

{kind=link}
Cross entropy loss stands as one of many cornerstone metrics in evaluating language fashions, serving as each a coaching goal and an analysis metric. On this complete information, we’ll discover what cross entropy loss is, the way it works particularly within the context of massive language fashions (LLMs), and why it issues a lot for understanding mannequin efficiency.
Whether or not you’re a machine studying practitioner, a researcher, or somebody seeking to perceive how trendy AI techniques are educated and evaluated, this text will give you a radical understanding of cross entropy loss and its significance on this planet of language modeling.
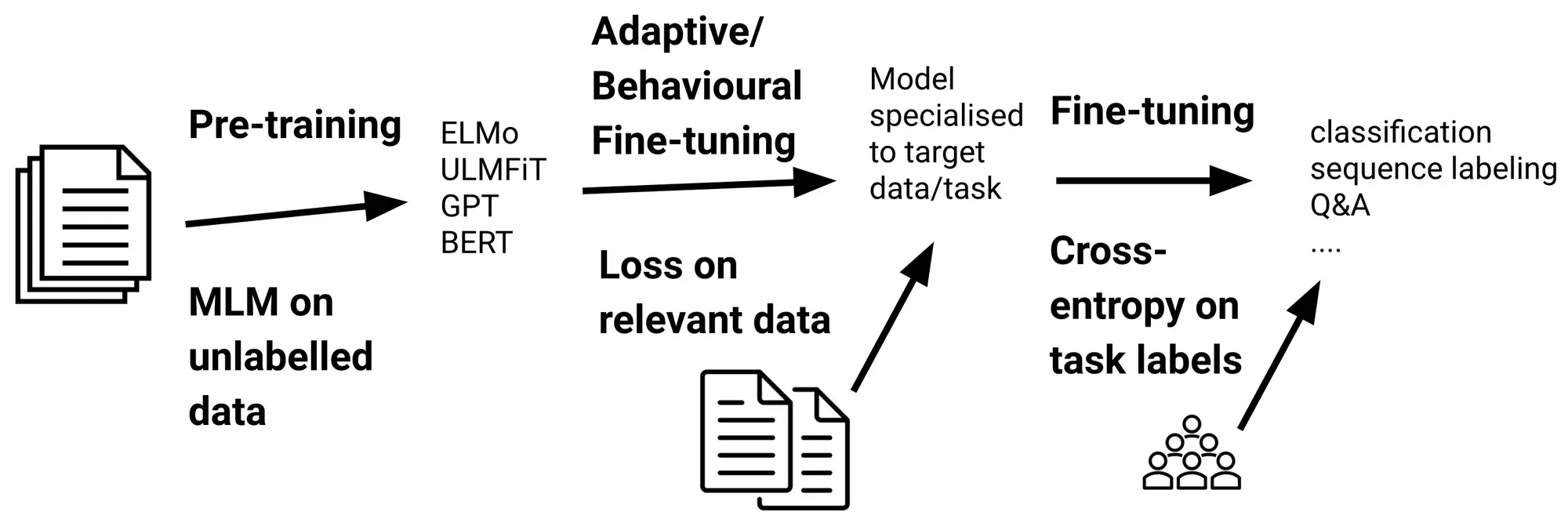
What’s Cross Entropy Loss?
Cross entropy loss measures the efficiency of a classification mannequin whose output is a likelihood distribution. Within the context of language fashions, it quantifies the distinction between the expected likelihood distribution of the subsequent token and the precise distribution (often a one-hot encoded vector representing the true subsequent token).
Key Options of Cross-Entropy Loss
- Data Idea Basis: Rooted in info principle, cross entropy measures what number of bits of knowledge are wanted to determine occasions from one likelihood distribution (the true distribution) if a coding scheme optimized for an additional distribution (the expected one) is used.
- Probabilistic Output: Works with fashions that produce likelihood distributions relatively than deterministic outputs.
- Uneven: In contrast to another distance metrics, cross entropy is just not symmetric—the ordering of the true and predicted distributions issues.
- Differentiable: Important for gradient-based optimization strategies utilized in neural community coaching.
- Delicate to Confidence: Closely penalizes assured however incorrect predictions, encouraging fashions to be unsure when acceptable.
Additionally Learn: Find out how to Consider a Massive Language Mannequin (LLM)?
Binary Cross Entropy & Method
For binary classification duties (resembling easy sure/no questions or sentiment evaluation), binary cross entropy is used:
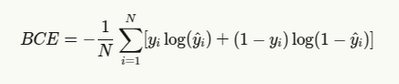
The place:
- yi is the true label (0 or 1)
- yi is the expected likelihood
- N is the variety of samples
Binary cross entropy is also called log loss, notably in machine studying competitions.
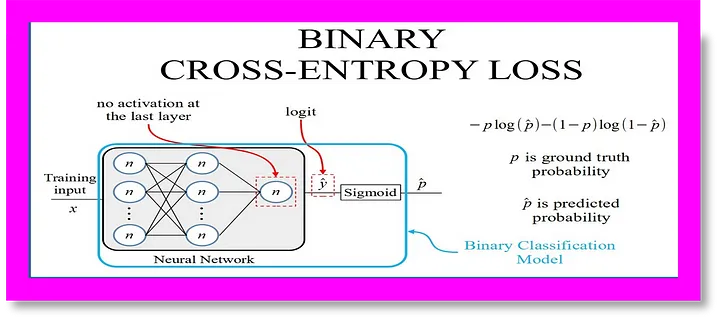
Cross Entropy as a Loss Perform
Throughout coaching, cross entropy serves as the target operate that the mannequin tries to attenuate. By evaluating the mannequin’s predicted likelihood distribution with the bottom fact, the coaching algorithm adjusts mannequin parameters to cut back the discrepancy between predictions and actuality.
Cross Entropy’s Position in LLMs
In Massive Language Fashions, cross entropy loss performs a number of essential roles:
- Coaching Goal: The first objective throughout pre-training and fine-tuning is to attenuate loss.
- Analysis Metric: Used to guage mannequin efficiency on held-out information.
- Perplexity Calculation: Perplexity, one other frequent LLM analysis metric, is derived from cross entropy: Perplexity=2^{CrossEntropy}.
- Mannequin Comparability: Completely different fashions will be in contrast based mostly on their loss on the identical dataset.
- Switch Studying Evaluation: This may point out how nicely a mannequin transfers data from pre-training to downstream duties.
How Does It Work?
For language fashions, cross entropy loss works as follows:
- The mannequin predicts a likelihood distribution over the whole vocabulary for the subsequent token.
- This distribution is in contrast with the true distribution (often a one-hot vector the place the precise subsequent token has likelihood 1).
- The adverse log-likelihood of the true token underneath the mannequin’s distribution is calculated.
- This worth is averaged over all tokens within the sequence or dataset.
Formulation and Clarification
The overall system for cross entropy loss in language modeling is:
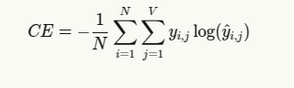
The place:
- N is the variety of tokens within the sequence
- V is the vocabulary dimension
- yi, j is 1 if token j is the right subsequent token at place i, in any other case 0
- yi, j is the expected likelihood of token j at place i
Since we’re often coping with a one-hot encoded floor fact, this simplifies to:
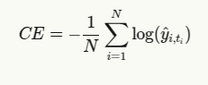
The place ti is the index of the true token at place i.
Cross Entropy Loss Implementation in PyTorch and TensorFlow Code
# PyTorch Implementation
import torch
import torch.nn as nn
import torch.nn.purposeful as F
import numpy as np
import matplotlib.pyplot as plt
# Easy Language Mannequin in PyTorch
class SimpleLanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
tremendous(SimpleLanguageModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def ahead(self, x):
# x form: [batch_size, sequence_length]
embedded = self.embedding(x) # [batch_size, sequence_length, embedding_dim]
lstm_out, _ = self.lstm(embedded) # [batch_size, sequence_length, hidden_dim]
logits = self.fc(lstm_out) # [batch_size, sequence_length, vocab_size]
return logits
# Guide Cross Entropy Loss calculation
def manual_cross_entropy_loss(logits, targets):
"""
Computes cross entropy loss manually
Args:
logits: Uncooked mannequin outputs [batch_size, sequence_length, vocab_size]
targets: True token indices [batch_size, sequence_length]
"""
batch_size, seq_len, vocab_size = logits.form
# Reshape for simpler processing
logits = logits.reshape(-1, vocab_size) # [batch_size*sequence_length, vocab_size]
targets = targets.reshape(-1) # [batch_size*sequence_length]
# Convert logits to possibilities utilizing softmax
probs = F.softmax(logits, dim=1)
# Get likelihood of the right token for every place
correct_token_probs = probs[range(len(targets)), targets]
# Compute adverse log chance
nll = -torch.log(correct_token_probs + 1e-10) # Add small epsilon to stop log(0)
# Common over all tokens
loss = torch.imply(nll)
return loss
# Instance utilization
def pytorch_example():
# Parameters
vocab_size = 10000
embedding_dim = 128
hidden_dim = 256
batch_size = 32
seq_length = 50
# Pattern information
inputs = torch.randint(0, vocab_size, (batch_size, seq_length))
targets = torch.randint(0, vocab_size, (batch_size, seq_length))
# Create mannequin
mannequin = SimpleLanguageModel(vocab_size, embedding_dim, hidden_dim)
# Get mannequin outputs
logits = mannequin(inputs)
# PyTorch's built-in loss operate
criterion = nn.CrossEntropyLoss()
# For CrossEntropyLoss, we have to reshape
pytorch_loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
# Our guide implementation
manual_loss = manual_cross_entropy_loss(logits, targets)
print(f"PyTorch CrossEntropyLoss: {pytorch_loss.merchandise():.4f}")
print(f"Guide CrossEntropyLoss: {manual_loss.merchandise():.4f}")
return mannequin, logits, targets
# TensorFlow Implementation
def tensorflow_implementation():
import tensorflow as tf
# Parameters
vocab_size = 10000
embedding_dim = 128
hidden_dim = 256
batch_size = 32
seq_length = 50
# Easy Language Mannequin in TensorFlow
class TFSimpleLanguageModel(tf.keras.Mannequin):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
tremendous(TFSimpleLanguageModel, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(hidden_dim, return_sequences=True)
self.fc = tf.keras.layers.Dense(vocab_size)
def name(self, x):
embedded = self.embedding(x)
lstm_out = self.lstm(embedded)
return self.fc(lstm_out)
# Create mannequin
tf_model = TFSimpleLanguageModel(vocab_size, embedding_dim, hidden_dim)
# Pattern information
tf_inputs = tf.random.uniform((batch_size, seq_length), minval=0, maxval=vocab_size, dtype=tf.int32)
tf_targets = tf.random.uniform((batch_size, seq_length), minval=0, maxval=vocab_size, dtype=tf.int32)
# Get mannequin outputs
tf_logits = tf_model(tf_inputs)
# TensorFlow's built-in loss operate
tf_loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
tf_loss = tf_loss_fn(tf_targets, tf_logits)
# Guide cross entropy calculation in TensorFlow
def tf_manual_cross_entropy(logits, targets):
batch_size, seq_len, vocab_size = logits.form
# Reshape
logits_flat = tf.reshape(logits, [-1, vocab_size])
targets_flat = tf.reshape(targets, [-1])
# Convert to possibilities
probs = tf.nn.softmax(logits_flat, axis=1)
# Get appropriate token possibilities
indices = tf.stack([tf.range(tf.shape(targets_flat)[0], dtype=tf.int32), tf.forged(targets_flat, tf.int32)], axis=1)
correct_probs = tf.gather_nd(probs, indices)
# Compute loss
loss = -tf.reduce_mean(tf.math.log(correct_probs + 1e-10))
return loss
manual_tf_loss = tf_manual_cross_entropy(tf_logits, tf_targets)
print(f"TensorFlow CrossEntropyLoss: {tf_loss.numpy():.4f}")
print(f"Guide TF CrossEntropyLoss: {manual_tf_loss.numpy():.4f}")
return tf_model, tf_logits, tf_targets
# Visualizing Cross Entropy
def visualize_cross_entropy():
# True label is 1 (one-hot encoding could be [0, 1])
true_label = 1
# Vary of predicted possibilities for sophistication 1
predicted_probs = np.linspace(0.01, 0.99, 100)
# Calculate cross entropy loss for every predicted likelihood
cross_entropy = [-np.log(p) if true_label == 1 else -np.log(1-p) for p in predicted_probs]
# Plot
plt.determine(figsize=(10, 6))
plt.plot(predicted_probs, cross_entropy)
plt.title('Cross Entropy Loss vs. Predicted Chance (True Class = 1)')
plt.xlabel('Predicted Chance for Class 1')
plt.ylabel('Cross Entropy Loss')
plt.grid(True)
plt.axvline(x=1.0, shade="r", linestyle="--", alpha=0.5, label="True Chance = 1.0")
plt.legend()
plt.present()
# Visualize loss panorama for binary classification
probs_0 = np.linspace(0.01, 0.99, 100)
probs_1 = 1 - probs_0
# Calculate loss for true label = 0
loss_true_0 = [-np.log(1-p) for p in probs_0]
# Calculate loss for true label = 1
loss_true_1 = [-np.log(p) for p in probs_0]
plt.determine(figsize=(10, 6))
plt.plot(probs_0, loss_true_0, label="True Label = 0")
plt.plot(probs_0, loss_true_1, label="True Label = 1")
plt.title('Cross Entropy Loss for Completely different True Labels')
plt.xlabel('Predicted Chance for Class 1')
plt.ylabel('Cross Entropy Loss')
plt.legend()
plt.grid(True)
plt.present()
# Run examples
if __name__ == "__main__":
print("PyTorch Instance:")
pt_model, pt_logits, pt_targets = pytorch_example()
print("nTensorFlow Instance:")
attempt:
tf_model, tf_logits, tf_targets = tensorflow_implementation()
besides ImportError:
print("TensorFlow not put in. Skipping TensorFlow instance.")
print("nVisualizing Cross Entropy:")
visualize_cross_entropy()Code Evaluation:
I’ve carried out cross entropy loss in each PyTorch and TensorFlow, displaying each built-in features and guide implementations. Let’s stroll by way of the important thing elements:
- SimpleLanguageModel: A primary LSTM-based language mannequin that predicts possibilities for the subsequent token.
- Guide Cross Entropy Implementation: Reveals how cross entropy is calculated from first ideas:
- Convert logits to possibilities utilizing softmax
- Extract the likelihood of the right token
- Take the adverse log of those possibilities
- Common throughout all tokens
- Visualizations: The code consists of visualizations displaying how loss adjustments with totally different predicted possibilities.
Output:
PyTorch Instance:PyTorch CrossEntropyLoss: 9.2140
Guide CrossEntropyLoss: 9.2140
TensorFlow Instance:
TensorFlow CrossEntropyLoss: 9.2103
Guide TF CrossEntropyLoss: 9.2103
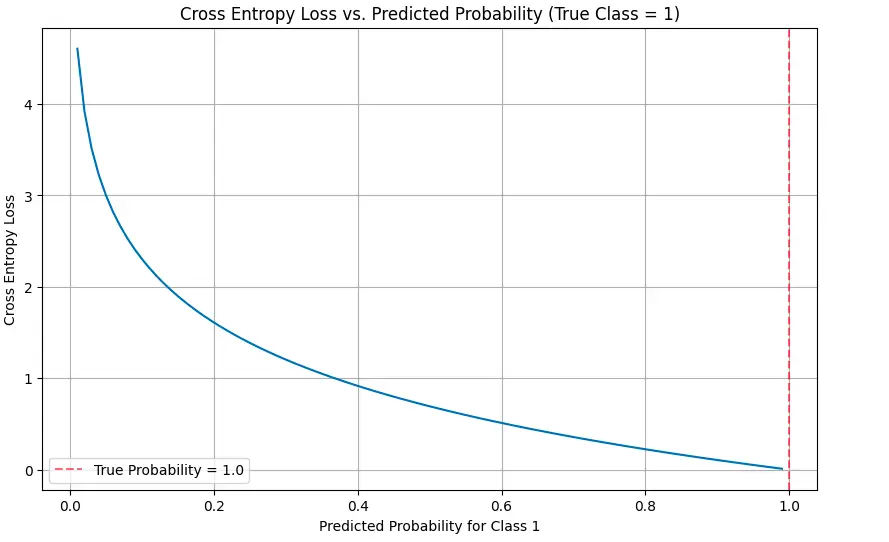
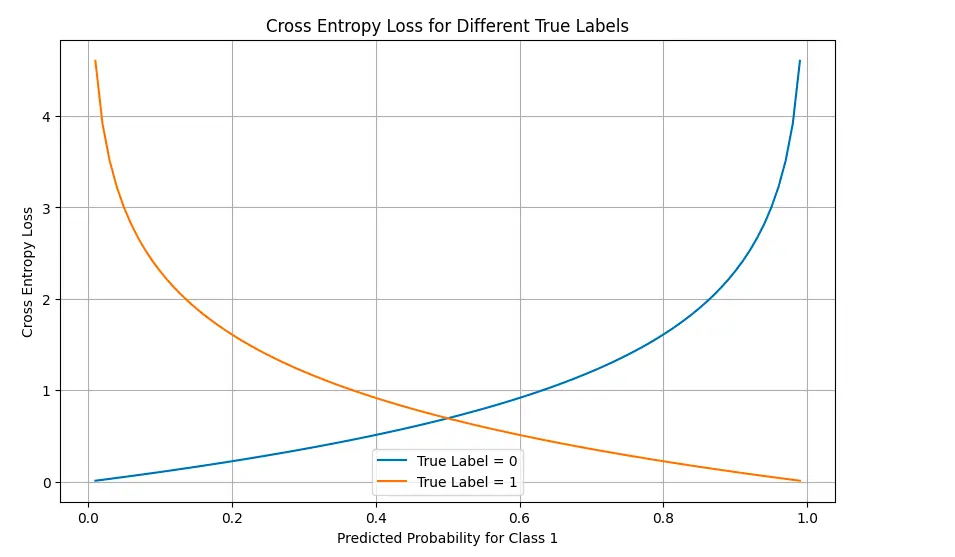
The visualizations illustrate how the loss will increase dramatically as predictions diverge from the true labels, particularly when the mannequin is confidently incorrect.
Benefits & Limitations
| Benefits | Limitations |
| Differentiable and easy, enabling gradient-based optimization | Could be numerically unstable with very small possibilities (requires epsilon dealing with) |
| Naturally handles probabilistic outputs | May have label smoothing to stop overconfidence |
| Nicely-suited for multi-class issues | Could be dominated by frequent courses in imbalanced datasets |
| Theoretically well-founded in info principle | Doesn’t instantly optimize for particular analysis metrics (like BLEU or ROUGE) |
| Computationally environment friendly | Assumes tokens are impartial, ignoring sequential dependencies |
| Penalizes assured however incorrect predictions | Much less interpretable than metrics like accuracy or perplexity |
| Could be decomposed per token for evaluation | Doesn’t account for semantic similarity between tokens |
Sensible Purposes
Cross entropy loss is used extensively in language mannequin purposes:
- Coaching Basis Fashions: Cross entropy loss is the usual goal operate for pre-training massive language fashions on huge textual content corpora.
- Tremendous-tuning: When adapting pre-trained fashions to particular duties, cross entropy stays the go-to loss operate.
- Sequence Technology: Even when producing textual content, the loss throughout coaching influences the standard of the mannequin’s outputs.
- Mannequin Choice: When evaluating totally different mannequin architectures or hyperparameter settings, loss on validation information is a key metric.
- Area Adaptation: Measuring how cross entropy adjustments throughout domains can point out how nicely a mannequin generalizes.
- Information Distillation: Used to switch data from bigger “instructor” fashions to smaller “scholar” fashions.
Comparability with Different Metrics
Whereas cross entropy loss is key, it’s usually used alongside different analysis metrics:
- Perplexity: Exponential of the cross entropy; extra interpretable because it represents how “confused” the mannequin is
- BLEU/ROUGE: For technology duties, these metrics seize n-gram overlap with reference texts
- Accuracy: Easy proportion of appropriate predictions, much less informative than cross entropy
- F1 Rating: Balances precision and recall for classification duties
- KL Divergence: Measures how one likelihood distribution diverges from one other
- Earth Mover’s Distance: Accounts for semantic similarity between tokens, not like cross entropy
Additionally Learn: High 15 LLM Analysis Metrics to Discover in 2025
Conclusion
Cross entropy loss stands as an indispensable instrument within the analysis and coaching of language fashions. Its theoretical foundations in info principle, mixed with its sensible benefits for optimization, make it the usual alternative for many NLP duties.
Understanding cross entropy loss gives perception not simply into how fashions are educated but in addition into their basic limitations and the trade-offs concerned in language modeling. As language fashions proceed to evolve, cross entropy loss stays a cornerstone metric, serving to researchers and practitioners measure progress and information innovation.
Whether or not you’re constructing your language fashions or evaluating current ones, a radical understanding of cross entropy loss is crucial for making knowledgeable choices and decoding outcomes accurately.
Gen AI Intern at Analytics Vidhya
Division of Pc Science, Vellore Institute of Expertise, Vellore, India
I’m presently working as a Gen AI Intern at Analytics Vidhya, the place I contribute to progressive AI-driven options that empower companies to leverage information successfully. As a final-year Pc Science scholar at Vellore Institute of Expertise, I convey a stable basis in software program growth, information analytics, and machine studying to my function.
Be at liberty to attach with me at [email protected]
Login to proceed studying and revel in expert-curated content material.