

{kind=link}
Introduction
In at present’s fast-paced enterprise world, the flexibility to extract related and correct information from numerous sources is essential for knowledgeable decision-making, course of optimization, and strategic planning. Whether or not it is analyzing buyer suggestions, extracting key info from authorized paperwork, or parsing internet content material, environment friendly information extraction can present useful insights and streamline operations.
Enter massive language fashions (LLMs) and their APIs – highly effective instruments that make the most of superior pure language processing (NLP) to know and generate human-like textual content. Nevertheless, it is essential to notice that LLM APIs
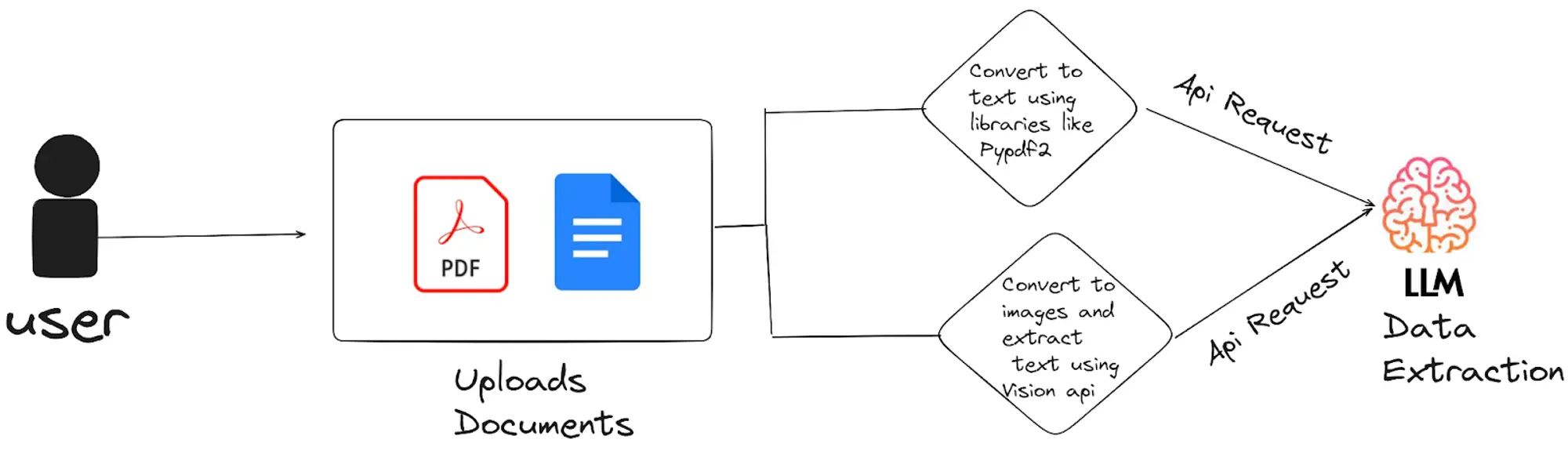
For doc evaluation, the everyday workflow includes:
- Doc Conversion to Pictures: Whereas some LLM APIs course of PDFs straight, changing them to pictures usually enhances OCR accuracy, making it simpler to extract textual content from non-searchable or poorly scanned paperwork
- Textual content Extraction Strategies:
- Utilizing Imaginative and prescient APIs:
Imaginative and prescient APIs excel at extracting textual content from photographs, even in difficult situations involving advanced layouts, various fonts, or low-quality scans. This strategy ensures dependable textual content extraction from paperwork which can be tough to course of in any other case. - Direct Extraction from Machine-Readable PDFs:
For easy, machine-readable PDFs, libraries like PyPDF2 can extract textual content straight with out changing the doc to pictures. This technique is quicker and extra environment friendly for paperwork the place the textual content is already selectable and searchable. - Enhancing Extraction with LLM APIs:
At the moment, textual content will be straight extracted and analyzed from picture in a single step utilizing LLMs. This built-in strategy simplifies the method by combining extraction, content material processing, key information level identification, abstract era, and perception provision into one seamless operation. To discover how LLMs will be utilized to totally different information extraction situations, together with the mixing of retrieval-augmented era strategies, see this overview of constructing RAG apps.
- Utilizing Imaginative and prescient APIs:
On this weblog, we’ll discover a couple of LLM APIs designed for information extraction straight from information and examine their options. Desk of Contents:
- Understanding LLM APIs
- Choice Standards for Prime LLM APIs
- LLM APIs We Chosen For Knowledge Extraction
- Comparative Evaluation of LLM APIs for Knowledge Extraction
- Experiment evaluation
- API Options and Pricing Evaluation
- Different literature on the web Evaluation
- Conclusion
Understanding LLM APIs
What Are LLM APIs?
Massive language fashions are synthetic intelligence methods which have been skilled on huge quantities of textual content information, enabling them to know and generate human-like language. LLM APIs, or software programming interfaces, present builders and companies with entry to those highly effective language fashions, permitting them to combine these capabilities into their very own functions and workflows.
At their core, LLM APIs make the most of subtle pure language processing algorithms to grasp the context and which means of textual content, going past easy sample matching or key phrase recognition. This depth of understanding is what makes LLMs so useful for a variety of language-based duties, together with information extraction. For a deeper dive into how these fashions function, discuss with this detailed information on what massive language fashions are.
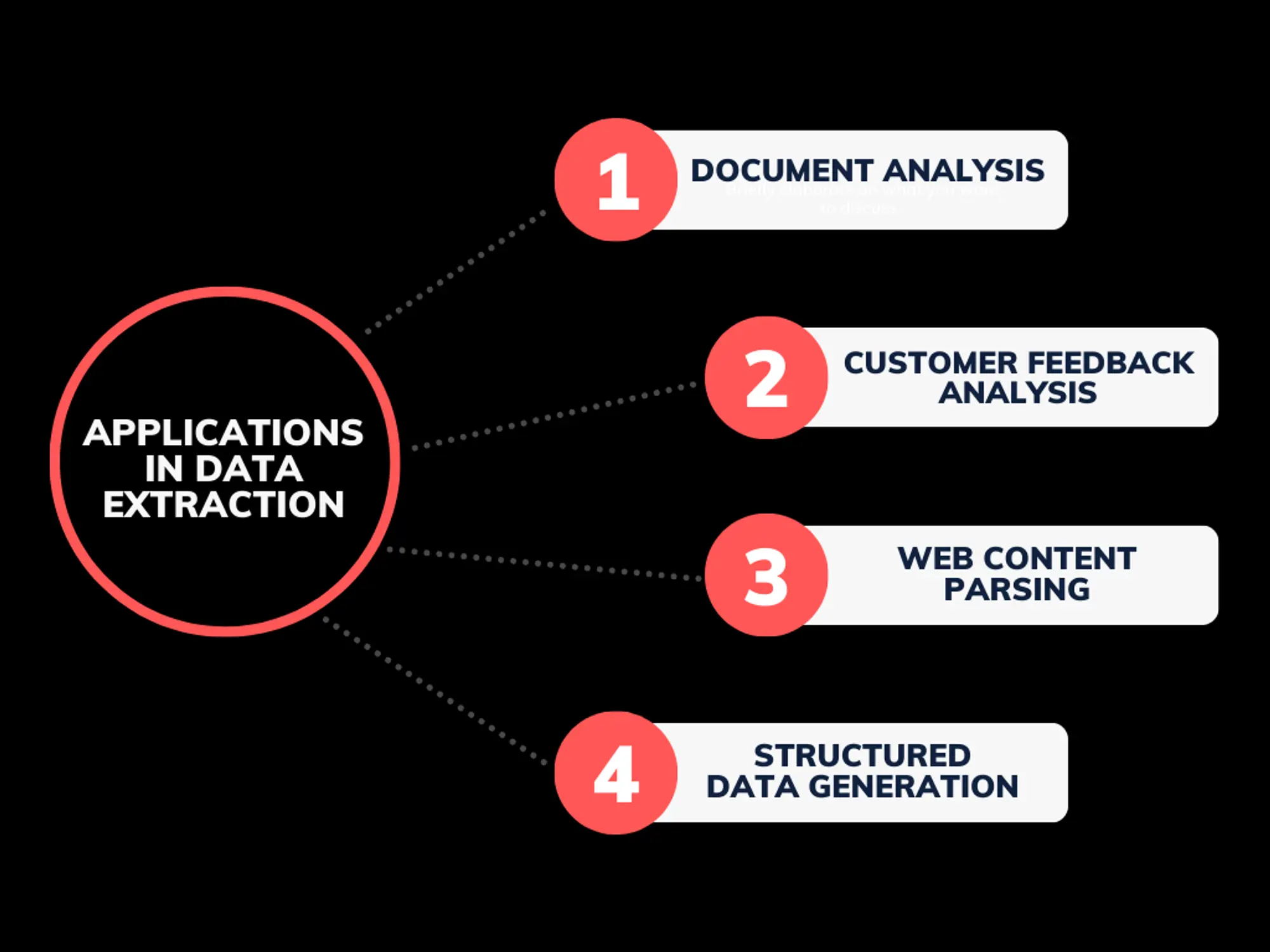
Whereas conventional LLM APIs primarily concentrate on processing and analyzing extracted textual content, multimodal fashions like ChatGPT and Gemini may also work together with photographs and different media varieties. These fashions do not carry out conventional information extraction (like OCR) however play a vital function in processing, analyzing, and contextualizing each textual content and pictures, remodeling information extraction and evaluation throughout numerous industries and use circumstances.
- Doc Evaluation: LLM APIs extract textual content from doc photographs, that are then parsed to determine key info from advanced paperwork like authorized contracts, monetary reviews, and regulatory filings.
- Buyer Suggestions Evaluation: After textual content extraction, LLM-powered sentiment evaluation and pure language understanding assist companies shortly extract insights from buyer evaluations, surveys, and assist conversations.
- Internet Content material Parsing: LLM APIs will be leveraged to course of and construction information extracted from internet pages, enabling the automation of duties like value comparability, lead era, and market analysis.
- Structured Knowledge Era: LLM APIs can generate structured information, akin to tables or databases, from unstructured textual content sources extracted from reviews or articles.
As you discover the world of LLM APIs to your information extraction wants, it is essential to contemplate the next key options that may make or break the success of your implementation:
Accuracy and Precision
Correct information extraction is the muse for knowledgeable decision-making and efficient course of automation. LLM APIs ought to exhibit a excessive stage of precision in understanding the context and extracting the related info from numerous sources, minimizing errors and inconsistencies.
Scalability
Your information extraction wants could develop over time, requiring an answer that may deal with rising volumes of information and requests with out compromising efficiency. Search for LLM APIs that supply scalable infrastructure and environment friendly processing capabilities.
Integration Capabilities
Seamless integration together with your present methods and workflows is essential for a profitable information extraction technique. Consider the benefit of integrating LLM APIs with your small business functions, databases, and different information sources.
Customization Choices
Whereas off-the-shelf LLM APIs can present glorious efficiency, the flexibility to fine-tune or customise the fashions to your particular {industry} or use case can additional improve the accuracy and relevance of the extracted information.
Safety and Compliance
When coping with delicate or confidential info, it is important to make sure that the LLM API you select adheres to strict safety requirements and regulatory necessities, akin to information encryption, consumer authentication, and entry management.
Context Lengths
The power to course of and perceive longer enter sequences, referred to as context lengths, can considerably enhance the accuracy and coherence of the extracted information. Longer context lengths permit the LLM to higher grasp the general context and nuances of the data, resulting in extra exact and related outputs.
Prompting Strategies
Superior prompting strategies, akin to few-shot studying and immediate engineering, allow LLM APIs to higher perceive and reply to particular information extraction duties. By rigorously crafting prompts that information the mannequin’s reasoning and output, customers can optimize the standard and relevance of the extracted information.
Structured Outputs
LLM APIs that may ship structured, machine-readable outputs, akin to JSON or CSV codecs, are significantly useful for information extraction use circumstances. These structured outputs facilitate seamless integration with downstream methods and automation workflows, streamlining the whole information extraction course of.
Choice Standards for Prime LLM APIs
With these key options in thoughts, the following step is to determine the highest LLM APIs that meet these standards. The APIs mentioned under have been chosen based mostly on their efficiency in real-world functions, alignment with industry-specific wants, and suggestions from builders and companies alike.
Components Thought-about:
- Efficiency Metrics: Together with accuracy, velocity, and precision in information extraction.
- Advanced Doc Dealing with: The power to deal with several types of paperwork
- Person Expertise: Ease of integration, customization choices, and the provision of complete documentation.
Now that we have explored the important thing options to contemplate, let’s dive into a better take a look at the highest LLM APIs we have chosen for information extraction:
OpenAI GPT-3/GPT-4 API
OpenAI API is thought for its superior GPT-4 mannequin, which excels in language understanding and era. Its contextual extraction functionality permits it to take care of context throughout prolonged paperwork for exact info retrieval. The API helps customizable querying, letting customers concentrate on particular particulars and offering structured outputs like JSON or CSV for simple information integration. With its multimodal capabilities, it could deal with each textual content and pictures, making it versatile for numerous doc varieties. This mix of options makes OpenAI API a sturdy alternative for environment friendly information extraction throughout totally different domains.
Google Gemini API

Google Gemini API is Google’s newest LLM providing, designed to combine superior AI fashions into enterprise processes. It excels in understanding and producing textual content in a number of languages and codecs, making it appropriate for information extraction duties. Gemini is famous for its seamless integration with Google Cloud providers, which advantages enterprises already utilizing Google’s ecosystem. It options doc classification and entity recognition, enhancing its skill to deal with advanced paperwork and extract structured information successfully.
Claude 3.5 Sonnet API
Claude 3.5 Sonnet API by Anthropic focuses on security and interpretability, which makes it a novel choice for dealing with delicate and complicated paperwork. Its superior contextual understanding permits for exact information extraction in nuanced situations, akin to authorized and medical paperwork. Claude 3.5 Sonnet’s emphasis on aligning AI conduct with human intentions helps reduce errors and enhance accuracy in essential information extraction duties.
Nanonets API
Nanonets isn’t a standard LLM API however is extremely specialised for information extraction. It gives endpoints particularly designed to extract structured information from unstructured paperwork, akin to invoices, receipts, and contracts. A standout function is its no-code mannequin retraining course of—customers can refine fashions by merely annotating paperwork on the dashboard. Nanonets additionally integrates seamlessly with numerous apps and ERPs, enhancing its versatility for enterprises. G2 evaluations spotlight its user-friendly interface and distinctive buyer assist, particularly for dealing with advanced doc varieties effectively.
On this part, we’ll conduct a radical comparative evaluation of the chosen LLM APIs—Nanonets, OpenAI, Google Gemini, and Claude 3.5 Sonnet—specializing in their efficiency and options for information extraction.
Experiment Evaluation: We are going to element the experiments carried out to judge every API’s effectiveness. This contains an summary of the experimentation setup, such because the sorts of paperwork examined (e.g., multipage textual paperwork, invoices, medical information, and handwritten textual content), and the factors used to measure efficiency. We’ll analyze how every API handles these totally different situations and spotlight any notable strengths or weaknesses.
API Options and Pricing Evaluation: This part will present a comparative take a look at the important thing options and pricing constructions of every API. We’ll discover features akin to Token lengths, Fee limits, ease of integration, customization choices, and extra. Pricing fashions can be reviewed to evaluate the cost-effectiveness of every API based mostly on its options and efficiency.
Different Literature on the Web Evaluation: We’ll incorporate insights from present literature, consumer evaluations, and {industry} reviews to offer extra context and views on every API. This evaluation will assist to spherical out our understanding of every API’s popularity and real-world efficiency, providing a broader view of their strengths and limitations.
This comparative evaluation will aid you make an knowledgeable choice by presenting an in depth analysis of how these APIs carry out in observe and the way they stack up in opposition to one another within the realm of information extraction.
Experiment Evaluation
Experimentation Setup
We examined the next LLM APIs:
- Nanonets OCR (Full Textual content) and Customized Mannequin
- ChatGPT-4o-latest
- Gemini 1.5 Professional
- Claude 3.5 Sonnet
Doc Varieties Examined:
- Multipage Textual Doc: Evaluates how properly APIs retain context and accuracy throughout a number of pages of textual content.
- Invoices/Receipt with Textual content and Tables: Assesses the flexibility to extract and interpret each structured (tables) and unstructured (textual content) information.
- Medical Document: Challenges APIs with advanced terminology, alphanumeric codes, and diverse textual content codecs.
- Handwritten Doc: Checks the flexibility to acknowledge and extract inconsistent handwriting.
Multipage Textual Doc
Goal: Assess OCR precision and content material retention. Need to have the ability to extract uncooked textual content from the under paperwork.
Metrics Used:
- Levenshtein Accuracy: Measures the variety of edits required to match the extracted textual content with the unique, indicating OCR precision.
- ROUGE-1 Rating: Evaluates how properly particular person phrases from the unique textual content are captured within the extracted output.
- ROUGE-L Rating: Checks how properly the sequence of phrases and construction are preserved.
Paperwork Examined:
- Pink badge of braveness.pdf (10 pages): A novel to check content material filtering and OCR accuracy.
- Self Generated PDF (1 web page): A single-page doc created to keep away from copyright points.

Outcomes
| API | End result | Levenshtein Accuracy | ROUGE-1 Rating | ROUGE-L Rating |
|---|---|---|---|---|
| Nanonets OCR | Success | 96.37% | 98.94% | 98.46% |
| ChatGPT-4o-latest | Success | 98% | 99.76% | 99.76% |
| Gemini 1.5 Professional | Error: Recitation | x | x | x |
| Claude 3.5 Sonnet | Error: Output blocked by content material filtering coverage | x | x | x |
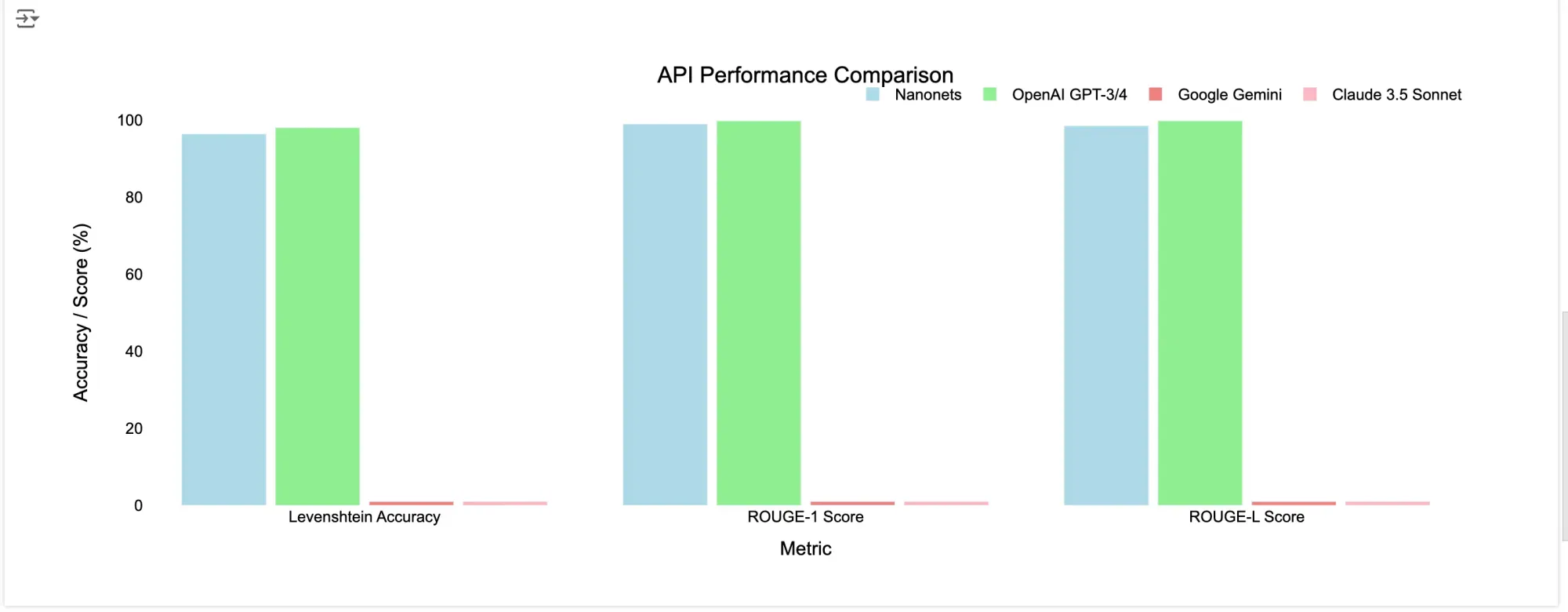
| API | End result | Levenshtein Accuracy | ROUGE-1 Rating | ROUGE-L Rating |
|---|---|---|---|---|
| Nanonets OCR | Success | 95.24% | 97.98% | 97.98% |
| ChatGPT-4o-latest | Success | 98.92% | 99.73% | 99.73% |
| Gemini 1.5 Professional | Success | 98.62% | 99.73% | 99.73% |
| Claude 3.5 Sonnet | Success | 99.91% | 99.73% | 99.73% |
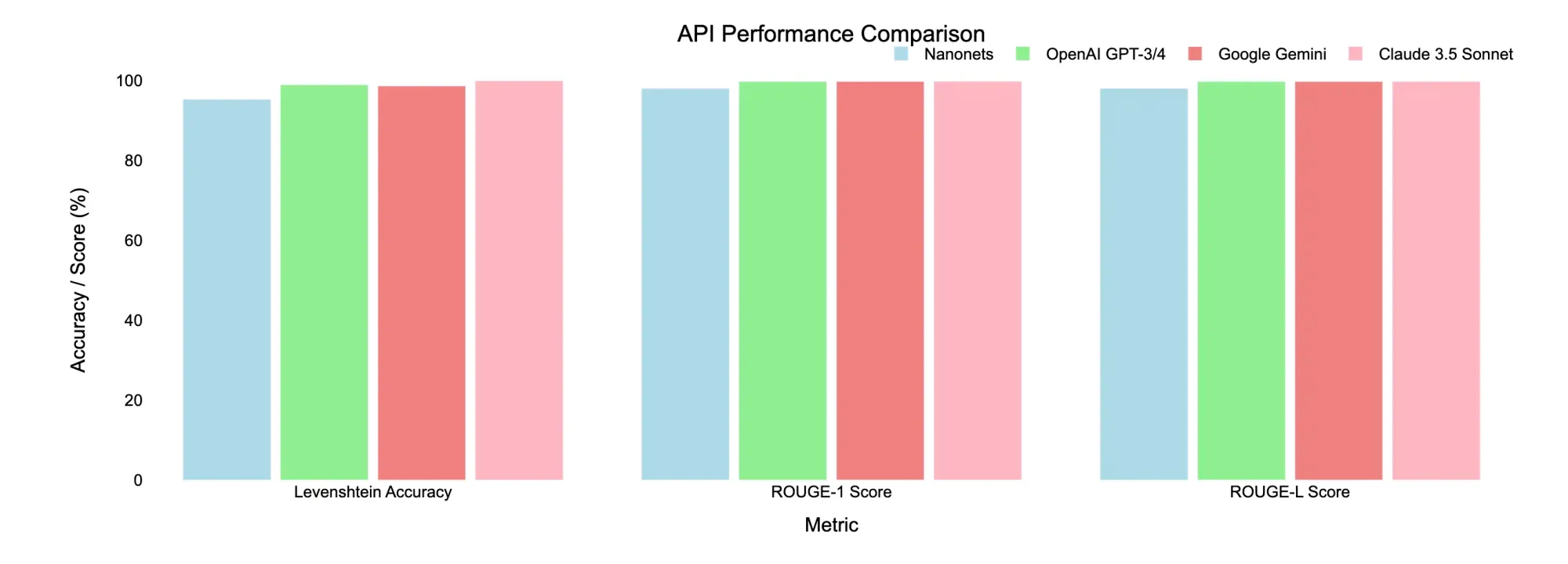
Key Takeaways
- Nanonets OCR and ChatGPT-4o-latest persistently carried out properly throughout each paperwork, with excessive accuracy and quick processing occasions.
- Claude 3.5 Sonnet encountered points with content material filtering, making it much less dependable for paperwork which may set off such insurance policies, nevertheless by way of retaining the construction of the unique doc, it stood out as the very best.
- Gemini 1.5 Professional struggled with “Recitation” errors, probably as a consequence of its content material insurance policies or non-conversational output textual content patterns
Conclusion: For paperwork which may have copyright points, Gemini and Claude won’t be very best as a consequence of potential content material filtering restrictions. In such circumstances, Nanonets OCR or ChatGPT-4o-latest might be extra dependable decisions.
💡
Total, whereas each Nanonets and ChatGPT-4o-latest carried out properly right here, the downside with GPT was that we wanted to make 10 separate requests (one for every web page) and convert PDFs to pictures earlier than processing. In distinction, Nanonets dealt with every part in a single step.
Goal: Consider the effectiveness of various LLM APIs in extracting structured information from invoices and receipts. That is totally different from simply doing an OCR and contains assessing their skill to precisely determine and extract key-value pairs and tables
Metrics Used:
- Precision: Measures the accuracy of extracting key-value pairs and desk information. It’s the ratio of accurately extracted information to the entire variety of information factors extracted. Excessive precision signifies that the API extracts related info precisely with out together with too many false positives.
- Cell Accuracy: Assesses how properly the API extracts information from tables, specializing in the correctness of information inside particular person cells. This metric checks if the values within the cells are accurately extracted and aligned with their respective headers.
Paperwork Examined:
- Check Bill An bill with 13 key-value pairs and a desk with 8 rows and 5 columns based mostly on which we can be judging the accuracy

Outcomes
The outcomes are from once we carried out the experiment utilizing a generic immediate from Chatgpt, Gemini, and Claude and utilizing a generic bill template mannequin for Nanonets
Key-Worth Pair Extraction
| API | Essential Key-Worth Pairs Extracted | Essential Keys Missed | Key Values with Variations |
|---|---|---|---|
| Nanonets OCR | 13/13 | None | – |
| ChatGPT-4o-latest | 13/13 | None | Bill Date: 11/24/18 (Anticipated: 12/24/18), PO Quantity: 31.8850876 (Anticipated: 318850876) |
| Gemini 1.5 Professional | 12/13 | Vendor Title | Bill Date: 12/24/18, PO Quantity: 318850876 |
| Claude 3.5 Sonnet | 12/13 | Vendor Deal with | Bill Date: 12/24/18, PO Quantity: 318850876 |
Desk Extraction
| API | Important Columns Extracted | Rows Extracted | Incorrect Cell Values |
|---|---|---|---|
| Nanonets OCR | 5/5 | 8/8 | 0/40 |
| ChatGPT-4o-latest | 5/5 | 8/8 | 1/40 |
| Gemini 1.5 Professional | 5/5 | 8/8 | 2/40 |
| Claude 3.5 Sonnet | 5/5 | 8/8 | 0/40 |
Key Takeaways
- Nanonets OCR proved to be extremely efficient for extracting each key-value pairs and desk information with excessive precision and cell accuracy.
- ChatGPT-4o-latest and Claude 3.5 Sonnet carried out properly however had occasional points with OCR accuracy, affecting the extraction of particular values.
- Gemini 1.5 Professional confirmed limitations in dealing with some key-value pairs and cell values precisely, significantly within the desk extraction.
Conclusion: For monetary paperwork, utilizing Nanonets for information extraction could be a more sensible choice. Whereas the opposite fashions can profit from tailor-made prompting strategies to enhance their extraction capabilities, OCR accuracy is one thing which may require customized retraining lacking within the different 3. We are going to speak about this in additional element in a later part of the weblog.
Medical Doc
Goal: Consider the effectiveness of various LLM APIs in extracting structured information from a medical doc, significantly specializing in textual content with superscripts, subscripts, alphanumeric characters, and specialised phrases.
Metrics Used:
- Levenshtein Accuracy: Measures the variety of edits required to match the extracted textual content with the unique, indicating OCR precision.
- ROUGE-1 Rating: Evaluates how properly particular person phrases from the unique textual content are captured within the extracted output.
- ROUGE-L Rating: Checks how properly the sequence of phrases and construction are preserved.
Paperwork Examined:
- Italian Medical Report A single-page doc with advanced textual content together with superscripts, subscripts, and alphanumeric characters.
Outcomes
| API | Levenshtein Accuracy | ROUGE-1 Rating | ROUGE-L Rating |
|---|---|---|---|
| Nanonets OCR | 63.21% | 100% | 100% |
| ChatGPT-4o-latest | 64.74% | 92.90% | 92.90% |
| Gemini 1.5 Professional | 80.94% | 100% | 100% |
| Claude 3.5 Sonnet | 98.66% | 100% | 100% |
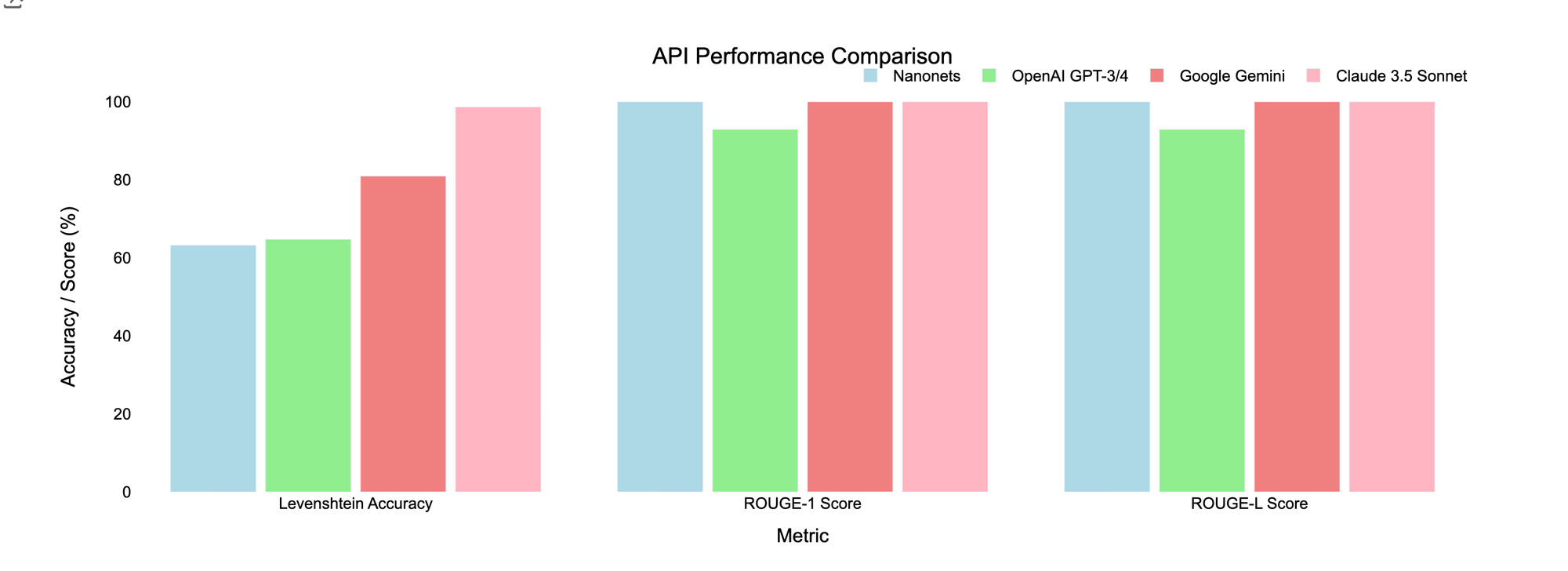
Key Takeaways
- Gemini 1.5 Professional and Claude 3.5 Sonnet carried out exceptionally properly in preserving the doc’s construction and precisely extracting advanced characters, with Claude 3.5 Sonnet main in general accuracy.
- Nanonets OCR offered first rate extraction outcomes however struggled with the complexity of the doc, significantly with retaining the general construction of the doc, leading to decrease Levenshtein Accuracy.
- ChatGPT-4o-latest confirmed barely higher efficiency in preserving the structural integrity of the doc.
Conclusion: For medical paperwork with intricate formatting, Claude 3.5 Sonnet is probably the most dependable choice for sustaining the unique doc’s construction. Nevertheless, if structural preservation is much less essential, Nanonets OCR and Google Gemini additionally supply sturdy alternate options with excessive textual content accuracy.
Handwritten Doc
Goal: Assess the efficiency of varied LLM APIs in precisely extracting textual content from a handwritten doc, specializing in their skill to deal with irregular handwriting, various textual content sizes, and non-standardized formatting.
Metrics Used:
- ROUGE-1 Rating: Evaluates how properly particular person phrases from the unique textual content are captured within the extracted output.
- ROUGE-L Rating: Checks how properly the sequence of phrases and construction are preserved.
Paperwork Examined:
- Handwritten doc 1 A single-page doc with inconsistent handwriting, various textual content sizes, and non-standard formatting.
- Handwritten doc 2 A single-page doc with inconsistent handwriting, various textual content sizes, and non-standard formatting.

Outcomes
| API | ROUGE-1 Rating | ROUGE-L Rating |
|---|---|---|
| Nanonets OCR | 86% | 85% |
| ChatGPT-4o-latest | 92% | 92% |
| Gemini 1.5 Professional | 94% | 94% |
| Claude 3.5 Sonnet | 93% | 93% |
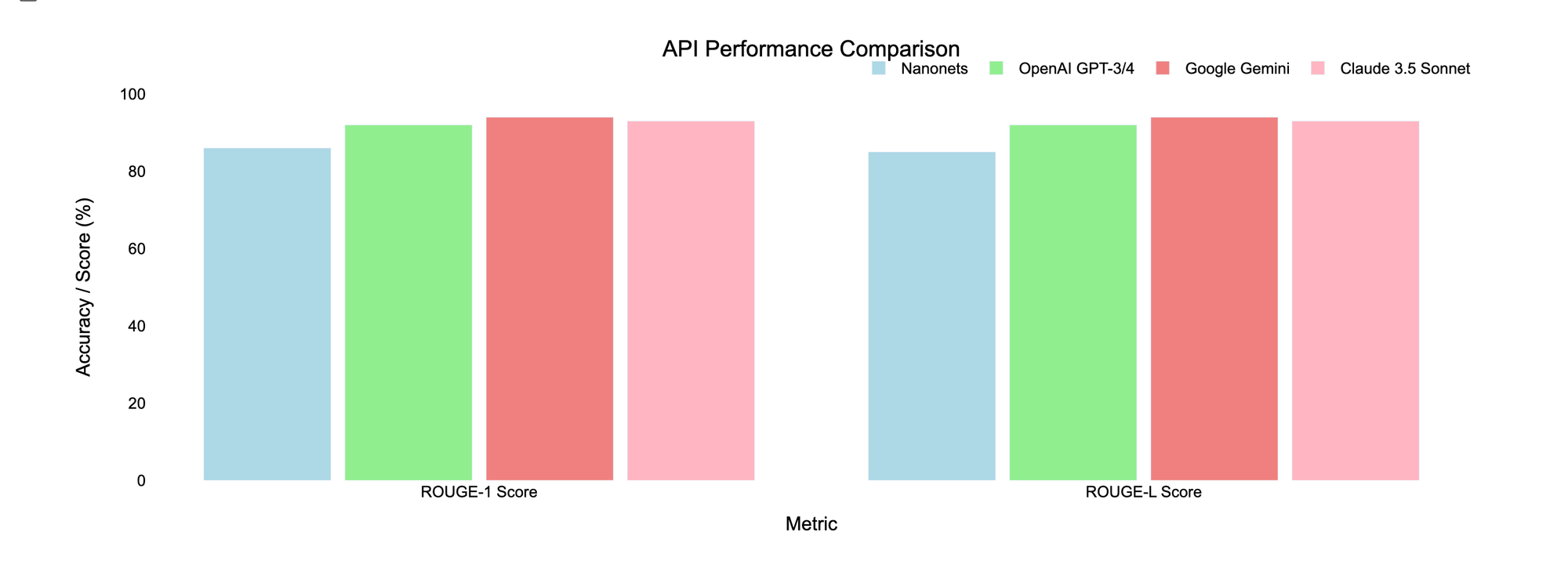
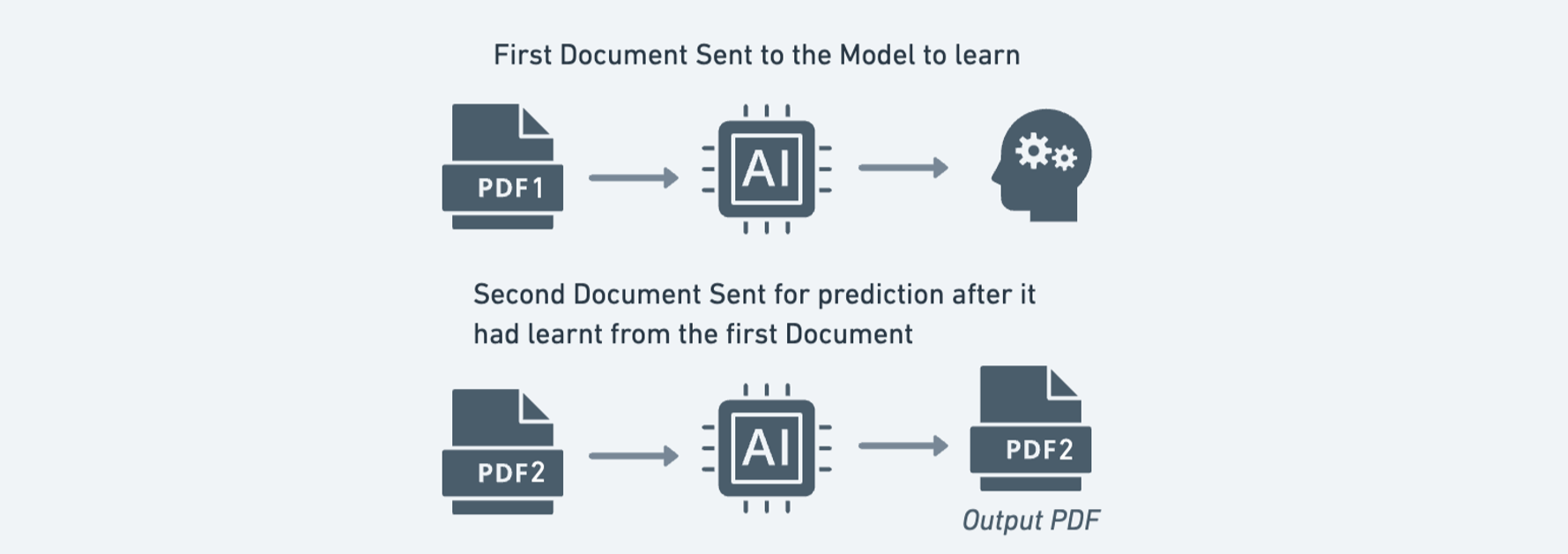
Affect of Coaching on Sonnet 3.5
To discover the potential for enchancment, the second doc was used to coach Claude 3.5 Sonnet earlier than extracting textual content from the primary doc. This resulted in a slight enchancment, with each ROUGE-1 and ROUGE-L scores will increase from 93% to 94%.
Key Takeaways
- ChatGPT-4o-latest Gemini 1.5 Professional and Claude 3.5 Sonnet carried out exceptionally properly, with solely minimal variations between them. Claude 3.5 Sonnet, after extra coaching, barely edged out Gemini 1.5 Professional in general accuracy.
- Nanonets OCR struggled a little bit with irregular handwriting, however that is one thing that may be resolved with the no-code coaching that it gives, one thing we’ll cowl another time
Conclusion: For handwritten paperwork with irregular formatting, all of the 4 choices confirmed the very best general efficiency. Retraining your mannequin can undoubtedly assist with enhancing accuracy right here.
API Options and Pricing Evaluation
When choosing a Massive Language Mannequin (LLM) API for information extraction, understanding charge limits, pricing, token lengths and extra options may be essential as properly. These elements considerably affect how effectively and successfully you’ll be able to course of and extract information from massive paperwork or photographs. As an illustration, in case your information extraction job includes processing textual content that exceeds the token restrict of an API, it’s possible you’ll face challenges with truncation or incomplete information, or in case your request frequency surpasses the speed limits, you might expertise delays or throttling, which may hinder the well timed processing of huge volumes of information.
| Characteristic | OpenAI GPT-4 | Google Gemini 1.5 Professional | Anthropic Claude 3.5 Sonnet | Nanonets OCR |
|---|---|---|---|---|
| Token Restrict (Free) | N/A (No free tier) | 32,000 | 8,192 | N/A (OCR particular) |
| Token Restrict (Paid) | 32,768 (GPT-4 Turbo) | 4,000,000 | 200,000 | N/A (OCR-specific) |
| Fee Limits (Free) | N/A (No free tier) | 2 RPM | 5 RPM | 2 RPM |
| Fee Limits (Paid) | Varies by tier, as much as 10,000 TPM* | 360 RPM | Varies by tier, goes as much as 4000 RPM | Customized plans out there |
| Doc Varieties Supported | Picture | photographs, movies | Pictures | Pictures and PDFs |
| Mannequin Retraining | Not out there | Not out there | Not out there | Accessible |
| Integrations with different Apps | Code-based API integration | Code-based API integration | Code-based API integration | Pre-built integrations with click-to-configure setup |
| Pricing Mannequin | Pay-per-token, tiered plans | Pay as you Go | Pay-per-token, tiered plans | Pay as you Go, Customized pricing based mostly on quantity |
| Beginning Value | $0.03/1K tokens (immediate), $0.06/1K tokens (completion) for GPT-4 | $3.5/1M tokens (enter), $10.5/1M tokens (output) | $0.25/1M tokens (enter), $1.25/1M tokens (output) | workflow based mostly, $0.05/step run |
- TPM = Tokens Per Minute, RPM= Requests Per Minute
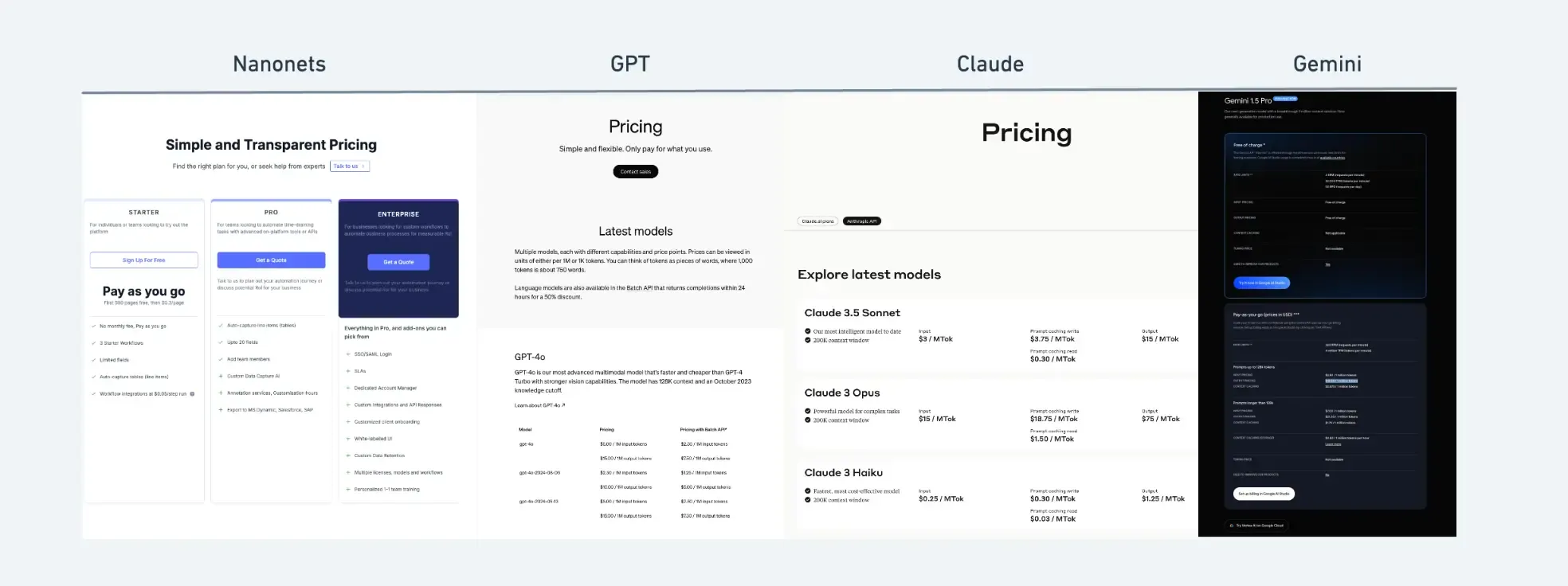
Hyperlinks for detailed pricing
Different Literature on the Web Evaluation
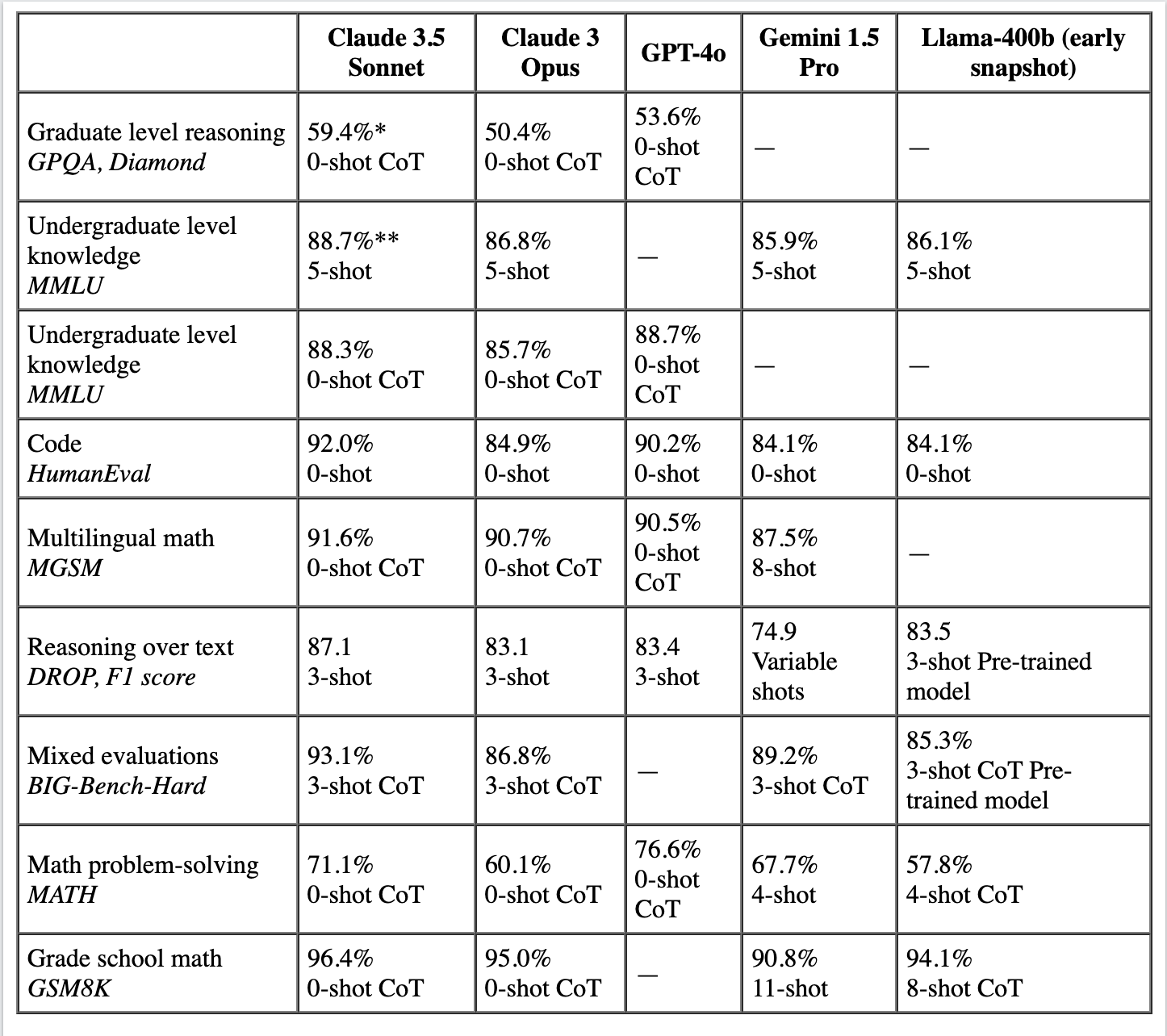
Along with our hands-on testing, we have additionally thought-about analyses out there from sources like Claude to offer a extra complete comparability of those main LLMs. The desk under presents an in depth comparative efficiency evaluation of varied AI fashions, together with Claude 3.5 Sonnet, Claude 3 Opus, GPT-4o, Gemini 1.5 Professional, and an early snapshot of Llama-400b. This analysis covers their talents in duties akin to reasoning, information retrieval, coding, and mathematical problem-solving. The fashions had been examined beneath totally different situations, like 0-shot, 3-shot, and 5-shot settings, which mirror the variety of examples offered to the mannequin earlier than producing an output. These benchmarks supply insights into every mannequin’s strengths and capabilities throughout numerous domains.
References:
Hyperlink 1
Hyperlink 2
Key Takeaways
- For detailed pricing and choices for every API, take a look at the hyperlinks offered above. They’ll aid you examine and discover the very best match to your wants.
- Moreover, whereas LLMs usually don’t supply retraining, Nanonets offers these options for its OCR options. This implies you’ll be able to tailor the OCR to your particular necessities, probably enhancing its accuracy.
- Nanonets additionally stands out with its pre-built integrations that make it simple to attach with different apps, simplifying the setup course of in comparison with the code-based integrations provided by different providers.
Conclusion
Deciding on the suitable LLM API for information extraction is crucial, particularly for numerous doc varieties like invoices, medical information, and handwritten notes. Every API has distinctive strengths and limitations based mostly in your particular wants.
- Nanonets OCR excels in extracting structured information from monetary paperwork with excessive precision, particularly for key-value pairs and tables.
- ChatGPT-4 gives balanced efficiency throughout numerous doc varieties however might have immediate fine-tuning for advanced circumstances.
- Gemini 1.5 Professional and Claude 3.5 Sonnet are sturdy in dealing with advanced textual content, with Claude 3.5 Sonnet significantly efficient in sustaining doc construction and accuracy.
For delicate or advanced paperwork, think about every API’s skill to protect the unique construction and deal with numerous codecs. Nanonets is good for monetary paperwork, whereas Claude 3.5 Sonnet is finest for paperwork requiring excessive structural accuracy.
In abstract, selecting the best API relies on understanding every choice’s strengths and the way they align together with your challenge’s wants.
| Characteristic | Nanonets | OpenAI GPT-3/4 | Google Gemini | Anthropic Claude |
|---|---|---|---|---|
| Pace (Experiment) | Quickest | Quick | Gradual | Quick |
| Strengths (Experiment) | Excessive precision in key-value pair extraction and structured outputs | Versatile throughout numerous doc varieties, quick processing | Wonderful in handwritten textual content accuracy, handles advanced codecs properly | Prime performer in retaining doc construction and complicated textual content accuracy |
| Weaknesses (Experiment) | Struggles with handwritten OCR | Wants fine-tuning for prime accuracy in advanced circumstances | Occasional errors in structured information extraction, slower velocity | Content material filtering points, particularly with copyrighted content material |
| Paperwork appropriate for | Monetary Paperwork | Dense Textual content Paperwork | Medical Paperwork, Handwritten Paperwork | Medical Paperwork, Handwritten Paperwork |
| Retraining Capabilities | No-code customized mannequin retraining out there | Positive tuning out there | Positive tuning out there | Positive tuning out there |
| Pricing Fashions | 3 (Pay-as-you-go, Professional, Enterprise) | 1 (Utilization-based, per-token pricing) | 1 (Utilization-based, per-token pricing) | 1 (Utilization-based, per-token pricing) |
| Integration Capabilities | Straightforward integration with ERP methods and customized workflows | Integrates properly with numerous platforms, APIs | Seamless integration with Google Cloud providers | Robust integration with enterprise methods |
| Ease of Setup | Fast setup with an intuitive interface | Requires API information for setup | Straightforward setup with Google Cloud integration | Person-friendly setup with complete guides |