

{kind=link}
Understanding the 3D house is a key problem in AI. This lies on the border of robotic and agent interplay with the bodily world. People can simply determine and relate to things, depth, and have an inherent understanding of physics in a lot of the instances. That is usually termed as embodied reasoning. And to know the world like people AI should develop this functionality to have the ability to infer a 3D construction of the atmosphere, determine objects, and plan actions.
Google’s Gemini fashions at the moment are on the frontier of this newly realized skill. They’re studying to “see” in 3D and may bodily level to objects and plan spatially in a fashion {that a} human would. On this article we’ll discover how LLM’s like Gemini perceive the 3D world and dive into the completely different viewpoints of spatial understanding to display how Gemini’s have a human-like high quality of notion.
Foundations of 3D Spatial Understanding
3D spatial understanding is the power to acknowledge info from the bodily sensors. To take action, the mannequin has to motive about depth, object places, and orientations, different than simply recognizing the educational spatial relations. Studying 3D spatial relations usually requires using geometric ideas, similar to projecting 3D factors onto a 2D image, with protecting in thoughts of depth, similar to shading, strains of perspective, and occlusion.
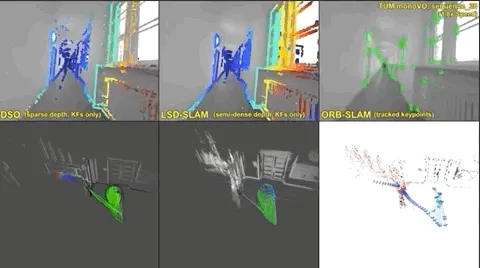
The classical strategy in robotics would possibly use stereo-vision or LiDAR to recuperate a 3D scene. For this there lies a complicated methodology known as the SLAM methodology which helps to seek out the 3D relations. Nonetheless, fashionable AI merely learns to immediately predict the 3D relationship from the information itself. And the Gemini is educated on large-scale coaching knowledge due to this fact, it sees tens of millions of pairs of photos and captions, and this helps it assigning language to visible options.
Moreover, the LLM’s can detect bounding packing containers by way of the prompts or open-ended textual content. It distinguishes itself by use of its illustration house, and treats coordinates as tokens in its output, and extra importantly, Gemini 2.0 was designed as an embodied mannequin. It must implicitly be taught to affiliate the pixels within the projected picture, the language, and the spatial ideas collectively.
Core Foundational Components
Gemini makes use of a type of spatial intelligence that features a number of essential ideas. These ideas collectively join pixels, or realized representations of the visible subject, to the spatial world. These consists of:
- Projection & geometry: The AI makes use of its understanding of a 3D-to-2D projection. It learns to determine the everyday shapes of objects as a part of its coaching. It additionally learns how perspective impacts the foreshortening of these shapes.
- Multi-view cues: Viewing the identical object from a number of views helps triangulate depth. Gemini can soak up quite a lot of photos of the identical scene. It could then use completely different views and angles when it generates 3D reasoning.
- Express coordinates: The mannequin can produce express coordinates. It immediately represents 2D factors as a [y, x] pair. It outputs 3D packing containers as a [x, y, z, w, h, d, roll, pitch, yaw] meter-based illustration. This lends itself to downstream programs with the ability to entry and use the output immediately.
- Language grounding: It hyperlinks spatial perceptions to semantic meanings. It solutions questions in regards to the picture in phrases and structured knowledge. As an illustration, it may well acknowledge “left of the pan” and level to the suitable space.
This combine is the inspiration of the Gemini’s spatial intelligence. The mannequin learns to motive about scenes in potential meanings of objects and coordinate programs. That is fairly just like how a human might signify a scene with factors and packing containers.
How Gemini Sees the 3D World
Gemini’s imaginative and prescient expertise prolong past that of a typical picture classifier. At its core, Gemini can detect and localize objects in photos when requested. For instance, you may ask Gemini to “detect all kitchen objects on this picture” and it’ll present an inventory of bounding packing containers and labels.
This detection is open vocabulary. This implies the mannequin isn’t restricted to a set set of classes and can discover objects described within the immediate. One time, the immediate requested Gemini to “detect the spill and what can be utilized to wash it up.” It was in a position to precisely detect the liquid spill in addition to the towel that was close by, although neither object was explicitly referred to within the immediate. This demonstrates how its visible ‘seeing’ is deeply linked to semantics.
However Gemini goes even additional! It could infer 3D info contained in 2D photos.
For instance, given two views of the identical scene, Gemini can match corresponding factors, reaching a sort of tough 3D correspondence, given each views. It was in a position to detect {that a} pink marker on a countertop in a single view was the identical pink marker on the desk within the different view.
How Gemini Detects Objects with 3D Bounding Packing containers
This functionality of 3D entry is accessible by means of the API. A developer can request structured 3D knowledge. Within the instance beneath (constructed on prime of Google’s Gemini Cookbook), a developer asks Gemini to “present these packing containers.”
from google.colab import userdata
GOOGLE_API_KEY=userdata.get('GOOGLE_API_KEY')
from google import genai
from google.genai import varieties
from PIL import Picture
# Load pattern photos
!wget https://storage.googleapis.com/generativeai-downloads/photos/kitchen.jpg -O kitchen.jpg -q
# Loading the API
shopper = genai.Shopper(api_key=GOOGLE_API_KEY)
# Load the chosen picture
img = Picture.open("kitchen.jpg")
# Analyze the picture utilizing Gemini
image_response = shopper.fashions.generate_content(
mannequin=MODEL_ID,
contents=[
img,
"""
Detect the 3D bounding boxes of no more than 10 items.
Output a json list where each entry contains the object name in "label" and its 3D bounding box in "box_3d"
The 3D bounding box format should be [x_center, y_center, z_center, x_size, y_size, z_size, roll, pitch, yaw].
"""
],
config = varieties.GenerateContentConfig(
temperature=0.5
)
)
# Verify response
print(image_response.textual content)Output:
[{"label": "oven", "box_3d": [-0.14,3.74,-0.71,0.76,0.59,1.08,0,0,0]},
{"label": "sink", "box_3d": [-1.07,2.09,-0.34,0.18,0.47,0.12,0,0,-6]},
{"label": "toaster", "box_3d": [-0.94,3.84,-0.18,0.27,0.16,0.2,0,0,1]},
{"label": "microwave", "box_3d": [1.01,3.8,-0.2,0.43,0.31,0.26,0,0,2]},
{"label": "espresso maker", "box_3d": [0.7,3.78,-0.18,0.2,0.32,0.3,0,0,53]},
{"label": "knife block", "box_3d": [-0.89,3.74,-0.22,0.1,0.25,0.21,0,0,-53]},
{"label": "vary hood", "box_3d": [-0.02,3.87,0.72,0.76,0.47,0.48,0,0,-1]},
{"label": "kitchen counter", "box_3d": [-0.93,2.58,-0.77,0.59,2.65,1.01,0,0,0]},
{"label": "kitchen counter", "box_3d": [0.66,1.73,-0.76,0.6,1.48,1.01,0,0,0]},
{"label": "kitchen cupboard", "box_3d": [0.95,1.69,0.77,0.33,0.72,0.71,0,0,0]}
Now the Gemini has identified the precise bounding field factors, now we’ll create an html script that can create 3D bounding packing containers over the issues detected by Gemini.
import base64
from io import BytesIO
def parse_json(json_output):
strains = json_output.splitlines()
for i, line in enumerate(strains):
if line == "```
json_output = "n".be part of(strains[i+1:])
json_output = json_output.break up("```")[0]
break
return json_output
def generate_3d_box_html(pil_image, boxes_json):
img_buf = BytesIO()
pil_image.save(img_buf, format="PNG")
img_str = base64.b64encode(img_buf.getvalue()).decode()
boxes_json = parse_json(boxes_json)
return f"""
<html>
<head>
<model>
physique {{ font-family: sans-serif; }}
#container {{ place:relative; }}
canvas {{ background:#000; }}
.box-label {{ place:absolute; coloration:#fff; background:#2962FF; padding:2px 6px; border-radius:3px; font-size:12px; remodel:translate(-50%,-50%); pointer-events:auto; }}
.box-line {{ place:absolute; background:#2962FF; peak:2px; }}
</model>
</head>
<physique>
<div id="container">
<canvas id="canvas" width="500" peak="400"></canvas>
<div id="overlay"></div>
</div>
<script>
let packing containers={boxes_json};
const canvas=doc.getElementById('canvas');
const ctx=canvas.getContext('2nd');
const overlay=doc.getElementById('overlay');
let img=new Picture();
img.onload=()=>{{
ctx.drawImage(img,0,0,canvas.width,canvas.peak);
overlay.innerHTML='';
packing containers.forEach(field=>{
let x=field.box_3d[0]*30+250;
let y=field.box_3d[1]*-30+200;
let w=field.box_3d[3]*30;
let h=field.box_3d[4]*30;
let label=doc.createElement('div');
label.className="box-label";
label.textContent=field.label;
label.model.left=`${{x}}px`;
label.model.prime=`${{y}}px`;
overlay.appendChild(label);
let line=doc.createElement('div');
line.className="box-line";
line.model.left=`${{x-w/2}}px`;
line.model.prime=`${{y-h/2}}px`;
line.model.width=`${{w}}px`;
overlay.appendChild(line);
});
}};
img.src="knowledge:picture/png;base64,{img_str}";
</script>
</physique>
</html>
"""Output:
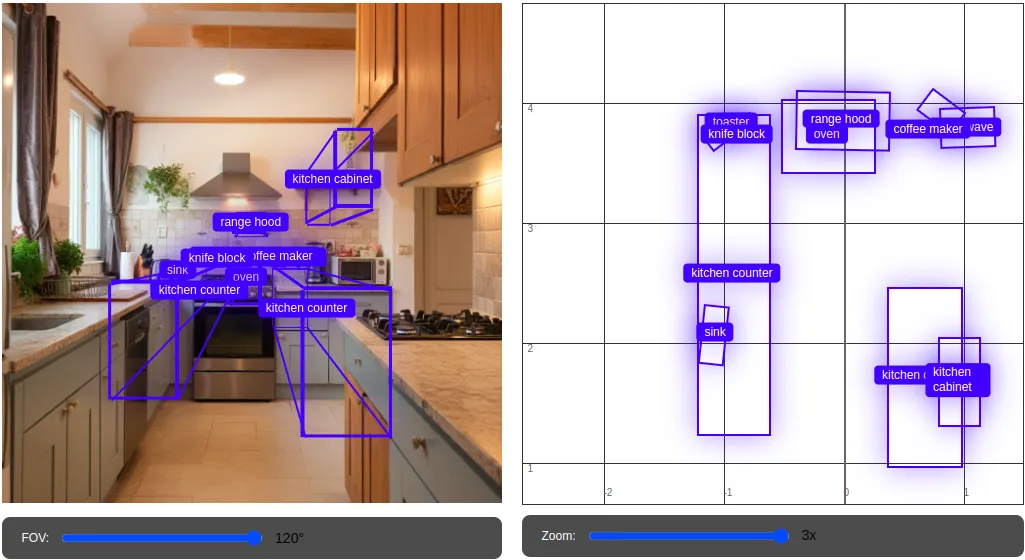
As you may see right here, Gemini goes even additional, it may well infer 3D info contained in 2D photos. For instance, given two views of the identical scene, Gemini can match corresponding factors, reaching a sort of tough 3D correspondence, given each views. It was in a position to detect the kitchen home equipment. Furthermore, you may even play with the sliding bars to zoom in or zoom out or hover the cursor over the field to visualise the detection in additional element.
How Gemini Factors: Interacting with Objects
Together with passive detection, Gemini may also actively level to things. Should you present Gemini with a picture and an accompanying immediate, it would return coordinates as output. This may produce an inventory of 2D factors, normalized to a grid with dimensions of 1000×1000. You possibly can instruct the mannequin to “level to all objects which might be pink.” Different choices can be to point a location like “level to the place you’d grasp the software.” Within the latter case, the mannequin will return a JSON record of factors and labels. The returned output is usually extra versatile than bounding packing containers.
For instance, after we requested the mannequin to discover a grasp level on a mug, it was in a position to appropriately level to the deal with for the grasp level. Gemini would be capable of point out spatial areas as properly. As an illustration, for two-dimensional areas, it might discover… “empty spot” or a “protected space to step”
Code Instance: 2D Pointing
from google.colab import userdata
GOOGLE_API_KEY=userdata.get('GOOGLE_API_KEY')
from google import genai
from google.genai import varieties
from PIL import Picture
# Load pattern photos
!wget https://storage.googleapis.com/generativeai-downloads/photos/kitchen.jpg -O kitchen.jpg -q
# Loading the API
shopper = genai.Shopper(api_key=GOOGLE_API_KEY)
# Load the chosen picture
img = Picture.open("room.jpg")
# Load and resize picture
img = Picture.open("software.png")
img = img.resize((800, int(800 * img.dimension[1] / img.dimension[0])), Picture.Resampling.LANCZOS) # Resizing to speed-up rendering
# Analyze the picture utilizing Gemini
image_response = shopper.fashions.generate_content(
mannequin=MODEL_ID,
contents=[
img,
"""
Point to no more than 10 items in the image, include spill.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...]. The factors are in [y, x] format normalized to 0-1000.
"""
],
config = varieties.GenerateContentConfig(
temperature=0.5
)
)
# Verify response
print(image_response.textual content)Output:
[[
{"point": [130, 760], "label": "deal with"},
{"level": [427, 517], "label": "screw"},
{"level": [472, 201], "label": "clamp arm"},
{"level": [466, 345], "label": "clamp arm"},
{"level": [685, 312], "label": "3 inch"},
{"level": [493, 659], "label": "screw"},
{"level": [402, 474], "label": "screw"},
{"level": [437, 664], "label": "screw"},
{"level": [427, 784], "label": "deal with"},
{"level": [452, 852], "label": "deal with"}
]
Gemini’s pointing operate can also be outlined as open vocabulary which means a consumer can consult with an object or components of an object in a pure language. Gemini was profitable in pointing to buttons and handles (components of objects) with out fashions being educated on these particular objects and within the HTML script we’ll use the Level detected by way of Gemini and pin level all of the objects detected by it.
# @title Level visualization code
import IPython
def parse_json(json_output):
# Parsing out the markdown fencing
strains = json_output.splitlines()
for i, line in enumerate(strains):
if line == "```json":
json_output = "n".be part of(strains[i+1:]) # Take away every little thing earlier than "```json"
json_output = json_output.break up("```")[0] # Take away every little thing after the closing "```"
break # Exit the loop as soon as "```json" is discovered
return json_output
def generate_point_html(pil_image, points_json):
# Convert PIL picture to base64 string
import base64
from io import BytesIO
buffered = BytesIO()
pil_image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
points_json = parse_json(points_json)
return f"""
<!DOCTYPE html>
<html>
<head>
<title>Level Visualization</title>
<model>
physique {{
margin: 0;
padding: 0;
background: #fff;
coloration: #000;
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, sans-serif;
}}
.point-overlay {{
place: absolute;
prime: 0;
left: 0;
width: 100%;
peak: 100%;
pointer-events: none;
}}
.level {{
place: absolute;
width: 12px;
peak: 12px;
background-color: #2962FF;
border: 2px stable #fff;
border-radius: 50%;
remodel: translate(-50%, -50%);
box-shadow: 0 0 40px rgba(41, 98, 255, 0.6);
opacity: 0;
transition: all 0.3s ease-in;
pointer-events: auto;
}}
.level.seen {{
opacity: 1;
}}
.level.fade-out {{
animation: pointFadeOut 0.3s forwards;
}}
.level.spotlight {{
remodel: translate(-50%, -50%) scale(1.1);
background-color: #FF4081;
box-shadow: 0 0 40px rgba(255, 64, 129, 0.6);
z-index: 100;
}}
@keyframes pointFadeOut {{
from {{
opacity: 1;
}}
to {{
opacity: 0.7;
}}
}}
.point-label {{
place: absolute;
background-color: #2962FF;
coloration: #fff;
font-size: 14px;
padding: 4px 12px;
border-radius: 4px;
remodel: translate(20px, -10px);
white-space: nowrap;
opacity: 0;
transition: all 0.3s ease-in;
box-shadow: 0 0 30px rgba(41, 98, 255, 0.4);
pointer-events: auto;
cursor: pointer;
}}
.point-label.seen {{
opacity: 1;
}}
.point-label.fade-out {{
opacity: 0.45;
}}
.point-label.spotlight {{
background-color: #FF4081;
box-shadow: 0 0 30px rgba(255, 64, 129, 0.4);
remodel: translate(20px, -10px) scale(1.1);
z-index: 100;
}}
</model>
</head>
<physique>
<div id="container" model="place: relative;">
<canvas id="canvas" model="background: #000;"></canvas>
<div id="pointOverlay" class="point-overlay"></div>
</div>
<script>
operate annotatePoints(body) {{
// Add factors with fade impact
const pointsData = {points_json};
const pointOverlay = doc.getElementById('pointOverlay');
pointOverlay.innerHTML = '';
const factors = [];
const labels = [];
pointsData.forEach(pointData => {{
// Skip entries with out coodinates.
if (!(pointData.hasOwnProperty("level")))
return;
const level = doc.createElement('div');
level.className="level";
const [y, x] = pointData.level;
level.model.left = `${{x/1000.0 * 100.0}}%`;
level.model.prime = `${{y/1000.0 * 100.0}}%`;
const pointLabel = doc.createElement('div');
pointLabel.className="point-label";
pointLabel.textContent = pointData.label;
level.appendChild(pointLabel);
pointOverlay.appendChild(level);
factors.push(level);
labels.push(pointLabel);
setTimeout(() => {{
level.classList.add('seen');
pointLabel.classList.add('seen');
}}, 0);
// Add hover results
const handleMouseEnter = () => {{
// Spotlight present level and label
level.classList.add('spotlight');
pointLabel.classList.add('spotlight');
// Fade out different factors and labels
factors.forEach((p, idx) => {{
if (p !== level) {{
p.classList.add('fade-out');
labels[idx].classList.add('fade-out');
}}
}});
}};
const handleMouseLeave = () => {{
// Take away spotlight from present level and label
level.classList.take away('spotlight');
pointLabel.classList.take away('spotlight');
// Restore different factors and labels
factors.forEach((p, idx) => {{
p.classList.take away('fade-out');
labels[idx].classList.take away('fade-out');
}});
}};
level.addEventListener('mouseenter', handleMouseEnter);
level.addEventListener('mouseleave', handleMouseLeave);
pointLabel.addEventListener('mouseenter', handleMouseEnter);
pointLabel.addEventListener('mouseleave', handleMouseLeave);
}});
}}
// Initialize canvas
const canvas = doc.getElementById('canvas');
const ctx = canvas.getContext('2nd');
const container = doc.getElementById('container');
// Load and draw the picture
const img = new Picture();
img.onload = () => {{
const aspectRatio = img.peak / img.width;
canvas.width = 800;
canvas.peak = Math.spherical(800 * aspectRatio);
container.model.width = canvas.width + 'px';
container.model.peak = canvas.peak + 'px';
ctx.drawImage(img, 0, 0, canvas.width, canvas.peak);
body.width = canvas.width;
body.peak = canvas.peak;
annotatePoints(body);
}};
img.src="knowledge:picture/png;base64,{img_str}";
const body = {{
width: canvas.width,
peak: canvas.peak
}};
annotatePoints(body);
</script>
</physique>
</html>
"""
This above script will create an HTML rendering of the picture and the factors.

Key Pointing Capabilities
This functionality for pointing doesn’t cease at easy objects. Additionally it is able to comprehending operate, pathways, and complicated consumer intent.
- Open-vocabulary factors: The Gemini system can level to something described by means of language. It could label a spoon deal with and the middle of a can upon request.
- Affordance inference: The mannequin can infer operate. For instance, it would level to the deal with of a pan or to a protected location to seize.
- Trajectory hints: It could even output sequences of factors as a path. In describing waypoints, it lists a number of places that fall between a beginning and ending purpose. In the identical instance it output a brand new path from a human hand to some software.
- Benchmark efficiency: When evaluated on pointing benchmarks, Gemini 2.0 carried out considerably higher than different fashions similar to GPT-4 Imaginative and prescient. In a benchmark instance the specialised mannequin Robotics-ER outperformed even a devoted pointing AI by means of numerous measures.
Pointing is linked to motion. Ex. In a robotic that’s knowledgeable by Gemini, it may well localize the fruit merchandise and decide grasp factors. Thus, the AI will level to the fruit merchandise and compute a grasp location that’s above it. Thus, Gemini permits robots to bodily motive and act. In abstract, it’s to level to a goal and plan methods to attain and safe that concentrate on.
How Gemini Causes: Spatial Planning & Embodied Intelligence
Gemini’s spatial reasoning talent manifests in real embodied reasoning. It shifts from perceiving to planning actions. Given a purpose, Gemini can plan actions with multi-step sequences. It is ready to ‘think about’ methods to transfer.
For instance, It could plan the place to know a mug and methods to strategy the mug. Google states, Gemini “intuitively figures out an acceptable two-finger grasp… and a protected trajectory.” This means it understands the 3D pose of the mug, the place the deal with can be, and the place to maneuver towards.
Furthermore, Gemini can seize ‘complete management pipelines.’ In trials, Gemini Robotics-ER did every little thing from notion to code. It took an image, detected objects, estimated states, reasoned about methods to transfer and made executable robotic code. DeepMind mentioned that it “performs all the mandatory steps” even when the robotic system is powered on. This might enable for an general doubling or tripling of process success charges.
Conclusion
Present AI is growing a stage of situational consciousness which was beforehand solely restricted to people. Google’s Gemini fashions exemplify such development with watershed developments whereas seeing house three-dimensionally, figuring out objects, and desirous about actions. By merging imaginative and prescient and language, Gemini fashions can postulate in regards to the object and estimate its location, reply to grammar, and write code for robots to behave on the data.
Whereas we’re nonetheless going through challenges associated to precision and experimental options, the Gemini fashions signify a big development in AI. This mannequin designs AI to behave extra like a human navigating the world. We understand house, motive about house, and use that info to tell motion. Because the expertise matures, we will anticipate extra parts of the mannequin to narrate to spatial reasoning, a step ahead in the direction of helpful robots and AR programs.
Often Requested Questions
A. It learns from large paired picture–textual content knowledge, multi-view cues, and geometric patterns so it may well infer depth, orientation, and object structure immediately from 2D photos.
A. It returns open-vocabulary coordinates for objects or components, infers affordances like grasp factors, and may define paths or protected areas for real-world interplay.
A. It could detect objects, infer 3D poses, select grasp factors, and generate step-by-step motion plans, permitting robots to maneuver and act with extra human-like reasoning.
Howdy! I am Vipin, a passionate knowledge science and machine studying fanatic with a powerful basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My purpose is to use data-driven insights to create sensible options that drive outcomes. I am desperate to contribute my expertise in a collaborative atmosphere whereas persevering with to be taught and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.