

{kind=link}
Synthetic intelligence, significantly the event of enormous language fashions (LLMs), has been quickly advancing, specializing in enhancing these fashions’ reasoning capabilities. As AI programs are more and more tasked with complicated problem-solving, it’s essential that they not solely generate correct options but in addition possess the flexibility to guage and refine their outputs critically. This enhancement in reasoning is crucial for creating AI that may function with better autonomy and reliability in varied refined duties. The continuing analysis on this area displays the rising demand for AI programs that may independently assess their reasoning processes and proper potential errors, thereby turning into simpler and reliable instruments.
A major problem in advancing LLMs is the event of mechanisms that allow these fashions to critique their reasoning processes successfully. Present strategies typically depend on primary prompts or exterior suggestions, that are restricted in scope and effectiveness. These approaches sometimes contain easy critiques that time out errors however don’t present the depth of understanding needed to enhance the mannequin’s reasoning accuracy considerably. This limitation leads to errors going undetected or improperly addressed, limiting AI’s skill to carry out complicated duties reliably. The problem, due to this fact, lies in making a self-critique framework that permits AI fashions to critically analyze and enhance their outputs meaningfully.
Historically, AI programs have improved their reasoning capabilities by way of exterior suggestions mechanisms, the place human annotators or different programs present corrective enter. Whereas these strategies will be efficient, they’re additionally resource-intensive and want extra scalability, making them impractical for widespread use. Furthermore, some present approaches incorporate primary types of self-criticism, however these typically should be revised to enhance mannequin efficiency considerably. The important thing downside with these strategies is that they don’t sufficiently improve the mannequin’s intrinsic skill to guage and refine its reasoning, which is crucial for growing extra clever AI programs.
Researchers from the Chinese language Info Processing Laboratory, the Chinese language Academy of Sciences, the College of Chinese language Academy of Sciences, and Xiaohongshu Inc. have developed a novel framework known as Critic-CoT. This framework is designed to considerably enhance the self-critique talents of LLMs by guiding them towards extra rigorous, System-2-like reasoning. The Critic-CoT framework leverages a structured Chain-of-Thought (CoT) format, permitting fashions to guage their reasoning steps and make needed refinements systematically. This revolutionary method reduces the necessity for expensive human annotations whereas pushing the boundaries of what AI can obtain in self-evaluation and correction.
The Critic-CoT framework operates by participating LLMs in a step-wise critique course of. The mannequin first generates an answer to a given downside after which critiques its output, figuring out errors or areas of enchancment. Following this, the mannequin refines the answer primarily based on the critique, and this course of is repeated iteratively till the answer is both corrected or validated. For instance, throughout experiments on the GSM8K and MATH datasets, the Critic-CoT mannequin may detect and proper errors in its options with excessive accuracy. The iterative nature of this course of permits the mannequin to repeatedly enhance its reasoning capabilities, making it more proficient at dealing with complicated duties.

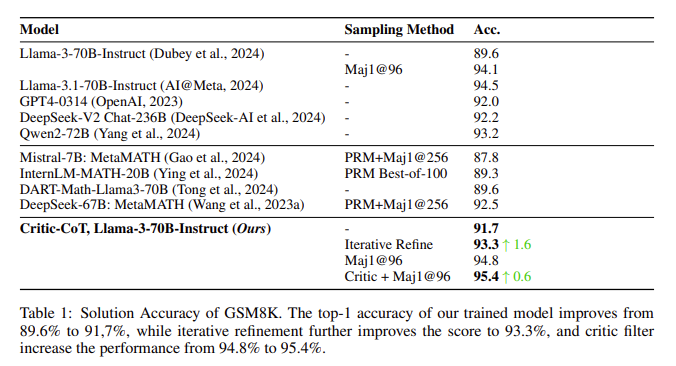
The effectiveness of the Critic-CoT framework was demonstrated by way of intensive experiments. On the GSM8K dataset, which consists of grade-school-level math phrase issues, the accuracy of the LLM improved from 89.6% to 93.3% after iterative refinement, with a critic filter additional rising accuracy to 95.4%. Equally, on the tougher MATH dataset, which incorporates highschool math competitors issues, the mannequin’s accuracy elevated from 51.0% to 57.8% after using the Critic-CoT framework, with extra features noticed when making use of the critic filter. These outcomes spotlight the numerous enhancements in task-solving efficiency that may be achieved by way of the Critic-CoT framework, significantly when the mannequin is tasked with complicated reasoning eventualities.

In conclusion, the Critic-CoT framework represents a considerable development in growing self-critique capabilities for LLMs. This analysis addresses the crucial problem of enabling AI fashions to guage and enhance their reasoning by introducing a structured and iterative refinement course of. The spectacular features in accuracy noticed in each the GSM8K and MATH datasets show the potential of Critic-CoT to boost the efficiency of AI programs throughout varied complicated duties. This framework improves the accuracy and reliability of AI reasoning and reduces the necessity for human intervention, making it a scalable and environment friendly answer for future AI improvement.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and LinkedIn. Be a part of our Telegram Channel. In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.