

{kind=link}
Buyer expectations for meals labeling have undergone a basic shift. In response to a current survey, three-quarters of U.S. consumers now demand complete details about the meals they purchase, and practically two-thirds scrutinize labels extra fastidiously than they did 5 years in the past. This is not a passing pattern, however moderately is pushed by extra households managing allergy symptoms and intolerances, and extra consumers dedicated to particular diets, comparable to vegan, vegetarian, or gluten-free.
However here is the problem: solely 16% of customers belief well being claims from meals producers. Which means consumers wish to consider merchandise themselves, on their very own phrases. They’re scanning ingredient lists and thoroughly reviewing bundle labels to higher perceive sourcing, manufacturing practices, vitamin, and the way these align with their particular well being wants as a part of their buying determination.
Whereas regulators work on up to date labeling necessities, main retailers are already taking motion. They’re utilizing superior knowledge extraction and ingredient analytics to remodel packaging and vitamin labels into searchable, filterable digital experiences. This lets clients discover precisely what they want, whether or not that is allergen-free choices, gluten-free merchandise, or sustainably sourced objects. These transparency initiatives not solely differentiate these retailers from their opponents but in addition drive deeper buyer engagement and increase gross sales, particularly of higher-margin merchandise.
The Information + AI Resolution
It’s difficult to maintain up with the 35,000 distinctive SKUs present in a typical U.S. grocery retailer, with 150 to 300 new ones launched month-to-month. However with as we speak’s agentic AI purposes, now you can automate meals label studying at scale and at an inexpensive value.
With photos of nutrient labels offered as inputs, these methods parse the photographs to extract uncooked ingredient and vitamin info. This info is then processed into structured knowledge that may energy each inner analytics and customer-facing digital experiences. From these knowledge, you’ll be able to then create customized classifications for allergens, ultra-processed substances, sustainability attributes, and life-style preferences, precisely what you should help your clients.
On this weblog, we’ll present you learn how to implement an end-to-end course of utilizing Databricks’ Agent Bricks capabilities to simplify and streamline the event and deployment of an automatic meals label reader to your group.
Constructing the Resolution
Our meals label studying workflow is fairly easy (Determine 1). We are going to load photos taken from meals packages into an accessible storage location, use AI to extract textual content from the photographs and convert it right into a desk, after which apply AI to align the extracted textual content to a identified schema.

In our first step, we accumulate quite a lot of photos of product packages displaying ingredient lists, just like the one proven in Determine 2. These photos in .png, .jpeg, or .pdf format are then loaded right into a Unity Catalog (UC) quantity, making them out there inside Databricks.

With our photos loaded, we choose Brokers from the left-hand menu of the Databricks workspace and navigate to the Data Extraction agent proven on the high of the web page (Determine 3).

The Data Extraction agent offers us with two choices: Use PDFs and Construct. We are going to begin by choosing the Use PDFs choice, which is able to permit us to outline a job extracting textual content from numerous picture codecs. (Whereas the .pdf format is indicated within the title of the choice chosen, different normal picture codecs are supported.)
Clicking the Use PDFs choice, we’re offered with a dialog whereby we are going to establish the UC quantity by which our picture recordsdata reside and the title of the (as of but non-existing) desk into which extracted info will probably be loaded (Determine 4)

Clicking the Begin Import button launches a job that extracts textual content particulars from the photographs in our UC quantity and hundreds them into our goal desk. (We are going to return to this job as we transfer to operationalize our workflow). The ensuing desk accommodates a area figuring out the file from which textual content has been extracted, together with a struct (JSON) area and a uncooked textual content area containing the textual content info captured from the picture (Determine 5).

Reviewing the textual content info delivered to our goal desk, we are able to see the complete vary of content material extracted from every picture. Any textual content readable from the picture is extracted and positioned within the raw_parsed and textual content fields for our entry.
As we’re solely within the textual content related to the substances record present in every picture, we might want to implement an agent to slender our focus to pick out parts of the extracted textual content. To do that, we return to the Brokers web page and click on the Construct choice related to the Data Extraction agent. Within the ensuing dialog, we establish the desk to which we beforehand landed our extracted textual content and establish the textual content area in that desk because the one containing the uncooked textual content we want to course of (Determine 6).

The agent will try to infer a schema for the extracted textual content and current knowledge parts mapped to this schema as pattern JSON output on the backside of the display screen. We will settle for the information on this construction or manually reorganize the information as a JSON doc of our personal definition. If we take the latter method (as will most frequently be the case), we merely paste the re-organized JSON into the output window, permitting the agent to deduce another schema for the textual content knowledge. It would take a number of iterations for the agent to ship precisely what you need from the information.
As soon as we now have the information organized the best way we wish it, we click on the Create Agent button to finish the construct. The UI now shows parse output from throughout a number of information, permitting us a possibility to validate its work and make additional modifications to reach at a constant set of outcomes (Determine 7).

Along with validating the schematized textual content, we are able to add further fields utilizing easy prompts that study our knowledge to reach at a worth. For instance, we’d search our ingredient record for objects more likely to comprise gluten to deduce if a product is gluten-free or establish animal-derived substances to establish a product as vegan-friendly. The agent will mix our knowledge with data embedded in an underlying mannequin to reach at these outcomes.
Clicking Save and Replace saves our adjusted agent. We will use the High quality Report and Optimization tabs to additional improve our agent as described right here. As soon as we’re glad with our agent, we click on Use to finish our construct. Deciding on the Create ETL Pipeline choice will generate a declarative pipeline that may permit us to operationalize our workflow.
Word: You possibly can watch a video demonstration of the next steps right here.
Operationalizing the Resolution
At this level, we now have outlined a job for extracting textual content from photos and loading it right into a desk. Now we have additionally outlined an ETL pipeline for mapping the extracted textual content to a well-defined schema. We will now mix these two parts to create an end-to-end job by which we are able to course of photos on an ongoing foundation.
Returning to the job created in our first step, i.e. Use PDFs, we are able to see this job consists of a single step. This step is outlined as a SQL question that makes use of a generative AI mannequin by means of a name to the ai_query() operate. What’s good about this method is that it makes it easy for builders to customise the logic surrounding the textual content extract step, comparable to modifying to logic to solely course of new recordsdata within the UC quantity.
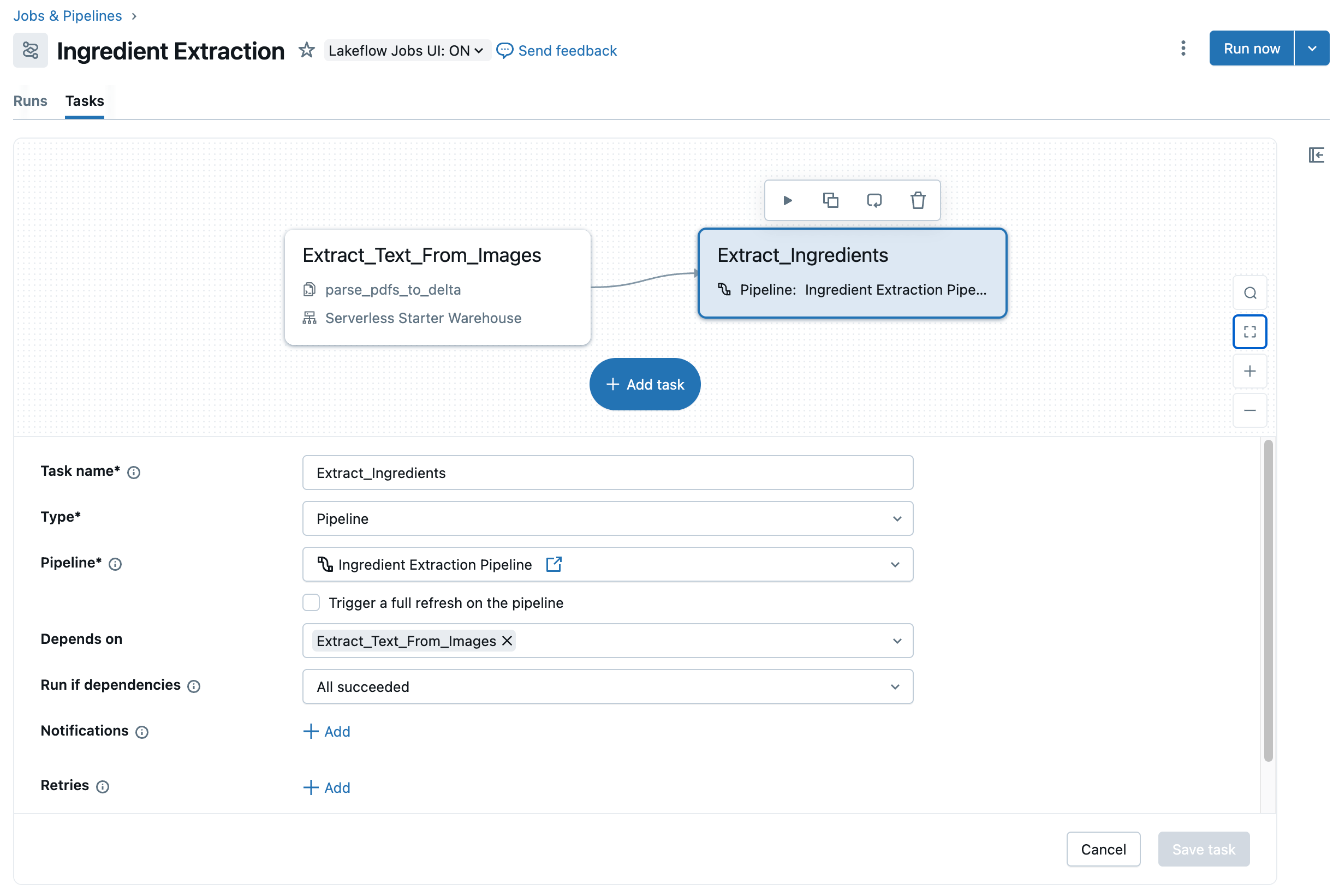
Assuming we’re glad with the logic in step one of our job, we are able to now add a subsequent step to the job, calling the ETL pipeline we outlined beforehand. The high-level actions required for this are discovered right here. The top result’s we now have a two-step job capturing our end-to-end workflow for ingredient record extraction that we are able to now schedule to run on an ongoing foundation (Determine 8).
Get Began Right now
Utilizing Databricks’ new Agent Bricks functionality, it’s comparatively straightforward to construct agentic workflows able to tackling beforehand difficult or cumbersome handbook duties. This opens up a spread of prospects for organizations able to automate doc processing at scale, whether or not for meals labels, provider compliance, sustainability reporting, or another problem involving unstructured knowledge.
Able to construct your first agent? Begin with Agent Bricks as we speak and expertise what main organizations have already found: automated optimization, no-code improvement, and production-ready high quality in hours as a substitute of weeks. Go to your Databricks workspace, navigate to the Brokers web page, and remodel your doc intelligence operations with the identical confirmed expertise that is already processing tens of millions of paperwork for enterprise clients worldwide.
- Begin constructing your first agent with Agent Bricks as we speak in your Databricks workspace
- Expertise no-code improvement and production-ready high quality in hours as a substitute of weeks