

{kind=link}
Streaming knowledge feeds many real-time analytics purposes, from logistics monitoring to real-time personalization. Occasion streams, similar to clickstreams, IoT knowledge and different time sequence knowledge, are frequent sources of knowledge into these apps. The broad adoption of Apache Kafka has helped make these occasion streams extra accessible. Change knowledge seize (CDC) streams from OLTP databases, which can present gross sales, demographic or stock knowledge, are one other helpful supply of knowledge for real-time analytics use circumstances. On this put up, we evaluate two choices for real-time analytics on occasion and CDC streams: Rockset and ClickHouse.
Structure
ClickHouse was developed, starting in 2008, to deal with net analytics use circumstances at Yandex in Russia. The software program was subsequently open sourced in 2016. Rockset was began in 2016 to fulfill the wants of builders constructing real-time knowledge purposes. Rockset leverages RocksDB, a high-performance key-value retailer, began as an open-source mission at Fb round 2010 and based mostly on earlier work finished at Google. RocksDB is used as a storage engine for databases like Apache Cassandra, CockroachDB. Flink, Kafka and MySQL.
As real-time analytics databases, Rockset and ClickHouse are constructed for low-latency analytics on massive knowledge units. They possess distributed architectures that permit for scalability to deal with efficiency or knowledge quantity necessities. ClickHouse clusters are inclined to scale up, utilizing smaller numbers of huge nodes, whereas Rockset is a serverless, scale-out database. Each supply SQL assist and are able to ingesting streaming knowledge from Kafka.
Storage Format
Whereas Rockset and ClickHouse are each designed for analytic purposes, there are important variations of their approaches. The ClickHouse identify derives from “Clickstream Knowledge Warehouse” and it was constructed with knowledge warehouses in thoughts, so it’s unsurprising that ClickHouse borrows lots of the similar concepts—column orientation, heavy compression and immutable storage—in its implementation. Column orientation is understood to be a greater storage format for OLAP workloads, like large-scale aggregations, and is on the core of ClickHouse’s efficiency.
The foundational thought in Rockset, in distinction, is the indexing of knowledge for quick analytics. Rockset builds a Converged Index™ that has traits of a number of kinds of indexes—row, columnar and inverted—on all fields. In contrast to ClickHouse, Rockset is a mutable database.
Separation of Compute and Storage
Design for the cloud is one other space the place Rockset and ClickHouse diverge. ClickHouse is obtainable as software program, which could be self-managed on-premises or on cloud infrastructure. A number of distributors additionally supply cloud variations of ClickHouse. Rockset is designed solely for the cloud and is obtainable as a totally managed cloud service.
ClickHouse makes use of a shared-nothing structure, the place compute and storage are tightly coupled. This helps cut back rivalry and enhance efficiency as a result of every node within the cluster processes the info in its native storage. That is additionally a design that has been utilized by well-known knowledge warehouses like Teradata and Vertica.
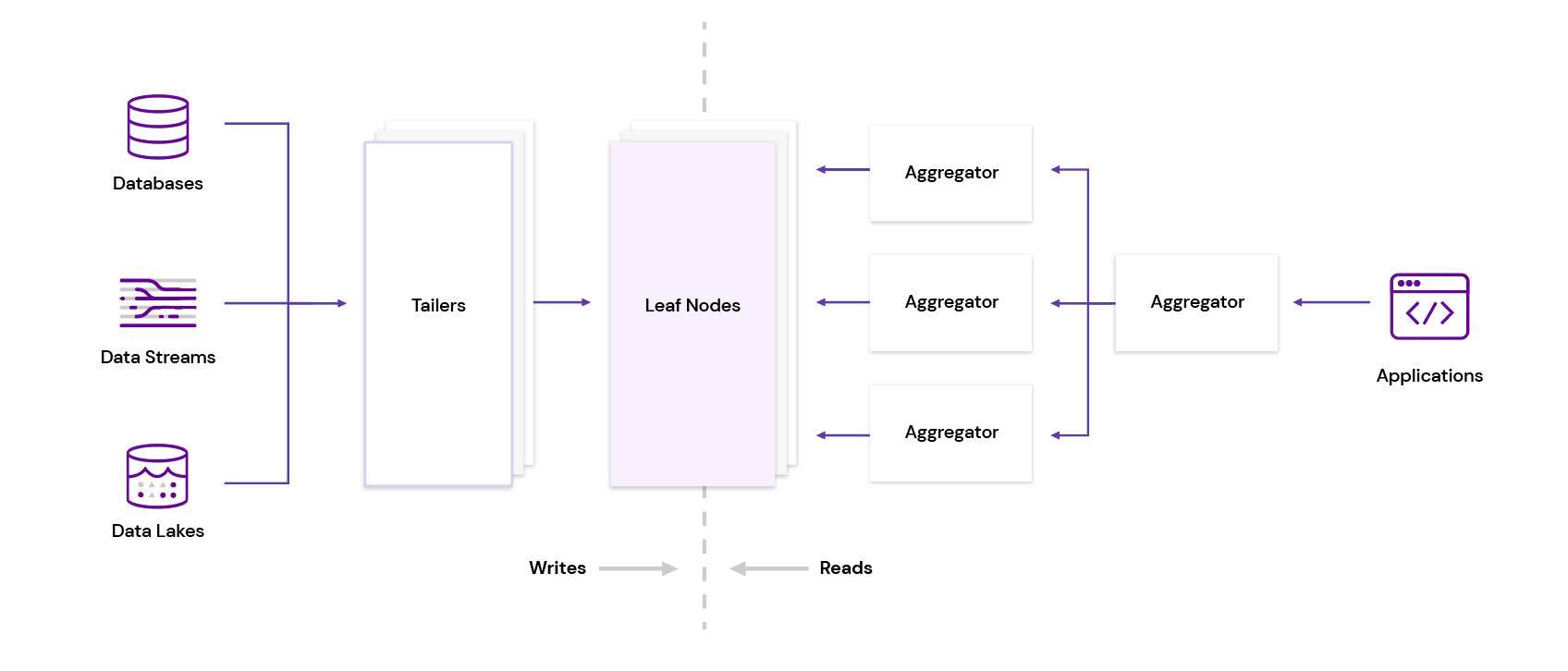
Rockset adopts an Aggregator-Leaf-Tailer (ALT) structure, popularized by net corporations like Fb, LinkedIn and Google. Tailers fetch new knowledge from knowledge sources, Leaves index and retailer the info and Aggregators execute queries in distributed trend. Not solely does Rockset separate compute and storage, it additionally disaggregates ingest and question compute, so every tier on this structure could be scaled independently.
Within the following sections, we look at how a few of these architectural variations influence the capabilities of Rockset and ClickHouse.
Knowledge Ingestion
Streaming vs Batch Ingestion
Whereas ClickHouse provides a number of methods to combine with Kafka to ingest occasion streams, together with a local connector, ClickHouse ingests knowledge in batches. For a column retailer to deal with excessive ingest charges, it must load knowledge in sufficiently massive batches as a way to decrease overhead and maximize columnar compression. ClickHouse documentation recommends inserting knowledge in packets of no less than 1000 rows, or not more than a single request per second. This implies customers must configure their streams to batch knowledge forward of loading into ClickHouse.
Rockset has native connectors that ingest occasion streams from Kafka and Kinesis and CDC streams from databases like MongoDB, DynamoDB, Postgres and MySQL. In all these circumstances, Rockset ingests on a per-record foundation, with out requiring batching, as a result of Rockset is designed to make real-time knowledge accessible as rapidly as doable. Within the case of streaming ingest, it usually takes 1-2 seconds from when knowledge is produced to when it’s queryable in Rockset.
Knowledge Mannequin
Most often, ClickHouse would require customers to specify a schema for any desk they create. To assist make this simpler, ClickHouse lately launched larger skill to deal with semi-structured knowledge utilizing the JSON Object sort. That is coupled with the added functionality to deduce the schema from the JSON, utilizing a subset of the entire rows within the desk. Dynamically inferred columns have some limitations, similar to the shortcoming for use as major or kind keys, so customers will nonetheless must configure some degree of specific schema definition for optimum efficiency.
Rockset will carry out schemaless ingestion for all incoming knowledge, and can settle for fields with blended varieties, nested objects and arrays, sparse fields and null values with out the person having to carry out any guide specification. Rockset robotically generates the schema based mostly on the precise fields and kinds current within the assortment, not on a subset of the info.
ClickHouse knowledge is normally denormalized in order to keep away from having to do JOINs, and customers have commented that the info preparation wanted to take action could be troublesome. In distinction, there isn’t any suggestion to denormalize knowledge in Rockset, as Rockset can deal with JOINs effectively.
Updates and Deletes
As talked about briefly within the Structure part, ClickHouse writes knowledge to immutable recordsdata, known as “components.” Whereas this design helps ClickHouse obtain sooner reads and writes, it does so at the price of replace efficiency.
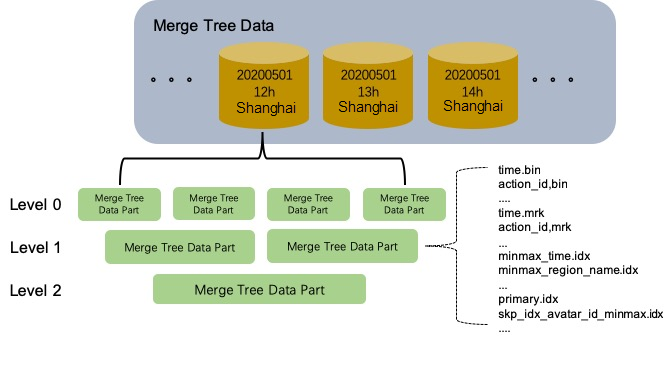
ClickHouse helps replace and delete operations, which it refers to as mutations. They don’t instantly replace or delete the info however as an alternative rewrite and merge the info components asynchronously. Any queries that run whereas an asynchronous mutation is in progress might get a mixture of knowledge from mutated and non-mutated components.
As well as, these mutations can get costly, as even small adjustments will trigger massive rewrites of whole components. ClickHouse documentation states that these are heavy operations and don’t advise that they be used continuously. Because of this, database CDC streams, which regularly include updates and deletes, are dealt with much less effectively by ClickHouse.
In distinction, all paperwork saved in a Rockset assortment are mutable and could be up to date on the area degree, even when these fields are deeply nested inside arrays and objects. Solely the fields in a doc which might be a part of an replace request must be reindexed, whereas the remainder of the fields within the doc stay untouched.
Rockset makes use of RocksDB, a high-performance key-value retailer that makes mutations trivial. RocksDB helps atomic writes and deletes throughout totally different keys. As a consequence of its design, Rockset is among the few real-time analytics databases that may effectively ingest from database CDC streams.
Ingest Transformations and Rollups
It’s helpful to have the ability to remodel and rollup streaming knowledge as it’s being ingested. ClickHouse has a number of storage engines that may pre-aggregate knowledge. The SummingMergeTree sums rows that correspond to the identical major key and shops the end result as a single row. The AggregatingMergeTree is comparable and applies mixture features to rows with the identical major key to supply a single row as its end result.
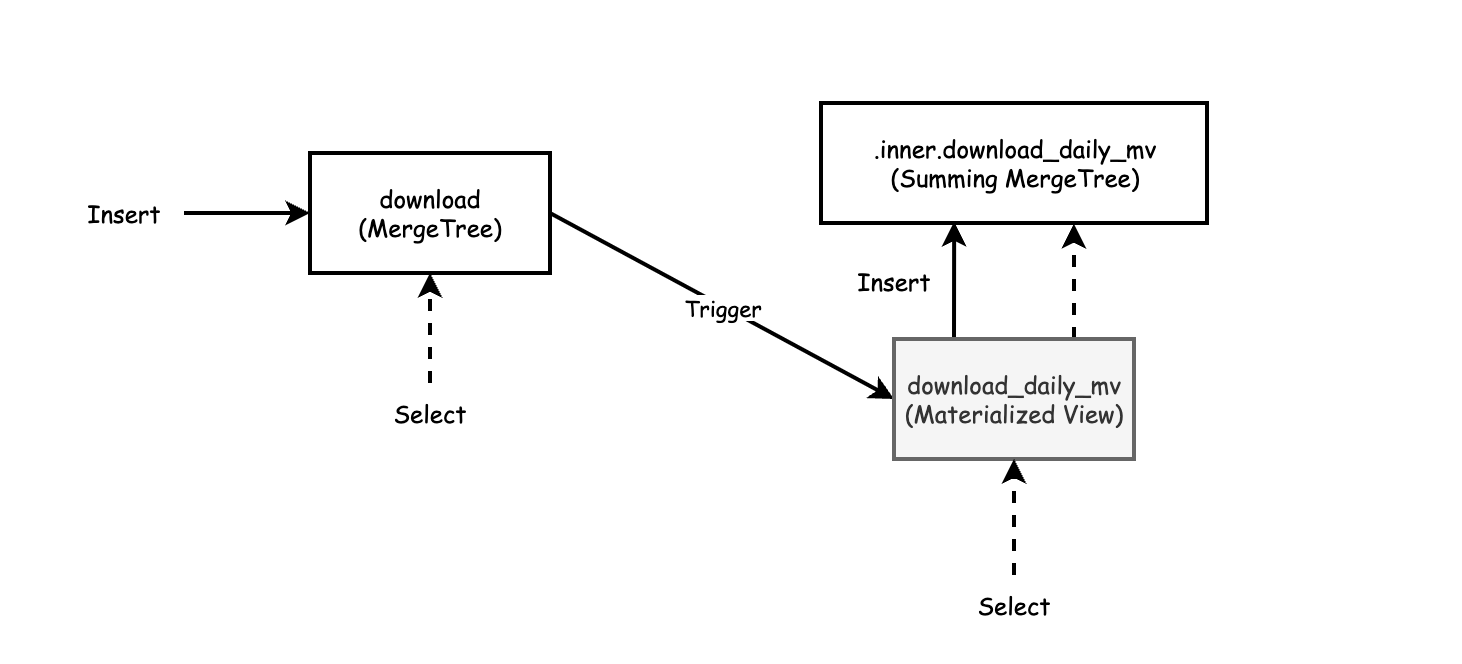
Rockset helps SQL transformations that apply to all paperwork on the level of ingestion. Customers have the flexibility to specify many extra kinds of transformations by using SQL. Widespread makes use of for ingest transformation embody dropping fields, area masking and hashing, and kind coercion.
Rollups in Rockset are a particular sort of transformation that aggregates knowledge upon ingest. Utilizing rollups reduces storage measurement and improves question efficiency as a result of solely the aggregated knowledge is saved and queried.
Queries and Efficiency
Indexing
ClickHouse’s efficiency stems primarily from storage optimizations similar to column orientation, aggressive compression and ordering of knowledge by major key. ClickHouse does use indexing to hurry up queries as effectively, however in a extra restricted trend as in comparison with its storage optimizations.
Main indexes in ClickHouse are sparse indexes. They don’t index each row however as an alternative have one index entry per group of rows. As a substitute of returning single rows that match the question, the sparse index is used to find teams of rows which might be doable matches.
Equally, ClickHouse makes use of secondary indexes, generally known as knowledge skipping indexes, to allow ClickHouse to skip studying blocks that won’t match the question. ClickHouse then scans by the lowered knowledge set to finish executing the question.
Rockset optimizes for compute effectivity, so indexing is the principle driver behind its question pace. Rockset’s Converged Index combines a row index, columnar index and inverted index. This enables Rockset’s SQL engine to make use of indexing optimally to speed up varied sorts of analytical queries, from extremely selective queries to large-scale aggregations. The Converged Index can also be a overlaying index, that means all queries could be resolved solely by the index, with none extra lookup.
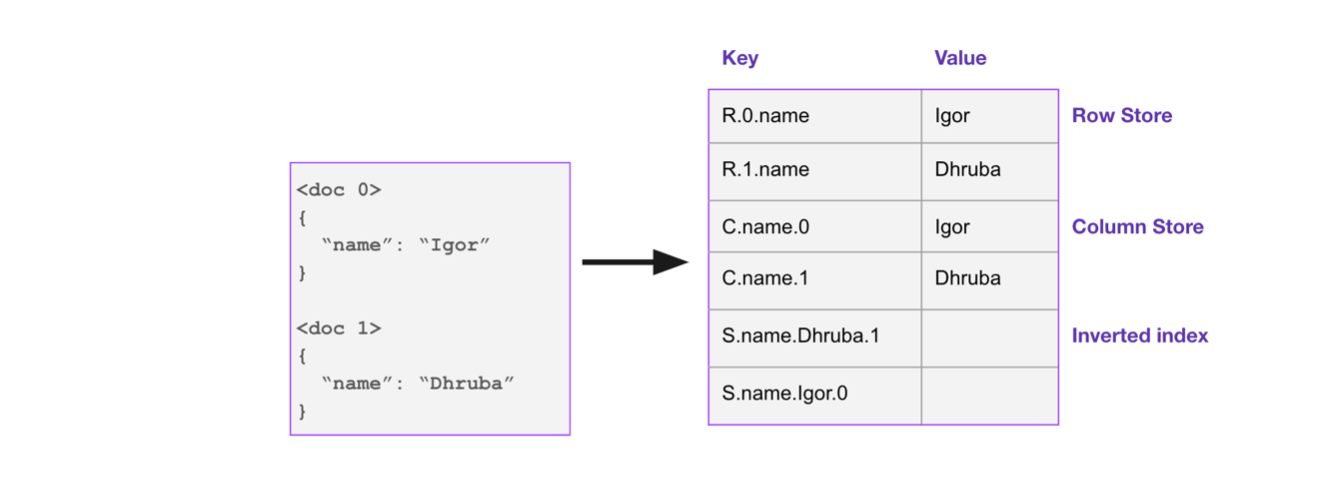
There’s a massive distinction in how indexing is managed in ClickHouse and Rockset. In ClickHouse, the onus is on the person to grasp what indexes are wanted as a way to configure major and secondary indexes. Rockset, by default, indexes all the info that’s ingested within the alternative ways supplied by the Converged Index.
Joins
Whereas ClickHouse helps JOIN performance, many customers report efficiency challenges with JOINs, significantly on massive tables. ClickHouse doesn’t have the flexibility to optimize these JOINs successfully, so options, like denormalizing knowledge beforehand to keep away from JOINs, are advisable.
In supporting full-featured SQL, Rockset was designed with JOIN efficiency in thoughts. Rockset partitions the JOINs, and these partitions run in parallel on distributed Aggregators that may be scaled out if wanted. It additionally has a number of methods of performing JOINs:
- Hash Be a part of
- Nested loop Be a part of
- Broadcast Be a part of
- Lookup Be a part of
The power to JOIN knowledge in Rockset is especially helpful when analyzing knowledge throughout totally different database programs and stay knowledge streams. Rockset can be utilized, for instance, to JOIN a Kafka stream with dimension tables from MySQL. In lots of conditions, pre-joining the info just isn’t an choice as a result of knowledge freshness is necessary or the flexibility to carry out advert hoc queries is required.
Operations
Cluster Administration
ClickHouse clusters could be run in self-managed mode or by an organization that commercializes ClickHouse as a cloud service. In a self-managed cluster, ClickHouse customers might want to set up and configure the ClickHouse software program in addition to required providers like ZooKeeper or ClickHouse Keeper. The cloud model will assist take away a number of the {hardware} and software program provisioning burden, however customers nonetheless must configure nodes, shards, software program variations, replication and so forth. Customers must intervene to improve the cluster, throughout which they could expertise downtime or efficiency degradation.
In distinction, Rockset is totally managed and serverless. The idea of clusters and servers is abstracted away, so no provisioning is required and customers would not have to handle any infrastructure themselves. Software program upgrades occur within the background, so customers can simply reap the benefits of the newest model of software program.
Scaling and Rebalancing
Whereas it’s pretty simple to get began with the single-node model of ClickHouse, scaling the cluster to fulfill efficiency and storage wants takes some effort. For example, establishing distributed ClickHouse includes making a shard desk on every particular person server after which defining the distributed view through one other create command.
As mentioned within the Structure overview, compute and storage are sure to one another in ClickHouse nodes and clusters. Customers must scale each compute and storage in fastened ratios and lack the pliability to scale sources independently. This may end up in useful resource utilization that’s suboptimal, the place both compute or storage is overprovisioned.
The tight coupling of compute and storage additionally provides rise to conditions the place imbalances or hotspots can happen. A typical state of affairs arises when including nodes to a ClickHouse cluster, which requires rebalancing of knowledge to populate the newly added nodes. ClickHouse documentation calls out that ClickHouse clusters usually are not elastic as a result of they don’t assist automated shard rebalancing. As a substitute, rebalancing is a extremely concerned course of that may embody manually weighting writes to bias the place new knowledge is written, guide relocation of current knowledge partitions, and even copying and exporting knowledge to a brand new cluster.
One other facet impact of the dearth of compute-storage separation is that a lot of small queries can have an effect on your entire cluster. ClickHouse recommends bi-level sharding to restrict the influence of those small queries.
Scaling in Rockset includes much less effort due to its separation of compute and storage. Storage autoscales as knowledge measurement grows, whereas compute could be scaled by specifying the Digital Occasion measurement, which governs the entire compute and reminiscence sources accessible within the system. Customers can scale sources independently for extra environment friendly useful resource utilization. No rebalancing is required as Rockset’s compute nodes entry knowledge from its shared storage.
Replication
As a consequence of ClickHouse’s shared-nothing structure, replicas serve a twin goal: availability and sturdiness. Whereas replicas have the potential to assist with question efficiency, they’re important to protect in opposition to the lack of knowledge, so ClickHouse customers should incur the extra price for replication. Configuring replication in ClickHouse additionally includes deploying ZooKeeper or ClickHouse Keeper, ClickHouse’s model of the service, for coordination.
In Rockset’s cloud-native structure, it makes use of cloud object storage to make sure sturdiness with out requiring extra replicas. A number of replicas can assist question efficiency, however these could be introduced on-line on demand, solely when there may be an lively question request. Through the use of cheaper cloud object storage for sturdiness and solely spinning up compute and quick storage for replicas when wanted for efficiency, Rockset can present higher price-performance.
Abstract
Rockset and ClickHouse are each real-time analytics choices for streaming knowledge, however they’re designed fairly otherwise underneath the hood. Their technical variations manifest themselves within the following methods.
- Effectivity of streaming writes and updates: ClickHouse discourages small, streaming writes and frequent updates as it’s constructed on immutable columnar storage. Rockset, as a mutable database, handles streaming ingest, updates and deletes way more effectively, making it appropriate as a goal for occasion and database CDC streams.
- Knowledge and question flexibility: ClickHouse normally requires knowledge to be denormalized as a result of large-scale JOINs don’t carry out effectively. Rockset operates on semi-structured knowledge, with out the necessity for schema definition or denormalization, and helps full-featured SQL together with JOINs.
- Operations: Rockset was constructed for the cloud from day one, whereas ClickHouse is software program that may be deployed on-premises or on cloud infrastructure. Rockset’s disaggregated cloud-native structure minimizes the operational burden on the person and allows fast and straightforward scale out.
For these causes, many organizations have opted to construct on Rockset moderately than put money into heavier knowledge engineering to make different options work. If you want to strive Rockset for your self, you’ll be able to arrange a brand new account and connect with a streaming supply in minutes.