

Introduction
At Databricks, Kubernetes is on the coronary heart of our inner techniques. Inside a single Kubernetes cluster, the default networking primitives like ClusterIP providers, CoreDNS, and kube-proxy are sometimes ample. They provide a easy abstraction to route service visitors. However when efficiency and reliability matter, these defaults start to point out their limits.
On this put up, we’ll share how we constructed an clever, client-side load balancing system to enhance visitors distribution, scale back tail latencies, and make service-to-service communication extra resilient.
If you’re a Databricks person, you don’t want to grasp this weblog to have the ability to use the platform to its fullest. However when you’re curious about taking a peek beneath the hood, learn on to listen to about a number of the cool stuff we’ve been engaged on!
Drawback assertion
Excessive-performance service-to-service communication in Kubernetes has a number of challenges, particularly when utilizing persistent HTTP/2 connections, as we do at Databricks with gRPC.
How Kubernetes Routes Requests by Default
- The consumer resolves the service title (e.g., my-service.default.svc.cluster.native) by way of CoreDNS, which returns the service’s ClusterIP (a digital IP).
- The consumer sends the request to the ClusterIP, assuming it is the vacation spot.
- On the node, iptables, IPVS, or eBPF guidelines (configured by kube-proxy) intercept the packet. The kernel rewrites the vacation spot IP to one of many backend Pod IPs primarily based on primary load balancing, similar to round-robin, and forwards the packet.
- The chosen pod handles the request, and the response is shipped again to the consumer.
Whereas this mannequin typically works, it rapidly breaks down in performance-sensitive environments, resulting in important limitations.
Limitations
At Databricks, we function lots of of stateless providers speaking over gRPC inside every Kubernetes cluster. These providers are sometimes high-throughput, latency-sensitive, and run at important scale.
The default load balancing mannequin falls quick on this atmosphere for a number of causes:
- Excessive tail latency: gRPC makes use of HTTP/2, which maintains long-lived TCP connections between purchasers and providers. Since Kubernetes load balancing occurs at Layer 4, the backend pod is chosen solely as soon as per connection. This results in visitors skew, the place some pods obtain considerably extra load than others. Consequently, tail latencies improve and efficiency turns into inconsistent beneath load.
- Inefficient useful resource utilization: When visitors will not be evenly unfold, it turns into arduous to foretell capability necessities. Some pods get CPU or reminiscence starved whereas others sit idle. This results in over-provisioning and waste.
- Restricted load balancing methods: kube-proxy helps solely primary algorithms like round-robin or random choice. There is no assist for methods like:
These limitations pushed us to rethink how we deal with service-to-service communication inside a Kubernetes cluster.
Our Strategy: Consumer-Aspect Load Balancing with Actual-Time Service Discovery
To handle the constraints of kube-proxy and default service routing in Kubernetes, we constructed a proxyless, absolutely client-driven load balancing system backed by a customized service discovery management airplane.
The elemental requirement we had was to assist load balancing on the utility layer, and eradicating dependency on the DNS on a essential path. A Layer 4 load balancer, like kube-proxy, can’t make clever per-request selections for Layer 7 protocols (similar to gRPC) that make the most of persistent connections. This architectural constraint creates bottlenecks, necessitating a extra clever strategy to visitors administration.
The next desk summarizes the important thing variations and some great benefits of a client-side strategy:
Desk 1: Default Kubernetes LB vs. Databricks’ Consumer-Aspect LB
| Characteristic/Facet | Default Kubernetes Load Balancing (kube-proxy) | Databricks’ Consumer-Aspect Load Balancing |
|---|---|---|
| Load Balancing Layer | Layer 4 (TCP/IP) | Layer 7 (Software/gRPC) |
| Determination Frequency | As soon as per TCP connection | Per-request |
| Service Discovery | CoreDNS + kube-proxy (digital IP) | xDS-based Management Aircraft + Consumer Library |
| Supported Methods | Primary (Spherical-robin, Random) | Superior (P2C, Zone-affinity, Pluggable) |
| Tail Latency Affect | Excessive (on account of visitors skew on persistent connections) | Lowered (even distribution, dynamic routing) |
| Useful resource Utilization | Inefficient (over-provisioning) | Environment friendly (balanced load) |
| Dependency on DNS/Proxy | Excessive | Minimal/Minimal, not on a essential path |
| Operational Management | Restricted | Wonderful-grained |
This technique permits clever, up-to-date request routing with minimal dependency on DNS or Layer 4 networking. It provides purchasers the flexibility to make knowledgeable selections primarily based on dwell topology and well being knowledge.
The determine reveals our customized Endpoint Discovery Service in motion. It reads service and endpoint knowledge from the Kubernetes API and interprets it into xDS responses. Each Armeria purchasers and API proxies stream requests to it and obtain dwell endpoint metadata, which is then utilized by utility servers for clever routing with fallback clusters as backup.”
Customized Management Aircraft (Endpoint discovery service)
We run a light-weight management airplane that constantly displays the Kubernetes API for adjustments to Providers and EndpointSlices. It maintains an up-to-date view of all backend pods for each service, together with metadata like zone, readiness, and shard labels.
RPC Consumer Integration
A strategic benefit for Databricks was the widespread adoption of a typical framework for service communication throughout most of its inner providers, that are predominantly written in Scala. This shared basis allowed us to embed client-side service discovery and cargo balancing logic straight into the framework, making it straightforward to undertake throughout groups with out requiring customized implementation effort.
Every service integrates with our customized consumer, which subscribes to updates from the management airplane for the providers it is determined by through the connection setup. The consumer maintains a dynamic record of wholesome endpoints, together with metadata like zone or shard, and updates routinely because the management airplane pushes adjustments.
As a result of the consumer bypasses each DNS decision and kube-proxy solely, it all the time has a dwell, correct view of service topology. This permits us to implement constant and environment friendly load balancing methods throughout all inner providers.
Superior Load Balancing in Shoppers
The rpc consumer performs request-aware load balancing utilizing methods like:
- Energy of Two Selections (P2C): For almost all of providers, a easy Energy of Two Selections (P2C) algorithm has confirmed remarkably efficient. This technique includes randomly deciding on two backend servers after which selecting the one with fewer lively connections or decrease load. Databricks’ expertise signifies that P2C strikes a robust stability between efficiency and implementation simplicity, constantly resulting in uniform visitors distribution throughout endpoints.
- Zone-affinity-based: The system additionally helps extra superior methods, similar to zone-affinity-based routing. This functionality is significant for minimizing cross-zone community hops, which might considerably scale back community latency and related knowledge switch prices, particularly in geographically distributed Kubernetes clusters.
The system additionally accounts for eventualities the place a zone lacks ample capability or turns into overloaded. In such circumstances, the routing algorithm intelligently spills visitors over to different wholesome zones, balancing load whereas nonetheless preferring native affinity every time potential. This ensures excessive availability and constant efficiency, even beneath uneven capability distribution throughout zones.
- Pluggable Help: The structure’s flexibility permits for pluggable assist for added load balancing methods as wanted.
Extra superior methods, like zone-aware routing, required cautious tuning and deeper context about service topology, visitors patterns, and failure modes; a subject to discover in a devoted follow-up put up.
To make sure the effectiveness of our strategy, we ran in depth simulations, experiments, and real-world metric evaluation. We validated that load remained evenly distributed and that key metrics like tail latency, error charge, and cross-zone visitors value stayed inside goal thresholds. The flexibleness to adapt methods per-service has been precious, however in apply, protecting it easy (and constant) has labored finest.
xDS Integration with Envoy
Our management airplane extends its utility past the interior service-to-service communication. It performs an important position in managing exterior visitors by talking the xDS API to Envoy, the invention protocol that lets purchasers fetch up-to-date configuration (like clusters, endpoints, and routing guidelines) dynamically. Particularly, it implements Endpoint Discovery Service (EDS) to supply Envoy with constant and up-to-date metadata about backend endpoints by programming ClusterLoadAssignment sources. This ensures that gateway-level routing (e.g., for ingress or public-facing visitors) aligns with the identical supply of fact utilized by inner purchasers.
Abstract
This structure provides us fine-grained management over routing habits whereas decoupling service discovery from the constraints of DNS and kube-proxy. The important thing takeaways are:
- purchasers all the time have a dwell, correct view of endpoints and their well being,
- load balancing methods could be tailor-made per-service, enhancing effectivity and tail latency, and
- each inner and exterior visitors share the identical supply of fact, making certain consistency throughout the platform.
Affect
After deploying our client-side load balancing system, we noticed important enhancements throughout each efficiency and effectivity:
- Uniform Request Distribution
Server-side QPS grew to become evenly distributed throughout all backend pods. In contrast to the prior setup, the place some pods had been overloaded whereas others remained underutilized, visitors now spreads predictably. The highest chart reveals the distribution earlier than EDS, whereas the underside chart reveals the balanced distribution after EDS. - Steady Latency Profiles
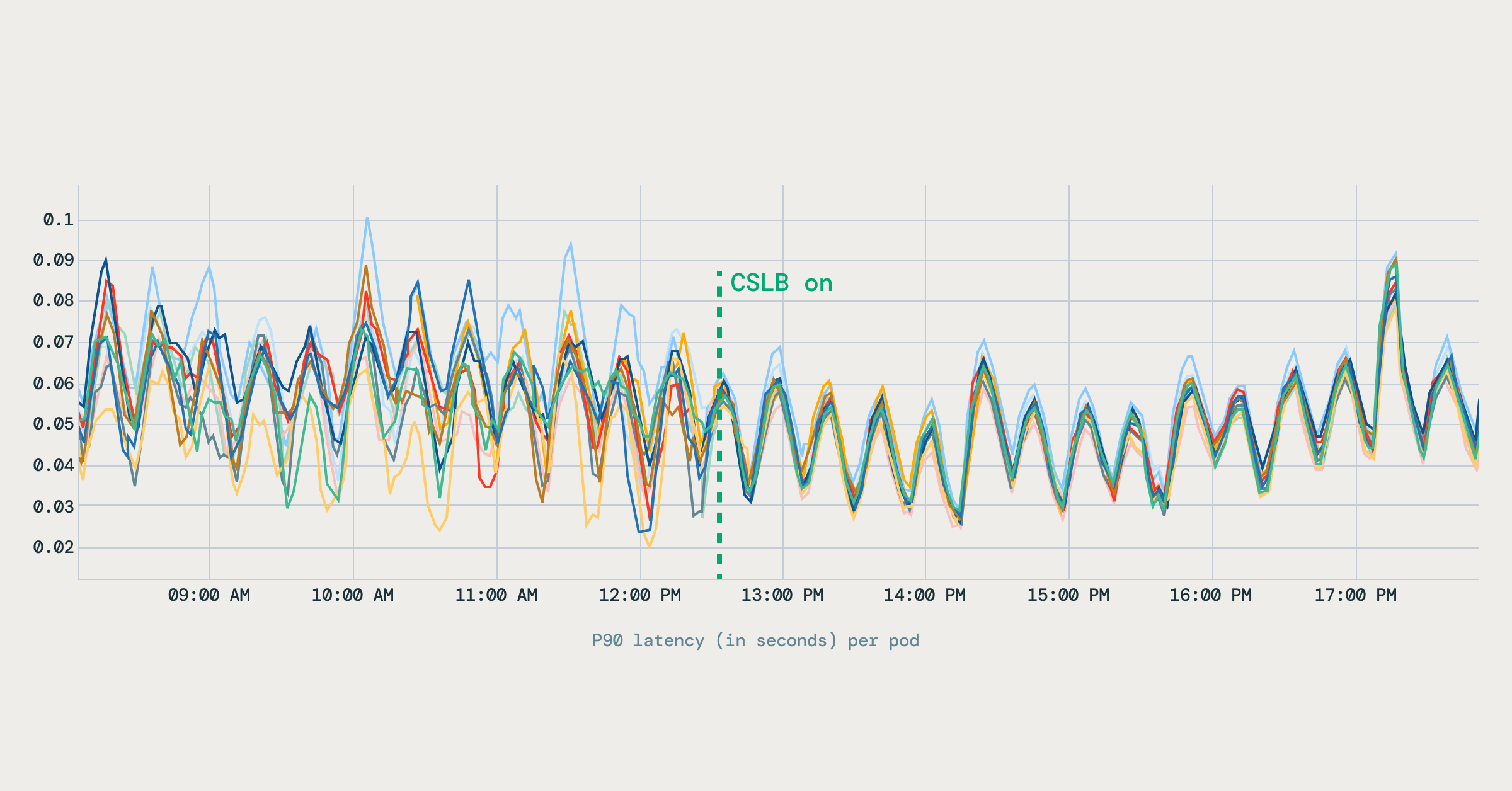
The variation in latency throughout pods dropped noticeably. Latency metrics improved and stabilized throughout pods, decreasing long-tail habits in gRPC workloads. The diagram beneath reveals how P90 latency grew to become extra steady after client-side load balancing was enabled.
- Useful resource Effectivity
With extra predictable latency and balanced load, we had been in a position to scale back over-provisioned capability. Throughout a number of providers, this resulted in roughly a 20% discount in pod depend, releasing up compute sources with out compromising reliability.
{kind=link}
Challenges and Classes Realized
Whereas the rollout delivered clear advantages, we additionally uncovered a number of challenges and insights alongside the best way:
- Server chilly begins: Earlier than client-side load balancing, most requests had been despatched over long-lived connections, so new pods had been not often hit till current connections had been recycled. After the shift, new pods started receiving visitors instantly, which surfaced cold-start points the place they dealt with requests earlier than being absolutely warmed up. We addressed this by introducing slow-start ramp-up and biasing visitors away from pods with greater noticed error charges. These classes additionally strengthened the necessity for a devoted warmup framework.
- Metrics-based routing: We initially experimented with skewing visitors primarily based on useful resource utilization alerts similar to CPU. Though conceptually engaging, this strategy proved unreliable: monitoring techniques had completely different SLOs than serving workloads, and metrics like CPU had been usually trailing indicators quite than real-time alerts of capability. We in the end moved away from this mannequin and selected to depend on extra reliable alerts similar to server well being.
- Consumer-library integration: Constructing load balancing straight into consumer libraries introduced sturdy efficiency advantages, however it additionally created some unavoidable gaps. Languages with out the library, or visitors flows that also rely on infrastructure load balancers, stay exterior the scope of client-side balancing.
Alternate options Thought-about
Whereas growing our client-side load balancing strategy, we evaluated different various options. Right here’s why we in the end determined in opposition to these:
Headless Providers
Kubernetes headless providers (clusterIP: None) present direct pod IPs by way of DNS, permitting purchasers and proxies (like Envoy) to carry out their very own load balancing. This strategy bypasses the limitation of connection-based distribution in kube-proxy and permits superior load balancing methods provided by Envoy (similar to spherical robin, constant hashing, and least-loaded spherical robin).
In principle, switching current ClusterIP providers to headless providers (or creating extra headless providers utilizing the identical selector) would mitigate connection reuse points by offering purchasers direct endpoint visibility. Nonetheless, this strategy comes with sensible limitations:
- Lack of Endpoint Weights: Headless providers alone do not assist assigning weights to endpoints, limiting our skill to implement fine-grained load distribution management.
- DNS Caching and Staleness: Shoppers regularly cache DNS responses, inflicting them to ship requests to stale or unhealthy endpoints.
- No Help for Metadata: DNS information don’t carry any extra metadata in regards to the endpoints (e.g., zone, area, shard). This makes it tough or unattainable to implement methods like zone-aware or topology-aware routing.
Though headless providers can provide a brief enchancment over ClusterIP providers, the sensible challenges and limitations made them unsuitable as a long-term answer at Databricks’ scale.
Service Meshes (e.g., Istio)
Istio supplies highly effective Layer 7 load balancing options utilizing Envoy sidecars injected into each pod. These proxies deal with routing, retries, circuit breaking, and extra – all managed centrally by means of a management airplane.
Whereas this mannequin provides many capabilities, we discovered it unsuitable for the environment at Databricks for just a few causes:
- Operational complexity: Managing hundreds of sidecars and management airplane parts provides important overhead, notably throughout upgrades and large-scale rollouts.
- Efficiency overhead: Sidecars introduce extra CPU, reminiscence, and latency prices per pod — which turns into substantial at our scale.
- Restricted consumer flexibility: Since all routing logic is dealt with externally, it’s tough to implement request-aware methods that depend on application-layer context.
We additionally evaluated Istio’s Ambient Mesh. Since Databricks already had proprietary techniques for features like certificates distribution, and our routing patterns had been comparatively static, the added complexity of adopting a full mesh outweighed the advantages. This was very true for a small infra crew supporting a predominantly Scala codebase.
It’s price noting that one of many largest benefits of sidecar-based meshes is language-agnosticism: groups can standardize resiliency and routing throughout polyglot providers with out sustaining consumer libraries all over the place. At Databricks, nevertheless, the environment is closely Scala-based, and our monorepo plus quick CI/CD tradition make the proxyless, client-library strategy way more sensible. Fairly than introducing the operational burden of sidecars, we invested in constructing first-class load balancing straight into our libraries and infrastructure parts.
Future instructions and Areas of exploration
Our present client-side load balancing strategy has considerably improved inner service-to-service communication. But, as Databricks continues to scale, we’re exploring a number of superior areas to additional improve our system:
Cross-Cluster and Cross-Area Load Balancing: As we handle hundreds of Kubernetes clusters throughout a number of areas, extending clever load balancing past particular person clusters is essential. We’re exploring applied sciences like flat L3 networking and service-mesh options, integrating seamlessly with multi-region Endpoint Discovery Service (EDS) clusters. This can allow sturdy cross-cluster visitors administration, fault tolerance, and globally environment friendly useful resource utilization.
Superior Load Balancing Methods for AI Use Circumstances: We plan to introduce extra refined methods, similar to weighted load balancing, to higher assist superior AI workloads. These methods will allow finer-grained useful resource allocation and clever routing selections primarily based on particular utility traits, in the end optimizing efficiency, useful resource consumption, and price effectivity.
Should you’re curious about engaged on large-scale distributed infrastructure challenges like this, we’re hiring. Come construct with us — discover open roles at Databricks!