

{kind=link}
Have you ever ever discovered your self observing a mannequin analysis tutorial from an information science course, making an attempt arduous to make sense of all the straightforward analysis metrics definitions and formulation? Or maybe you’ve discovered your self continuously forgetting the very basic equations when you find yourself getting ready to your knowledge scientist/NLP/AI engineer interviews?
I’ve been there. Most studying supplies dive straight into formulation and mathematical definitions. Some are with lovely visualizations, which is nice for fast, cheatsheet reference throughout knowledge pipeline implementation or interview prep. Nonetheless, this method typically leaves us cramming these formulation as trivia flashcards, with out understanding what they really imply.
After studying this text, it is possible for you to to:
- Construct an intuitive understanding of analysis metrics earlier than diving into formulation
- Clarify why total accuracy might be deceptive
- Join complicated metrics, like BLEU and ROUGE, to basic analysis ideas
Whether or not you’re an information scientist simply beginning with NLP, a part of a newly fashioned AI workforce, or just searching for a clearer understanding of analysis fundamentals, this text takes a distinct method. As an alternative of specializing in the formulation, we’ll assist you to construct your instinct one step at a time.
Begin with The “Naive” Query
Think about you got a dataset with 100 outputs from a language mannequin, together with an ideal floor reality dataset (containing truthful reference outputs). You’re requested to guage it. First query that involves your thoughts:
“How good is the mannequin?”
That’s a great query, and this may be even higher if we break down what “good” truly means in concrete phrases.
Total Accuracy
Probably the most intuitive reply could be: “The mannequin ought to get all issues proper. Extra right outputs = higher mannequin, fewer errors = higher efficiency.” If we assume actual matches with our floor reality, this provides us:
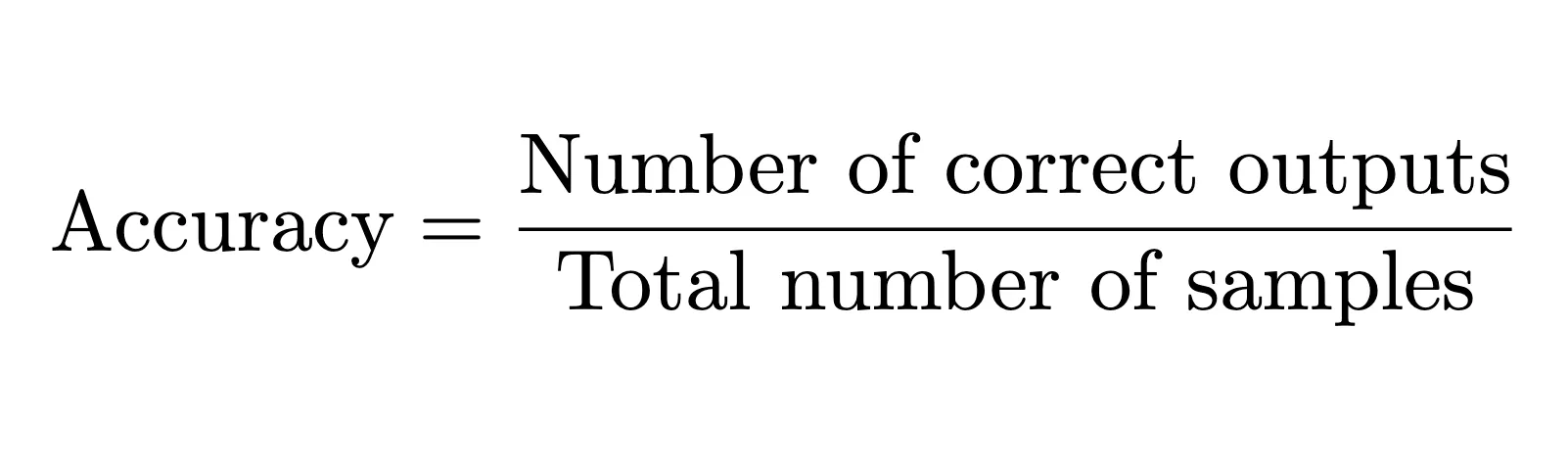
Getting 100% accuracy could be too perfect, and in the actual world, fashions make errors.
Nonetheless, a mannequin can nonetheless be glorious even with seemingly poor total accuracy.
Actual-World State of affairs: Hate Speech Detection
Let’s add some background info to your dataset. Think about we’re within the strategy of constructing a system to detect hate speech in Reddit feedback. Our system will deal with catching unfavourable (hateful) content material, relatively than completely classifying constructive or impartial feedback, primarily based on our mannequin outputs.
Right here’s a pattern of what we’d see:
| Pattern | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Floor reality | unfavourable | constructive | impartial | impartial | impartial | constructive | unfavourable | constructive | impartial | impartial |
| Mannequin output | unfavourable | impartial | constructive | constructive | constructive | impartial | unfavourable | impartial | constructive | constructive |
Total accuracy: 2/10 = 20%
For those who choose by the rating, it seems horrible. However when you take a more in-depth have a look at the desk, the mannequin efficiently recognized all the two cases of hate speech, which is precisely what we care about for this software. Whereas it fully failed to differentiate between impartial and constructive feedback, it’s catching all of the circumstances that matter most.
This means we want a extra centered analysis method. As an alternative of total accuracy, let’s deal with the particular output we care about. That results in our first supporting query:
“Did the mannequin catch every thing we care about?”
Out of all of the hate speech in our dataset, what fraction did the mannequin efficiently determine?

Is the Metric Good Sufficient?
Now, let’s examine two totally different fashions on the identical job:
| Pattern | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Floor reality | unfavourable | constructive | impartial | impartial | impartial | constructive | unfavourable | constructive | impartial | impartial |
| Mannequin 1 output | unfavourable | impartial | constructive | constructive | constructive | impartial | unfavourable | impartial | constructive | constructive |
| Mannequin 2 output | unfavourable | unfavourable | unfavourable | constructive | unfavourable | impartial | unfavourable | impartial | constructive | constructive |
Utilizing our “catch every thing we care about” metric from above:
Mannequin 1: 2/2 = 100% Mannequin 2: 2/2 = 100%
Each fashions rating perfectly- however wait! This doesn’t inform the entire story. Mannequin 2 is flagging many non-hateful feedback as hate speech—a significant issue that will frustrate customers. That brings us to our subsequent supporting query:
“When the mannequin flags an output that we care about, is it an accurate output?”
Out of all of the hate speech predictions our mannequin made, what fraction had been truly right?

Let’s calculate for each fashions:
Mannequin 1: 2/2 = 100% Mannequin 2: 2/5 = 40%
As we are able to see, Mannequin 1 performs significantly better than Mannequin 2, because it doesn’t generate any false alarms for hate speech detection.
Can This Substitute Our First Metric?
Let’s take a look at this with a 3rd mannequin:
| Pattern | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Floor reality | unfavourable | constructive | impartial | impartial | impartial | constructive | unfavourable | constructive | impartial | impartial |
| Mannequin 1 output | unfavourable | impartial | constructive | constructive | constructive | impartial | unfavourable | impartial | constructive | constructive |
| Mannequin 3 output | unfavourable | impartial | constructive | constructive | constructive | impartial | constructive | impartial | constructive | constructive |
Mannequin 1: 2/2 = 100% Mannequin 3: 1/1 = 100%
Each fashions rating completely on our second metric, however we are able to study from the dataset that Mannequin 3 solely caught half of the particular hate speech in our dataset.
This tells us each metrics matter—we want fashions that may catch all of the reference circumstances we care about, but all of the outputs of that sort are right.
In apply, it’s uncommon for a mannequin to realize 100% on each metrics, and we would like a single metric that balances each issues. Since each metrics are charges (fractions), we use the harmonic imply relatively than the arithmetic imply to mix them.
The harmonic imply provides equal weight to each metrics and is delicate to low values—if both metric is poor, the mixed rating will likely be poor:
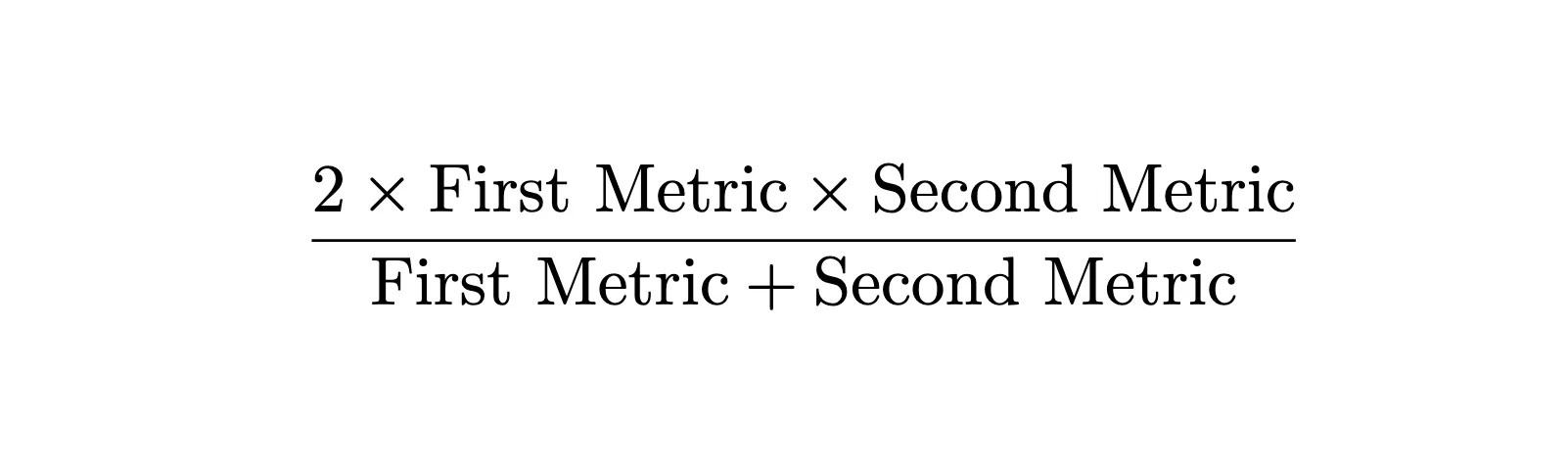
Bringing Them Collectively
Now that we’ve constructed instinct for these ideas, let’s join them to their historic origins:
The primary metric sort is categorized as Recall, and the second metric sort is categorized as Precision. Each had been first coined by Cyril Cleverdon within the Sixties in the course of the Cranfield information-retrieval experiments.
He wanted methods to quantify how effectively doc retrieval techniques carried out: recall measured “completeness” (did we discover all of the related paperwork?), whereas precision measured the “exactness” of retrieved paperwork (had been the retrieved paperwork truly related?),
The mixed harmonic imply, which known as the F1 Rating, comes from the F_β effectiveness perform outlined by C. J. van Rijsbergen. The “F1” is just the case the place β = 1, giving equal weight to precision and recall. This metric was later popularized by the 1992 MUC-4 analysis convention and have become commonplace.
When Precise Matches Aren’t Sufficient
Our hate speech instance is a classification drawback, and we validate output through actual match. However many NLP duties contain extra nuanced analysis the place actual matches don’t seize the total image.
Take into account these eventualities:
- Machine Translation: “The cat sat on the mat” vs “A cat was sitting on the mat” – totally different phrases, comparable that means
- Textual content Summarization: There are lots of alternative ways to summarize the identical doc
- Data Retrieval: Output is a ranked record of paperwork, not a single merchandise
For these duties, we are able to’t merely use a binary methodology (i.e., true/false) after we validate mannequin outputs. Good translations can use totally different phrases, in addition to good summaries, and the search end result record might not be thought-about a failure if solely the final 2 gadgets within the record had been ranked in another way.
This implies our analysis formulation must evolve and mutate to suit these extra complicated eventualities. Let’s discover just a few examples:
Data Retrieval: Evaluating Ranked Lists
As we talked about, we’re not evaluating a single prediction—we’re evaluating a complete ranked record. Each our basic questions ought to apply, with a twist – “Out of all of the related paperwork, what number of seem within the high Okay outcomes?” and “Out of the primary Okay outcomes, what number of are literally related?”.
Instance: Looking for “machine studying papers”
- Prime 10 outcomes: 7 are literally about ML, 3 are irrelevant
- Complete related papers in database: 100 papers complete
- First metric @10: 7/100 = 7% (we’re solely catching 7% of all of the machine studying papers)
- Second metric @10: 7/10 = 70% (after we present a high 10 end result, we’re proper 70% of the time)
This is identical considering as our hate speech detection. The “@10” half simply acknowledges that customers sometimes solely have a look at the primary web page of outcomes:

Translation Duties: BLEU Rating
Keep in mind our second supporting query – “When the mannequin flags an output that we care about, is it an accurate output?” For translation, this turns into: “When our mannequin produces phrases, what number of have the same that means to the reference translation?”
BLEU applies our second metric’s considering to translation by asking: “What fraction of the phrases and phrases in our translation truly seem within the reference?”
Instance:
- Reference: “The cat sat on the mat”
- Mannequin output: “A cat was sitting on the mat”
- Phrase-level matches: cat, on, the, mat all seem in reference (4 out of 6 mannequin phrases = 67%)
- Phrase-level matches: “on the”, “the mat” each seem in reference (2 out of 5 potential phrases = 40%)
BLEU builds upon the idea of precision by checking matches at each phrase and phrase ranges—similar to how we checked particular person predictions in our hate speech instance, however now utilized to the interpretation area:
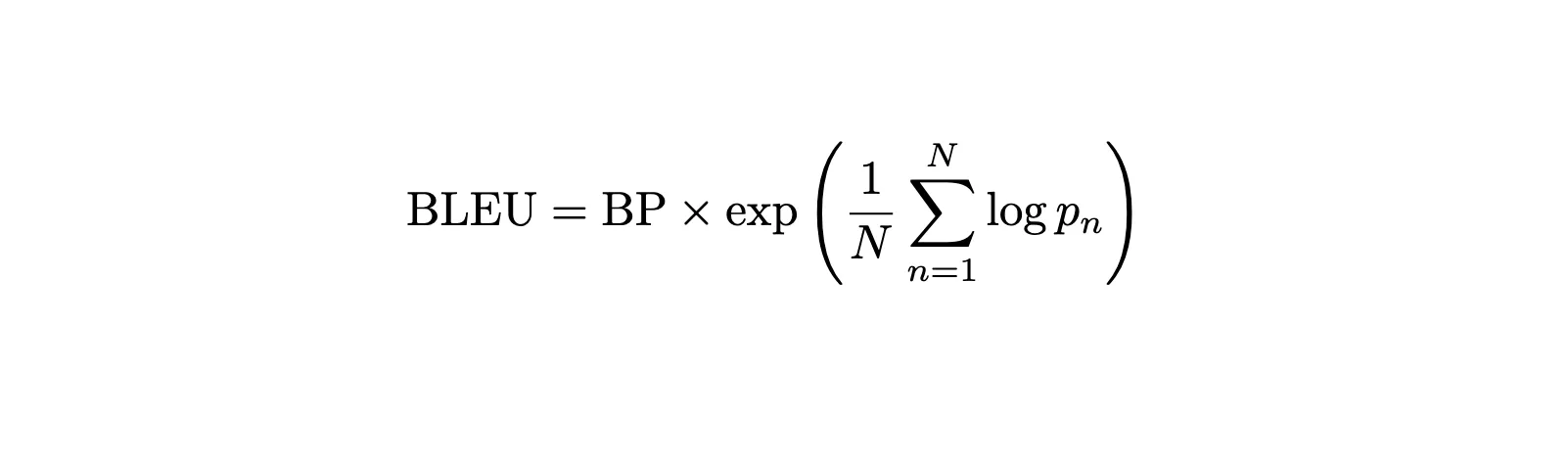
Summarization Duties: ROUGE Rating
Again to our first supporting question- “Did the mannequin catch every thing we care about?” For summarization, this turns into: “Did our abstract seize the important thing info from the reference?”
ROUGE applies our first metric’s considering to summaries, by asking: “What fraction of the vital phrases and ideas from the reference abstract seem in our mannequin’s abstract?”
Instance:
- Reference: “The research exhibits train improves psychological well being”
- Mannequin output: “Train helps psychological well being based on analysis”
- Phrase-level protection: train, psychological, well being seem in mannequin abstract (3 out of seven reference phrases = 43%)
- Idea protection: The core thought “train improves psychological well being” is captured, even with totally different wording
ROUGE focuses on our first metric as a result of a great abstract ought to seize the important info from the reference. The precise wording issues lower than masking the important thing factors.

Word: There are totally different variations of BLEU, ROUGE, and @Okay system, and we is not going to undergo all of the variations and notations right here since it is going to be out of our studying targets and should introduce extra confusion.
Learn extra: Analysis Metrics or Classification Fashions
Conclusion
Understanding analysis metrics doesn’t have to start out with memorizing definitions and formulation. By constructing instinct via sensible eventualities, we are able to see why totally different metrics exist and when to make use of them. For instance, A fraud detection system (recall-focused) wants a distinct analysis than a spam filter (precision-focused).
The subsequent time you encounter an unfamiliar analysis metric, attempt asking: What side of mannequin efficiency is that this making an attempt to seize? What real-world drawback was it designed to resolve?
In our subsequent exploration, we’ll dive into analysis methods together with similarity-based approaches, different judging strategies, and frameworks for dealing with contexts the place “right” is inherently pluralistic.
Any questions? join with me right here
Continuously Requested Questions
A. Accuracy treats all outputs equally. In duties like hate speech detection, we care extra about catching dangerous content material than completely classifying impartial or constructive feedback, so accuracy alone might be deceptive.
A. Recall solutions: “Did we catch every thing we care about?” It’s the fraction of all related gadgets accurately recognized by the mannequin, like discovering all hate speech feedback in a dataset.
A. Precision solutions: “When the mannequin flags one thing, is it proper?” It’s the fraction of flagged gadgets which can be right, lowering false alarms and bettering person belief.
A. F1 combines precision and recall utilizing the harmonic imply, balancing completeness and correctness. A low worth in both metric pulls the F1 down, making it a great single measure of each.
A. BLEU focuses on precision for translations (what number of generated phrases match references), whereas ROUGE focuses on recall for summaries (how a lot reference content material is roofed). Each adapt core metrics to extra complicated NLP outputs.
AI product builder and impartial researcher specializing in conversational AI, NLP, and the analysis and reliability of ML/AI techniques.
Grasp of Utilized Knowledge Science @ College of Michigan.
Designed and deployed manufacturing conversational AI—enterprise chatbots and LLM-powered assistants—bridging analysis with product constraints. His present pursuits embrace rubric-guided human analysis, optimizing retrieval for RAG and agentic workflows, and taking AI from prototype to manufacturing with clear, trustworthy metrics. He additionally printed the Conventional Chinese language version of O’Reilly’s Designing Machine Studying Methods. Contact: [email protected] · arthurcho.notion.website
Login to proceed studying and luxuriate in expert-curated content material.