

{kind=link}
Amazon OpenSearch Service has taken a big leap ahead in scalability and efficiency with the introduction of assist for 1,000-node OpenSearch Service domains able to dealing with 500,000 shards with OpenSearch Service model 2.17. This breakthrough is made attainable by a number of options, together with Distant Publication, which introduces an revolutionary cluster state publication mechanism that enhances scalability, availability, and sturdiness. It makes use of the distant cluster state function as the bottom. This function supplies sturdiness and makes certain metadata shouldn’t be misplaced even when the vast majority of the cluster supervisor nodes fail completely. Through the use of a distant retailer for cluster state publication, OpenSearch Service can now assist clusters with the next variety of nodes and shards.
The cluster state is an inner knowledge construction that accommodates cluster data. The elected cluster supervisor node manages this state. It’s distributed to follower nodes via the transport layer and saved domestically on every node. A follower node generally is a knowledge node, a coordinator node or a non-elected cluster supervisor node. Nevertheless, because the cluster grows, publishing the cluster state over the transport layer turns into difficult. The rising dimension of the cluster state consumes extra community bandwidth and blocks transport threads throughout publication. This could affect scalability and availability. This publish explains cluster state publication, Distant Publication, and their advantages in bettering sturdiness, scalability, and availability.
How did cluster state publication work earlier than Distant Publication?
The elected cluster supervisor node is chargeable for sustaining and distributing the newest OpenSearch cluster state to all of the follower nodes. The cluster state updates while you create indexes and replace mappings, or when inner actions like shard relocations happen. Distribution of the updates follows a two-phase course of: publish and commit. Within the publish section, the cluster supervisor sends the up to date state to the follower nodes and saves a replica domestically. After a majority (greater than half) of the eligible cluster supervisor nodes acknowledge this replace, the commit section begins, the place the follower nodes are instructed to use the brand new state.
To optimize efficiency, the elected cluster supervisor sends solely the modifications for the reason that final replace, known as the diff state, lowering knowledge switch. Nevertheless, if a folllower node is out of sync or new to the cluster, it would reject the diff state. In such instances, the cluster supervisor sends the complete cluster state to these follower nodes.
The next diagram depicts the cluster state publication stream.
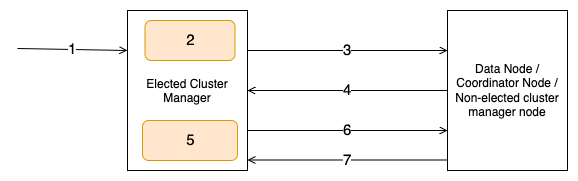
The workflow consists of the next steps:
- The person invokes an admin API akin to create index.
- The elected cluster supervisor node computes the cluster state for the admin API request.
- The elected cluster supervisor node sends the cluster state publish request to follower nodes.
- The follower nodes reply with an acknowledgement to the publish request.
- The elected cluster supervisor node persists the cluster state to the disk.
- The elected cluster supervisor node sends the commit request to follower nodes.
- The follower nodes reply with an acknowledgement to the commit request.
We’ve noticed secure cluster operations with this publication stream as much as 200 nodes or 75,000 shards. Nevertheless, because the cluster state grows in dimension with extra indexes, shards, and nodes, it begins consuming excessive community bandwidth and blocking transport threads for an extended period throughout publication. Moreover, it turns into CPU and reminiscence intensive for the elected cluster supervisor to transmit to the follower nodes, typically impacting publication latency. The elevated latency can result in a excessive pending job depend on the elected cluster supervisor. This could trigger request timeouts, or in extreme instances, cluster supervisor failure, making a cluster outage.
Utilizing a distant retailer for cluster state publication improved availability and scalability
With Distant Publication, cluster state updates are transmitted via an Amazon Easy Storage Service (Amazon S3) bucket because the distant retailer, somewhat than transmitting the state over the transport layer. When the elected cluster supervisor updates the cluster state, it uploads the brand new state to Amazon S3 along with persisting on disk. The cluster supervisor uploads a manifest file, which retains observe of the entities and which entities modified from their earlier state. Equally, follower nodes obtain the manifest from Amazon S3 and may determine if it wants the complete state or solely modified entities. This has two advantages: diminished cluster supervisor useful resource utilization and quicker transport thread availability.
Creating new domains or upgrading from present OpenSearch Service variations to 2.17 or above, or making use of the service patch to an present 2.17 or above area, allows Distant Publication by default, This supplies seamless migration with the distant state. That is enabled by default for SLA clusters, with or with out remote-backed storage. Let’s dive into some particulars of this design and perceive the way it works internally.
How is the distant retailer modeled for scalability?
Having scalable and environment friendly Amazon S3 storage is crucial for Distant Publication to work seamlessly. The cluster state has a number of entities, which get up to date at completely different frequencies. For instance, cluster node knowledge solely modifications if a brand new node joins the cluster or an outdated node leaves the cluster, which normally occurs throughout blue/inexperienced deployments or node replacements. Nevertheless, shard allocation can change a number of occasions a day primarily based on index creations, rollovers, or inner service triggered relocations. The storage schema wants to have the ability to deal with these entities in a means {that a} change in a single entity doesn’t affect one other entity. A manifest file retains observe of the entities. Every cluster state entity has its personal separate file, like one for templates, one for cluster settings, one for cluster nodes, and so forth. For entities that scale with the variety of indexes, like index metadata and index shard allocation, per-index recordsdata are created to verify modifications in an index could be uploaded and downloaded independently. The manifest file retains observe of paths to those particular person entity recordsdata. The next code exhibits a pattern manifest file. It accommodates the small print of the granular cluster state entities’ recordsdata uploaded to Amazon S3 together with some primary metadata.
Along with protecting observe of cluster state parts, the manifest file additionally retains observe of what entities modified in comparison with the final state, which is the diff manifest. Within the previous code, diff manifest has a piece for metadata diff and routing desk diff. This signifies that between these two variations of the cluster state, these entities have modified.
We additionally maintain a separate shard diff file particularly for shard allocation. As a result of a number of shards for various indexes could be relocated in a single cluster state replace, having this shard diff file additional reduces the variety of recordsdata to obtain.
This configuration supplies the next advantages:
- Separate recordsdata assist forestall bloating a single doc
- Per-index recordsdata reduces the variety of updates and successfully reduces the community bandwidth utilization, as a result of most updates have an effect on just a few indexes
- Having a diff tracker makes downloads on nodes environment friendly as a result of solely restricted knowledge must be downloaded
To assist the dimensions and excessive request price to Amazon S3, we use Amazon S3 pre-partitioning, so we will scale proportionally with the variety of clusters and indexes. For managing storage dimension, an asynchronous scheduler is added, which cleans up stale recordsdata and retains solely the final 10 lately up to date paperwork. After a cluster is deleted, a site sweeper job removes the recordsdata for that cluster after just a few days.
Distant Publication overview
Now that you simply perceive how cluster state is continued in Amazon S3, let’s see how it’s used throughout the publication workflow. When a cluster state replace happens, the elected cluster supervisor uploads modified entities to Amazon S3 in parallel, with the variety of concurrent uploads decided by a set thread pool. It then updates and uploads a manifest file with diff particulars and file paths.
Through the publish section, the elected cluster supervisor sends the manifest path, time period, and model to follower nodes utilizing a new distant transport motion. When the elected cluster supervisor modifications, the newly elected cluster supervisor increments the time period which signifies the variety of occasions a brand new cluster supervisor election has occurred. The elected cluster supervisor increments the cluster state model when the cluster state is up to date. You should use these two parts to establish cluster state development and ensure nodes function with the identical understanding of the cluster’s configuration. The follower nodes obtain the manifest, decide in the event that they want a full state or simply the diff, after which obtain the required recordsdata from Amazon S3 in parallel. After the brand new cluster state is computed, follower nodes acknowledge the elected cluster supervisor.
Within the commit section, the elected cluster supervisor updates the manifest, marking it as dedicated, and instructs follower nodes to commit the brand new cluster state. This course of supplies environment friendly distribution of cluster state updates, particularly in giant clusters, by minimizing direct knowledge switch between nodes and utilizing Amazon S3 for storage and retrieval. The next diagram depicts the Distant Publication stream when an index creation triggers a cluster state replace.
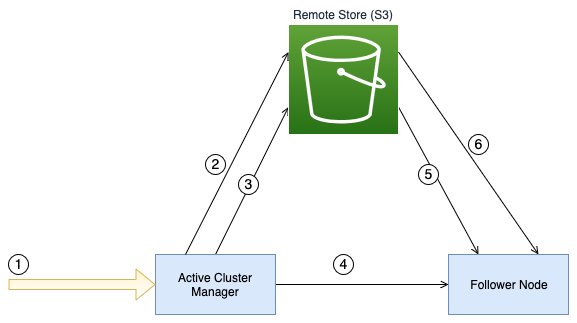
The workflow consists of the next steps:
- The person invokes an admin API akin to create index.
- The elected cluster supervisor node uploads the index metadata and routing desk recordsdata in parallel to the configured distant retailer.
- The elected cluster supervisor node uploads the manifest file containing the small print of the metadata recordsdata to the distant retailer.
- The elected cluster supervisor sends the distant manifest file path to the follower nodes.
- The follower node downloads the manifest file from the distant retailer.
- The follower nodes obtain the index metadata and routing desk recordsdata from the distant retailer in parallel.
Failure detection in publication
Distant Publication brings in a big change to how publication works and the way the cluster state is managed. Points in file creation, publication, or downloading and creating cluster state on follower nodes can have a possible affect on the cluster. To ensure the brand new stream works as anticipated, a checksum validation is added to the publication stream. On the elected cluster supervisor, after creating a brand new cluster state, a checksum is created for particular person entities and the general cluster state and added to the manifest. On follower nodes, after the cluster state is created after obtain, a checksum is created once more and matched in opposition to the checksum from the manifest. A mismatch in checksums means the cluster state on the follower node is completely different from that on the elected cluster supervisor. Within the default mode, the service solely logs which entity is failing the checksum match and lets the cluster state persist. For additional debugging, checksum match helps completely different modes, the place it may obtain the entire state and discover the diff between two states in hint mode, or fail the publication request in failure mode.
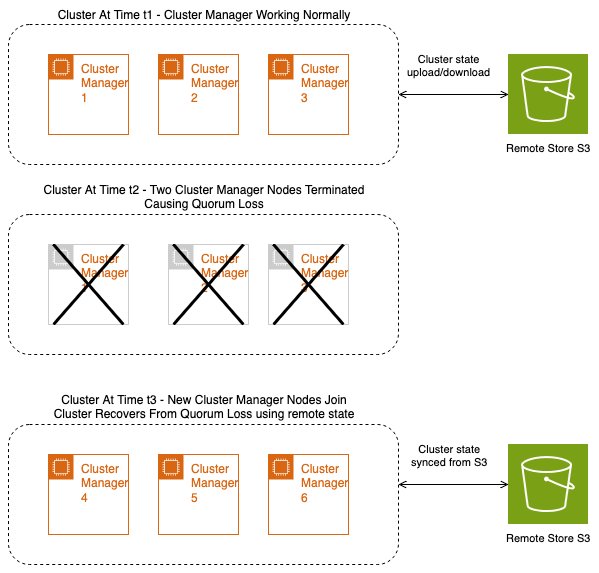
Restoration from failures
With distant state, quorum loss is recovered through the use of the cluster state from the distant retailer. With out distant state, the cluster supervisor may lose metadata, resulting in knowledge loss on your cluster. Nevertheless, the cluster supervisor can now use the final continued state to assist forestall metadata loss within the cluster. The next diagram illustrates the states of a cluster earlier than a quorum loss, throughout a quorum loss, and after the quorum loss restoration occurs utilizing a distant retailer.
Advantages
On this part, we talk about a number of the answer advantages.
Scalability and availability
Distant Publication considerably reduces the CPU, reminiscence, and community overhead for the elected cluster supervisor when transmitting the state to the follower nodes. Moreover, transport threads chargeable for sending publish requests to follower nodes are made out there extra rapidly, as a result of the distant publish request dimension is smaller. The publication request dimension stays constant no matter the cluster state dimension, giving constant publication efficiency. This enhancement allows OpenSearch Service to assist bigger clusters of as much as 1,000 nodes and the next variety of shards per node, with out overwhelming the elected cluster supervisor. With diminished load on the cluster supervisor, its availability improves, so it may extra effectively serve admin API requests.
Sturdiness
With the cluster state being continued to Amazon S3, we get Amazon S3 sturdiness. Clusters struggling quorum loss as a result of alternative of cluster supervisor nodes can hydrate with the distant cluster state and get better from quorum loss. As a result of Amazon S3 has the final dedicated cluster state, there is no such thing as a knowledge loss on restoration.
Cluster state publication efficiency
We examined the elected cluster supervisor efficiency in a 1,000-node area containing 500,000 shards. We in contrast two variations: the brand new Distant Publication system vs. the older cluster state publication system. Each clusters had been operated with the identical workload for just a few hours. The next are some key observations:
- Cluster state publication time diminished from a mean of 13 seconds to 4 seconds, which is a three-fold enchancment
- Community out diminished from a mean of 4 GB to three GB
- Elected cluster supervisor useful resource utilization confirmed important enchancment, with JVM dropping from a mean of 40% to twenty% and CPU dropping from 50% to 40%
We examined on a 100-node cluster as properly and noticed efficiency enhancements with the rise within the dimension of the cluster state. With 50,000 shards, the uncompressed cluster state dimension elevated to 600 MB. The next observations had been made throughout cluster state replace when in comparison with a cluster with out Distant Publication:
- Max community out site visitors diminished from 11.3 GB to five.7 GB (roughly 50%)
- Common elected cluster supervisor JVM utilization diminished from 54% to 35%
- Common elected cluster supervisor CPU diminished from 33% to twenty%
Contributing to open supply
OpenSearch is an open supply, community-driven software program. Yow will discover code for the Distant Publication function within the mission’s GitHub repository. A few of the notable GitHub pull requests have been added inline to the previous textual content. Yow will discover the RFCs for distant state and distant state publication within the mission’s GitHub repository. A extra complete record of pull requests is connected within the meta points for distant state, distant publication, and distant routing desk.
Trying forward
The brand new Distant Publication structure allows groups to construct further options and optimizations utilizing the distant retailer:
- Quicker restoration after failures – With the brand new structure, we’ve the final profitable cluster state in Amazon S3, which could be downloaded on the brand new cluster supervisor. On the time of writing, solely cluster metadata will get restored on restoration after which the elected cluster supervisor tries to construct shard allocation by contacting the info nodes. This takes up plenty of CPU and reminiscence for each the cluster supervisor and knowledge nodes, along with the time taken to collate the info to construct the allocation desk. With the final profitable shard allocation out there in Amazon S3, the elected cluster supervisor can obtain the info, construct the allocation desk domestically, after which replace the cluster state to the follower nodes, making restoration quicker and fewer resource-intensive.
- Lazy loading – The cluster state entities could be loaded as wanted as an alternative of . This method reduces the typical reminiscence utilization on a follower node and is predicted to hurry up cluster state publication.
- Node-specific metadata – At current, each follower node downloads and masses the complete cluster state. Nevertheless, we will optimize this by modifying the logic so {that a} knowledge node solely downloads the index metadata and routing desk for the indexes it accommodates.
- Optimize cluster state downloads – There is a chance to optimize the downloading of cluster state entities. We’re exploring compression and serialization methods to attenuate the quantity of knowledge transmitted.
- Restoring to an older state – The service retains the cluster state for the final 10 updates. This can be utilized to revive the cluster to a earlier state in case the state will get corrupted.
Conclusion
Distant Publication makes cluster state publication quicker and extra sturdy, considerably bettering cluster scalability, reliability, and restoration capabilities, probably lowering buyer incidents and operational overhead. This transformation in structure allows additional enhancements in elected cluster supervisor efficiency and making domains extra sturdy, particularly for bigger domains the place cluster supervisor operations turn into heavy because the variety of indexes and nodes improve. We encourage you to improve to the newest model to benefit from these enhancements and share your expertise with our neighborhood.
Concerning the authors
 Himshikha Gupta is a Senior Engineer with Amazon OpenSearch Service. She is worked up about scaling challenges with distributed programs. She is an energetic contributor to OpenSearch, targeted on shard administration and cluster scalability
Himshikha Gupta is a Senior Engineer with Amazon OpenSearch Service. She is worked up about scaling challenges with distributed programs. She is an energetic contributor to OpenSearch, targeted on shard administration and cluster scalability
 Sooraj Sinha is a software program engineer at Amazon, specializing in Amazon OpenSearch Service since 2021. He has labored on a number of core parts of OpenSearch, together with indexing, cluster administration, and cross-cluster replication. His contributions have targeted on bettering the provision, efficiency, and sturdiness of OpenSearch.
Sooraj Sinha is a software program engineer at Amazon, specializing in Amazon OpenSearch Service since 2021. He has labored on a number of core parts of OpenSearch, together with indexing, cluster administration, and cross-cluster replication. His contributions have targeted on bettering the provision, efficiency, and sturdiness of OpenSearch.