

{kind=link}
The time period harness has emerged as a shorthand to imply all the things in an AI agent besides the mannequin itself – Agent = Mannequin + Harness. That could be a very extensive definition, and due to this fact value narrowing down for widespread classes of brokers. I wish to take the freedom right here of defining its which means within the bounded context of utilizing a coding agent. In coding brokers, a part of the harness is already in-built (e.g. by way of the system immediate, or the chosen code retrieval mechanism, or perhaps a subtle orchestration system). However coding brokers additionally present us, their customers, with many options to construct an outer harness particularly for our use case and system.

Determine 1:
The time period “harness” means various things relying on the bounded context.
A well-built outer harness serves two targets: it will increase the likelihood that the agent will get it proper within the first place, and it offers a suggestions loop that self-corrects as many points as attainable earlier than they even attain human eyes. Finally it ought to scale back the overview toil and improve the system high quality, all with the additional advantage of fewer wasted tokens alongside the way in which.
Feedforward and Suggestions
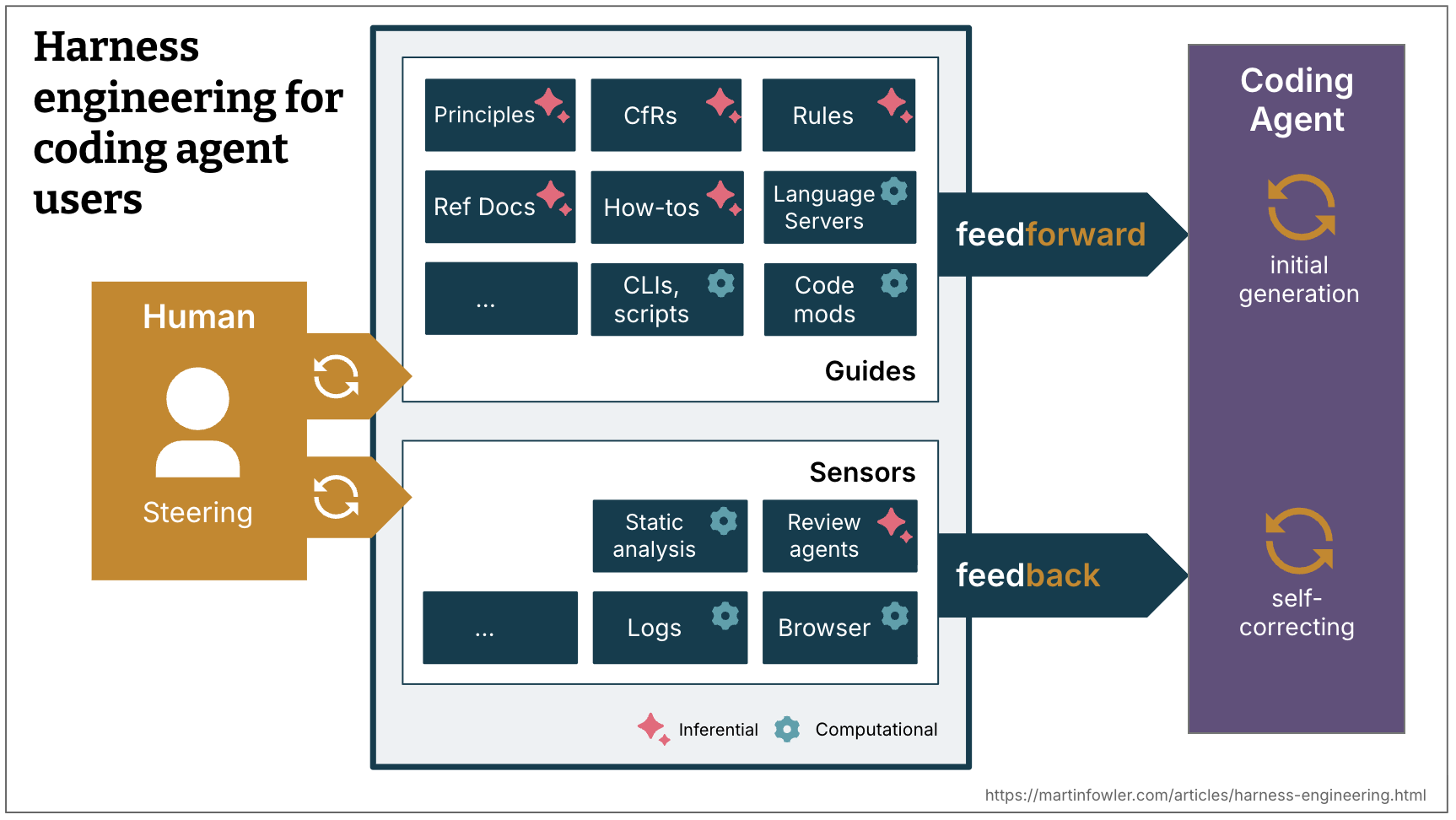
To harness a coding agent we each anticipate undesirable outputs and attempt to forestall them, and we put sensors in place to permit the agent to self-correct:
- Guides (feedforward controls) – anticipate the agent’s behaviour and purpose to steer it earlier than it acts. Guides improve the likelihood that the agent creates good leads to the primary try
- Sensors (suggestions controls) – observe after the agent acts and assist it self-correct. Notably highly effective once they produce alerts which might be optimised for LLM consumption, e.g. customized linter messages that embody directions for the self-correction – a constructive form of immediate injection.
Individually, you get both an agent that retains repeating the identical errors (feedback-only) or an agent that encodes guidelines however by no means finds out whether or not they labored (feed-forward-only).
Computational vs Inferential
There are two execution varieties of guides and sensors:
- Computational – deterministic and quick, run by the CPU. Assessments, linters, kind checkers, structural evaluation. Run in milliseconds to seconds; outcomes are dependable.
- Inferential – Semantic evaluation, AI code overview, “LLM as decide”. Usually run by a GPU or NPU. Slower and costlier; outcomes are extra non-deterministic.
Computational guides improve the likelihood of fine outcomes with deterministic tooling. Computational sensors are low cost and quick sufficient to run on each change, alongside the agent. Inferential controls are after all costlier and non-deterministic, however permit us to each present wealthy steerage, and add extra semantic judgment. Regardless of their non-determinism, inferential sensors can significantly improve our belief when used with a robust mannequin, or quite a mannequin that’s appropriate to the duty at hand.
Examples
| Course | Computational / Inferential | Instance implementations | |
|---|---|---|---|
| Coding conventions | feedforward | Inferential | AGENTS.md, Abilities |
| Directions how you can bootstrap a brand new mission | feedforward | Each | Talent with directions and a bootstrap script |
| Code mods | feedforward | Computational | A instrument with entry to OpenRewrite recipes |
| Structural exams | suggestions | Computational | A pre-commit (or coding agent) hook operating ArchUnit exams that examine for violations of module boundaries |
| Directions how you can overview | suggestions | Inferential | Abilities |
The steering loop
The human’s job in that is to steer the agent by iterating on the harness. Every time a problem occurs a number of occasions, the feedforward and suggestions controls must be improved to make the difficulty much less possible to happen sooner or later, and even forestall it.
Within the steering loop, we are able to after all additionally use AI to enhance the harness. Coding brokers now make it less expensive to construct extra customized controls and extra customized static evaluation. Brokers may help write structural exams, generate draft guidelines from noticed patterns, scaffold customized linters, or create how-to guides from codebase archaeology.
Timing: Maintain high quality left
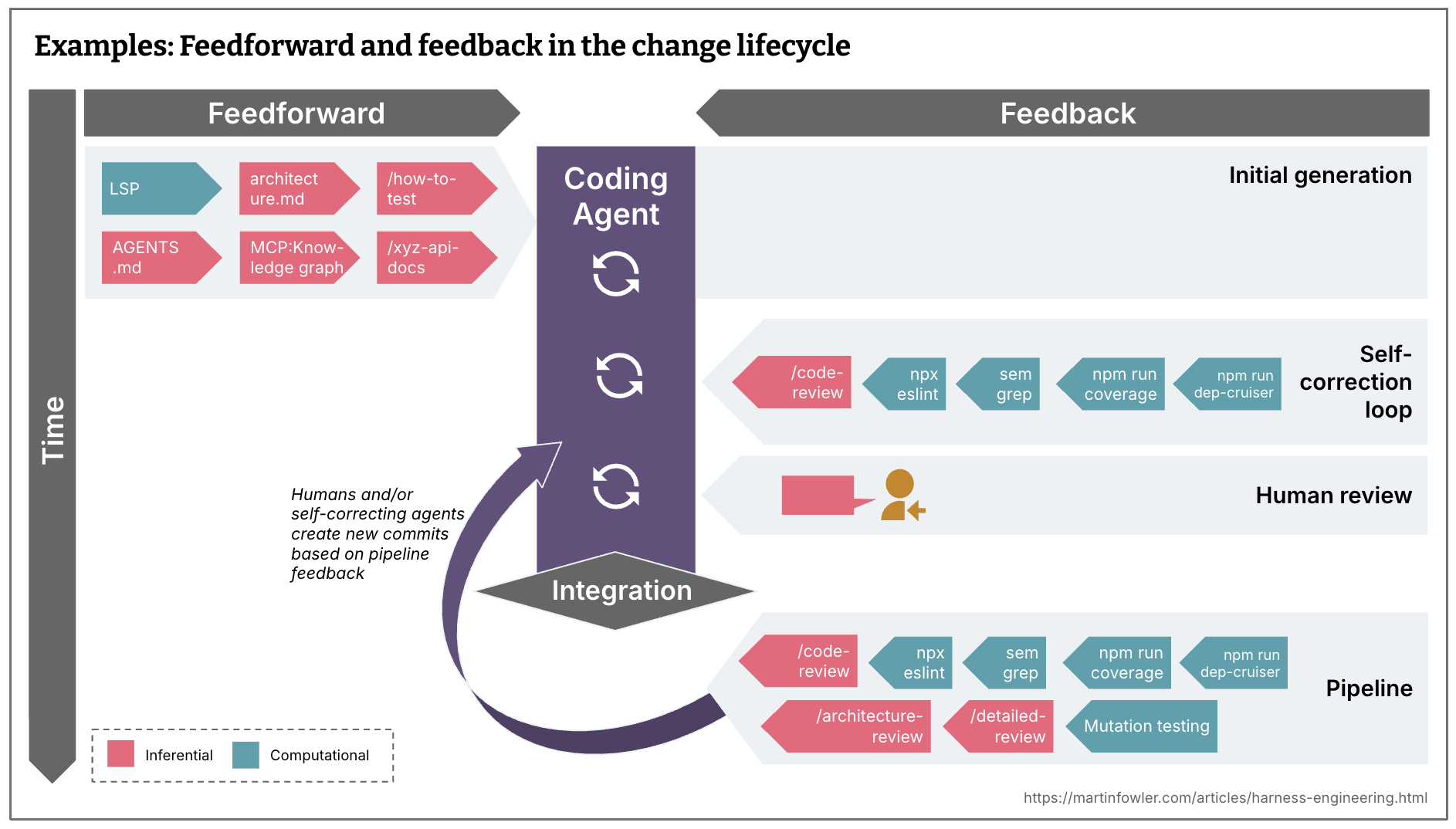
Groups who’re constantly integrating have at all times confronted the problem of spreading exams, checks and human opinions throughout the event timeline in response to their price, velocity and criticality. While you aspire to constantly ship, you ideally even need each commit state to be deployable. You wish to have checks as far left within the path to manufacturing as attainable, because the earlier you discover points, the cheaper they’re to repair. Suggestions sensors, together with the brand new inferential ones, must be distributed throughout the lifecycle accordingly.
Feedforward and suggestions within the change lifecycle
- What is fairly quick and must be run even earlier than integration, and even earlier than a commit is even created? (e.g. linters, quick check suites, primary code overview agent)
- What’s costlier and will due to this fact solely be run post-integration within the pipeline, along with a repetition of the quick controls? (e.g. mutation testing, a extra broad code overview that may consider the larger image)
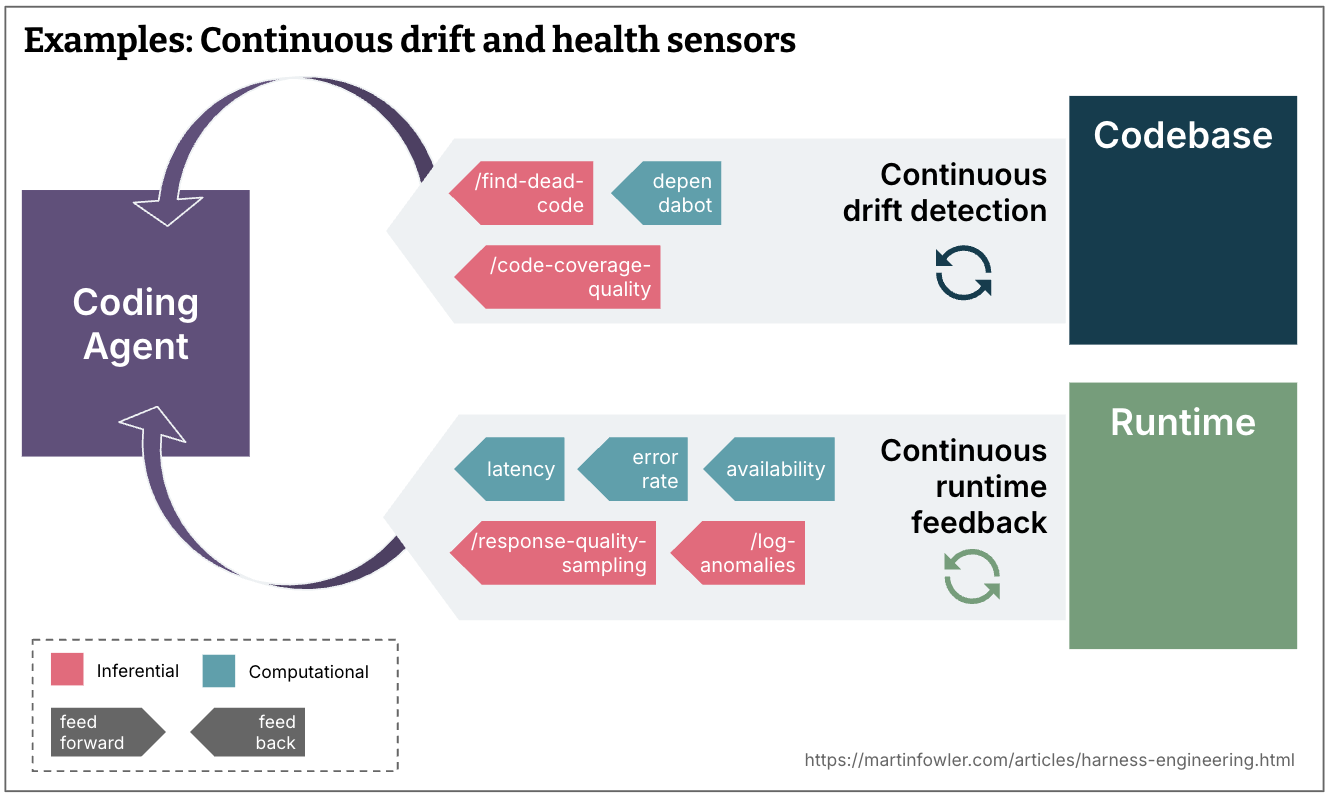
Steady drift and well being sensors
- What kind of drift accumulates progressively and must be monitored by sensors operating constantly towards the codebase, outdoors the change lifecycle? (e.g. useless code detection, evaluation of the standard of the check protection, dependency scanners)
- What runtime suggestions may brokers be monitoring? (e.g. having them search for degrading SLOs to make solutions how you can enhance them, or AI judges constantly sampling response high quality and flagging log anomalies)
Regulation classes
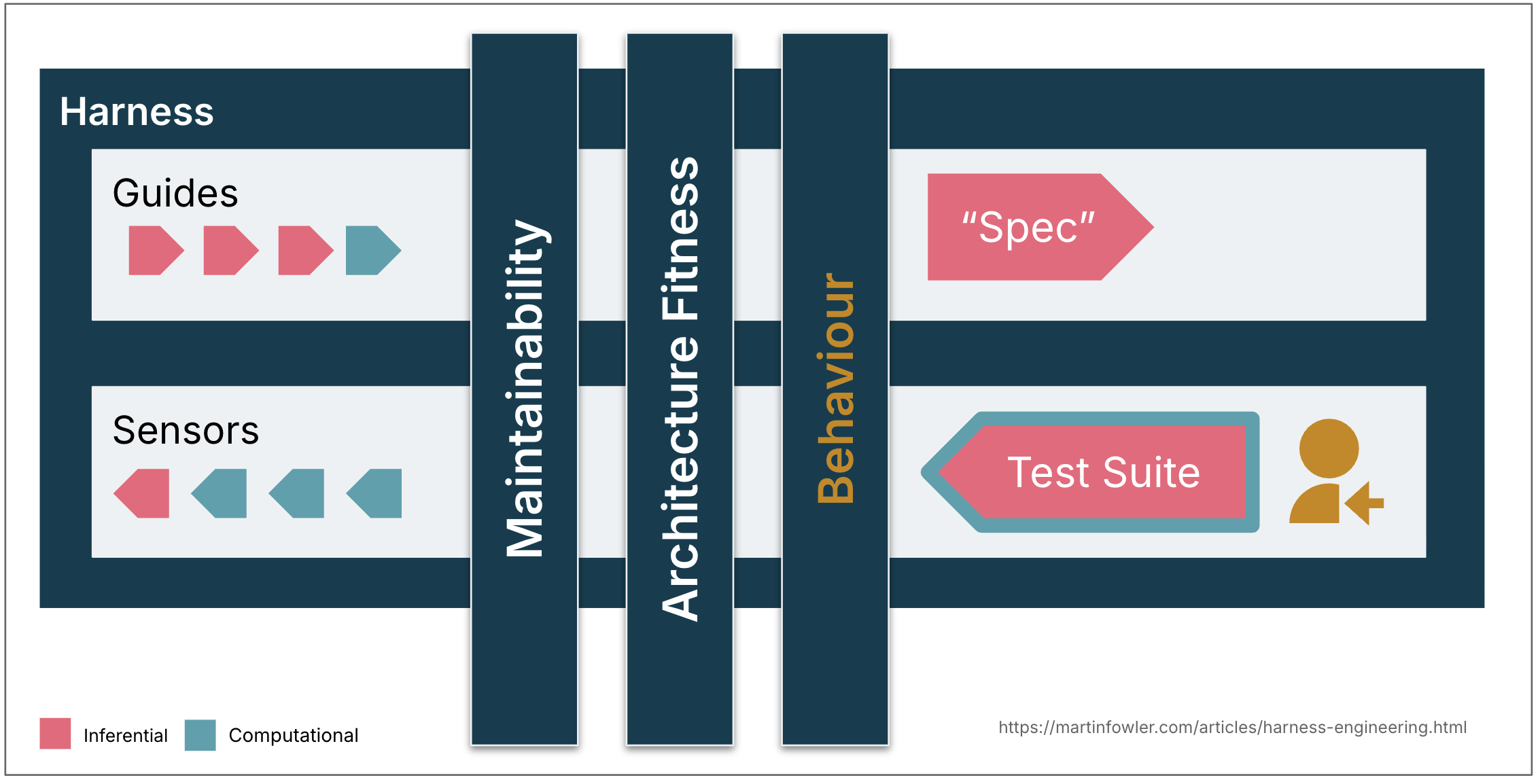
The agent harness acts like a cybernetic governor, combining feed-forward and suggestions to control the codebase in direction of its desired state. It is helpful to tell apart between a number of dimensions of that desired state, categorised by what the harness is meant to control. Distinguishing between these classes helps as a result of harnessability and complexity differ throughout them, and qualifying the phrase provides us extra exact language for a time period that’s in any other case very generic.
The next are three classes that appear helpful to me as of now:
Maintainability harness
Roughly the entire examples I’m giving on this article are about regulating inner code high quality and maintainability. That is in the meanwhile the simplest kind of harness, as we have now plenty of pre-existing tooling that we are able to use for this.
To mirror on how a lot these aforementioned maintainability harness concepts improve my belief in brokers, I mapped widespread coding agent failure modes that I catalogued earlier than towards it.
Computational sensors catch the structural stuff reliably: duplicate code, cyclomatic complexity, lacking check protection, architectural drift, type violations. These are low cost, confirmed, and deterministic.
LLMs can partially tackle issues that require semantic judgment – semantically duplicate code, redundant exams, brute-force fixes, over-engineered options – however expensively and probabilistically. Not on each commit.
Neither catches reliably among the higher-impact issues: Misdiagnosis of points, overengineering and pointless options, misunderstood directions. They’re going to typically catch them, however not reliably sufficient to scale back supervision. Correctness is outdoors any sensor’s remit if the human did not clearly specify what they wished within the first place.
Structure health harness
This teams guides and sensors that outline and examine the structure traits of the appliance. Mainly: Health Features.
Examples:
- Abilities that feed ahead our efficiency necessities, and efficiency exams that feed again to the agent if it improved or degraded them.
- Abilities that describe coding conventions for higher observability (like logging requirements), and debugging directions that ask the agent to mirror on the standard of the logs it had out there.
Behaviour harness
That is the elephant within the room – how will we information and sense if the appliance functionally behaves the way in which we’d like it to? For the time being, I see most individuals who give excessive autonomy to their coding brokers do that:
- Feed-forward: A practical specification (of various ranges of element, from a brief immediate to multi-file descriptions)
- Feed-back: Test if the AI-generated check suite is inexperienced, has moderately excessive protection, some may even monitor its high quality with mutation testing. Then mix that with handbook testing.
This strategy places plenty of religion into the AI-generated exams, that is not ok but. A few of my colleagues are seeing good outcomes with the authorized fixtures sample, however it’s simpler to use in some areas than others. They use it selectively the place it suits, it isn’t a wholesale reply to the check high quality downside.
So total, we nonetheless have quite a bit to do to determine good harnesses for practical behaviour that improve our confidence sufficient to scale back supervision and handbook testing.
Harnessability
Not each codebase is equally amenable to harnessing. A codebase written in a strongly typed language naturally has type-checking as a sensor; clearly definable module boundaries afford architectural constraint guidelines; frameworks like Spring summary away particulars the agent does not even have to fret about and due to this fact implicitly improve the agent’s possibilities of success. With out these properties, these controls aren’t out there to construct.
This performs out in a different way for greenfield versus legacy. Greenfield groups can bake harnessability in from day one – know-how choices and structure decisions decide how governable the codebase shall be. Legacy groups, particularly with purposes which have accrued plenty of technical debt, face the tougher downside: the harness is most wanted the place it’s hardest to construct.
Harness templates
Most enterprises have a couple of widespread topologies of providers that cowl 80% of what they want – enterprise providers that exposes information by way of APIs; occasion processing providers; information dashboards. In lots of mature engineering organizations these topologies are already codified in service templates. These may evolve into harness templates sooner or later: a bundle of guides and sensors that leash a coding agent to the construction, conventions and tech stack of a topology. Groups might begin choosing tech stacks and buildings partly primarily based on what harnesses are already out there for them.
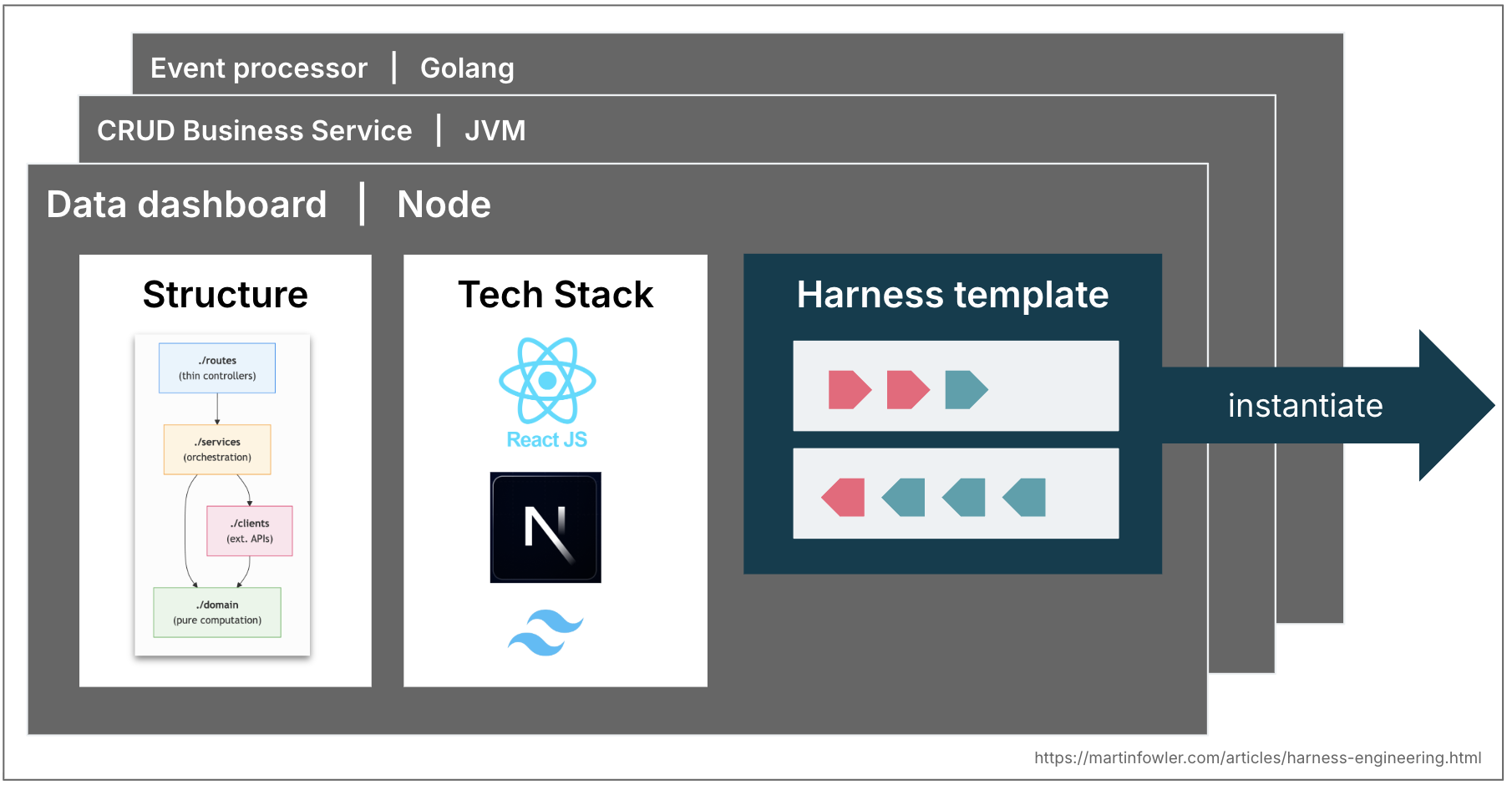
We might after all face comparable challenges as with service templates. As quickly as groups instantiate them, they begin fall out of sync with upstream enhancements. Harness templates would face the identical versioning and contribution issues, perhaps even worse with non-deterministic guides and sensors which might be tougher to check.
The function of the human
As human builders we convey our abilities and expertise as an implicit harness to each codebase. We absorbed conventions and good practices, we have now felt the cognitive ache of complexity, and we all know that our identify is on the commit. We additionally carry organisational alignment – consciousness of what the group is making an attempt to attain, which technical debt is tolerated for enterprise causes, and what “good” seems like on this particular context. We go in small steps and at our human tempo, which creates the considering house for that have to get triggered and utilized.
A coding agent has none of this: no social accountability, no aesthetic disgust at a 300-line operate, no instinct that “we do not do it that means right here,” and no organisational reminiscence. It does not know which conference is load-bearing and which is simply behavior, or whether or not the technically appropriate resolution suits what the group is making an attempt to do.
Harnesses are an try and externalise and make express what human developer expertise brings to the desk, however it could actually solely go thus far. Constructing a coherent system of guides and sensors and self-correction loops is pricey, so we have now to prioritise with a transparent aim in thoughts: A very good harness shouldn’t essentially purpose to completely remove human enter, however to direct it to the place our enter is most necessary.
A place to begin – and open questions
The psychological mannequin I’ve laid out right here describes methods which might be already taking place in observe and helps body discussions about what we nonetheless want to determine. Its aim is to boost the dialog above the characteristic stage – from abilities and MCP servers to how we strategically design a system of controls that provides us real confidence in what brokers produce.
Listed below are some harness-related examples from the present discourse:
- An OpenAI group documented what their harness seems like: layered structure enforced by customized linters and structural exams, and recurring “rubbish assortment” that scans for drift and has brokers recommend fixes. Their conclusion: “Our most troublesome challenges now heart on designing environments, suggestions loops, and management programs.”
- Stripe’s write-up about their minions describes issues like pre-push hooks that run related linters primarily based on a heuristic, they spotlight how necessary “shift suggestions left” is to them, and their “blueprints” present how they’re integrating suggestions sensors into the agent workflows.
- Mutation and structural testing are examples of computational suggestions sensors which have been underused up to now, however at the moment are having a resurgence.
- There’s elevated chatter amongst builders in regards to the integration of LSPs and code intelligence in coding brokers, examples of computational feedforward guides.
- I hear tales from groups at Thoughtworks about tackling structure drift with each computational and inferential sensors, e.g. rising API high quality with a mixture of brokers and customized linters, or rising code high quality with a “janitor military”.
There’s a lot nonetheless to determine, not simply the already talked about behavioural harness. How will we hold a harness coherent because it grows, with guides and sensors in sync, not contradicting one another? How far can we belief brokers to make smart trade-offs when directions and suggestions alerts level in numerous instructions? If sensors by no means fireplace, is {that a} signal of top quality or insufficient detection mechanisms? We want a solution to consider harness protection and high quality just like what code protection and mutation testing do for exams. Feedforward and suggestions controls are presently scattered throughout supply steps, there’s actual potential for tooling that helps configure, sync, and purpose about them as a system. Constructing this outer harness is rising as an ongoing engineering observe, not a one-time configuration.