

{kind=link}
Massive Language Fashions (LLMs) have gained vital consideration for his or her versatility, however their factualness stays a crucial concern. Research have revealed that LLMs can produce nonfactual, hallucinated, or outdated info, undermining reliability. Present analysis strategies, corresponding to fact-checking and fact-QA, face a number of challenges. Reality-checking struggles to evaluate the factualness of generated content material, whereas fact-QA encounters difficulties scaling up analysis knowledge as a result of costly annotation processes. Each approaches additionally face the danger of information contamination from web-crawled pretraining corpora. Additionally, LLMs typically reply inconsistently to the identical truth when introduced in several varieties, a problem is that current analysis datasets should be outfitted to handle.
Present makes an attempt to guage LLMs’ data primarily use particular datasets, however face challenges like knowledge leakage, static content material, and restricted metrics. Information graphs (KGs) supply benefits in customization, evolving data, and decreased take a look at set leakage. Strategies like LAMA and LPAQA use KGs for analysis however battle with unnatural query codecs and impracticality for big KGs. KaRR overcomes some points however stays inefficient for big graphs and lacks generalizability. Present approaches give attention to accuracy over reliability, failing to handle LLMs’ inconsistent responses to the identical truth. Additionally, no current work visualizes LLMs’ data utilizing KGs, presenting a possibility for enchancment. These limitations spotlight the necessity for extra complete and environment friendly strategies to guage and perceive LLMs’ data retention and accuracy.
Researchers from Apple launched KGLENS, an progressive data probing framework that has been developed to measure data alignment between KGs and LLMs and determine LLMs’ data blind spots. The framework employs a Thompson sampling-inspired technique with a parameterized data graph (PKG) to probe LLMs effectively. KGLENS encompasses a graph-guided query generator that converts KGs into pure language utilizing GPT-4, designing two varieties of questions (fact-checking and fact-QA) to cut back reply ambiguity. Human analysis exhibits that 97.7% of generated questions are wise to annotators.
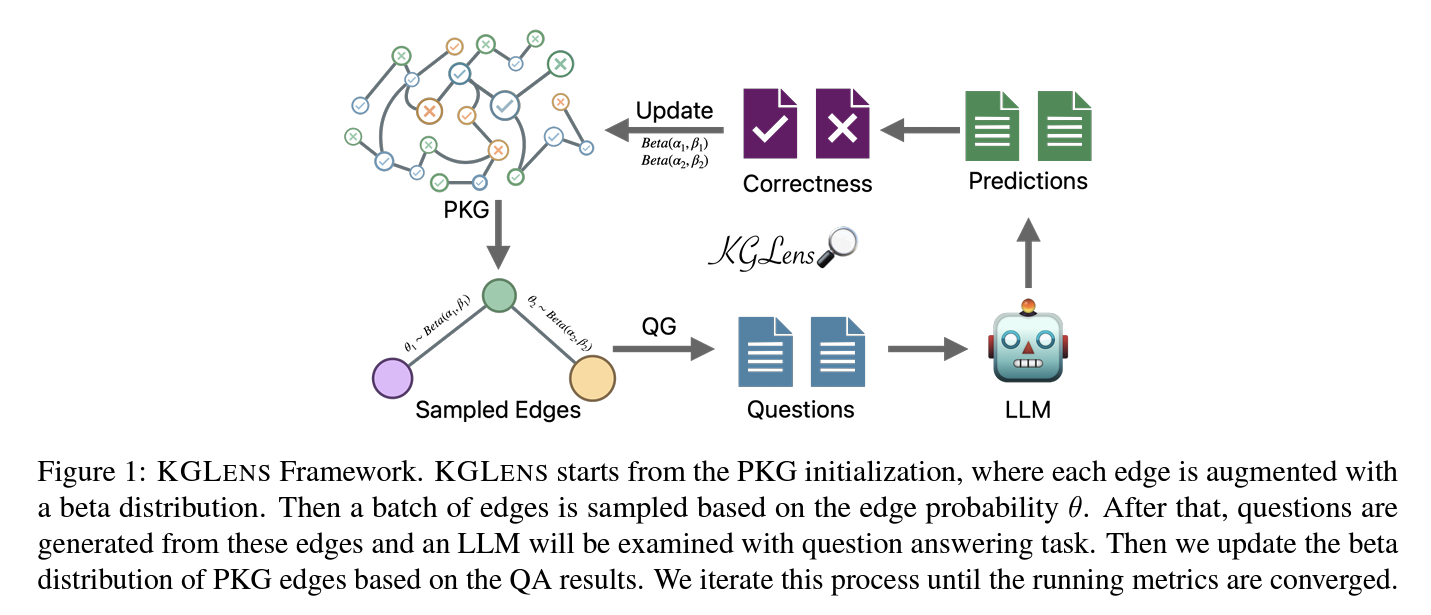
KGLENS employs a singular strategy to effectively probe LLMs’ data utilizing a PKG and Thompson sampling-inspired technique. The framework initializes a PKG the place every edge is augmented with a beta distribution, indicating the LLM’s potential deficiency on that edge. It then samples edges based mostly on their chance, generates questions from these edges, and examines the LLM by a question-answering process. The PKG is up to date based mostly on the outcomes, and this course of iterates till convergence. Additionally, This framework encompasses a graph-guided query generator that converts KG edges into pure language questions utilizing GPT-4. It creates two varieties of questions: Sure/No questions for judgment and Wh-questions for era, with the query kind managed by the graph construction. Entity aliases are included to cut back ambiguity.
For reply verification, KGLENS instructs LLMs to generate particular response codecs and employs GPT-4 to verify the correctness of responses for Wh-questions. The framework’s effectivity is evaluated by numerous sampling strategies, demonstrating its effectiveness in figuring out LLMs’ data blind spots throughout numerous matters and relationships.
KGLENS analysis throughout numerous LLMs reveals that the GPT-4 household constantly outperforms different fashions. GPT-4, GPT-4o, and GPT-4-turbo present comparable efficiency, with GPT-4o being extra cautious with private info. A major hole exists between GPT-3.5-turbo and GPT-4, with GPT-3.5-turbo typically performing worse than legacy LLMs as a result of its conservative strategy. Legacy fashions like Babbage-002 and Davinci-002 present solely slight enchancment over random guessing, highlighting the progress in current LLMs. The analysis gives insights into completely different error varieties and mannequin behaviors, demonstrating the various capabilities of LLMs in dealing with numerous data domains and issue ranges.
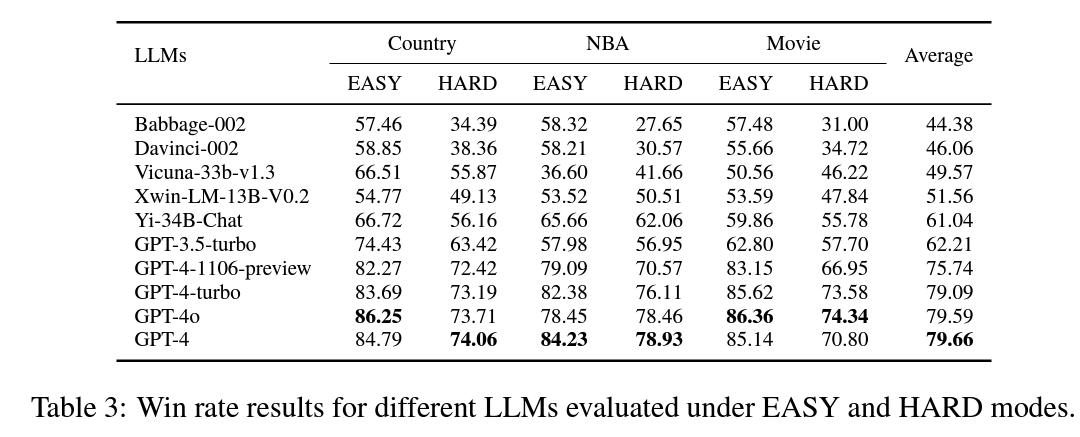
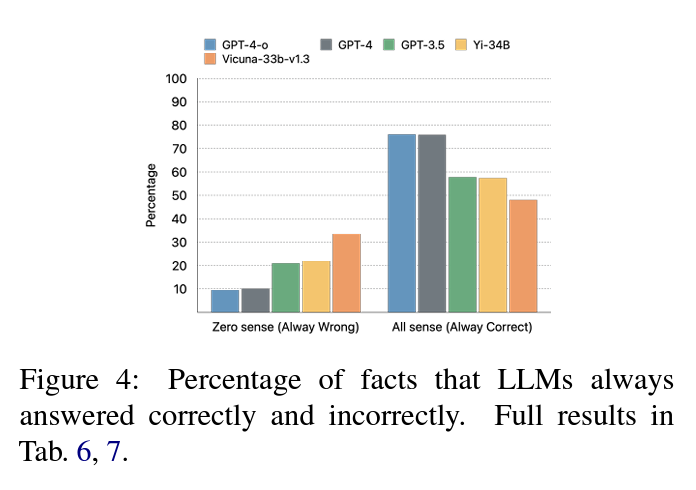
KGLENS introduces an environment friendly technique for evaluating factual data in LLMs utilizing a Thompson sampling-inspired strategy with parameterized Information Graphs. The framework outperforms current strategies in revealing data blind spots and demonstrates adaptability throughout numerous domains. Human analysis confirms its effectiveness, attaining 95.7% accuracy. KGLENS and its evaluation of KGs shall be made accessible to the analysis group, fostering collaboration. For companies, this instrument facilitates the event of extra dependable AI programs, enhancing person experiences and enhancing mannequin data. KGLENS represents a major development in creating extra correct and reliable AI functions.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.