

{kind=link}
Our clients inform us that scientists are more and more spending extra time managing data-related challenges than specializing in science. The first purpose for this problem is that scientific information is available in many varieties and is siloed throughout programs, teams, and phases, and scientists wrestle to effectively uncover, entry, share, and analyze datasets throughout silos. This fragmentation creates prolonged cycles filled with guide interventions, resulting in inefficiencies. Mapping information sources and negotiating entry throughout silos can take 4–6 weeks, integrating datasets can prolong to months, and totally connecting information from supply to tooling can take years, if ever achieved. These information challenges scale back lab productiveness and decelerate scientific innovation, which lower drug and product pipeline throughput, and in the end delay time-to-market. The answer lies in breaking down information silos by creating digital environments that assist scientists effectively join disparate datasets and analytical instruments, to allow them to conduct iterative speculation and product testing with out know-how friction.
Half 1 of this sequence exhibits an instance undertaking in drug goal identification the place two teams of scientists must collaborate as they combine no-code information looking, scientific information administration, and complicated analytics. On this instance, a computational biology workforce begins by mining the scientific literature on a information search GUI. Subsequent, they navigate to a knowledge catalog to seek out and entry related datasets, which they share with the information scientist workforce to run analytics with subtle instruments (see the next determine). Though the end-to-end journey illustrates the advantages to a goal identification instance, the underlying information challenges and know-how resolution apply to any life sciences use case requiring the combination of knowledge administration and analytics. Particulars of the implementation and technical resolution will probably be mentioned in Half 2 of the sequence.
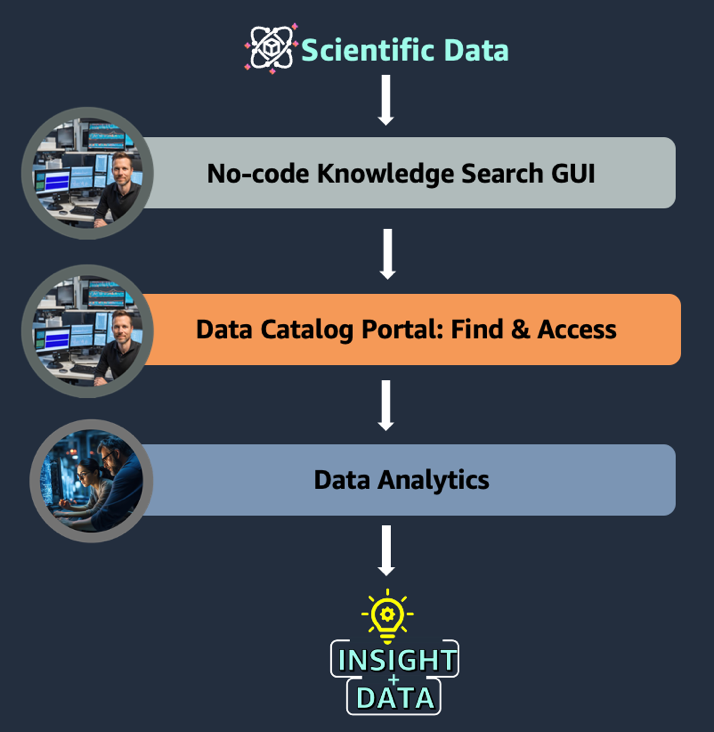
Instance use case
A computational biologist has been tasked with figuring out a goal for Non-Alcoholic Fatty Liver Illness (NAFLD). A typical query from the biologist could be “Can I discover genes related to NAFLD and do now we have a affected person cohort with variants in these genes?” The answer we designed for this use case entails three easy steps:
- Search the scientific literature by way of a no-code interface to establish genomic variants related to NAFLD.
- Search an inner information catalog with pure language:
- Discover datasets of curiosity, similar to multi-omics and medical information for sufferers related to NAFLD.
- Request entry to the related datasets.
- Share related datasets with an information scientist collaborator for deeper evaluation.
In designing this resolution, we targeted on the next options:
- Offering no-code scientists with point-and-click and natural-language interfaces
- Decreasing silos with information findability, governance automation, and seamless collaboration
- Offering technical personas with the delicate instruments and environments they like
Answer overview
This resolution makes use of the subsequent era of Amazon SageMaker, together with Amazon SageMaker Unified Studio, an built-in information and AI growth setting. SageMaker Unified Studio gives capabilities for information processing, SQL analytics, mannequin growth, and generative AI utility growth, constructed on present AWS companies. The following era of SageMaker additionally consists of Amazon SageMaker Catalog, which is constructed on Amazon DataZone, a information administration service designed to streamline information discovery, information cataloging, information sharing, and governance. Your group can have a single safe information hub the place everybody within the group can discover, entry, and collaborate on information throughout AWS, on premises, and even third-party sources.
SageMaker Catalog helps sure system asset sorts, similar to tables from Amazon Redshift, tables from AWS Glue, and object collections from Amazon Easy Storage Service (Amazon S3). It additionally gives the flexibility to assist customized asset sorts, which provides customers flexibility to catalog information that may’t be categorized as a system asset kind. For asset kind S3ObjectCollectionType, see Implement a customized subscription workflow for unmanaged Amazon S3 belongings revealed with Amazon DataZone. SageMaker Catalog additionally gives the flexibility to assist customized asset sorts, which provides customers flexibility to catalog information that may’t be categorized as a system asset kind. For this instance use case, we used AWS HealthOmics variant shops to retailer and permit querying of genomic variant information. This instance lists HealthOmics variant shops as a customized asset kind throughout the catalog. Particulars of the implementation and technical resolution for entry administration will probably be mentioned in Half 2 of the sequence.
Within the instance use case, a computational biologist, with a view to establish a goal for NAFLD, depends closely on various datasets from a number of sources (genomic sequences, gene expression information, medical data, and extra). This information comes from each inner sources (first-party) and exterior companions or public databases (third-party). A number of groups are chargeable for gathering and processing this information earlier than making it out there to computational biologists, researchers, information scientists, and bioinformaticians throughout the group.
On this resolution, customers (information engineers, information scientists, bioinformaticians, computational biologists) log in to a project-based setting from SageMaker Unified Studio with a preconfigured authentication methodology. A typical workflow entails the next steps:
- Knowledge stewards as licensed members of tasks publish information belongings into the SageMaker catalog.
- Knowledge customers as licensed members of tasks in search of to research information for his or her scientific wants discover and uncover out there information belongings of curiosity from the SageMaker catalog.
- Knowledge customers request to subscribe to the related found information belongings.
- Knowledge producers overview and resolve to approve or reject the subscription request.
- Knowledge customers entry and analyze the information utilizing preconfigured instruments from SageMaker Unified Studio.
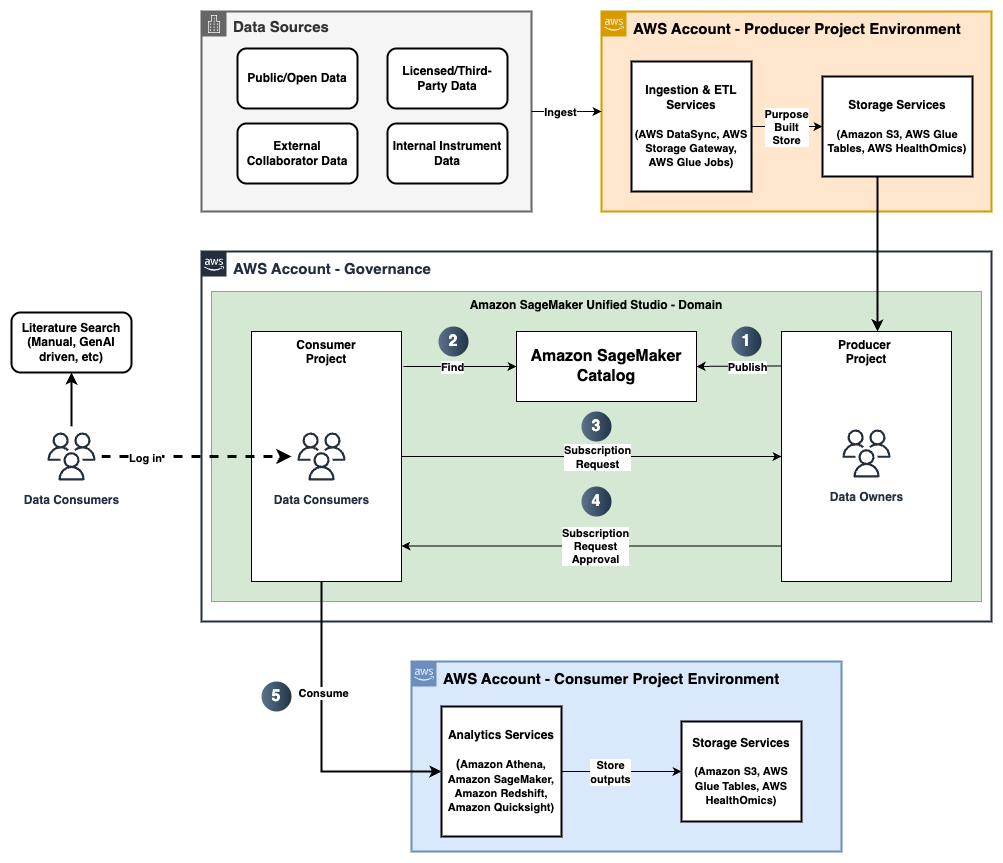
The next diagram illustrates the answer structure and workflow.
Within the following sections, we discover every step of the workflow in additional element.
Step 1: Knowledge producers publish information belongings
As proven within the previous workflow diagram, information producers can use SageMaker Catalog to publish their datasets as information belongings or information merchandise with acceptable enterprise (similar to supply, license, vendor, research identifier), scientific (similar to illness title, cohort info, information modality, assay kind), or technical (file sorts, information codecs, file sizes) metadata. In our instance use case, the information producers publish medical information as AWS Glue tables and genomic variant information as a desk throughout the HealthOmics variant retailer. Moreover, information producers can use AI-based suggestions to mechanically populate descriptors, making it easy for customers to seek out and perceive its use.
Step 2: Knowledge customers discover related datasets
Knowledge customers, similar to information scientists and bioinformaticians, can log in to SageMaker Unified Studio and navigate to SageMaker Catalog to seek for the suitable information belongings and merchandise, similar to “NAFLD Variants” or “NAFLD Scientific.” They’ll additionally discover information belongings or merchandise utilizing metadata filters similar to research identifiers or illness names to find the potential datasets related to a research or illness.
Step 3: Knowledge customers subscribe to required information belongings or merchandise
After the information customers see an information asset or information product of curiosity (for instance, the medical and genomics information for NAFLD), they’ll subscribe to them. Knowledge customers may optionally embrace a remark within the subscription request so as to add extra context to the request. This initiates the subscription workflow primarily based on the asset kind.
Step 4: Knowledge producers overview and approve the subscription request
Knowledge producers get notified of subscription requests and overview if entry needs to be granted and approve accordingly. The response can optionally embrace a remark for reasoning and traceability. As well as, information producers can restrict entry to sure rows and columns to guard managed information.
Step 5: Knowledge customers entry the subscribed information belongings or merchandise
Upon approval from the information producer, the information shopper will get entry to these information belongings and might use them within the acceptable environments configured inside their undertaking. For instance, information scientists can open a workspace with a JupyterLab pocket book already out there inside SageMaker Unified Studio. Subsequently, the information scientist can begin analyzing the tabular medical and variant information that was simply permitted for entry.
Conclusion
The following era of SageMaker transforms how scientists work with information by creating an built-in information and analytics setting. On this unified setting, information producers are empowered to publish datasets with wealthy metadata. Knowledge customers are ready to make use of the catalog inside SageMaker Unified Studio to seek for their required datasets, both utilizing free textual content or utilizing metadata and enterprise glossary filters. Knowledge customers can subscribe to information securely, faucet into highly effective search capabilities utilizing free textual content or metadata filters, and entry important evaluation instruments (Amazon Athena, JupyterLab IDE, Amazon EMR) immediately. The result’s a unified digital workspace that reduces communication bottlenecks, hurries up scientific cycles, and removes technical boundaries. Scientists can now give attention to what issues most—testing hypotheses and merchandise, and scaling scientific innovation to manufacturing—inside a unified, highly effective platform. This streamlined strategy accelerates data-driven science, enabling analysis establishments, pharmaceutical corporations, and medical laboratories to innovate extra effectively. For instance, information scientists can launch an area with a JupyterLab pocket book preinstalled.
Think about using the subsequent era of SageMaker to extend productiveness inside your group. Contact your account representatives or an AWS Consultant to find out how we will help speed up your tasks and your online business.
In regards to the authors
 Nadeem Bulsara is a Principal Options Architect at AWS specializing in Genomics and Life Sciences. He brings his 13+ years of Bioinformatics, Software program Engineering, and Cloud Improvement abilities in addition to expertise in analysis and medical genomics and multi-omics to assist Healthcare and Life Sciences organizations globally. He’s motivated by the trade’s mission to allow individuals to have a protracted and wholesome life.
Nadeem Bulsara is a Principal Options Architect at AWS specializing in Genomics and Life Sciences. He brings his 13+ years of Bioinformatics, Software program Engineering, and Cloud Improvement abilities in addition to expertise in analysis and medical genomics and multi-omics to assist Healthcare and Life Sciences organizations globally. He’s motivated by the trade’s mission to allow individuals to have a protracted and wholesome life.
 Chaitanya Vejendla is a Senior Options Architect specialised in DataLake & Analytics primarily working for Healthcare and Life Sciences trade division at AWS. Chaitanya is chargeable for serving to life sciences organizations and healthcare corporations in creating fashionable information methods, deploy information governance and analytical functions, digital medical data, gadgets, and AI/ML-based functions, whereas educating clients about the right way to construct safe, scalable, and cost-effective AWS options. His experience spans throughout information analytics, information governance, AI, ML, huge information, and healthcare-related applied sciences.
Chaitanya Vejendla is a Senior Options Architect specialised in DataLake & Analytics primarily working for Healthcare and Life Sciences trade division at AWS. Chaitanya is chargeable for serving to life sciences organizations and healthcare corporations in creating fashionable information methods, deploy information governance and analytical functions, digital medical data, gadgets, and AI/ML-based functions, whereas educating clients about the right way to construct safe, scalable, and cost-effective AWS options. His experience spans throughout information analytics, information governance, AI, ML, huge information, and healthcare-related applied sciences.
 Dr. Mileidy Giraldo has over 20 years of expertise bridging bioinformatics, analysis, and trade know-how technique. She makes a speciality of making know-how accessible for organizations within the life sciences sector. In her present position as WW Lead for Life Sciences Technique and Lab of the Future at AWS, she helps biotechs, biopharma, and diagnostics organizations design Knowledge & AI-driven initiatives that modernize labs and assist scientists unlock the total worth of their information.
Dr. Mileidy Giraldo has over 20 years of expertise bridging bioinformatics, analysis, and trade know-how technique. She makes a speciality of making know-how accessible for organizations within the life sciences sector. In her present position as WW Lead for Life Sciences Technique and Lab of the Future at AWS, she helps biotechs, biopharma, and diagnostics organizations design Knowledge & AI-driven initiatives that modernize labs and assist scientists unlock the total worth of their information.
 Chris Clark is a Senior Options Architect targeted on serving to Life Science clients leverage AWS know-how to advance their operational capabilities. With 20+ years of hands-on expertise in life sciences manufacturing and provide chain, he combines deep trade information along with his AWS experience to information his clients. When he’s not working to resolve buyer challenges, he enjoys biking and constructing and repairing issues in his workshop.
Chris Clark is a Senior Options Architect targeted on serving to Life Science clients leverage AWS know-how to advance their operational capabilities. With 20+ years of hands-on expertise in life sciences manufacturing and provide chain, he combines deep trade information along with his AWS experience to information his clients. When he’s not working to resolve buyer challenges, he enjoys biking and constructing and repairing issues in his workshop.
 Nick Furr is a Specialist Options Architect at AWS, supporting Knowledge & Analytics for Healthcare and Life Sciences. He helps suppliers, payers, and life sciences organizations construct safe, scalable information platforms to drive innovation and enhance outcomes. His work focuses on modernizing information methods by way of cloud analytics, ruled information processing, and machine studying to be used circumstances like medical analysis and inhabitants well being.
Nick Furr is a Specialist Options Architect at AWS, supporting Knowledge & Analytics for Healthcare and Life Sciences. He helps suppliers, payers, and life sciences organizations construct safe, scalable information platforms to drive innovation and enhance outcomes. His work focuses on modernizing information methods by way of cloud analytics, ruled information processing, and machine studying to be used circumstances like medical analysis and inhabitants well being.
 Subrat Das is a Principal Options Architect for World Healthcare and Life Sciences accounts at AWS. He’s obsessed with modernizing and architecting complicated clients workloads. When he’s not engaged on know-how options, he enjoys lengthy hikes and touring around the globe.
Subrat Das is a Principal Options Architect for World Healthcare and Life Sciences accounts at AWS. He’s obsessed with modernizing and architecting complicated clients workloads. When he’s not engaged on know-how options, he enjoys lengthy hikes and touring around the globe.