

{kind=link}
Within the dynamic world of synthetic intelligence and tremendous development of Generative AI, builders are always looking for revolutionary methods to extract significant perception from textual content. This weblog put up walks you thru an thrilling undertaking that harnesses the ability of Google’s Gemini AI to create an clever English Educator Utility that analyzes textual content paperwork and supplies tough phrases, medium phrases, their synonyms, antonyms, use-cases and in addition supplies the vital questions with a solution from the textual content. I consider training is the sector that advantages most from the developments of Generative AIs or LLMs and it’s GREAT!
Studying Aims
- Integrating Google Gemini AI fashions into Python-based APIs.
- Perceive tips on how to combine and make the most of the English Educator App API to reinforce language studying functions with real-time knowledge and interactive options.
- Discover ways to leverage the English Educator App API to construct personalized instructional instruments, bettering consumer engagement and optimizing language instruction.
- Implementation of clever textual content evaluation utilizing superior AI prompting.
- Managing complicated AI interplay error-free with error-handling methods.
This text was printed as part of the Information Science Blogathon.
What are APIs?
API (Utility Programming Interfaces) function a digital bridge between totally different software program functions. They’re outlined as a set of protocols and guidelines that allow seamless communication, permitting builders to entry particular functionalities with out diving into complicated underlying implementation.
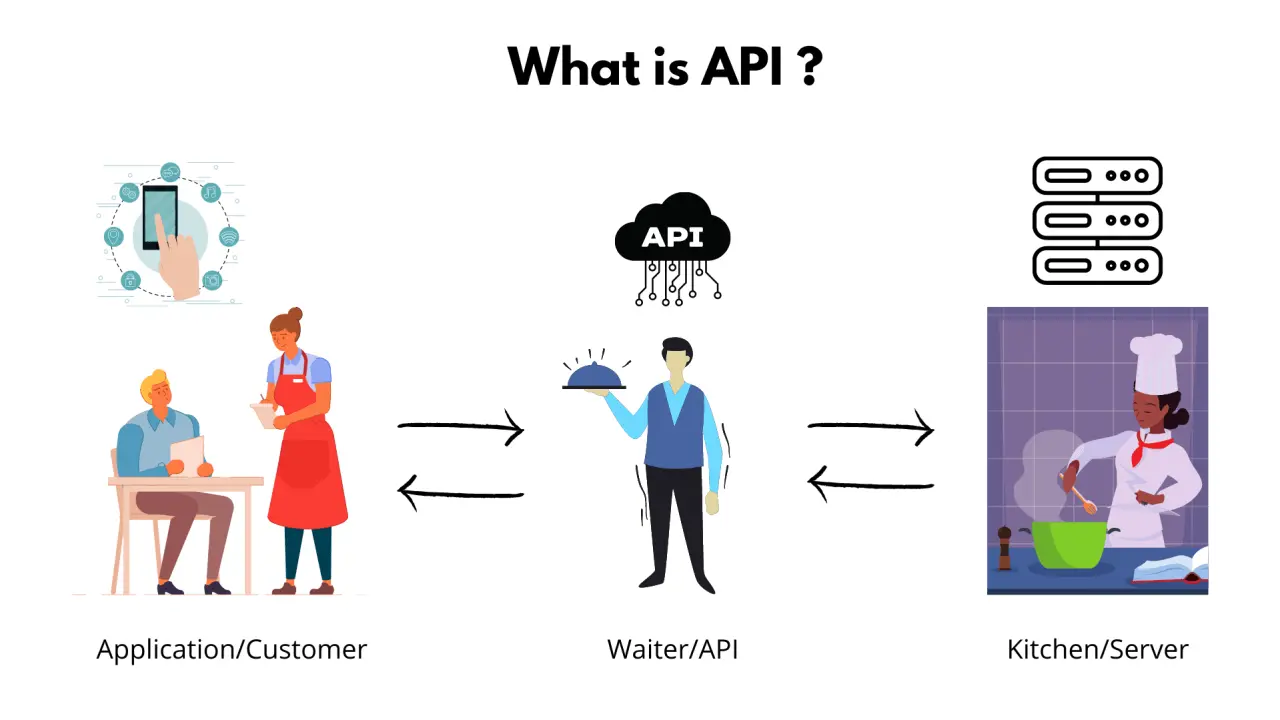
What’s REST API?
REST (Representational State Switch) is an architectural type for designing networked functions. It makes use of customary HTTP strategies to carry out operations on assets.
Necessary REST strategies are:
- GET: Retrieve knowledge from a server.
- POST: Create new assets.
- PUT: Replace present assets utterly.
- PATCH: Partially replace present assets.
- DELETE: Take away assets.
Key traits embody:
- Stateless communication
- Uniform interface
- Shopper-Serve structure
- Cacheable assets
- Layered system design
REST APIs use URLs to determine assets and usually return knowledge in JSON codecs. They supply a standardized, scalable strategy for various functions to speak over the web, making them elementary in trendy net and cell growth.
Pydantic and FastAPI: A Good Pair
Pydantic revolutionizes knowledge validation in Python by permitting builders to create sturdy knowledge fashions with kind hints and validation guidelines. It ensures knowledge integrity and supplies crystal-clear interface definitions, catching potential errors earlier than they propagate by means of the system.
FastAPI enhances Pydantic fantastically, providing a contemporary, high-performance asynchronous net framework for constructing APIs.
Its key benefit of FastAPI:
- Automated interactive API documentation
- Excessive-speed efficiency
- Constructed-in help for Asynchronous Server Gateway Interface
- Intuitive knowledge validation
- Clear and simple syntax
A Transient on Google Gemini
Google Gemini represents a breakthrough in multimodal AI fashions, able to processing complicated info throughout textual content, code, audio, and picture. For this undertaking, I leverage the ‘gemini-1.5-flash’ mannequin, which supplies:
- Speedy and clever textual content processing utilizing prompts.
- Superior pure language understanding.
- Versatile system directions for personalized outputs utilizing prompts.
- Capability to generate a nuanced, context-aware response.
Undertaking Setup and Atmosphere Configuration
Organising the event setting is essential for a easy implementation. We use Conda to create an remoted, reproducible setting
# Create a brand new conda setting
conda create -n educator-api-env python=3.11
# Activate the setting
conda activate educator-api-env
# Set up required packages
pip set up "fastapi[standard]" google-generativeai python-dotenvUndertaking Architectural Parts
Our API is structured into three main parts:
- fashions.py : Outline knowledge constructions and validation
- providers.py : Implements AI-powered textual content extractor providers
- important.py : Create API endpoints and handles request routing
Constructing the API: Code Implementation
Getting Google Gemini API Key and Safety setup for the undertaking.
Create a .env file within the undertaking root, Seize your Gemini API Key from right here, and put your key within the .env file
GOOGLE_API_KEY="ABCDEFGH-67xGHtsf"This file will likely be securely accessed by the service module utilizing os.getenv(“<google-api-key>”). So your vital secret key won’t be public.
Pydantic Fashions: Making certain Information Integrity
We outline structured fashions that assure knowledge consistency for the Gemini response. We’ll implement two knowledge fashions for every knowledge extraction service from the textual content.
Vocabulary knowledge extraction mannequin:
- WordDetails: It should construction and validate the extracted phrase from the AI
from pydantic import BaseModel, Subject
from typing import Record, Non-compulsory
class WordDetails(BaseModel):
phrase: str = Subject(..., description="Extracted vocabulary phrase")
synonyms: Record[str] = Subject(
default_factory=listing, description="Synonyms of the phrase"
)
antonyms: Record[str] = Subject(
default_factory=listing, description="Antonyms of the phrase"
)
usecase: Non-compulsory[str] = Subject(None, description="Use case of the phrase")
instance: Non-compulsory[str] = Subject(None, description="Instance sentence")- VocabularyResponse: It should construction and validate the extracted phrases into two classes very tough phrases and medium tough phrases.
class VocabularyResponse(BaseModel):
difficult_words: Record[WordDetails] = Subject(
..., description="Record of adverse vocabulary phrases"
)
medium_words: Record[WordDetails] = Subject(
..., description="Record of medium vocabulary phrases"
)Query and Reply extraction mannequin
- QuestionAnswerModel: It should construction and validate the extracted questions and solutions.
class QuestionAnswerModel(BaseModel):
query: str = Subject(..., description="Query")
reply: str = Subject(..., description="Reply")- QuestionAnswerResponse: It should construction and validate the extracted responses from the AI.
class QuestionAnswerResponse(BaseModel):
questions_and_answers: Record[QuestionAnswerModel] = Subject(
..., description="Record of questions and solutions"
)These fashions present computerized validation, kind checking, and clear interface definitions, stopping potential runtime errors.
Service Module: Clever Textual content Processing
The service module has two providers:
This service GeminiVocabularyService services:
- Makes use of Gemini to determine difficult phrases.
- Generates complete phrase insights.
- Implement sturdy JSON parsing.
- Manages potential error eventualities.
First, we’ve to import all the mandatory libraries and arrange the logging and setting variables.
import os
import json
import logging
from fastapi import HTTPException
import google.generativeai as genai
from dotenv import load_dotenv
# Configure logging
logging.basicConfig(degree=logging.INFO)
logger = logging.getLogger(__name__)
# Load setting variables
load_dotenv()This GeminiVocabularyService class has three methodology.
The __init__ Methodology has vital Gemini configuration, Google API Key, Setting generative mannequin, and immediate for the vocabulary extraction.
Immediate:
"""You might be an skilled vocabulary extractor.
For the given textual content:
1. Determine 3-5 difficult vocabulary phrases
2. Present the next for EACH phrase in a STRICT JSON format:
- phrase: The precise phrase
- synonyms: Record of 2-3 synonyms
- antonyms: Record of 2-3 antonyms
- usecase: A short rationalization of the phrase's utilization
- instance: An instance sentence utilizing the phrase
IMPORTANT: Return ONLY a sound JSON that matches this construction:
{
"difficult_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"instance": "string"
}
],
"medium_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"instance": "string"
}
],
}
""" Code Implementation
class GeminiVocabularyService:
def __init__(self):
_google_api_key = os.getenv("GOOGLE_API_KEY")
# Retrieve API Key
self.api_key = _google_api_key
if not self.api_key:
increase ValueError(
"Google API Secret is lacking. Please set GOOGLE_API_KEY in .env file."
)
# Configure Gemini API
genai.configure(api_key=self.api_key)
# Technology Configuration
self.generation_config = {
"temperature": 0.7,
"top_p": 0.95,
"max_output_tokens": 8192,
}
# Create Generative Mannequin
self.vocab_model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=self.generation_config, # kind: ignore
system_instruction="""
You might be an skilled vocabulary extractor.
For the given textual content:
1. Determine 3-5 difficult vocabulary phrases
2. Present the next for EACH phrase in a STRICT JSON format:
- phrase: The precise phrase
- synonyms: Record of 2-3 synonyms
- antonyms: Record of 2-3 antonyms
- usecase: A short rationalization of the phrase's utilization
- instance: An instance sentence utilizing the phrase
IMPORTANT: Return ONLY a sound JSON that matches this construction:
{
"difficult_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"instance": "string"
}
],
"medium_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"instance": "string"
}
],
}
""",
)The extracted_vocabulary methodology has the chat course of, and response from the Gemini by sending textual content enter utilizing the sending_message_async() perform. This methodology has one personal utility perform _parse_response(). This personal utility perform will validate the response from the Gemini, verify the mandatory parameters then parse the info to the extracted vocabulary perform. It should additionally log the errors akin to JSONDecodeError, and ValueError for higher error administration.
Code Implementation
The extracted_vocabulary methodology:
async def extract_vocabulary(self, textual content: str) -> dict:
attempt:
# Create a brand new chat session
chat_session = self.vocab_model.start_chat(historical past=[])
# Ship message and await response
response = await chat_session.send_message_async(textual content)
# Extract and clear the textual content response
response_text = response.textual content.strip()
# Try and extract JSON
return self._parse_response(response_text)
besides Exception as e:
logger.error(f"Vocabulary extraction error: {str(e)}")
logger.error(f"Full response: {response_text}")
increase HTTPException(
status_code=500, element=f"Vocabulary extraction failed: {str(e)}"
)The _parsed_response methodology:
def _parse_response(self, response_text: str) -> dict:
# Take away markdown code blocks if current
response_text = response_text.change("```json", "").change("```", "").strip()
attempt:
# Try and parse JSON
parsed_data = json.masses(response_text)
# Validate the construction
if (
not isinstance(parsed_data, dict)
or "difficult_words" not in parsed_data
):
increase ValueError("Invalid JSON construction")
return parsed_data
besides json.JSONDecodeError as json_err:
logger.error(f"JSON Decode Error: {json_err}")
logger.error(f"Problematic response: {response_text}")
increase HTTPException(
status_code=400, element="Invalid JSON response from Gemini"
)
besides ValueError as val_err:
logger.error(f"Validation Error: {val_err}")
increase HTTPException(
status_code=400, element="Invalid vocabulary extraction response"
)The whole CODE of the GeminiVocabularyService module.
class GeminiVocabularyService:
def __init__(self):
_google_api_key = os.getenv("GOOGLE_API_KEY")
# Retrieve API Key
self.api_key = _google_api_key
if not self.api_key:
increase ValueError(
"Google API Secret is lacking. Please set GOOGLE_API_KEY in .env file."
)
# Configure Gemini API
genai.configure(api_key=self.api_key)
# Technology Configuration
self.generation_config = {
"temperature": 0.7,
"top_p": 0.95,
"max_output_tokens": 8192,
}
# Create Generative Mannequin
self.vocab_model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=self.generation_config, # kind: ignore
system_instruction="""
You might be an skilled vocabulary extractor.
For the given textual content:
1. Determine 3-5 difficult vocabulary phrases
2. Present the next for EACH phrase in a STRICT JSON format:
- phrase: The precise phrase
- synonyms: Record of 2-3 synonyms
- antonyms: Record of 2-3 antonyms
- usecase: A short rationalization of the phrase's utilization
- instance: An instance sentence utilizing the phrase
IMPORTANT: Return ONLY a sound JSON that matches this construction:
{
"difficult_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"instance": "string"
}
],
"medium_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"instance": "string"
}
],
}
""",
)
async def extract_vocabulary(self, textual content: str) -> dict:
attempt:
# Create a brand new chat session
chat_session = self.vocab_model.start_chat(historical past=[])
# Ship message and await response
response = await chat_session.send_message_async(textual content)
# Extract and clear the textual content response
response_text = response.textual content.strip()
# Try and extract JSON
return self._parse_response(response_text)
besides Exception as e:
logger.error(f"Vocabulary extraction error: {str(e)}")
logger.error(f"Full response: {response_text}")
increase HTTPException(
status_code=500, element=f"Vocabulary extraction failed: {str(e)}"
)
def _parse_response(self, response_text: str) -> dict:
# Take away markdown code blocks if current
response_text = response_text.change("```json", "").change("```", "").strip()
attempt:
# Try and parse JSON
parsed_data = json.masses(response_text)
# Validate the construction
if (
not isinstance(parsed_data, dict)
or "difficult_words" not in parsed_data
):
increase ValueError("Invalid JSON construction")
return parsed_data
besides json.JSONDecodeError as json_err:
logger.error(f"JSON Decode Error: {json_err}")
logger.error(f"Problematic response: {response_text}")
increase HTTPException(
status_code=400, element="Invalid JSON response from Gemini"
)
besides ValueError as val_err:
logger.error(f"Validation Error: {val_err}")
increase HTTPException(
status_code=400, element="Invalid vocabulary extraction response"
)
Query-Reply Technology Service
This Query Reply Service services:
- Creates contextually wealthy comprehension questions.
- Generates exact, informative solutions.
- Handles complicated textual content evaluation requirement.
- JSON and Worth error dealing with.
This QuestionAnswerService has three strategies:
__init__ methodology
The __init__ methodology is generally the identical because the Vocabulary service class aside from the immediate.
Immediate:
"""
You might be an skilled at creating complete comprehension questions and solutions.
For the given textual content:
1. Generate 8-10 various questions masking:
- Vocabulary which means
- Literary units
- Grammatical evaluation
- Thematic insights
- Contextual understanding
IMPORTANT: Return ONLY a sound JSON on this EXACT format:
{
"questions_and_answers": [
{
"question": "string",
"answer": "string"
}
]
}
Tips:
- Questions needs to be clear and particular
- Solutions needs to be concise and correct
- Cowl totally different ranges of comprehension
- Keep away from sure/no questions
""" Code Implementation:
The __init__ methodology of QuestionAnswerService class
def __init__(self):
_google_api_key = os.getenv("GOOGLE_API_KEY")
# Retrieve API Key
self.api_key = _google_api_key
if not self.api_key:
increase ValueError(
"Google API Secret is lacking. Please set GOOGLE_API_KEY in .env file."
)
# Configure Gemini API
genai.configure(api_key=self.api_key)
# Technology Configuration
self.generation_config = {
"temperature": 0.7,
"top_p": 0.95,
"max_output_tokens": 8192,
}
self.qa_model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=self.generation_config, # kind: ignore
system_instruction="""
You might be an skilled at creating complete comprehension questions and solutions.
For the given textual content:
1. Generate 8-10 various questions masking:
- Vocabulary which means
- Literary units
- Grammatical evaluation
- Thematic insights
- Contextual understanding
IMPORTANT: Return ONLY a sound JSON on this EXACT format:
{
"questions_and_answers": [
{
"question": "string",
"answer": "string"
}
]
}
Tips:
- Questions needs to be clear and particular
- Solutions needs to be concise and correct
- Cowl totally different ranges of comprehension
- Keep away from sure/no questions
""",
)The Query and Reply Extraction
The extract_questions_and_answers methodology has a chat session with Gemini, a full immediate for higher extraction of questions and solutions from the enter textual content, an asynchronous message despatched to the Gemini API utilizing send_message_async(full_prompt), after which stripping response knowledge for clear knowledge. This methodology additionally has a personal utility perform identical to the earlier one.
Code Implementation:
extract_questions_and_answers
async def extract_questions_and_answers(self, textual content: str) -> dict:
"""
Extracts questions and solutions from the given textual content utilizing the supplied mannequin.
"""
attempt:
# Create a brand new chat session
chat_session = self.qa_model.start_chat(historical past=[])
full_prompt = f"""
Analyze the next textual content and generate complete comprehension questions and solutions:
{textual content}
Make sure the questions and solutions present deep insights into the textual content's which means, type, and context.
"""
# Ship message and await response
response = await chat_session.send_message_async(full_prompt)
# Extract and clear the textual content response
response_text = response.textual content.strip()
# Try and parse and validate the response
return self._parse_response(response_text)
besides Exception as e:
logger.error(f"Query and reply extraction error: {str(e)}")
logger.error(f"Full response: {response_text}")
increase HTTPException(
status_code=500, element=f"Query-answer extraction failed: {str(e)}"
)_parse_response
def _parse_response(self, response_text: str) -> dict:
"""
Parses and validates the JSON response from the mannequin.
"""
# Take away markdown code blocks if current
response_text = response_text.change("```json", "").change("```", "").strip()
attempt:
# Try and parse JSON
parsed_data = json.masses(response_text)
# Validate the construction
if (
not isinstance(parsed_data, dict)
or "questions_and_answers" not in parsed_data
):
increase ValueError("Response have to be an inventory of questions and solutions.")
return parsed_data
besides json.JSONDecodeError as json_err:
logger.error(f"JSON Decode Error: {json_err}")
logger.error(f"Problematic response: {response_text}")
increase HTTPException(
status_code=400, element="Invalid JSON response from the mannequin"
)
besides ValueError as val_err:
logger.error(f"Validation Error: {val_err}")
increase HTTPException(
status_code=400, element="Invalid question-answer extraction response"
)API Endpoints: Connecting Customers to AI
The primary file defines two main POST endpoint:
It’s a put up methodology that can primarily devour enter knowledge from the shoppers and ship it to the AI APIs by means of the vocabulary Extraction Service. It should additionally verify the enter textual content for minimal phrase necessities and in any case, it would validate the response knowledge utilizing the Pydantic mannequin for consistency and retailer it within the storage.
@app.put up("/extract-vocabulary/", response_model=VocabularyResponse)
async def extract_vocabulary(textual content: str):
# Validate enter
if not textual content or len(textual content.strip()) < 10:
increase HTTPException(status_code=400, element="Enter textual content is just too quick")
# Extract vocabulary
outcome = await vocab_service.extract_vocabulary(textual content)
# Retailer vocabulary in reminiscence
key = hash(textual content)
vocabulary_storage[key] = VocabularyResponse(**outcome)
return vocabulary_storage[key]This put up methodology, can have principally the identical because the earlier POST methodology besides it would use Query Reply Extraction Service.
@app.put up("/extract-question-answer/", response_model=QuestionAnswerResponse)
async def extract_question_answer(textual content: str):
# Validate enter
if not textual content or len(textual content.strip()) < 10:
increase HTTPException(status_code=400, element="Enter textual content is just too quick")
# Extract vocabulary
outcome = await qa_service.extract_questions_and_answers(textual content)
# Retailer outcome for retrieval (utilizing hash of textual content as key for simplicity)
key = hash(textual content)
qa_storage[key] = QuestionAnswerResponse(**outcome)
return qa_storage[key]There are two main GET methodology:
First, the get-vocabulary methodology will verify the hash key with the shoppers’ textual content knowledge, if the textual content knowledge is current within the storage the vocabulary will likely be introduced as JSON knowledge. This methodology is used to indicate the info on the CLIENT SIDE UI on the net web page.
@app.get("/get-vocabulary/", response_model=Non-compulsory[VocabularyResponse])
async def get_vocabulary(textual content: str):
"""
Retrieve the vocabulary response for a beforehand processed textual content.
"""
key = hash(textual content)
if key in vocabulary_storage:
return vocabulary_storage[key]
else:
increase HTTPException(
status_code=404, element="Vocabulary outcome not discovered for the supplied textual content"
)Second, the get-question-answer methodology may even verify the hash key with the shoppers’ textual content knowledge identical to the earlier methodology, and can produce the JSON response saved within the storage to the CLIENT SIDE UI.
@app.get("/get-question-answer/", response_model=Non-compulsory[QuestionAnswerResponse])
async def get_question_answer(textual content: str):
"""
Retrieve the question-answer response for a beforehand processed textual content.
"""
key = hash(textual content)
if key in qa_storage:
return qa_storage[key]
else:
increase HTTPException(
status_code=404,
element="Query-answer outcome not discovered for the supplied textual content",
)Key Implementation Characteristic
To run the appliance, we’ve to import the libraries and instantiate a FastAPI service.
Import Libraries
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from typing import Non-compulsory
from .fashions import VocabularyResponse, QuestionAnswerResponse
from .providers import GeminiVocabularyService, QuestionAnswerServiceInstantiate FastAPI Utility
# FastAPI Utility
app = FastAPI(title="English Educator API")Cross-origin Useful resource Sharing (CORS) Assist
Cross-origin useful resource sharing (CORS) is an HTTP-header-based mechanism that enables a server to point any origins akin to area, scheme, or port aside from its personal from which a browser ought to allow loading assets. For safety causes, the browser restricts CORS HTTP requests initiated from scripts.
# FastAPI Utility
app = FastAPI(title="English Educator API")
# Add CORS middleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)In-memory validation mechanism: Easy Key Phrase Storage
We use easy key-value-based storage for the undertaking however you should use MongoDB.
# Easy key phrase storage
vocabulary_storage = {}
qa_storage = {}Enter Validation mechanisms and Complete error dealing with.
Now’s the time to run the appliance.
To run the appliance in growth mode, we’ve to make use of FasyAPI CLI which can put in with the FastAPI.
Kind the code to your terminal within the software root.
$ fastapi dev important.pyOutput:
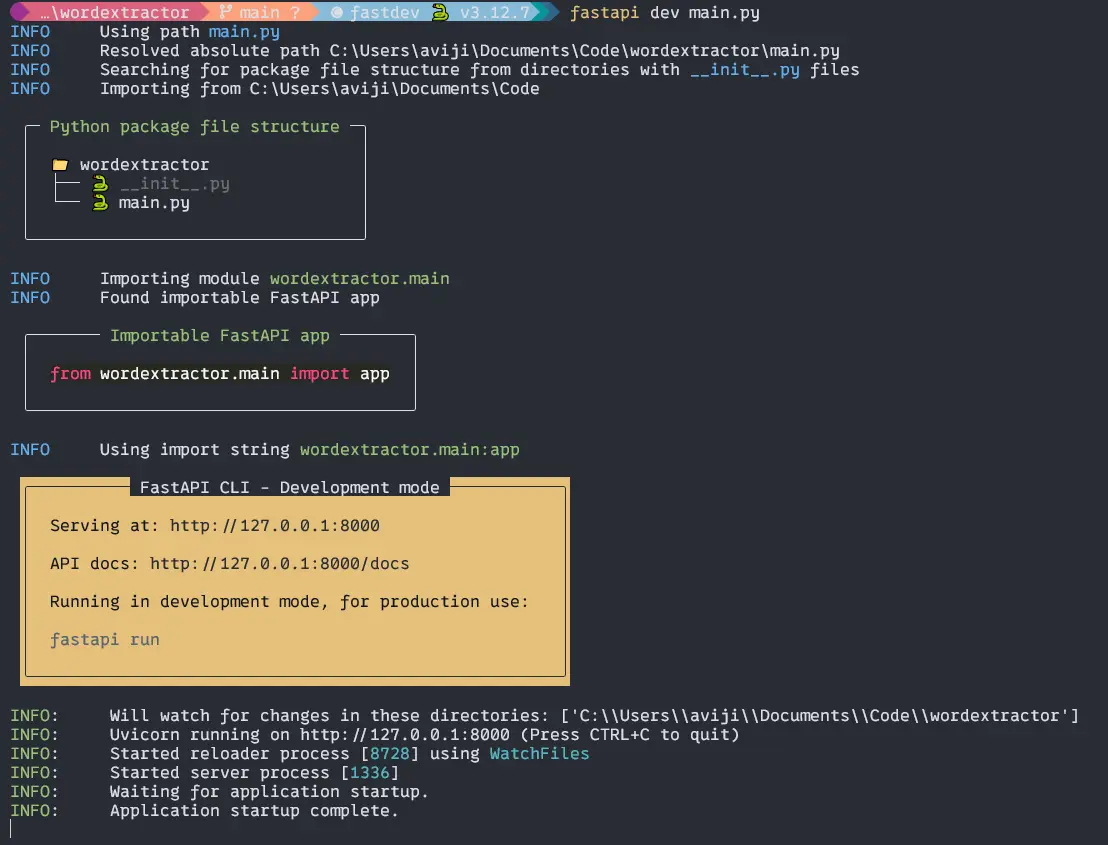
Then if you happen to CTRL + Proper Click on on the hyperlink http://127.0.0.1:8000 you’re going to get a welcome display on the net browser.

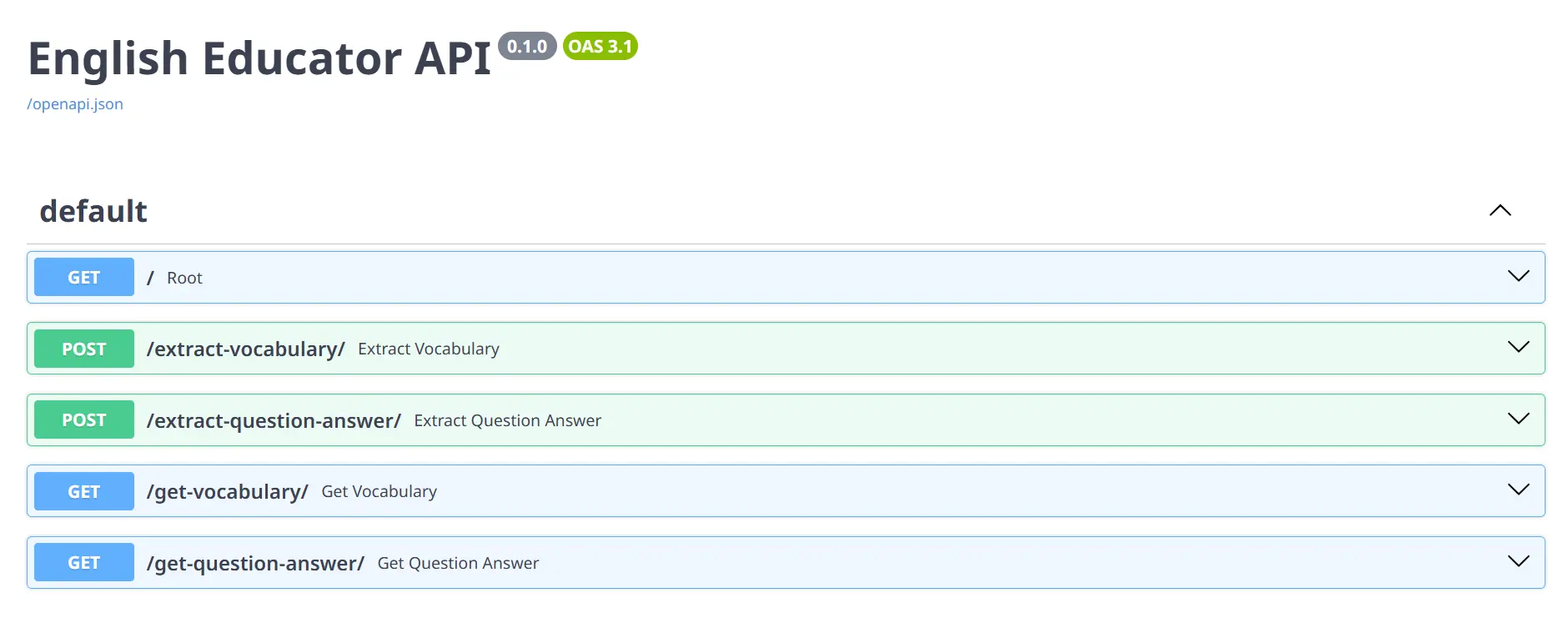
To go to the docs web page of FastAPI simply click on on the subsequent URL or kind http://127.0.0.1:8000/docs in your browser, and you will note all of the HTTP strategies on the web page for testing.
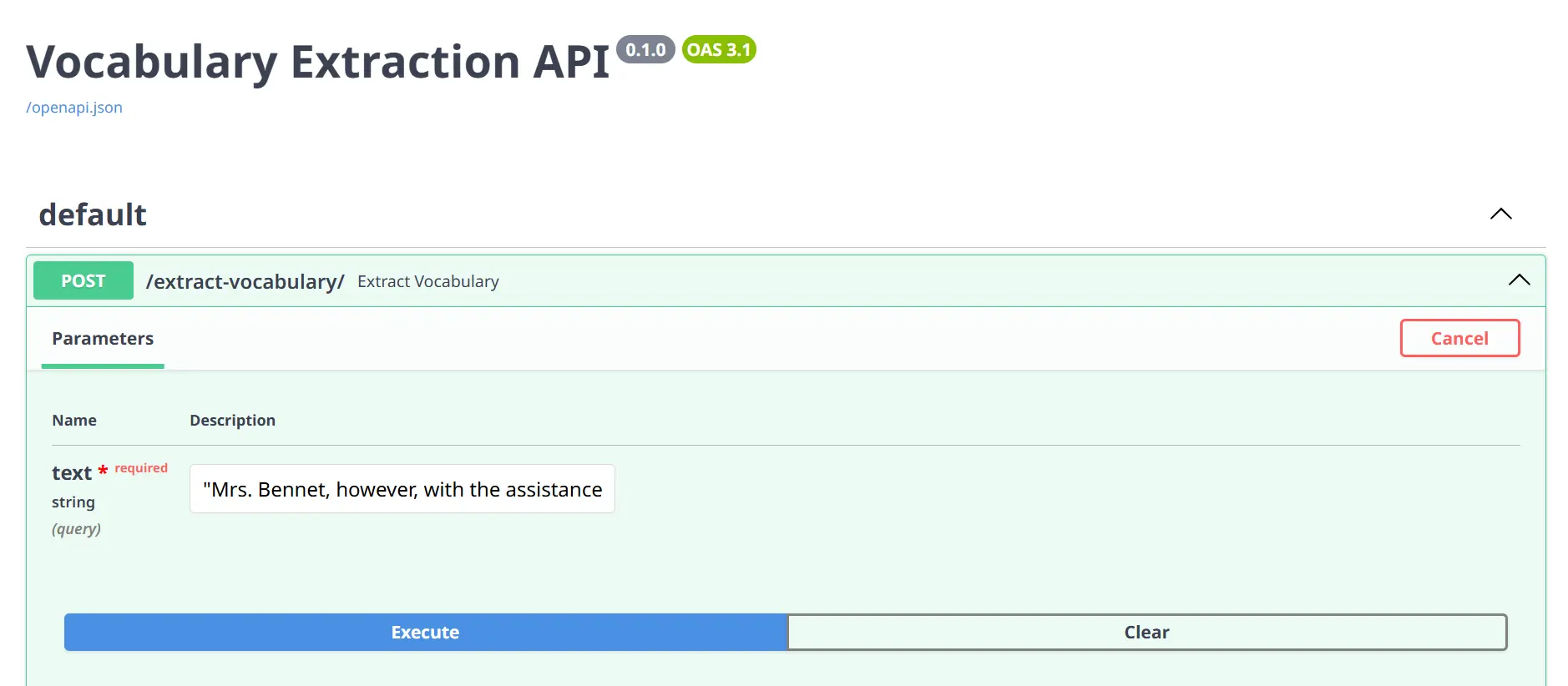
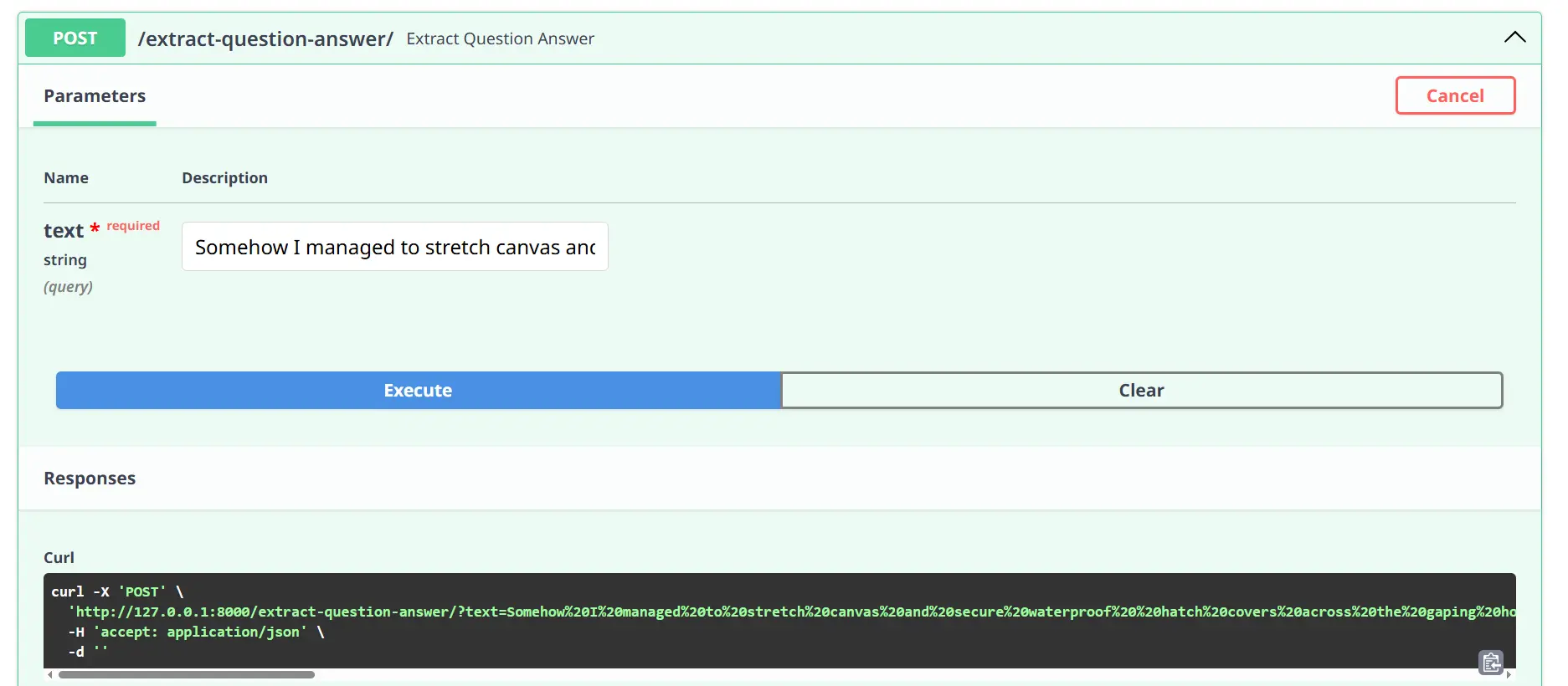
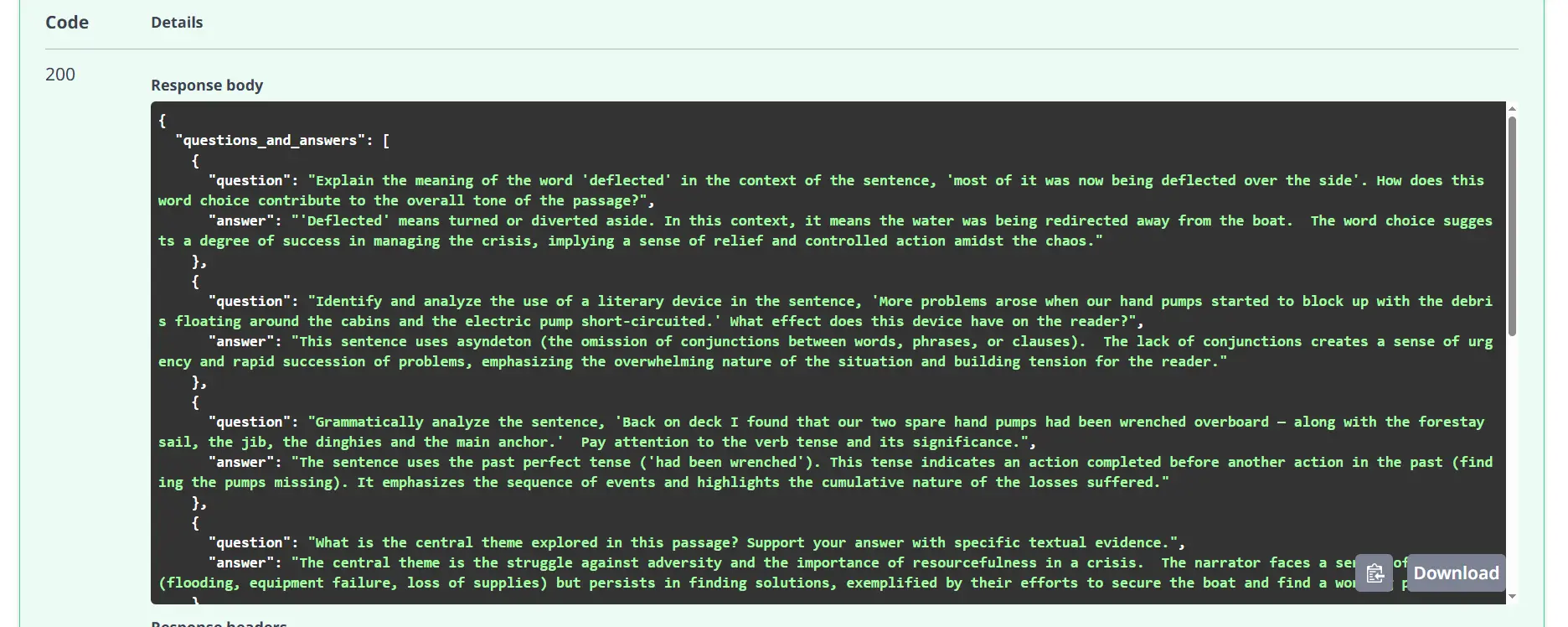
Now to check the API, Click on on any of the POST strategies and TRY IT OUT, put any textual content you wish to within the enter area, and execute. You’re going to get the response in keeping with the providers akin to vocabulary, and query reply.
Execute:
Response:
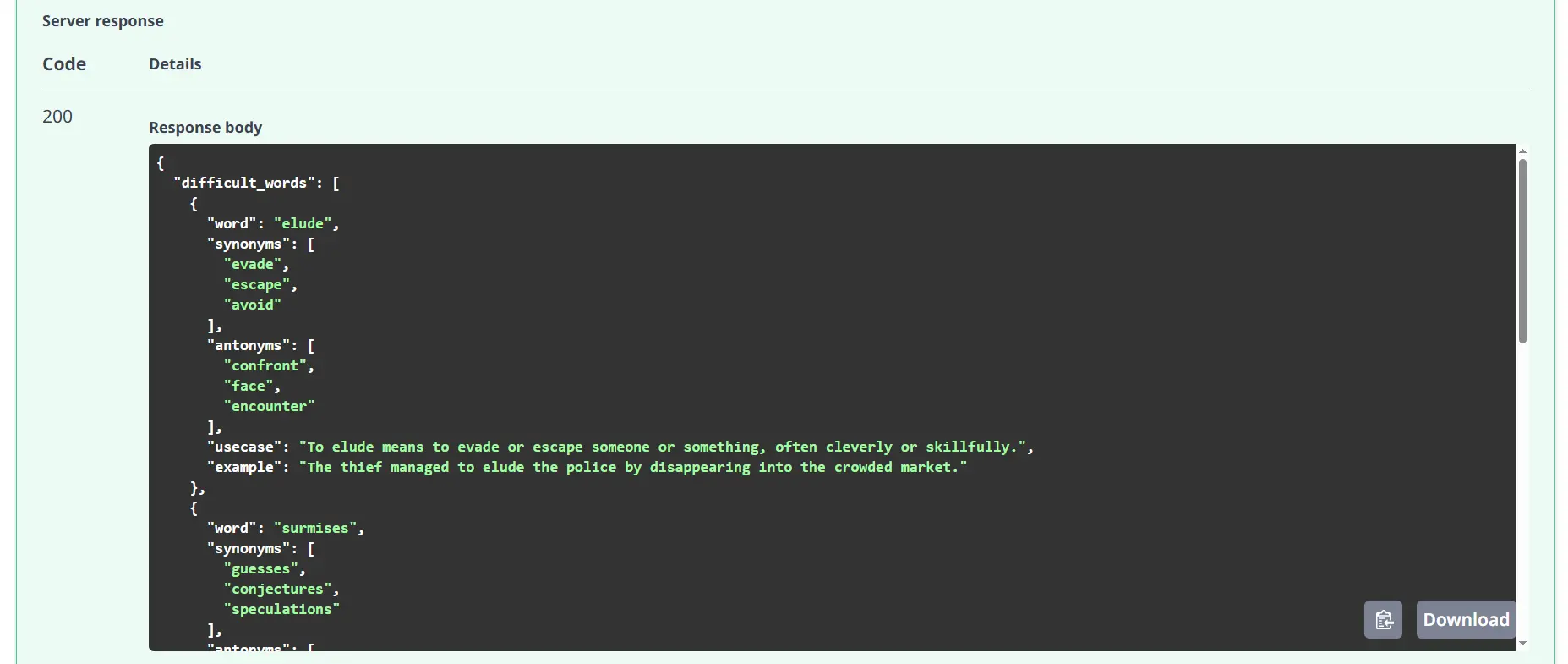
Execute:
Response:
Testing Get Strategies
Get vocabulary from the storage.
Execute:
Put the identical textual content you placed on the POST methodology on the enter area.
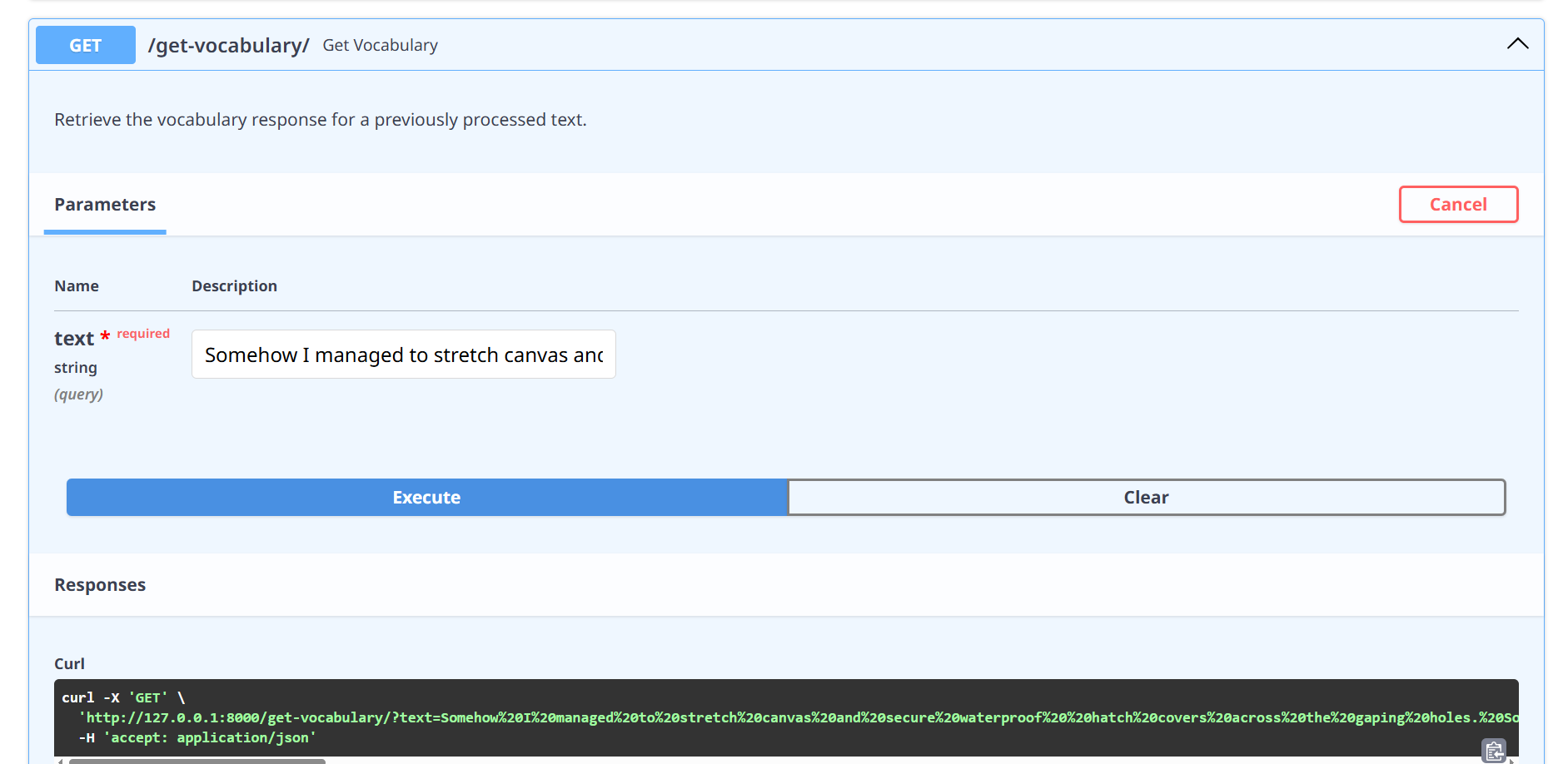
Response:
You’re going to get the under output from the storage.
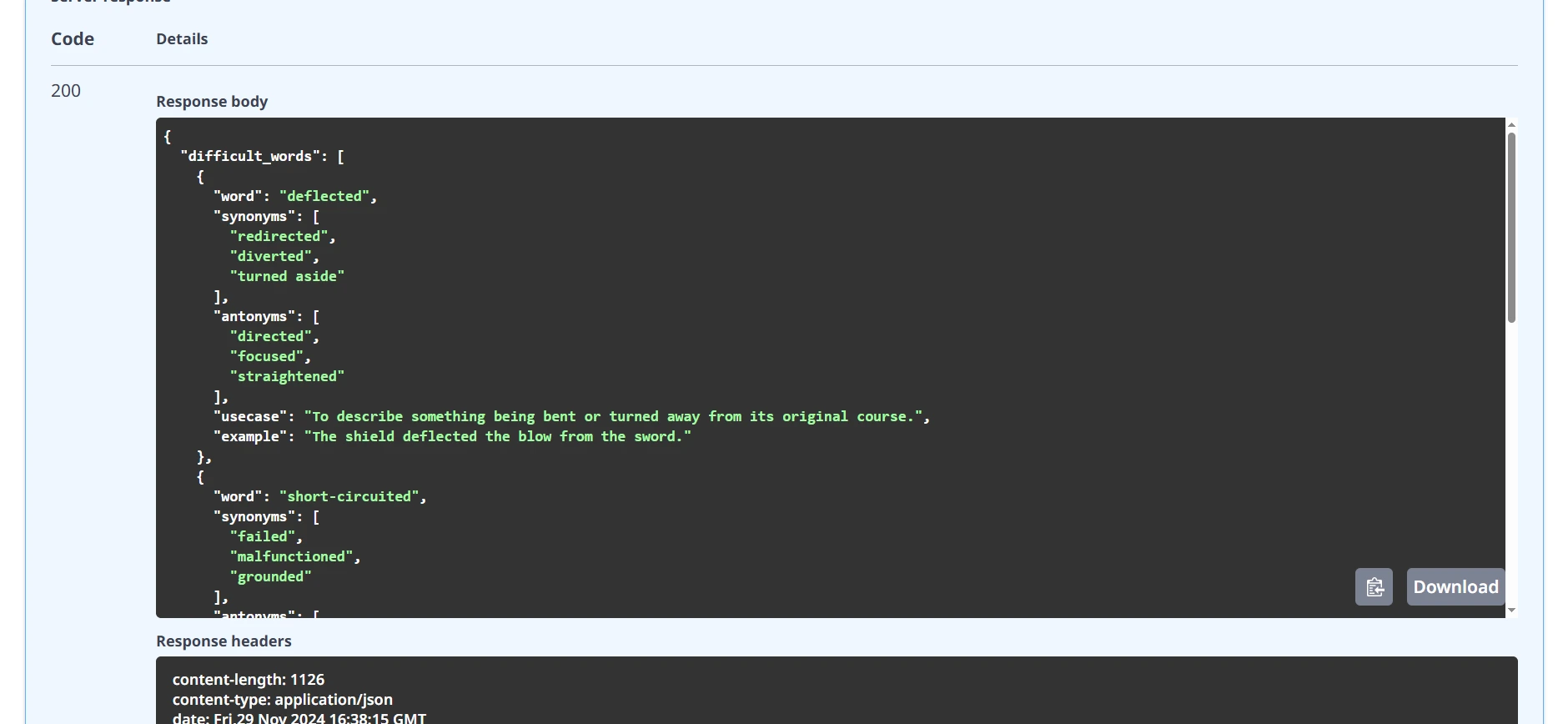
and in addition for question-and-answer
Execute:
Response:
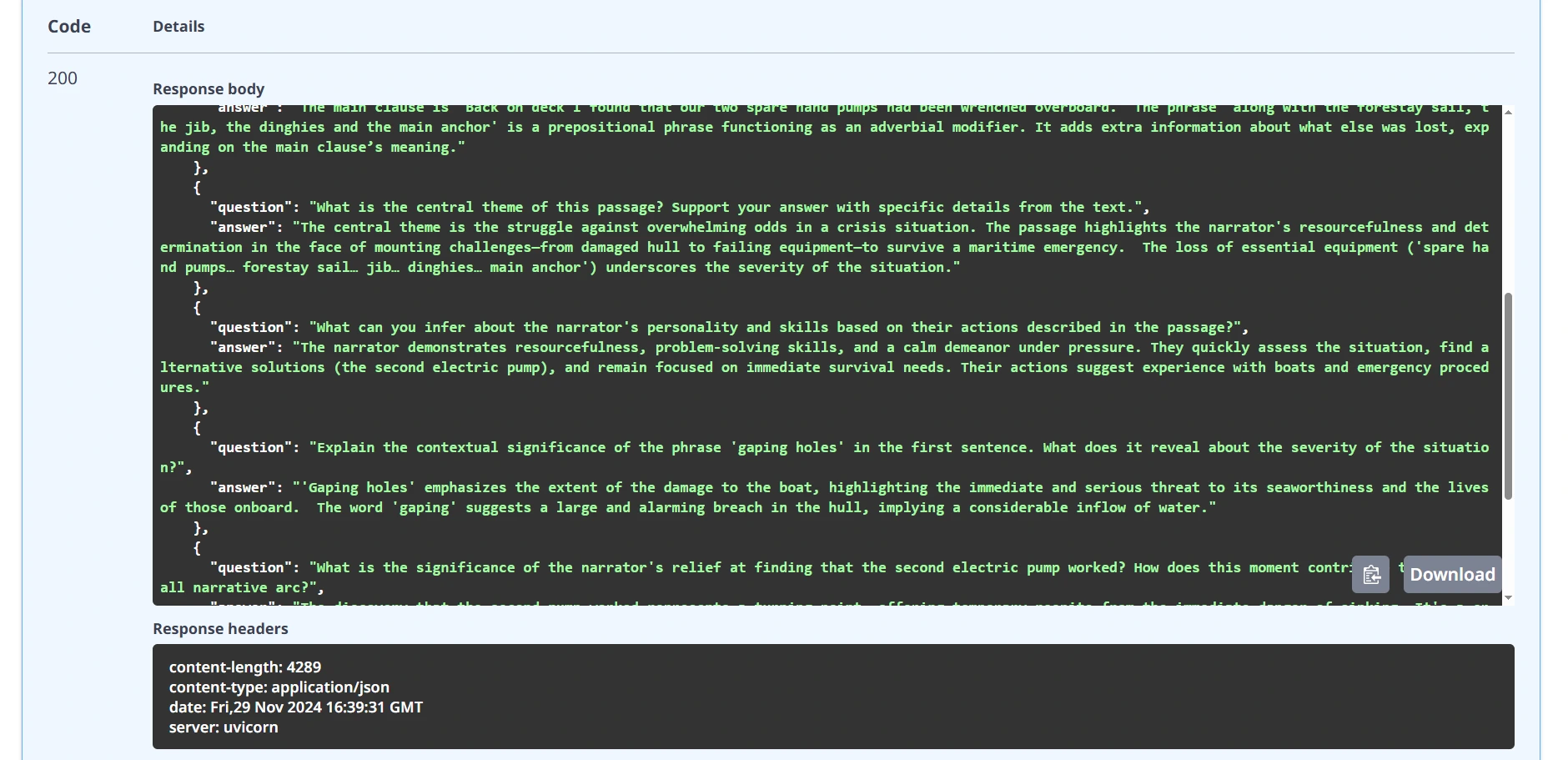
That will likely be totally operating net server API for English educators utilizing Google Gemini AI.
Additional Improvement Alternative
The present implementation opens doorways to thrilling future enhancements:
- Discover persistent storage options to retain knowledge successfully throughout classes.
- Combine sturdy authentication mechanisms for enhanced safety.
- Advance textual content evaluation capabilities with extra subtle options.
- Design and construct an intuitive front-end interface for higher consumer interplay.
- Implement environment friendly charge limiting and caching methods to optimize efficiency.
Sensible Issues and Limitations
Whereas our API demonstrates highly effective capabilities, it is best to contemplate:
- Take into account API utilization prices and charge limits when planning utilization to keep away from surprising fees and guarantee scalability.
- Be conscious of processing time for complicated texts, as longer or intricate inputs might lead to slower response instances.
- Put together for steady mannequin updates from Google, which can affect the API’s efficiency or capabilities over time.
- Perceive that AI-generated responses can fluctuate, so it’s vital to account for potential inconsistencies in output high quality.
Conclusion
Now we have created a versatile, clever API that transforms textual content evaluation by means of the synergy of Google Gemini, FastAPI, and Pydantic. This answer demonstrates how trendy AI applied sciences could be leveraged to extract deep, significant insights from textual knowledge.
You will get all of the code of the undertaking within the CODE REPO.
Key Takeaways
- AI-powered APIs can present clever, context-aware textual content evaluation.
- FastAPI simplifies complicated API growth with computerized documentation.
- The English Educator App API empowers builders to create interactive and customized language studying experiences.
- Integrating the English Educator App API can streamline content material supply, bettering each instructional outcomes and consumer engagement.
Steadily Requested Query
A. The present model makes use of environment-based API key administration and contains elementary enter validation. For manufacturing, extra safety layers are beneficial.
A. At all times evaluate Google Gemini’s present phrases of service and licensing for industrial implementations.
A. Efficiency is determined by Gemini API response instances, enter complexity, and your particular processing necessities.
A. The English Educator App API supplies instruments for educators to create customized language studying experiences, providing options like vocabulary extraction, pronunciation suggestions, and superior textual content evaluation.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Creator’s discretion.
A self-taught, project-driven learner, like to work on complicated tasks on deep studying, Laptop imaginative and prescient, and NLP. I at all times attempt to get a deep understanding of the subject which can be in any area akin to Deep studying, Machine studying, or Physics. Like to create content material on my studying. Attempt to share my understanding with the worlds.