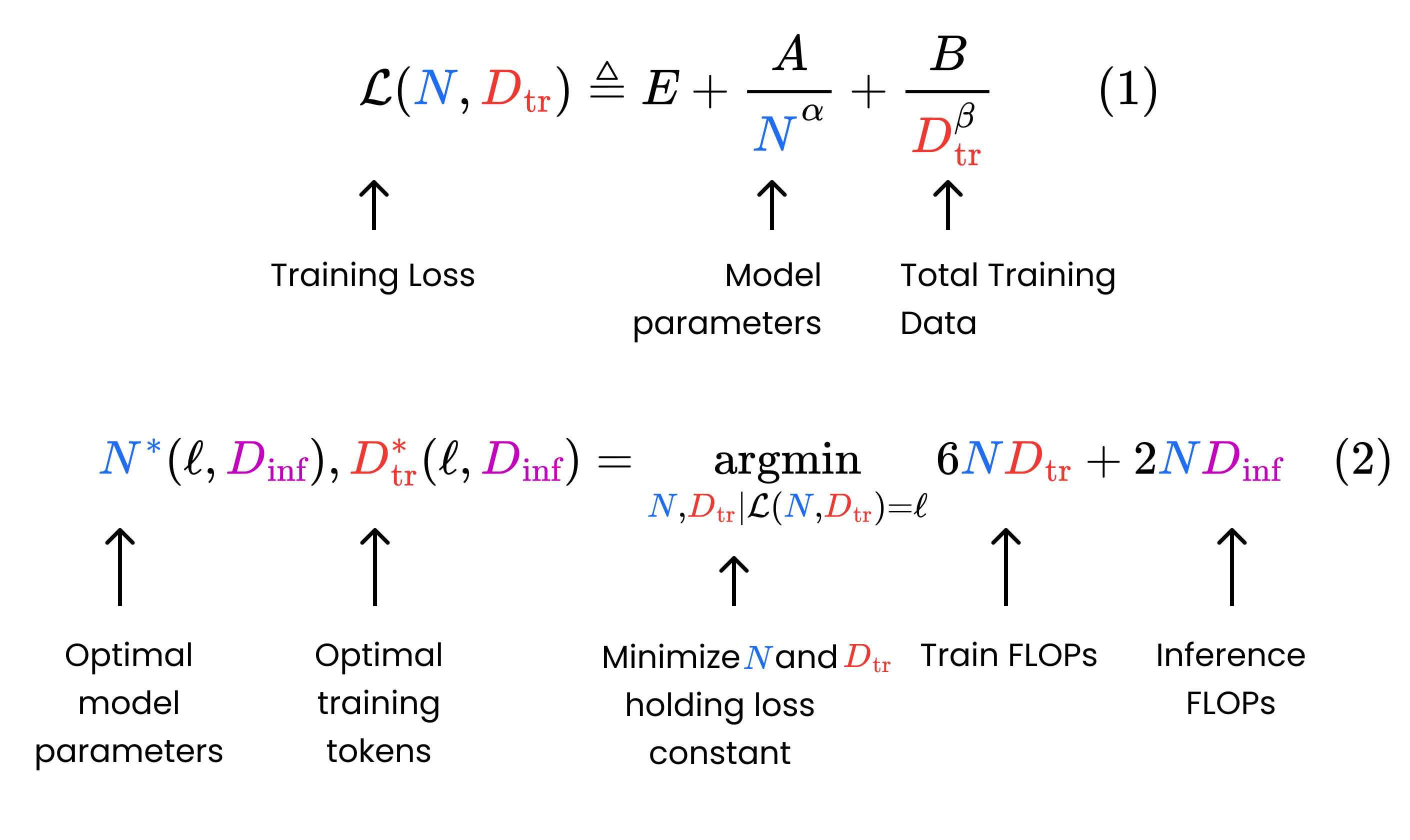
The Chinchilla paper introduced a parametric perform (Fig. 2, Eq. 1) for mannequin loss by way of the variety of mannequin parameters and coaching tokens. The authors skilled a big set of fashions to empirically discover the best-fit values for the coefficients in Equation 1. Then, they developed a formulation to decrease this perform (decrease loss = greater high quality mannequin) topic to a mounted coaching compute finances, the place compute is measured by way of floating-point operations (FLOPs).
Against this, we assume a mounted pretraining loss (i.e. mannequin high quality) and discover the mannequin dimension and coaching period that decrease the full compute over the mannequin’s lifetime, together with each coaching and inference (Fig. 2, Eq. 2).
We imagine our setup is extra intently aligned with how groups take into consideration growing LLMs for manufacturing. In follow, organizations care deeply about making certain their mannequin reaches a sure high quality. Provided that it hits their analysis metrics can they then deploy it to finish customers. Scaling legal guidelines are helpful inasmuch as they assist decrease the full price required to coach and serve fashions that meet these metrics.
For instance, suppose you’re seeking to practice and serve a 13B Chinchilla-quality mannequin, and also you anticipate 2 trillion tokens of inference demand over the mannequin’s lifetime. On this state of affairs, it’s best to as an alternative practice a 7B mannequin on 2.1x the coaching knowledge till it reaches 13B high quality, and serve this 7B mannequin as an alternative. This can scale back the compute required over your mannequin’s lifetime (coaching + inference) by 17% (Determine 1).
How Lengthy Can You Actually Practice?
In high-demand inference situations, our scaling legislation means that we should always practice considerably smaller fashions on way more knowledge than Chinchilla signifies, producing knowledge/mannequin ratios of tons of and even hundreds of tokens per parameter. Nevertheless, scaling legal guidelines haven’t been validated at these outer ranges. Most researchers conduct experiments solely at typical (<~100 tokens/parameter) ratios. Can fashions actually continue to learn should you practice them for that lengthy?
To characterize transformer conduct at excessive knowledge sizes, we skilled 47 LLMs with the MPT structure, with various dimension and token ratios. Our fashions ranged from 150M to 6B parameters, and our knowledge budgets ranged from 10 to 10,000 tokens per parameter. On account of useful resource constraints, we couldn’t full a full sweep for all mannequin sizes (e.g. we skilled our 2.5B mannequin on as much as 500 tokens/parameter).
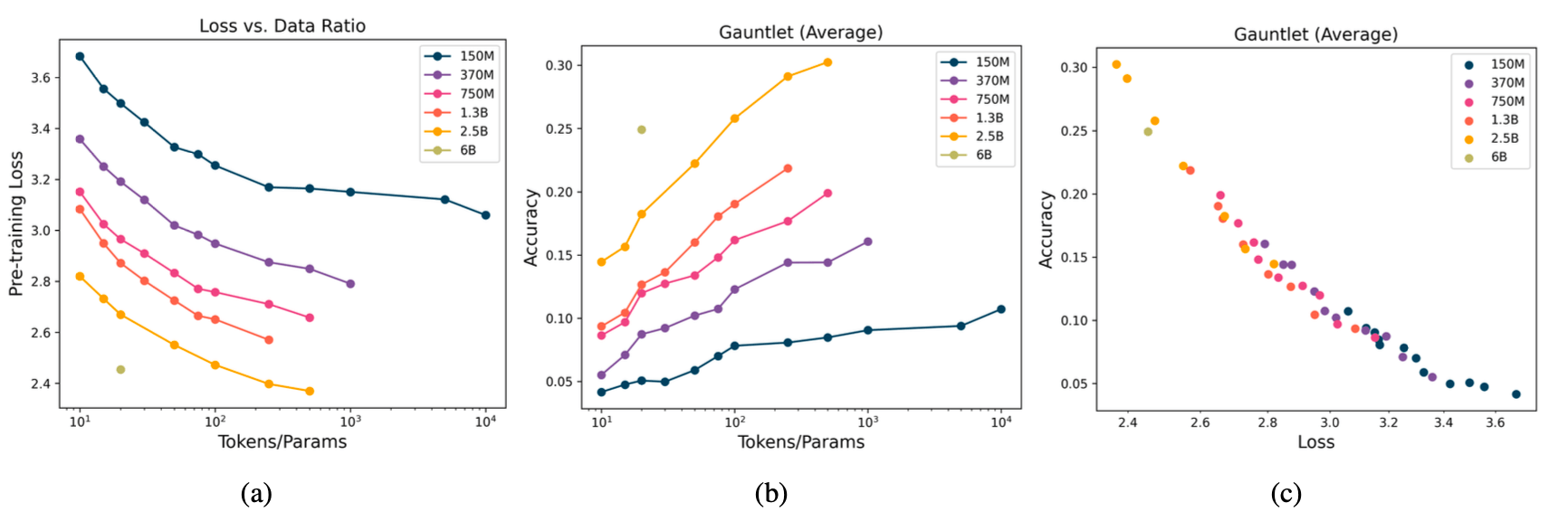
Our key experimental discovering is that loss continues to lower (i.e. mannequin high quality improves) as we improve tokens per parameter, even to excessive ratios. Though it takes exponentially extra tokens to scale back loss at giant ratios, loss doesn’t plateau as we scale to 10,000 tokens per parameter for our 150M mannequin. We discover no proof of a “saturation level” for LLMs, though additional testing is required at excessive scales.
Along with mannequin loss, we additionally thought of downstream metrics. We evaluated every mannequin on a model of our open supply Mosaic Analysis Gauntlet, which consists of 50-odd duties in 5 totally different classes: World Information (e.g. MMLU), Commonsense Reasoning (e.g. BIG-bench), studying comprehension (SQuAD), language understanding (e.g. LAMBADA), and symbolic drawback fixing (e.g. GSM-8k). Our downstream metrics additionally improved as we skilled longer and longer.
Loss and Gauntlet Common are tightly correlated (Fig 3(c)), displaying that enhancements in loss are wonderful predictors of enhancements basically mannequin high quality. LLM builders concerned with predicting downstream metrics as a perform of mannequin parameters and token counts can use loss as a proxy for his or her mixture outcomes and reap the benefits of current scaling legal guidelines to precisely perceive how their downstream metrics change at scale.
Estimating Actual-World Prices of Coaching and Inference
Up to now, our proposed scaling legislation purely optimizes for minimal whole (coaching + inference) FLOPs. Nevertheless, in follow, we care way more about minimizing prices quite than compute, and the price of a coaching FLOP is totally different from the price of an inference FLOP. Inference is run on totally different {hardware}, with totally different costs, and at totally different utilizations.
To make our methodology extra relevant to real-world deployments, we modified our goal in Fig. 2. As an alternative of minimizing FLOPs, we minimized price. To provide an excellent price estimate, we break up off coaching, prefill (processing prompts), and decoding (output technology) and estimated prices for every stage. Though our methodology simplifies how issues work in the true world, it’s versatile sufficient to account for various {hardware} sorts and utilization.
Adjusting our methodology from compute-optimal to cost-optimal can profoundly affect our suggestions. For instance, assuming lifelike numbers for coaching, immediate processing, and output technology, a Chinchilla-style 70B mannequin is just one% off the compute-optimal mannequin for a similar inference demand of two trillion tokens, however prices 36% greater than a cost-optimal mannequin.
Conclusion
Our analysis modifies scaling legal guidelines to account for the computational and real-world prices of each coaching and inference. As inference demand grows, the extra price pushes the optimum coaching setup towards smaller and longer-trained fashions.
We experimentally validated the speculation that very small fashions, skilled on sufficient knowledge, can match bigger ones skilled to their Chinchilla ratio (20x tokens/parameter). Our outcomes present that LLM practitioners working in inference-heavy regimes can (and sometimes ought to!) practice fashions significantly longer than the present literature suggests and proceed to see high quality enhancements.
Lastly, this work impressed our growth of DBRX, a Databricks Combination-of-Consultants mannequin with 132B whole parameters skilled for 12 trillion tokens. Wish to practice your individual fashions? Contact us! At Databricks Mosaic AI, we conduct LLM analysis like this so you possibly can practice high-quality, performant fashions extra effectively on our platform.
Occupied with growing language fashions and sharing insights about them? Be a part of Databricks Mosaic AI! We’ve got open engineering and analysis positions.
Notes and Additional Studying
This analysis was first printed in early kind in December 2023 on the NeurIPS 2023 Workshop on Environment friendly Pure Language and Speech Processing. It will likely be introduced in July 2024 on the Worldwide Convention on Machine Studying. The complete analysis paper could also be considered at this hyperlink: Past Chinchilla-Optimum: Accounting for Inference in Language Mannequin Scaling Legal guidelines.
Many research have contributed to the event of scaling legal guidelines for LLMs, together with Hestness et al. (2017; 2019), Rosenfeld et al. (2019), Henighan et al. (2020), Kaplan et al. (2020), Sorscher et al. (2022), and Caballero et al. (2022) (see Villalobos (2023) for a overview). A few of these research targeted on scaling legal guidelines for switch settings (i.e. downstream efficiency), reminiscent of Hernandez et al. (2021); Mikami et al. (2021); Abnar et al. (2021) and Tay et al. (2022).
A number of research reminiscent of Besiroglu et al. (2024) and Porian et al. (2024) have additionally additional scrutinized the parametric perform becoming strategy of the unique Chinchilla paper by Hoffman et al. 2022.
A handful of thrilling scaling legislation papers have been printed since 2023, when an earlier model of this work was introduced (Sardana and Frankle 2023). For instance, Krajewski et al. (2024) characterize variations in scaling properties between dense transformers and Combination of Knowledgeable (MoE) fashions. Extra theoretical research embrace Michaud et al. (2024), Bordelon et al. (2024), Paquette et al. (2024) and Ruan et al. (2024).
The outcomes introduced in Gadre et al. (2024) are significantly related to this paper. The authors practice 100 fashions between the sizes of 1.4B and 6.9B parameters and on knowledge with tokens-per-parameter ratios between 20 and 640. Just like our examine, they discover dependable scaling legal guidelines in these mannequin and knowledge regimes. Additionally they discover that downstream job efficiency is strongly correlated to LLM perplexity.