

{kind=link}
RAG has develop into a preferred know-how in 2025, it avoids the fine-tuning of the mannequin which is dear in addition to time-consuming. There’s an elevated demand for RAG frameworks within the present state of affairs, Lets Perceive what are these. Retrieval-augmented era (RAG) frameworks are important instruments within the subject of synthetic intelligence. They improve the capabilities of Giant Language Fashions (LLMs) by permitting them to retrieve related info from exterior sources. This results in extra correct and context-aware responses. Right here, we’ll discover 5 notable RAG frameworks: LangChain, LlamaIndex, LangGraph, Haystack, and RAGFlow. Every framework gives distinctive options that may enhance your AI tasks.
1. LangChain
LangChain is a versatile framework that simplifies the event of purposes utilizing LLMs. It offers instruments for constructing RAG purposes, making integration simple.
- Key Options:
- Modular design for straightforward customization.
- Helps varied LLMs and information sources.
- Constructed-in instruments for doc retrieval and processing.
- Appropriate for chatbots and digital assistants.
Right here’s the hands-on:
Set up the next libraries
! pip set up langchain_community tiktoken langchain-openai langchainhub chromadb langchainArrange OpenAI API key and os surroundings
from getpass import getpass
openai = getpass("OpenAI API Key:")
import os
os.environ["OPENAI_API_KEY"] = openaiImport the next dependencies
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddingsLoading the doc for RAG utilizing WebBase Loader (exchange with your personal Knowledge)
# Load Paperwork
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()Chunking the doc utilizing RecursiveCharacterTextSplitter
# Break up
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)Storing the vector paperwork in ChromaDB
# Embed
vectorstore = Chroma.from_documents(paperwork=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()Pulling the RAG immediate from the LangChain hub and defining LLM
# Immediate
immediate = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)Processing the retrieved docs
# Submit-processing
def format_docs(docs):
return "nn".be a part of(doc.page_content for doc in docs)Creating the RAG chain
# Chain
rag_chain = (
format_docs, "query": RunnablePassthrough()
| immediate
| llm
| StrOutputParser()Invoking the chain with the query
# Query
rag_chain.invoke("What's Activity Decomposition?")Output
‘Activity Decomposition is a way used to interrupt down advanced duties into
smaller and easier steps. This method helps brokers to plan forward and
deal with tough duties extra successfully. Activity decomposition will be achieved
by varied strategies, together with utilizing prompting methods, task-specific
directions, or human inputs.’
Additionally Learn: Discover all the things about LangChain Right here.
2. LlamaIndex
LlamaIndex, beforehand referred to as the GPT Index, focuses on organizing and retrieving information effectively for LLM purposes. It helps builders entry and use massive datasets rapidly.
- Key Options:
Right here’s the hands-on:
Set up the next dependencies
!pip set up llama-index llama-index-readers-file
!pip set up llama-index-embeddings-openai
!pip set up llama-index-llms-openaiImport the next dependencies and initialize the LLM and embeddings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
llm = OpenAI(mannequin="gpt-4o")
embed_model = OpenAIEmbedding()
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_modelObtain the info (You’ll be able to exchange it along with your information)
!wget 'https://uncooked.githubusercontent.com/run-llama/llama_index/essential/docs/docs/examples/information/10k/uber_2021.pdf' -O './uber_2021.pdf'Learn the info utilizing SimpleDirectoryReader
from llama_index.core import SimpleDirectoryReader
paperwork = SimpleDirectoryReader(input_files=["/content/uber_2021.pdf"]).load_data()Chunking the doc utilizing TokenTextSplitter
from llama_index.core.node_parser import TokenTextSplitter
splitter = TokenTextSplitter(
chunk_size=512,
chunk_overlap=0,
)
nodes = splitter.get_nodes_from_documents(paperwork)Storing the vector embeddings in VectorStoreIndex
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex(nodes)
query_engine = index.as_query_engine(similarity_top_k=2)
Invoking the LLM utilizing RAG
response = query_engine.question("What's the income of Uber in 2021?")
print(response)Output
‘The income of Uber in 2021 was $171.7 million.
3. LangGraph
LangGraph connects LLMs with graph-based information buildings. This framework is helpful for purposes that require advanced information relationships.
- Key Options:
- Effectively retrieves information from graph buildings.
- Combines LLMs with graph information for higher context.
- Permits customization of the retrieval course of.
Code
Set up the next dependencies
%pip set up --quiet --upgrade langchain-text-splitters langchain-community langgraph langchain-openaiInitialise the mannequin, embeddings and Vector database
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(mannequin="text-embedding-3-large")
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)Import the next dependencies
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.paperwork import Doc
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import Listing, TypedDictObtain the dataset utilizing WebBaseLoader(exchange it with your personal dataset)
# Load and chunk contents of the weblog
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()Chunking of the doc utilizing RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Index chunks
_ = vector_store.add_documents(paperwork=all_splits)# Outline immediate for question-answering
immediate = hub.pull("rlm/rag-prompt")
Defining the State, Nodes and edges in Langgraph
Outline state for utility
class State(TypedDict):
query: str
context: Listing[Document]
reply: str
# Outline utility steps
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "nn".be a part of(doc.page_content for doc in state["context"])
messages = immediate.invoke({"query": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"reply": response.content material}Compiling the Graph
# Compile utility and take a look at
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()Invoking the LLM for RAG
response = graph.invoke({"query": "What's Activity Decomposition?"})
print(response["answer"])Output
Activity Decomposition is the method of breaking down an advanced activity into
smaller, manageable steps. This may be achieved utilizing methods like Chain
of Thought (CoT) or Tree of Ideas, which information fashions to purpose step by
step or consider a number of prospects. The aim is to simplify advanced
duties and improve understanding of the reasoning course of.
4. Haystack
Haystack is an end-to-end framework for growing purposes powered by LLMs and transformer fashions. It excels in doc search and query answering.
- Key Options:
- Combines doc search with LLM capabilities.
- Makes use of varied retrieval strategies for optimum outcomes.
- Gives pre-built pipelines for fast improvement.
- Appropriate with Elasticsearch and OpenSearch.
Right here’s the hands-on:
Set up the next Dependencies
!pip set up haystack-ai
!pip set up "datasets>=2.6.1"
!pip set up "sentence-transformers>=3.0.0"
Import the VectorStore and initialise it
from haystack.document_stores.in_memory import InMemoryDocumentStore
document_store = InMemoryDocumentStore()Loading the inbuilt dataset from the dataset library
from datasets import load_dataset
from haystack import Doc
dataset = load_dataset("bilgeyucel/seven-wonders", break up="practice")
docs = [Document(content=doc["content"], meta=doc["meta"]) for doc in dataset]Downloading the Embedding mannequin (you may exchange it with OpenAI embeddings additionally)
from haystack.elements.embedders import SentenceTransformersDocumentEmbedder
doc_embedder = SentenceTransformersDocumentEmbedder(mannequin="sentence-transformers/all-MiniLM-L6-v2")
doc_embedder.warm_up()
docs_with_embeddings = doc_embedder.run(docs)
document_store.write_documents(docs_with_embeddings["documents"])Storing the embeddings in VectorStore
from haystack.elements.retrievers.in_memory import InMemoryEmbeddingRetriever
retriever = InMemoryEmbeddingRetriever(document_store)Defining the immediate for RAG
from haystack.elements.builders import ChatPromptBuilder
from haystack.dataclasses import ChatMessage
template = [
ChatMessage.from_user(
"""
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
)
]
prompt_builder = ChatPromptBuilder(template=template)Initializing the LLM
from haystack.elements.mills.chat import OpenAIChatGenerator
chat_generator = OpenAIChatGenerator(mannequin="gpt-4o-mini")Defining the Pipeline nodes
from haystack import Pipeline
basic_rag_pipeline = Pipeline()
# Add elements to your pipeline
basic_rag_pipeline.add_component("text_embedder", text_embedder)
basic_rag_pipeline.add_component("retriever", retriever)
basic_rag_pipeline.add_component("prompt_builder", prompt_builder)
basic_rag_pipeline.add_component("llm", chat_generator)Connecting the nodes to one another
# Now, join the elements to one another
basic_rag_pipeline.join("text_embedder.embedding", "retriever.query_embedding")
basic_rag_pipeline.join("retriever", "prompt_builder")
basic_rag_pipeline.join("prompt_builder.immediate", "llm.messages")Invoking the LLM utilizing RAG
query = "What does Rhodes Statue appear like?"
response = basic_rag_pipeline.run({"text_embedder": {"textual content": query}, "prompt_builder": {"query": query}})
print(response["llm"]["replies"][0].textual content)Output
Batches: 100%1/1 [00:00<00:00, 17.91it/s]
‘The Colossus of Rhodes, a statue of the Greek sun-god Helios, is believed to
have stood roughly 33 meters (108 ft) tall and was constructed with
iron tie bars and brass plates forming its pores and skin, crammed with stone blocks.
Though the precise particulars of its look should not definitively recognized,
up to date accounts counsel that it had curly hair with bronze or silver
spikes radiating like flames on the pinnacle. The statue seemingly depicted Helios
in a robust, commanding pose, presumably with one hand shielding his eyes,
much like different representations of the solar god from the time. General, it
was designed to challenge energy and radiance, celebrating Rhodes' victory
over its enemies.’
5. RAGFlow
RAGFlow focuses on integrating retrieval and era processes. It streamlines the event of RAG purposes.
- Key Options:
- Simplifies the connection between retrieval and era.
- Permits for tailor-made workflows to fulfill challenge wants.
- Integrates simply with varied databases and doc codecs.
Right here’s the hands-on:
Join on the RAGFlow after which Click on on Strive RAGFlow
Then Click on on Create Data Base
Then Go to Mannequin Suppliers and choose the LLM mannequin that you just need to use, We’re utilizing Groq right here and paste its API key.
Then Go to System Mannequin settings and choose the chat mannequin from there.
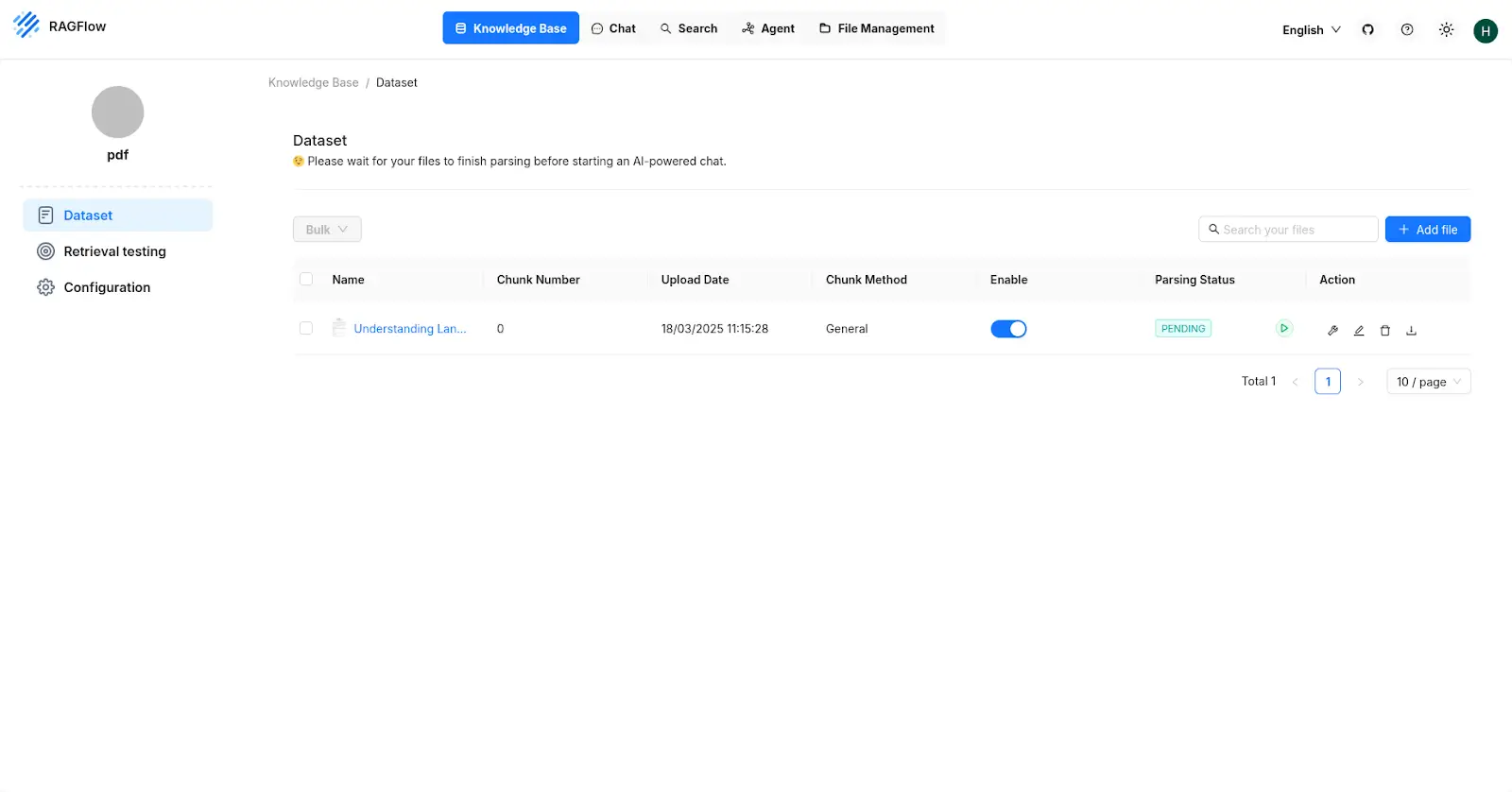
Now go to datasets and add the pdf you need, then click on on the Play button close to the Parsing standing column and look ahead to the pdf to get parsed.
Now go to the chat part create an assistant there, Give it a reputation and likewise choose the data base that you just created.
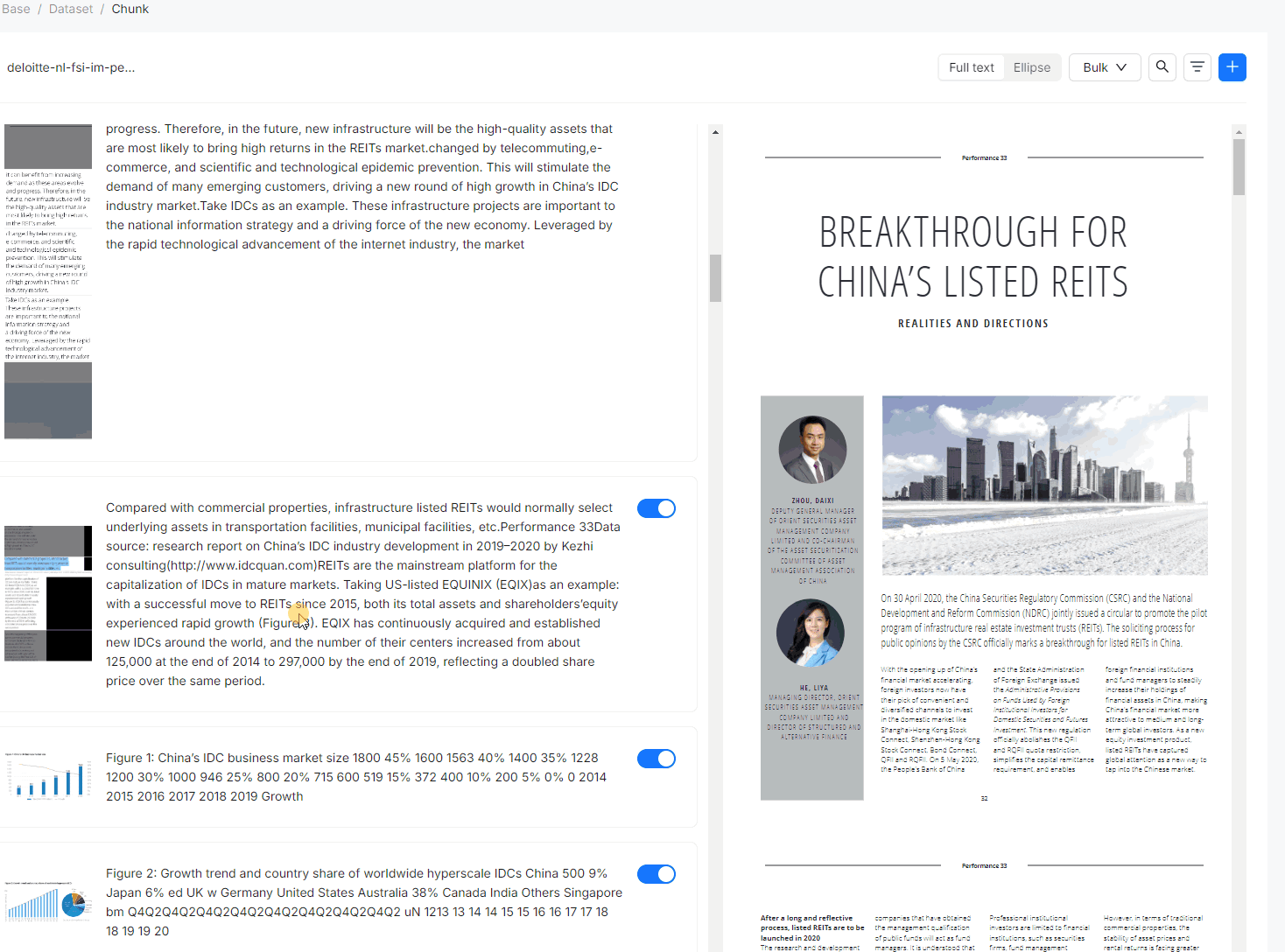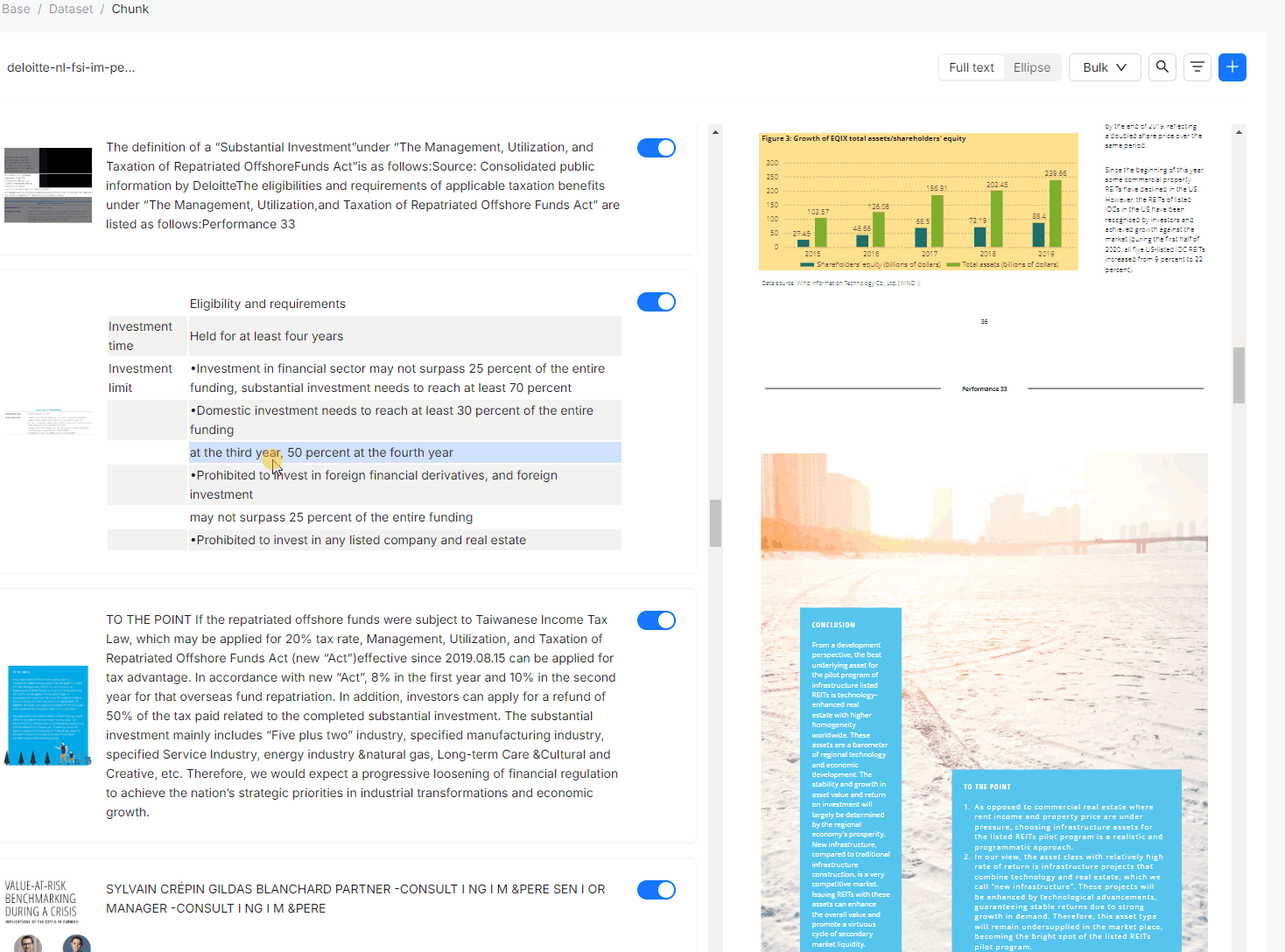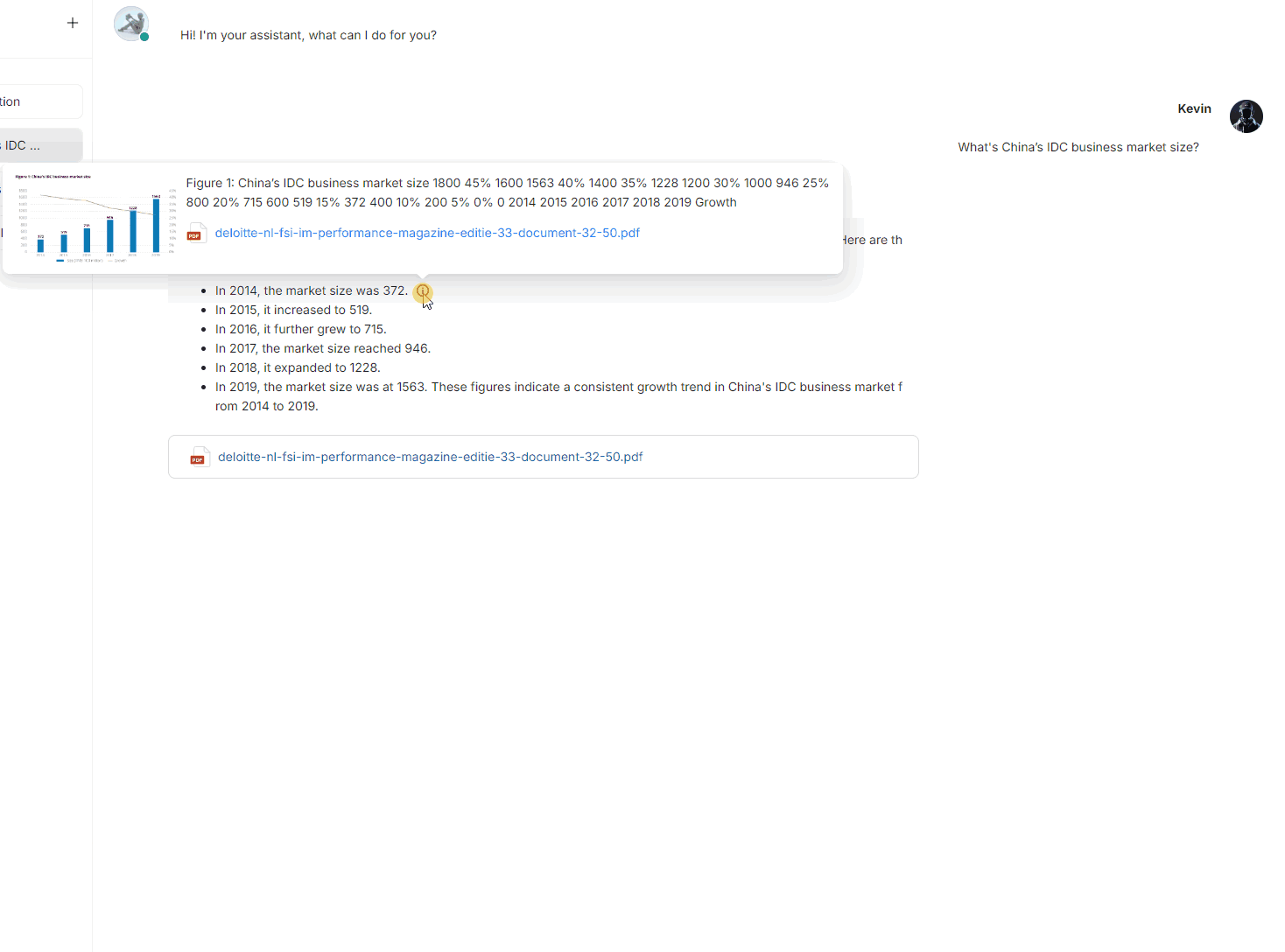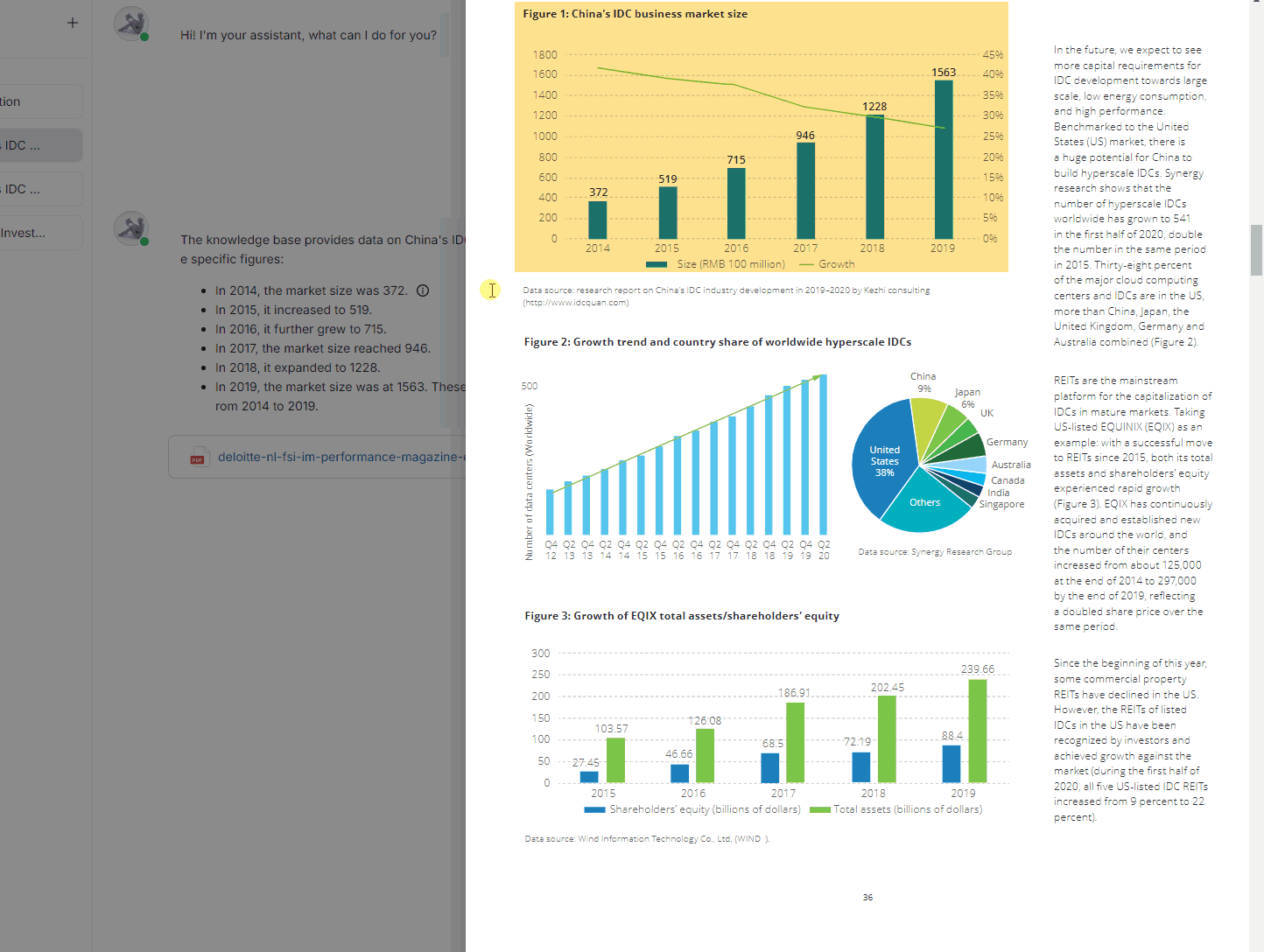
Then create a brand new chat and ask the query it would carry out RAG over your data base and reply accordingly.
Conclusion
RAG has develop into an essential know-how for customized enterprise datasets in current occasions, therefore the necessity for RAG frameworks has elevated drastically. Frameworks like LangChain, LlamaIndex, LangGraph, Haystack, and RAGFlow signify important developments in AI purposes. By utilizing these frameworks, builders can create techniques that present correct and related info. As AI continues to evolve, these instruments will play an essential function in shaping clever purposes.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Obsessed with GenAI, NLP, and making machines smarter (in order that they don’t exchange him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.