

{kind=link}
Apache Iceberg, a high-performance open desk format (OTF), has gained widespread adoption amongst organizations managing giant scale analytic tables and information volumes. Iceberg brings the reliability and ease of SQL tables to information lakes whereas enabling engines like Apache Spark, Apache Trino, Apache Flink, Apache Presto, Apache Hive, Apache Impala, and AWS analytic providers like Amazon Athena to flexibly and securely entry information with lakehouse structure. Whereas the lakehouse constructed utilizing Iceberg represents an evolution to the information lake, nevertheless it nonetheless requires providers to compact and optimize the information and partitions that comprise the tables. Self-managing Iceberg tables with giant volumes of knowledge poses a number of challenges, together with managing concurrent transactions, processing real-time information streams, dealing with small file proliferation, sustaining information high quality and governance, and guaranteeing compliance.
At re:Invent 2024, Amazon S3 launched Amazon S3 Tables marking the primary cloud object retailer with native Iceberg assist for Parquet information, designed to streamline tabular information administration at scale. Parquet is without doubt one of the most typical and quickest rising information varieties in Amazon S3. Amazon S3 shops exabytes of Parquet information, and averages over 15 million requests per second to this information. Whereas S3 Tables initially supported Parquet file kind, as mentioned within the S3 Tables AWS Information Weblog, the Iceberg specification extends to Avro, and ORC file codecs for managing giant analytic tables. Now, S3 Tables is increasing its capabilities to incorporate computerized compaction for these further file varieties inside Iceberg tables. This enhancement can also be out there for Iceberg tables on normal goal S3 buckets, utilizing the lakehouse structure of Amazon SageMaker that beforehand supported Parquet compaction as lined within the weblog submit Speed up queries on Apache Iceberg tables via AWS Glue auto compaction.
This weblog submit explores the efficiency advantages of computerized compaction of Iceberg tables utilizing Avro and ORC file varieties in S3 Tables for a knowledge ingestion use with over 20 billion occasions.
Parquet, ORC, and Avro file codecs
Parquet is without doubt one of the most typical and quickest rising information varieties in Amazon S3. It was initially developed by Twitter and now a part of the Apache ecosystem, is understood for its broad compatibility with large information instruments reminiscent of Spark, Hive, Impala, and Drill. Amazon S3 shops exabytes of Apache Parquet information, and averages over 15 million requests per second to this information. Parquet makes use of a hybrid encoding scheme and helps advanced nested information constructions, making it ultimate for read-heavy workloads and analytics throughout numerous platforms. Parquet additionally supplies glorious compression and environment friendly I/O by enabling selective column reads, lowering the quantity of knowledge scanned throughout queries.
ORC was particularly designed for Hadoop ecosystem and optimized for Hive. It usually affords higher compression ratios and higher learn efficiency for sure forms of queries resulting from its light-weight indexing and aggressive predicate pushdown capabilities. ORC consists of built-in statistics and helps light-weight indexes, which might speed up filtering operations considerably. Whereas Parquet affords broader instrument compatibility, ORC typically outperforms it inside Hive-centric environments, particularly when coping with flat information constructions and enormous sequential scans.
Avro file format is often utilized in streaming situations for its serialization and schema dealing with capabilities and for its seamless integration with Apache Kafka, providing a robust mixture for dealing with real-time information streams. For instance, for storing and validating streaming information schemas, you have got the choice of utilizing AWS Glue Schema registry in AWS. Avro, in distinction with Parquet and ORC, is a row-based storage format designed for environment friendly information serialization and schema evolution. Avro excels in write-heavy use circumstances like information ingestion and streaming and is usually used with Kafka. Not like Parquet and ORC, that are optimized for analytical queries, Avro is designed for quick reads and writes of full information, and it shops the schema alongside the information, enabling simpler information change and evolution over time.
Under is a comparability of those 3 file codecs.
| Parquet | ORC | Avro | |
| Storage format | Columnar | Columnar | Row-based |
| Greatest for | Analytics & queries throughout columns | Hive-based queries, heavy compression | Information ingestion, streaming, serialization |
| Compression | Good | Glorious (particularly numerical information) | Average |
| Software compatibility | Broad (Spark, Hive, Presto, and so forth.) | Robust with Hive/Hadoop | Robust with Kafka, Flink, and so forth. |
| Question efficiency | Superb for analytics | Glorious in Hive | Not optimized for analytics |
| Schema evolution | Supported | Supported | Glorious (schema saved with information) |
| Nested information assist | Sure | Restricted | Sure |
| Write effectivity | Average | Average | Excessive |
| Learn effectivity | Excessive (for columnar scans) | Very excessive (in Hive) | Excessive (for full file reads) |
Resolution Overview
We run two variations of the identical structure: one the place the tables are auto compacted, and one other with out compaction utilizing on this case S3 Tables. By evaluating each situations, this submit demonstrates the effectivity, question efficiency, and price advantages of auto compacted tables vs. non-compacted tables in a simulated Web of Issues (IoT) information pipeline. The next diagram illustrates the answer structure.
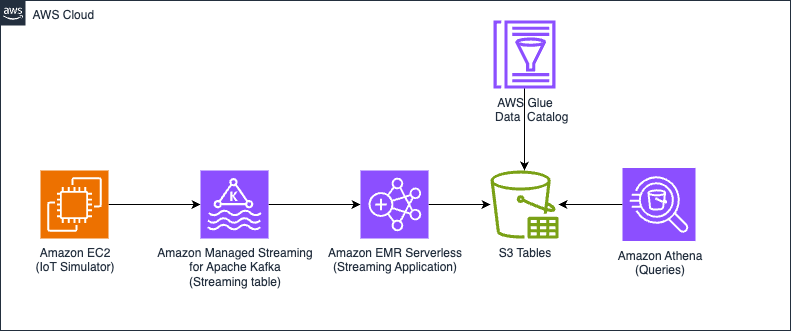
Determine 1 – Resolution structure diagram
Compaction efficiency take a look at
We simulated IoT information ingestion with over 20 billion occasions and used MERGE INTO for information deduplication throughout two time-based partitions, involving heavy partition reads and shuffling. After ingestion, we ran queries in Athena to match efficiency between compacted and uncompacted tables utilizing the Merge on Learn (MoR) mode on each Avro and ORC codecs. We use the next desk configuration settings:
We use 'write.distribution.mode=hash' to generate greater information that can profit the efficiency. Notice that as we’re producing fairly giant information already the variations between un-compacted and compacted tables are usually not going to that large, it will change considerably relying in your workload (for instance, partitioning, enter charge, batch dimension) and your chosen write distribution mode. For extra particulars, please consult with the Writing Distribution Modes part within the Apache Iceberg documentation.
The next desk reveals metrics of the Athena question efficiency. Please consult with part “Question and Be a part of information from these S3 Tables to construct insights” for question particulars. All desk sizes used to research the question efficiency are over 2 billion rows. These outcomes are particular to this simulation train and the readers’ outcomes could fluctuate relying on their information dimension and queries they’re working.
| Question | Avro question time compaction | Avro question time with out compaction | ORC question time with out compaction | ORC question time with compaction | % enchancment Avro | % enchancment ORC |
| Question 1 | 22.45 secs | 26.54 secs | 30.16 secs | 20.32 secs | 15.41% | 32.63% |
| Question 2 | 22.68 secs | 25.83 secs | 34.17 secs | 20.51 secs | 12.20% | 39.98% |
| Question 3 | 25.92 secs | 35.65 secs | 29.05 secs | 24.95 secs | 27.29% | 14.11% |
Stipulations
To arrange your personal analysis setting and take a look at the function, you want the next stipulations.
AWS account with entry to the next AWS providers:
Create S3 desk bucket and allow integration with AWS analytics providers
Go to S3 console and allow desk buckets function.
Then select the Create desk bucket button, fill Desk bucket title with any bucket title you like, choose the Allow integration checkbox, then select Create desk bucket.
Arrange Amazon S3 storage
Create an S3 bucket with the next construction:
Obtain the descriptor file worker.desc from the GitHub repo and put it into the S3 bucket you simply created.
Obtain the appliance on the releases web page
Get the packaged utility S3Tables-Avro-orc-auto-compaction-benchmark-0.1 from the GitHub repo, then add the JAR file to the “jars” listing on the S3 bucket. Checkpoint can be used for the Structured Streaming checkpointing mechanism. As a result of we use 4 streaming job runs, one for compacted and one for uncompacted information on every format, we additionally create a “checkpointAuto” folder for each.
Create an EMR Serverless utility
Create an EMR Serverless utility with the next settings (for directions, see Getting began with Amazon EMR Serverless):
- Sort: Spark
- Model: 7.20
- Structure: x86_64
- Java Runtime: Java 17
- Metastore Integration: AWS Glue Information Catalog
- Logs: Allow Amazon CloudWatch Logs if desired (it’s really helpful however not required for this weblog)
Configure the community (VPC, subnets, and default safety group) to permit the EMR Serverless utility to succeed in the MSK cluster. Be aware of the application-id to make use of later for launching the roles.
Create an MSK cluster
Create an MSK cluster on the Amazon MSK console. For extra particulars, see Get began utilizing Amazon MSK. It is advisable to use customized create with at the very least two brokers utilizing 3.5.1, Apache Zookeeper mode model, and occasion kind kafka.m7g.xlarge. Don’t use public entry, as an alternative select two personal subnets to deploy (one dealer per subnet or Availability Zone, for a complete of two brokers). For the safety group, keep in mind that the EMR cluster and the Amazon EC2 based mostly producer might want to attain the cluster and act accordingly.
For safety, use PLAINTEXT (in manufacturing, you must safe entry to the cluster). Select 200 GB as storage dimension for every dealer and don’t allow tiered storage. For community safety teams, you may select the default of the VPC.
For the MSK cluster configuration, use the next settings:
Configure the information simulator
Log in to your EC2 occasion. As a result of it’s working on a non-public subnet, you should use an occasion endpoint to attach. To create one, see Hook up with your situations utilizing EC2 Occasion Join Endpoint. After you log in, challenge the next instructions:
Create Kafka matters
Create two Kafka matters—keep in mind that you must change the bootstrap server with the corresponding shopper info. You may get this information from the Amazon MSK console on the main points web page in your MSK cluster.
Launching EMR Serverless Jobs for Iceberg Tables (Avro/ORC – Compacted & Non-Compacted)
Now it’s time to launch EMR Serverless streaming jobs for 4 totally different Iceberg tables. Every job makes use of a distinct Spark Structured Streaming checkpoint and a particular Java class for ingestion logic.
Earlier than launching the roles, make certain:
- You have got disabled auto-compaction within the S3 tables the place vital (see S3 Tables upkeep). On this case for
employee_Avro_uncompactedandemployee_orc_uncompactedtables. - Your EMR Serverless IAM function has permissions to learn/write from S3Tables. Open AWS Lake formation console, then, you may comply with these docs to present permissions to the EMR Serverless Function.
After launching every job launch the information simulator and let it end. Then you may cancel the job run and launch the subsequent one ( whereas launching the information simulator once more).
Launch the information simulator
Obtain the JAR file to the EC2 occasion and run the producer, word that can do that as soon as.
aws s3 cp s3://s3bucket/jars/streaming-iceberg-ingest-1.0-SNAPSHOT.jar .
Now you can begin the protocol buffer producers. Use the next instructions:
It’s best to run this command for every of the tables ( job runs), run the command after the ingestion course of has began.
Desk 1: employee_orc_uncompacted
Checkpoint: checkpointORC
Java Class: SparkCustomIcebergIngestMoRS3BucketsORC
Desk 2: employee_avro_uncompacted
Checkpoint: checkpointAvro
Java Class: SparkCustomIcebergIngestMoRS3BucketsAvro
Desk 3: employee_orc (Auto-Compacted)
Checkpoint: checkpointORCAuto
Java Class: SparkCustomIcebergIngestMoRS3BucketsAutoORC
Desk 4: employee_avro (Auto-Compacted)
Checkpoint: checkpointAvroAuto
Java Class: SparkCustomIcebergIngestMoRS3BucketsAutoAvro
Question and Be a part of information from these S3 Tables to construct insights
You possibly can go to Athena console after which run the queries. Please be certain that Lake Formation permissions are utilized on the catalog database and tables in your IAM Console function. For extra particulars, please consult with docs on the Grant Lake Formation permissions in your desk.
To benchmark these queries in Athena, you may run every question a number of occasions—sometimes 5 runs per question—to acquire a dependable efficiency estimate. Within the Athena console, merely execute the identical question repeatedly and file the execution time for every run, which is displayed within the question historical past. After getting 5 execution occasions, calculate the common to get a consultant benchmark worth. This strategy helps account for variations in efficiency resulting from background load, offering extra constant and significant outcomes.
Question 1
Question 2
Question 3
Conclusion
AWS has expanded assist for Iceberg desk optimization to incorporate all Iceberg supported file codecs: Parquet, Avro, and ORC. This complete compaction functionality is now out there for each Amazon S3 Tables and Iceberg tables generally goal S3 buckets utilizing the lakehouse structure in SageMaker with Glue Information Catalog optimization. S3 Tables ship a completely managed expertise via continuous optimization, robotically sustaining your tables by dealing with compaction, snapshot retention, and unreferenced file elimination. These automated upkeep options considerably enhance question efficiency and cut back question engine prices. Compaction assist for Avro and ORC codecs is now out there in all AWS Areas the place S3 Tables or optimization with the AWS Glue Information Catalog can be found. To study extra about S3 Tables compaction, see the S3 Tables upkeep documentation. For normal goal bucket optimization, see the Glue Information Catalog optimization documentation.
Particular because of everybody who contributed to this launch: Matthieu Dufour, Srishti Bhargava, Stylianos Herodotou, Kannan Ratnasingham, Shyam Rathi, David Lee.
In regards to the authors
 Angel Conde Manjon is a Sr. EMEA Information & AI PSA, based mostly in Madrid. He has beforehand labored on analysis associated to Information Analytics and Synthetic Intelligence in various European analysis initiatives. In his present function, Angel helps companions develop companies centered on Information and AI.
Angel Conde Manjon is a Sr. EMEA Information & AI PSA, based mostly in Madrid. He has beforehand labored on analysis associated to Information Analytics and Synthetic Intelligence in various European analysis initiatives. In his present function, Angel helps companions develop companies centered on Information and AI.
 Diego Colombatto is a Principal Companion Options Architect at AWS. He brings greater than 15 years of expertise in designing and delivering Digital Transformation initiatives for enterprises. At AWS, Diego works with companions and clients advising methods to leverage AWS applied sciences to translate enterprise wants into options. Resolution architectures, algorithmic buying and selling and cooking are a few of his passions and he’s all the time open to start out a dialog on these matters.
Diego Colombatto is a Principal Companion Options Architect at AWS. He brings greater than 15 years of expertise in designing and delivering Digital Transformation initiatives for enterprises. At AWS, Diego works with companions and clients advising methods to leverage AWS applied sciences to translate enterprise wants into options. Resolution architectures, algorithmic buying and selling and cooking are a few of his passions and he’s all the time open to start out a dialog on these matters.
 Sandeep Adwankar is a Senior Technical Product Supervisor at AWS. Primarily based within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise that allow clients to enhance how they handle, safe, and entry information.
Sandeep Adwankar is a Senior Technical Product Supervisor at AWS. Primarily based within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise that allow clients to enhance how they handle, safe, and entry information.