

{kind=link}
Introduction
Retrieval-Augmented Era techniques are revolutionary fashions throughout the fields of pure language processing since they combine the elements of each retrieval and era fashions. On this respect, RAG techniques show to be versatile when the dimensions and number of duties which are being executed by LLMs improve, LLMs present extra environment friendly options to fine-tune by use case. Therefore, when the RAG techniques re-iterate an externally listed data in the course of the era course of, it’s able to producing extra correct contextual and related contemporary data response. However, real-world purposes of RAG techniques provide some difficulties, which could have an effect on their performances, though the potentials are evident. This text focuses on these key challenges and discusses measures which could be taken to enhance efficiency of RAG techniques. That is based mostly on a current discuss given by Dipanjan (DJ) on Enhancing Actual-World RAG Methods: Key Challenges & Sensible Options, within the DataHack Summit 2024.
Understanding RAG Methods
RAG techniques mix retrieval mechanisms with giant language fashions to generate responses leveraging exterior knowledge.

The core elements of a RAG system embody:
- Retrieval: This part includes use of 1 or a number of queries to seek for paperwork, or items of data in a database, or every other supply of data outdoors the system. Retrieval is the method by which an applicable quantity of related data is fetched in order to assist in the formulation of a extra correct and contextually related response.
- LLM Response Era: As soon as the related paperwork are retrieved, they’re fed right into a giant language mannequin (LLM). The LLM then makes use of this data to generate a response that’s not solely coherent but in addition knowledgeable by the retrieved knowledge. This exterior data integration permits the LLM to supply solutions grounded in real-time knowledge, slightly than relying solely on pre-existing data.
- Fusion Mechanism: In some superior RAG techniques, a fusion mechanism could also be used to mix a number of retrieved paperwork earlier than producing a response. This mechanism ensures that the LLM has entry to a extra complete context, enabling it to supply extra correct and nuanced solutions.
- Suggestions Loop: Trendy RAG techniques typically embody a suggestions loop the place the standard of the generated responses is assessed and used to enhance the system over time. This iterative course of can contain fine-tuning the retriever, adjusting the LLM, or refining the retrieval and era methods.
Advantages of RAG Methods
RAG techniques provide a number of benefits over conventional strategies like fine-tuning language fashions. Nice-tuning includes adjusting a mannequin’s parameters based mostly on a particular dataset, which could be resource-intensive and restrict the mannequin’s skill to adapt to new data with out further retraining. In distinction, RAG techniques provide:
- Dynamic Adaptation: RAG techniques permit fashions to dynamically entry and incorporate up-to-date data from exterior sources, avoiding the necessity for frequent retraining. Because of this the mannequin can stay related and correct whilst new data emerges.
- Broad Information Entry: By retrieving data from a big selection of sources, RAG techniques can deal with a broader vary of matters and questions with out requiring in depth modifications to the mannequin itself.
- Effectivity: Leveraging exterior retrieval mechanisms could be extra environment friendly than fine-tuning as a result of it reduces the necessity for large-scale mannequin updates and retraining, focusing as an alternative on integrating present and related data into the response era course of.
Typical Workflow of a RAG System
A typical RAG system operates by way of the next workflow:

- Question Era: The method begins with the era of a question based mostly on the consumer’s enter or context. This question is crafted to elicit related data that can help in crafting a response.
- Retrieval: The generated question is then used to go looking exterior databases or data sources. The retrieval part identifies and fetches paperwork or knowledge which are most related to the question.
- Context Era: The retrieved paperwork are processed to create a coherent context. This context supplies the required background and particulars that can inform the language mannequin’s response.
- LLM Response: Lastly, the language mannequin makes use of the context generated from the retrieved paperwork to supply a response. This response is predicted to be well-informed, related, and correct, leveraging the newest data retrieved.

Key Challenges in Actual-World RAG Methods
Allow us to now look into the important thing challenges in real-world techniques. That is impressed by the well-known paper “Seven Failure Factors When Engineering a Retrieval Augmented Era System” by Barnett et al. as depicted within the following determine. We are going to dive into every of those issues in additional element within the following part with sensible options to sort out these challenges.
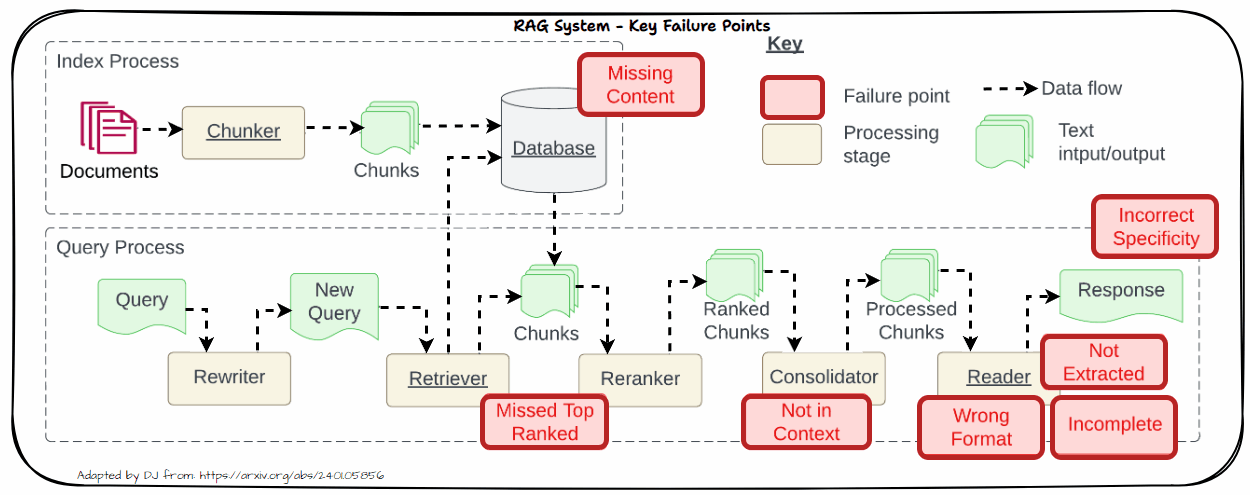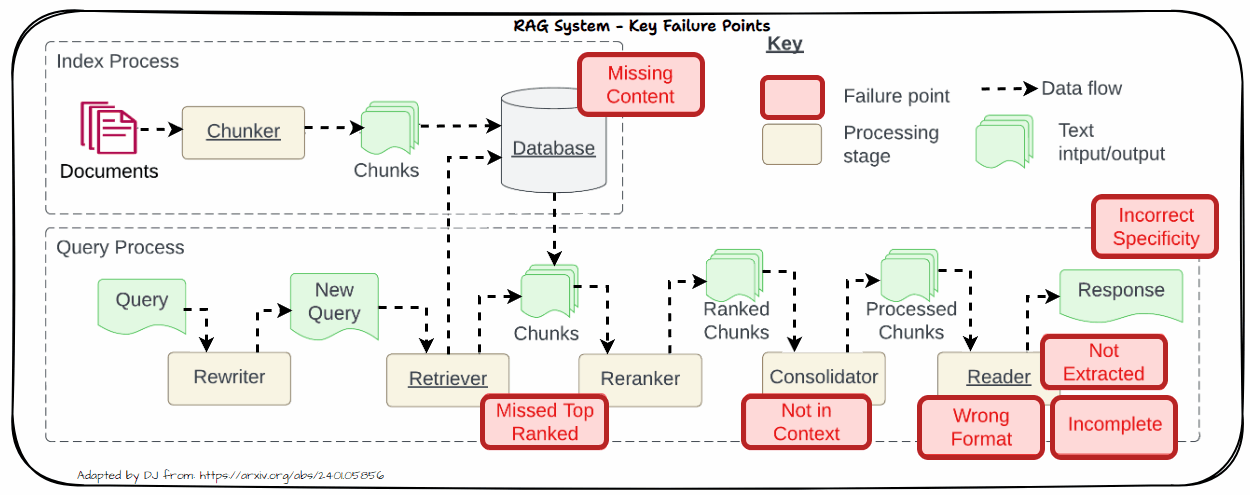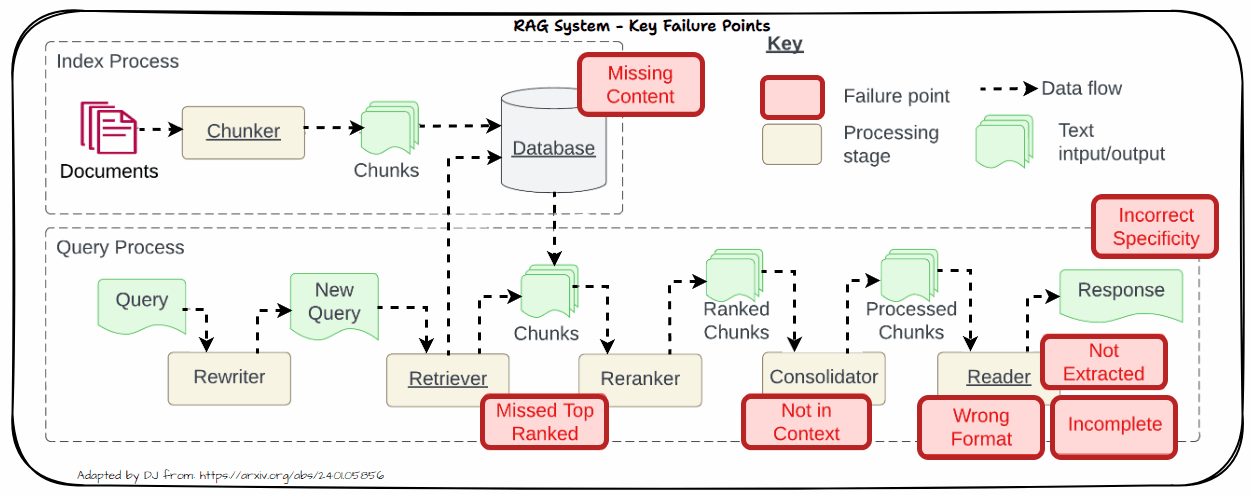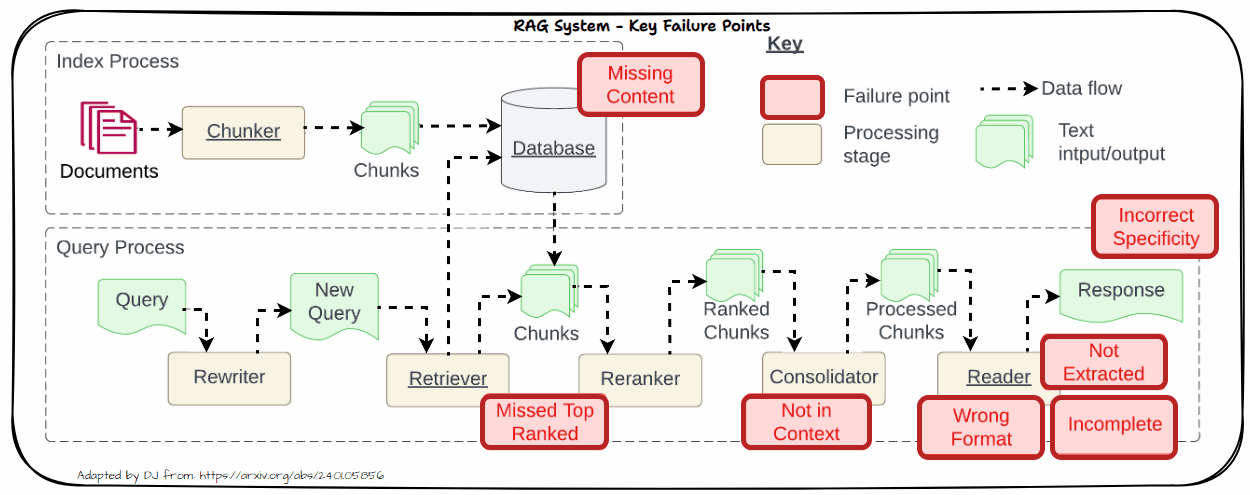
Lacking Content material
One important problem in RAG techniques is coping with lacking content material. This downside arises when the retrieved paperwork don’t comprise enough or related data to adequately tackle the consumer’s question. When related data is absent from the retrieved paperwork, it may result in a number of points like Impression on Accuracy and Relevance.

The absence of essential content material can severely impression the accuracy and relevance of the language mannequin’s response. With out the required data, the mannequin might generate solutions which are incomplete, incorrect, or lack depth. This not solely impacts the standard of the responses but in addition diminishes the general reliability of the RAG system.
Options for Lacking Content material

These are the approaches we will take to sort out challenges with lacking content material.
- Usually updating and sustaining the data base ensures that it comprises correct and complete data. This could scale back the chance of lacking content material by offering the retrieval part with a richer set of paperwork.
- Crafting particular and assertive prompts with clear constraints can information the language mannequin to generate extra exact and related responses. This helps in narrowing down the main focus and bettering the response’s accuracy.
- Implementing RAG techniques with agentic capabilities permits the system to actively search and incorporate exterior sources of data. This method helps tackle lacking content material by increasing the vary of sources and bettering the relevance of the retrieved knowledge.
You possibly can try this pocket book for extra particulars with hands-on examples!
Missed High Ranked
When paperwork that needs to be top-ranked fail to look within the retrieval outcomes, the system struggles to supply correct responses. This downside, generally known as “Missed High Ranked,” happens when necessary context paperwork usually are not prioritized within the retrieval course of. Because of this, the mannequin might not have entry to essential data wanted to reply the query successfully.
Regardless of the presence of related paperwork, poor retrieval methods can forestall these paperwork from being retrieved. Consequently, the mannequin might generate responses which are incomplete or inaccurate because of the lack of crucial context. Addressing this subject includes bettering the retrieval technique to make sure that essentially the most related paperwork are recognized and included within the context.

Not in Context
The “Not in Context” subject arises when paperwork containing the reply are current in the course of the preliminary retrieval however don’t make it into the ultimate context used for producing a response. This downside typically outcomes from ineffective retrieval, reranking, or consolidation methods. Regardless of the presence of related paperwork, flaws in these processes can forestall the paperwork from being included within the last context.
Consequently, the mannequin might lack the required data to generate a exact and correct reply. Enhancing retrieval algorithms, reranking strategies, and consolidation methods is important to make sure that all pertinent paperwork are correctly built-in into the context, thereby enhancing the standard of the generated responses.

The “Not Extracted” subject happens when the LLM struggles to extract the right reply from the offered context, regardless that the reply is current. This downside arises when the context comprises an excessive amount of pointless data, noise, or contradictory particulars. The abundance of irrelevant or conflicting data can overwhelm the mannequin, making it tough to pinpoint the correct reply.
To deal with this subject, it’s essential to enhance context administration by decreasing noise and guaranteeing that the data offered is related and constant. This may assist the LLM give attention to extracting exact solutions from the context.

Incorrect Specificity
When the output response is simply too obscure and lacks element or specificity, it typically outcomes from obscure or generic queries that fail to retrieve the best context. Moreover, points with chunking or poor retrieval methods can exacerbate this downside. Imprecise queries may not present sufficient route for the retrieval system to fetch essentially the most related paperwork, whereas improper chunking can dilute the context, making it difficult for the LLM to generate an in depth response. To deal with this, refine queries to be extra particular and enhance chunking and retrieval strategies to make sure that the context offered is each related and complete.

Options for Missed High Ranked, Not in Context, Not Extracted and Incorrect Specificity
- Use Higher Chunking Methods
- Hyperparameter Tuning – Chunking & Retrieval
- Use Higher Embedder Fashions
- Use Superior Retrieval Methods
- Use Context Compression Methods
- Use Higher Reranker Fashions
You possibly can try this pocket book for extra particulars with hands-on examples!
Experiment with numerous Chunking Methods
You possibly can discover and experiment with numerous chunking methods within the given desk:

Hyperparameter Tuning – Chunking & Retrieval
Hyperparameter tuning performs a crucial function in optimizing RAG techniques for higher efficiency. Two key areas the place hyperparameter tuning could make a big impression are chunking and retrieval.

Chunking
Within the context of RAG techniques, chunking refers back to the technique of dividing giant paperwork into smaller, extra manageable segments. This permits the retriever to give attention to extra related sections of the doc, bettering the standard of the retrieved context. Nevertheless, figuring out the optimum chunk measurement is a fragile stability—chunks which are too small may miss necessary context, whereas chunks which are too giant may dilute relevance. Hyperparameter tuning helps find the best chunk measurement that maximizes retrieval accuracy with out overwhelming the LLM.
Retrieval
The retrieval part includes a number of hyperparameters that may affect the effectiveness of the retrieval course of. As an example, you possibly can fine-tune the variety of retrieved paperwork, the edge for relevance scoring, and the embedding mannequin used to enhance the standard of the context offered to the LLM. Hyperparameter tuning in retrieval ensures that the system is persistently fetching essentially the most related paperwork, thus enhancing the general efficiency of the RAG system.
Higher Embedder Fashions
Embedder fashions assist in changing your textual content into vectors that are utilizing throughout retrieval and search. Don’t ignore embedder fashions as utilizing the unsuitable one can price your RAG System’s efficiency dearly.

Newer Embedder Fashions will likely be educated on extra knowledge and sometimes higher. Don’t simply go by benchmarks, use and experiment in your knowledge. Don’t use industrial fashions if knowledge privateness is necessary. There are a number of embedder fashions accessible, do try the Large Textual content Embedding Benchmark (MTEB) leaderboard to get an thought of the possibly good and present embedder fashions on the market.

Higher Reranker Fashions
Rerankers are fine-tuned cross-encoder transformer fashions. These fashions absorb a pair of paperwork (Question, Doc) and return again a relevance rating.

Fashions fine-tuned on extra pairs and launched lately will normally be higher so do try for the newest reranker fashions and experiment with them.
Superior Retrieval Methods
To deal with the constraints and ache factors in conventional RAG techniques, researchers and builders are more and more implementing superior retrieval methods. These methods intention to boost the accuracy and relevance of the retrieved paperwork, thereby bettering the general system efficiency.
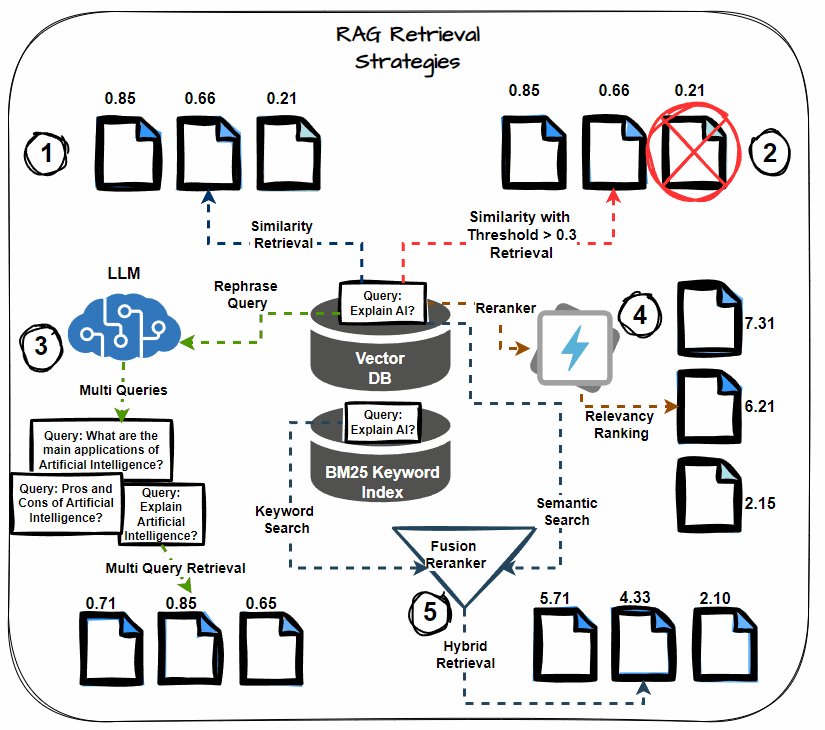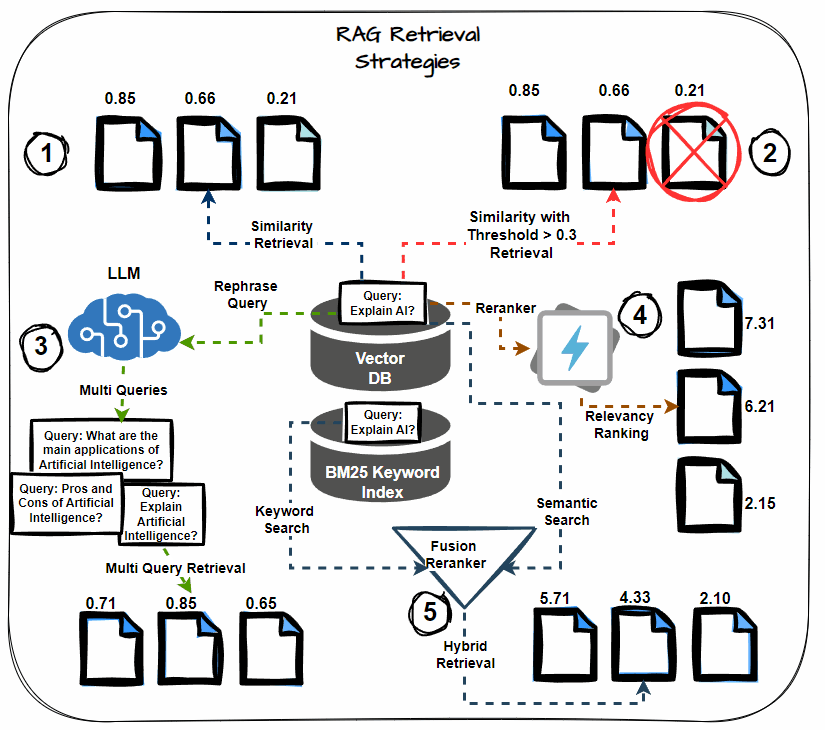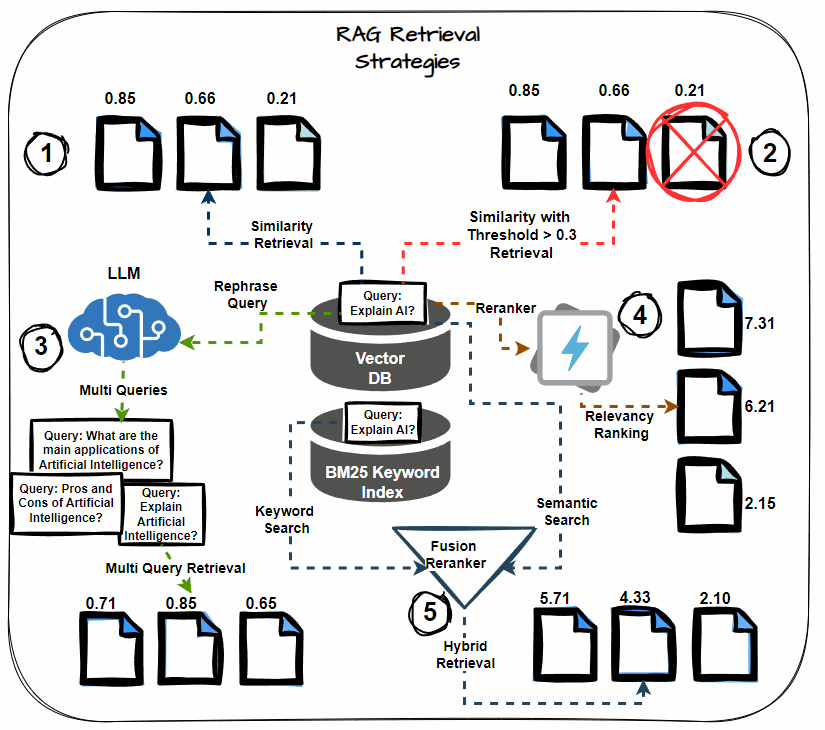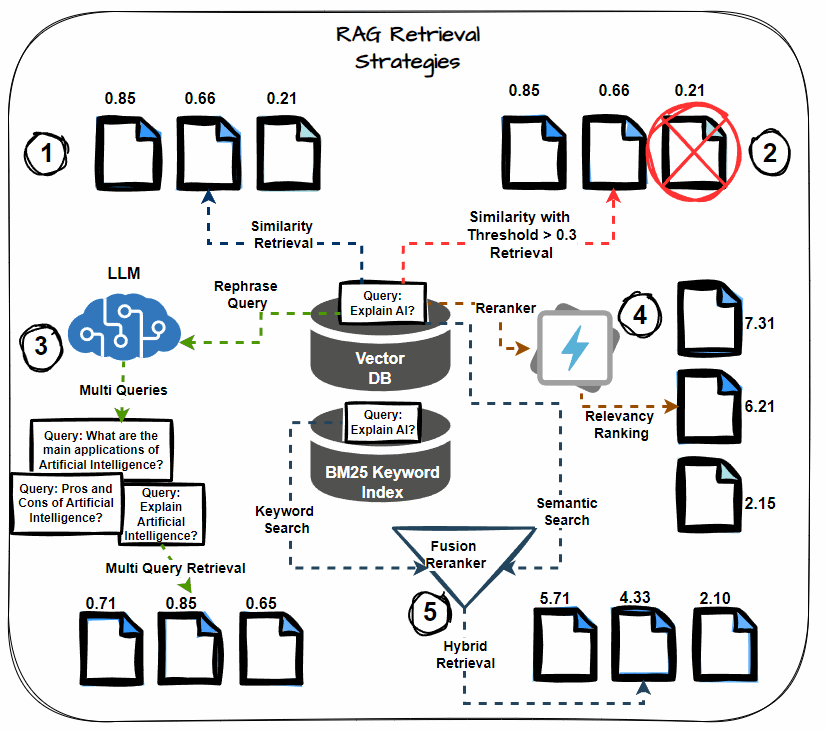
Semantic Similarity Thresholding
This system includes setting a threshold for the semantic similarity rating in the course of the retrieval course of. Think about solely paperwork that exceed this threshold as related, together with them within the context for LLM processing. Prioritize essentially the most semantically related paperwork, decreasing noise within the retrieved context.
Multi-query Retrieval
As an alternative of counting on a single question to retrieve paperwork, multi-query retrieval generates a number of variations of the question. Every variation targets totally different points of the data want, thereby growing the chance of retrieving all related paperwork. This technique helps mitigate the danger of lacking crucial data.
Hybrid Search (Key phrase + Semantic)
A hybrid search method combines keyword-based retrieval with semantic search. Key phrase-based search retrieves paperwork containing particular phrases, whereas semantic search captures paperwork contextually associated to the question. This twin method maximizes the probabilities of retrieving all related data.
Reranking
After retrieving the preliminary set of paperwork, apply reranking methods to reorder them based mostly on their relevance to the question. Use extra subtle fashions or further options to refine the order, guaranteeing that essentially the most related paperwork obtain increased precedence.
Chained Retrieval
Chained retrieval breaks down the retrieval course of into a number of phases, with every stage additional refining the outcomes. The preliminary retrieval fetches a broad set of paperwork. Then, subsequent phases refine these paperwork based mostly on further standards, resembling relevance or specificity. This technique permits for extra focused and correct doc retrieval.
Context Compression Strategies
Context compression is a vital approach for refining RAG techniques. It ensures that essentially the most related data is prioritized, resulting in correct and concise responses. On this part, we’ll discover two major strategies of context compression: prompt-based compression and filtering. We can even look at their impression on enhancing the efficiency of real-world RAG techniques.

Immediate-Based mostly Compression
Immediate-based compression includes utilizing language fashions to determine and summarize essentially the most related elements of retrieved paperwork. This system goals to distill the important data and current it in a concise format that’s most helpful for producing a response. Advantages of this method embody:
- Improved Relevance: By specializing in essentially the most pertinent data, prompt-based compression enhances the relevance of the generated response.
- Limitations: Nevertheless, this technique might also have limitations, resembling the danger of oversimplifying advanced data or shedding necessary nuances throughout summarization.
Filtering
Filtering includes eradicating total paperwork from the context based mostly on their relevance scores or different standards. This system helps handle the amount of data and be sure that solely essentially the most related paperwork are thought of. Potential trade-offs embody:
- Lowered Context Quantity: Filtering can result in a discount within the quantity of context accessible, which could have an effect on the mannequin’s skill to generate detailed responses.
- Elevated Focus: However, filtering helps keep give attention to essentially the most related data, bettering the general high quality and relevance of the response.
Mistaken Format
The “Mistaken Format” downside happens when an LLM fails to return a response within the specified format, resembling JSON. This subject arises when the mannequin deviates from the required construction, producing output that’s improperly formatted or unusable. As an example, in the event you anticipate a JSON format however the LLM supplies plain textual content or one other format, it disrupts downstream processing and integration. This downside highlights the necessity for cautious instruction and validation to make sure that the LLM’s output meets the desired formatting necessities.

Options for Mistaken Format
- Highly effective LLMs have native assist for response codecs e.g OpenAI helps JSON outputs.
- Higher Prompting and Output Parsers
- Structured Output Frameworks
You possibly can try this pocket book for extra particulars with hands-on examples!
For instance fashions like GPT-4o have native output parsing assist like JSON which you’ll allow as proven within the following code snapshot.

Incomplete
The “Incomplete” downside arises when the generated response lacks crucial data, making it incomplete. This subject typically outcomes from poorly worded questions that don’t clearly convey the required data, insufficient context retrieved for the response, or ineffective reasoning by the mannequin.
Incomplete responses can stem from a wide range of sources, together with ambiguous queries that fail to specify the required particulars, retrieval mechanisms that don’t fetch complete data, or reasoning processes that miss key components. Addressing this downside includes refining query formulation, bettering context retrieval methods, and enhancing the mannequin’s reasoning capabilities to make sure that responses are each full and informative.

Answer for Incomplete
- Use Higher LLMs like GPT-4o, Claude 3.5 or Gemini 1.5
- Use Superior Prompting Strategies like Chain-of-Thought, Self-Consistency
- Construct Agentic Methods with Software Use if needed
- Rewrite Consumer Question and Enhance Retrieval – HyDE
HyDE is an attention-grabbing method the place the thought is to generate a Hypothetical reply to the given query which is probably not factually completely right however would have related textual content components which may help retrieve the extra related paperwork from the vector database as in comparison with retrieving utilizing simply the query as depicted within the following workflow.

Different Enhancements from Latest Analysis Papers
Allow us to now look onto few enhancements from current analysis papers which have really labored.
RAG vs. Lengthy Context LLMs
Lengthy-context LLMs typically ship superior efficiency in comparison with Retrieval-Augmented Era (RAG) techniques attributable to their skill to deal with actually lengthy paperwork and generate detailed responses with out worrying about all the info pre-processing wanted for RAG techniques. Nevertheless, they arrive with excessive computing and value calls for, making them much less sensible for some purposes. A hybrid method provides an answer by leveraging the strengths of each fashions. On this technique, you first use a RAG system to supply a response based mostly on the retrieved context. Then, you possibly can make use of a long-context LLM to assessment and refine the RAG-generated reply if wanted. This technique permits you to stability effectivity and value whereas guaranteeing high-quality, detailed responses when needed as talked about within the paper, Retrieval Augmented Era or Lengthy-Context LLMs? A Complete Research and Hybrid Method, Zhuowan Li et al.

RAG vs Lengthy Context LLMs – Self-Router RAG
Let’s take a look at a sensible workflow of how you can implement the answer proposed within the above paper. In an ordinary RAG circulate, the method begins with retrieving context paperwork from a vector database based mostly on a consumer question. The RAG system then makes use of these paperwork to generate a solution whereas adhering to the offered data. If the answerability of the question is unsure, an LLM decide immediate determines if the question is answerable or unanswerable based mostly on the context. For instances the place the question can’t be answered satisfactorily with the retrieved context, the system employs a long-context LLM. This LLM makes use of the whole context paperwork to supply an in depth response, guaranteeing that the reply relies solely on the offered data.

Agentic Corrective RAG
Agentic Corrective RAG attracts inspiration from the paper, Corrective Retrieval Augmented Era, Shi-Qi Yan et al. the place the thought is to first do a traditional retrieval from a vector database in your context paperwork based mostly on a consumer question. Then as an alternative of the usual RAG circulate, we assess how related are the retrieved paperwork to reply the consumer question utilizing an LLM-as-Decide circulate and if there are some irrelevant paperwork or no related paperwork, we do an internet search to get stay data from the online for the consumer question earlier than following the traditional RAG circulate as depicted within the following determine.

First, retrieve context paperwork from the vector database based mostly on the enter question. Then, use an LLM to evaluate the relevance of those paperwork to the query. If all paperwork are related, proceed with out additional motion. If some paperwork are ambiguous or incorrect, rephrase the question and search the online for higher context. Lastly, ship the rephrased question together with the up to date context to the LLM for producing the response. That is proven intimately within the following sensible workflow illustration.

Agentic Self-Reflection RAG
Agentic Self-Reflection RAG (SELF-RAG) introduces a novel method that enhances giant language fashions (LLMs) by integrating retrieval with self-reflection. This framework permits LLMs to dynamically retrieve related passages and mirror on their very own responses utilizing particular reflection tokens, bettering accuracy and adaptableness. Experiments reveal that SELF-RAG surpasses conventional fashions like ChatGPT and Llama2-chat in duties resembling open-domain QA and reality verification, considerably boosting factuality and quotation precision. This was proposed within the paper Self-RAG: Studying to Retrieve, Generate, and Critique by way of Self-Reflection, Akari Asai et al.

A sensible implementation of this workflow is depicted within the following illustration the place we do a traditional RAG retrieval, then use an LLM-as-Decide grader to evaluate doc related, do net searches or question rewriting and retrieval if wanted to get extra related context paperwork. The following step includes producing the response and once more utilizing LLM-as-Decide to mirror on the generated reply and ensure it solutions the query and isn’t having any hallucinations.

Conclusion
Enhancing real-world RAG techniques requires addressing a number of key challenges, together with lacking content material, retrieval issues, and response era points. Implementing sensible options, resembling enriching the data base and using superior retrieval methods, can considerably improve the efficiency of RAG techniques. Moreover, refining context compression strategies additional contributes to bettering system effectiveness. Steady enchancment and adaptation are essential as these techniques evolve to fulfill the rising calls for of assorted purposes. Key takeaways from the discuss could be summarized within the following determine.

Future analysis and improvement efforts ought to give attention to bettering retrieval techniques, discover the above talked about methodologies. Moreover, exploring new approaches like Agentic AI may help optimize RAG techniques for even higher effectivity and accuracy.
It’s also possible to consult with the GitHub hyperlink to know extra.
Steadily Requested Questions
A. RAG techniques mix retrieval mechanisms with giant language fashions to generate responses based mostly on exterior knowledge.
A. They permit fashions to dynamically incorporate up-to-date data from exterior sources with out frequent retraining.
A. Widespread challenges embody lacking content material, retrieval issues, response specificity, context overload, and system latency.
A. Options embody higher knowledge cleansing, assertive prompting, and leveraging agentic RAG techniques for stay data.
A. Methods embody semantic similarity thresholding, multi-query retrieval, hybrid search, reranking, and chained retrieval.
My identify is Ayushi Trivedi. I’m a B. Tech graduate. I’ve 3 years of expertise working as an educator and content material editor. I’ve labored with numerous python libraries, like numpy, pandas, seaborn, matplotlib, scikit, imblearn, linear regression and plenty of extra. I’m additionally an creator. My first guide named #turning25 has been revealed and is on the market on amazon and flipkart. Right here, I’m technical content material editor at Analytics Vidhya. I really feel proud and glad to be AVian. I’ve a terrific crew to work with. I like constructing the bridge between the know-how and the learner.