

{kind=link}
Giant pre-trained generative transformers have demonstrated distinctive efficiency in numerous pure language technology duties, utilizing giant coaching datasets to seize the logic of human language. Nonetheless, adapting these fashions for sure purposes by fine-tuning poses vital challenges. The computational effectivity of fine-tuning relies upon closely on the mannequin dimension, making it pricey for researchers to work on giant fashions. The fine-tuning on smaller datasets poses a danger of catastrophic forgetting, the place the mannequin overfits a particular process area and loses vital data gained throughout pre-training. Attributable to this challenge, reasoning abilities, like compositional generalization and commonsense face issues whereas evaluating the mannequin.
The prevailing strategies embrace prompt-tuning, which entails including tokens or trainable vectors to the enter and optimizing their embeddings. This methodology permits for adaptation to new duties with minimal knowledge, decreasing the chance of catastrophic forgetting. The second methodology is the NeurAlly-Decomposed Oracles (NADO) algorithm, which offers a center floor by a smaller transformer mannequin to manage the bottom mannequin with out altering its parameters. Nonetheless, questions stay about its optimum coaching practices for vital distribution discrepancies and decreasing extra prices related to coaching the NADO module. The final methodology is the GeLaTo Algorithm, an revolutionary framework to reinforce autoregressive textual content technology by integrating tractable probabilistic fashions (TPMs).
A group of researchers from the College of California, Los Angeles, Amazon AGI, and Samsung Analysis America have launched norm-Disentangled NeurAlly-Decomposed Oracles (DiNADO), an improved parameterization of the NADO algorithm. It enhances NADO’s convergence throughout supervised fine-tuning and later levels and focuses on the individuality of world parametric optima. The inefficiency of gradient estimation is dealt with utilizing NADO with sparse indicators from the management sign operate, displaying tips on how to enhance pattern and gradient estimation effectivity. Furthermore, a pure mixture of DiNADO with approaches like LoRA allows base mannequin updates by a contrastive formulation and enhances NADO’s mannequin capability whereas bettering inference-time efficiency.
The DiNADO is evaluated utilizing two most important duties: Formal Machine Translation (FormalMT) and Lexically Constrained Era (LCG). For FormalMT, a proper reference and a binary classifier are used to approximate the formality rating. The LCG process makes use of the CommonGen dataset, which evaluates compositional generalization talents and commonsense reasoning of textual content technology fashions. The experiments are divided into two components:
- Outcomes utilizing a GPT-2-Giant base distribution, evaluated by technology high quality and controllability.
- A pattern effectivity examine on how completely different designs and goal reweighting methods enhance NADO’s pattern effectivity.
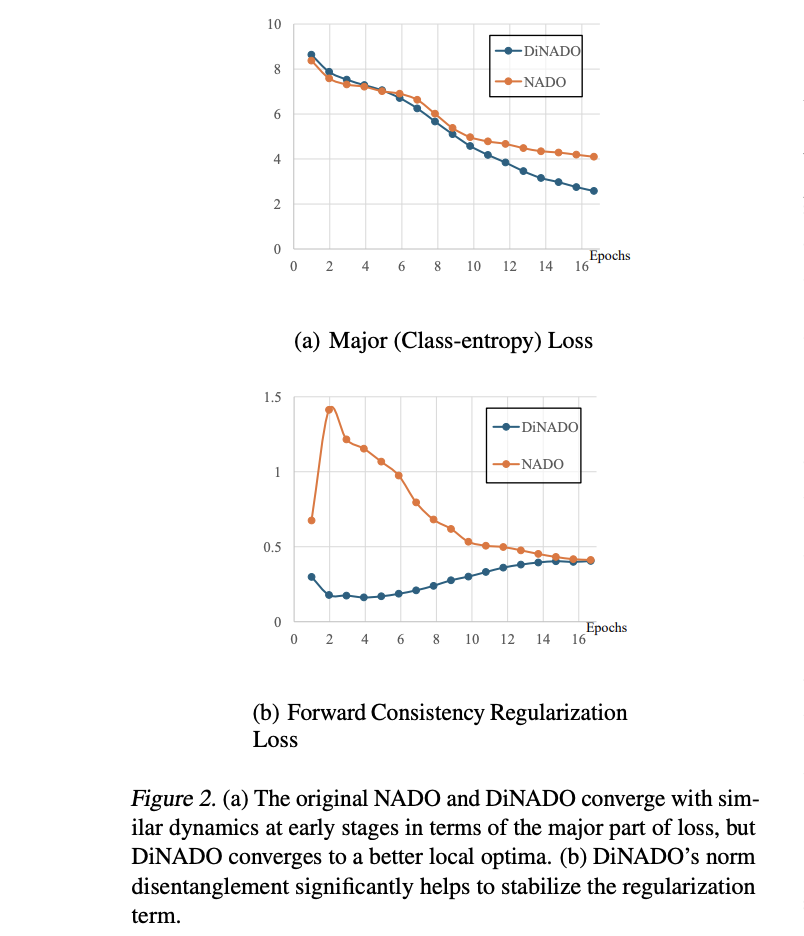
The outcomes show that DiNADO-Mushy outperforms DiNADO-Onerous, because the strict ahead consistency of DiNADO-Onerous can have an effect on the oracle sign’s studying. Bigger capability NADO modules provide enhanced flexibility and controllability with DiNADO-Merge, displaying extra generalizable efficiency. Furthermore, DiNADO’s norm-disentanglement helps management the regularization time period beneath 0.5, making certain that updates within the R operate persistently enhance the composed distribution. This contrasts with vanilla NADO, the place divergence within the regularization time period can have an effect on efficiency enhancement, highlighting DiNADO’s superior coaching dynamics and effectiveness in managed textual content technology duties.
In abstract, researchers launched DiNADO, an enhanced parameterization of the NADO algorithm. One of many most important benefits of DiNADO is its compatibility with fine-tuning strategies like LoRA, enabling a capacity-rich variant of NADO. Furthermore, the researchers carried out a theoretical evaluation of the vanilla NADO implementation’s flawed designs and urged particular options. This paper contributes beneficial insights and enhancements within the subject of controllable language technology, doubtlessly opening new pathways for extra environment friendly and efficient textual content technology purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel. If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit

Sajjad Ansari is a closing yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the influence of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.