
{kind=link}
Nicely, that was fast. Barely a 12 months after Kafka-compatible streaming startup WarpStream Labs opened its digital doorways, it’s been acquired by Confluent, the business outfit behind Apache Kafka. The large get for Confluent is WarpStream’s S3-based knowledge streaming providing, which WarpStream claims eliminates the costly inter-networking charges that plagues Kafka within the cloud. Confluent additionally takes out a possible competitor.
WarpStream Labs was based in July 2023 by two Datadog engineers, Richard Artoul and Ryan Worl, with the purpose of delivering a quick cloud-native knowledge streaming platform that was absolutely suitable with Apache Kafka, which continues to dominate the streaming knowledge panorama. Artoul, who’s the CEO, described the Chicago-based firm’s distinctive streaming structure in his introductory weblog put up, appropriately titled “Kafka is lifeless, lengthy dwell Kafka.”
“WarpStream is an Apache Kafka protocol suitable knowledge streaming platform constructed instantly on high of S3,” Artoul writes. “It’s delivered as a single, stateless Go binary so there are not any native disks to handle, no brokers to rebalance, and no ZooKeeper to function. WarpStream is 5-10x cheaper than Kafka within the cloud as a result of knowledge streams on to and from S3 as a substitute of utilizing inter-zone networking, which could be over 80% of the infrastructure value of a Kafka deployment at scale.”

WarpStream CEO and co-founder Richard Artoul
The motion of Kafka knowledge inside an Availability Zone is an actual downside for the Kafka structure, Artoul says, and finally contributes to knowledge storage prices which can be about 10-20x extra per GiB than S3 storage.
“Kafka was designed to run in LinkedIn’s knowledge facilities, the place the community engineers didn’t cost their utility builders for shifting knowledge round,” Artoul wrote in his introductory weblog. “However as we speak, most Kafka customers are working it on a public cloud, an surroundings with fully totally different constraints and price fashions. Sadly, except your group can decide to 10s or 100s of hundreds of thousands of {dollars} per 12 months in cloud spend, there isn’t a escaping the physics of this downside.”
As a substitute of constructing customized instruments to assist automate the administration of Kafka knowledge, Artoul and Worl determined to take a radically simiplified strategy. They had been knowledgeable by their work at DataDog, the place they constructed a columnar database for observability knowledge working instantly on S3. “Once we had been carried out, we had a (largely) stateless and auto scaling knowledge lake that was extraordinarily value efficient, by no means ran out of disk area, and was trivial to function,” he write. “Virtually in a single day our Kafka clusters immediately seemed historic by comparability.”
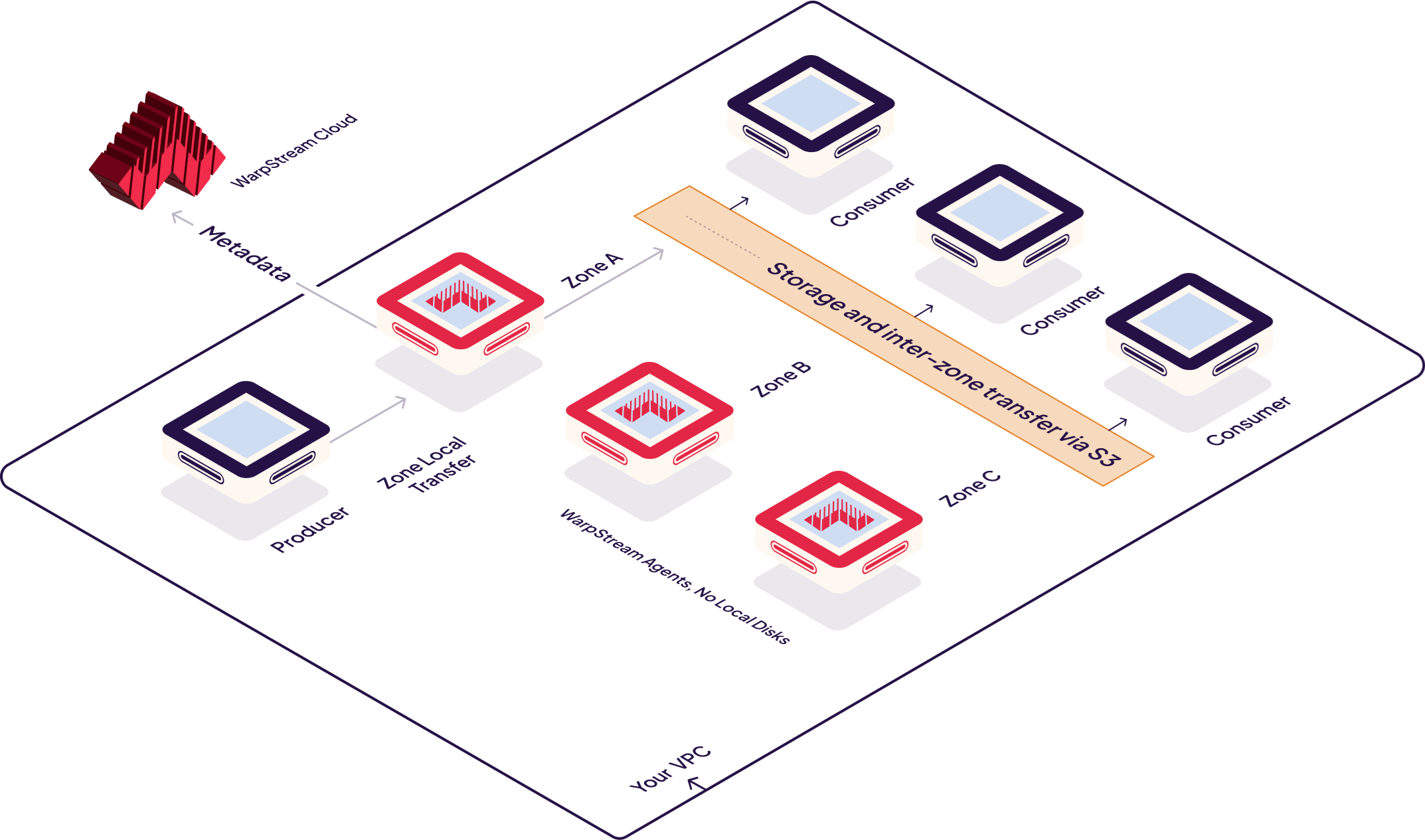
WarpStream Cloud structure (Picture courtesy WarpStream Labs)
By growing WarpStream round S3, Artoul and Worl felt they had been following within the footsteps of Databricks and Snowflake, which “lean into cloud economics by designing their programs from teh floor up round commity object storage.”
WarpStream Labs was rising its BYOC providing and had a full complement of options it was wanting so as to add. It has raised $20 million in enterprise capital, and had greater than a dozen staff, along with corporations like Grafana Labs, Zomato, PostHog, and others. Then Jay Kreps, the CEO and co-founder of Confluent and one of many co-creators of Kafka, got here calling on the 2 founders.
Kreps appreciated the BYOC strategy that WarpStream had taken, notably because it pertains to enabling clients to keep up management of their knowledge whereas additionally delivering a completely managed expertise in in clients’ personal cloud accounts. That was one thing that Confluent had been engaged on, too.
“Once we checked out merchandise that labored this fashion they had been typically the worst of each worlds: self-managed knowledge programs that had been forklifted into the cloud with semi-managed fashions that left accountability for safety and uptime fairly obscure,” Kreps wrote in a weblog put up yesterday.
It was WarpStream’s “distinctive architectural strategy” that caught Kreps’ consideration, and what finally led to a gathering in New York a couple of months again. That assembly finally culminated in a deal getting carried out, and yesterday’s acquisition announcement, the phrases of which weren’t disclosed.

WarpStream prices vs hosted and self-managed Kafka (Picture courtesy WarpStream)
Confluent’s plan requires the WarpStream product to proceed to be developed and supported. It’s going to sit smack dab in the midst of the Confluent lineup, proper between Confluent Platform, which delivers plenty of management however is troublesome to handle, and Confluent Cloud, which is simple to handle however doesn’t provide quite a lot of management.
“I’ve been deeply impressed with WarpStream–it’s BYOC carried out proper,” Kreps says in a press launch. “With this acquisition, we’ve an information streaming providing for everybody.”
Particularly, Confluent sees WarpStream being adopted by organizations working “massive scale workloads with relaxed latency necessities in their very own cloud surroundings.” That would come with issues like processing enormous observability streams and loading knowledge lakes.
“At the moment the WarpStream product remains to be a younger startup product, so it received’t instantly be a match for all clients,” Kreps says within the weblog, “however we plan to spend money on safety and hardening over time to carry it as much as the identical enterprise-grade requirements as Confluent Platform and Confluent Cloud, in addition to combine it into our programs for ease of signup, billing, and account administration.
There may also be some sharing of parts between WarpStream and the Confluent-developed merchandise, together with issues like knowledge connectors, stream processing, and governance options, Kreps says.
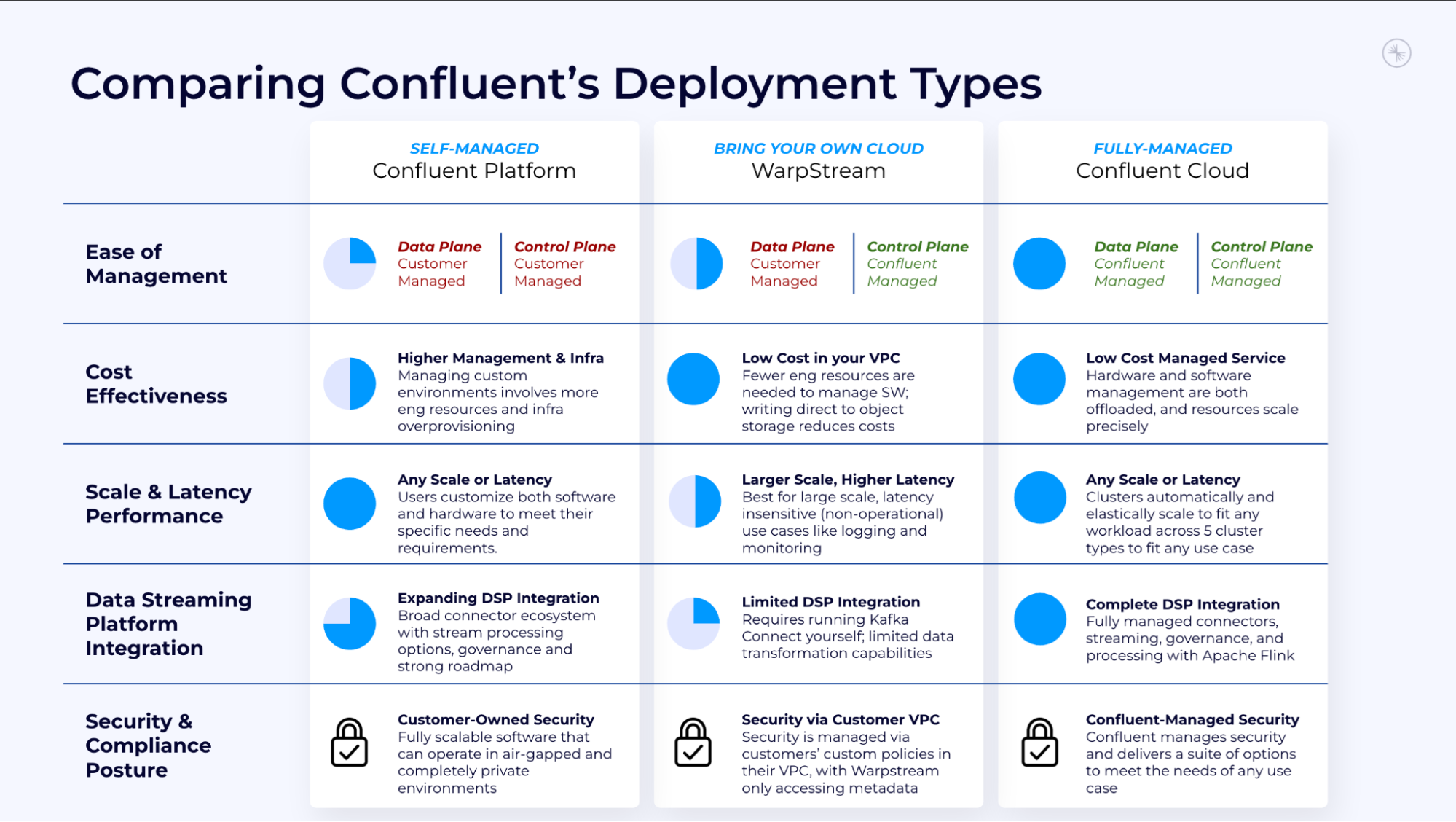
(Picture courtesy Confluent)
In the meantime, the WarpStream crew has a full listing of options they’re engaged on, together with assist for Kafka transactions, cluster quotas, a BYOC schema registry, a mirroring product known as Orbit, active-active multi-region clusters, and buyer management planes for Google Cloud and Azure (it at present solely helps AWS).
“Many bulletins like this proceed to lament that the product is shutting down or radically altering, however we’re doing fairly the other,” Artoul wrote in his weblog put up as we speak, appropriately titled “WarpStream Is Lifeless, Lengthy Dwell WarpStream.” WarpStream is about to get higher–lots higher–with the assets and backing of the chief in streaming.”
Associated Gadgets:
Confluent Provides Flink, Iceberg to Hosted Kafka Service
Confluent Works to Conceal Streaming Complexity
Confluent Expands Apache Flink Capabilities to Simplify AI and Stream Processing