

{kind=link}
On this publish, we discover the efficiency advantages of utilizing the Amazon EMR runtime for Apache Spark and Apache Iceberg in comparison with working the identical workloads with open supply Spark 3.5.1 on Iceberg tables. Iceberg is a well-liked open supply high-performance format for big analytic tables. Our benchmarks display that Amazon EMR can run TPC-DS 3 TB workloads 2.7 occasions sooner, decreasing the runtime from 1.548 hours to 0.564 hours. Moreover, the price effectivity improves by 2.2 occasions, with the full price lowering from $16.09 to $7.23 when utilizing Amazon Elastic Compute Cloud (Amazon EC2) On-Demand r5d.4xlarge situations, offering observable features for information processing duties.
The Amazon EMR runtime for Apache Spark presents a high-performance runtime setting whereas sustaining 100% API compatibility with open supply Spark and Iceberg desk format. In Run Apache Spark 3.5.1 workloads 4.5 occasions sooner with Amazon EMR runtime for Apache Spark, we detailed a few of the optimizations, displaying a runtime enchancment of 4.5 occasions sooner and a couple of.8 occasions higher price-performance in comparison with open supply Spark 3.5.1 on the TPC-DS 3 TB benchmark. Nonetheless, lots of the optimizations are geared in direction of DataSource V1, whereas Iceberg makes use of Spark DataSource V2. Recognizing this, we’ve got targeted on migrating a few of the current optimizations within the EMR runtime for Spark to DataSource V2 and introducing Iceberg-specific enhancements. These enhancements are constructed on high of the Spark runtime enhancements on question planning, bodily plan operator enhancements, and optimizations with Amazon Easy Storage Service (Amazon S3) and the Java runtime. We have now added eight new optimizations incrementally for the reason that Amazon EMR 6.15 launch in 2023, that are current in Amazon EMR 7.1 and turned on by default. A few of the enhancements embody the next:
- Optimizing DataSource V2 in Spark:
- Dynamic filtering on non-partitioned columns
- Eradicating redundant broadcast hash joins
- Partial hash mixture pushdowns
- Bloom filter-based joins
- Iceberg-specific enhancements:
- Information prefetch
- Assist for file size-based estimations
Amazon EMR on EC2, Amazon EMR Serverless, Amazon EMR on Amazon EKS, and Amazon EMR on AWS Outposts all use the optimized runtimes. Consult with Working with Apache Iceberg in Amazon EMR and Greatest practices for optimizing Apache Iceberg workloads for extra particulars.
Benchmark outcomes for Amazon EMR 7.1 vs. open supply Spark 3.5.1 and Iceberg 1.5.2
To evaluate the Spark engine’s efficiency with the Iceberg desk format, we carried out benchmark checks utilizing the 3 TB TPC-DS dataset, model 2.13 (our outcomes derived from the TPC-DS dataset are usually not straight corresponding to the official TPC-DS outcomes on account of setup variations). Benchmark checks for the EMR runtime for Spark and Iceberg have been carried out on Amazon EMR 7.1 clusters with Spark 3.5.0 and Iceberg 1.4.3-amzn-0 variations, and open supply Spark 3.5.1 and Iceberg 1.5.2 was deployed on EC2 clusters designated for open supply runs.
The setup directions and technical particulars can be found in our GitHub repository. To attenuate the affect of exterior catalogs like AWS Glue and Hive, we used the Hadoop catalog for the Iceberg tables. This makes use of the underlying file system, particularly Amazon S3, because the catalog. We are able to outline this setup by configuring the property spark.sql.catalog.<catalog_name>.sort. The actual fact tables used the default partitioning by the date column, which have a variety of partitions various from 200–2,100. No precalculated statistics have been used for these tables.
We ran a complete of 104 SparkSQL queries in three sequential rounds, and the common runtime of every question throughout these rounds was taken for comparability. The typical runtime for the three rounds on Amazon EMR 7.1 with Iceberg enabled was 0.56 hours, demonstrating a 2.7-fold pace improve in comparison with open supply Spark 3.5.1 and Iceberg 1.5.2. The next determine presents the full runtimes in seconds.
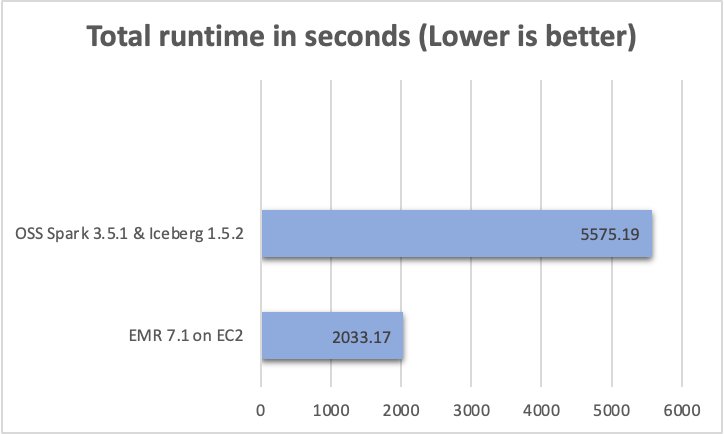
The next desk summarizes the metrics.
| Metric | Amazon EMR 7.1 on EC2 | Open Supply Spark 3.5.1 and Iceberg 1.5.2 |
| Common runtime in seconds | 2033.17 | 5575.19 |
| Geometric imply over queries in seconds | 10.13153 | 20.34651 |
| Price* | $7.23 | $16.09 |
*Detailed price estimates are mentioned later on this publish.
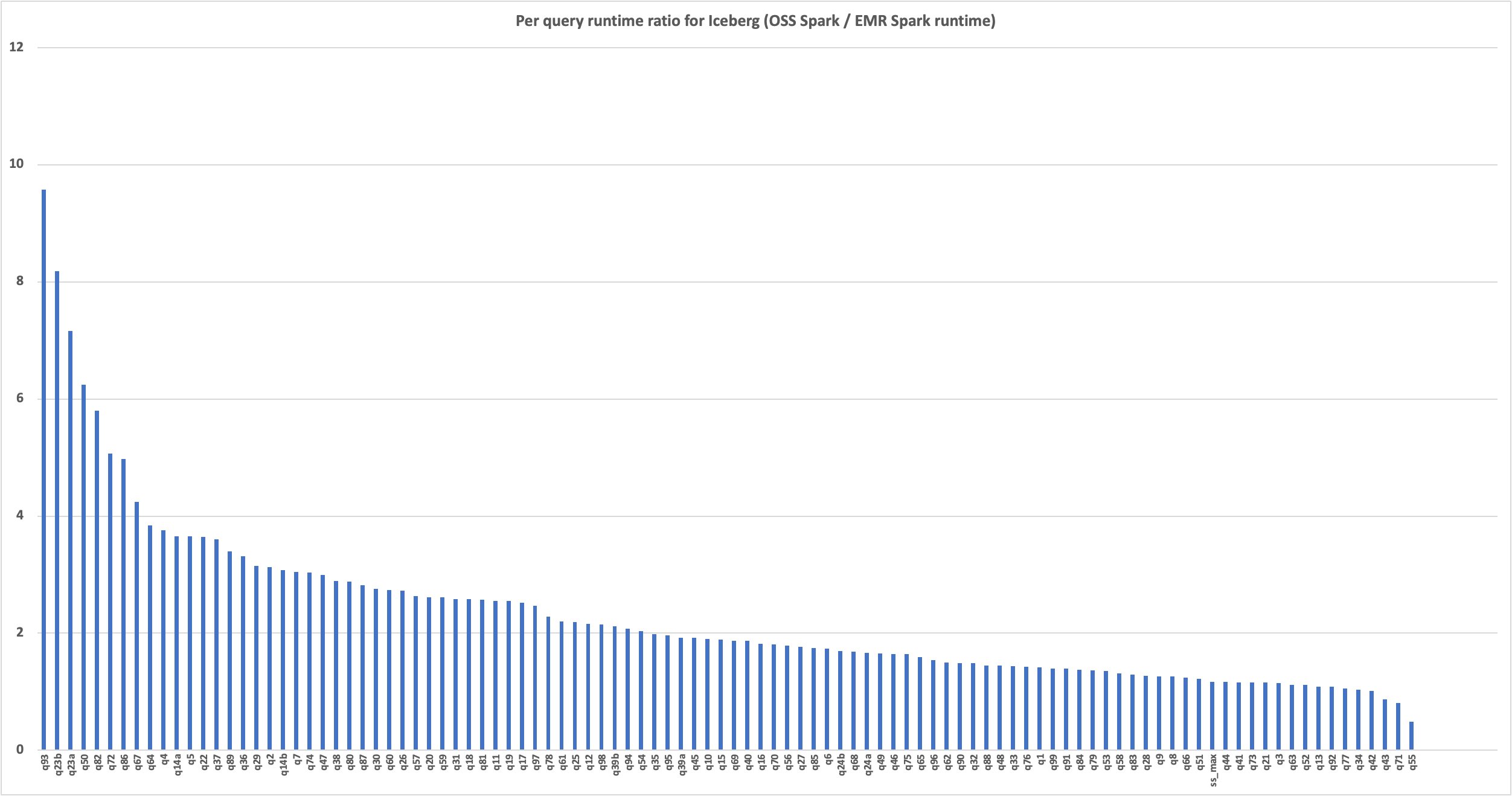
The next chart demonstrates the per-query efficiency enchancment of Amazon EMR 7.1 relative to open supply Spark 3.5.1 and Iceberg 1.5.2. The extent of the speedup varies from one question to a different, starting from 9.6 occasions sooner for q93 to 1.04 occasions sooner for q34, with Amazon EMR outperforming the open supply Spark with Iceberg tables. The horizontal axis arranges the TPC-DS 3 TB benchmark queries in descending order primarily based on the efficiency enchancment seen with Amazon EMR, and the vertical axis depicts the magnitude of this speedup in seconds.
Price comparability
Our benchmark supplies the full runtime and geometric imply information to evaluate the efficiency of Spark and Iceberg in a fancy, real-world determination assist situation. For added insights, we additionally look at the price facet. We calculate price estimates utilizing formulation that account for EC2 On-Demand situations, Amazon Elastic Block Retailer (Amazon EBS), and Amazon EMR bills.
- Amazon EC2 price (contains SSD price) = variety of situations * r5d.4xlarge hourly fee * job runtime in hours
- 4xlarge hourly fee = $1.152 per hour
- Root Amazon EBS price = variety of situations * Amazon EBS per GB-hourly fee * root EBS quantity measurement * job runtime in hours
- Amazon EMR price = variety of situations * r5d.4xlarge Amazon EMR price * job runtime in hours
- 4xlarge Amazon EMR price = $0.27 per hour
- Complete price = Amazon EC2 price + root Amazon EBS price + Amazon EMR price
The calculations reveal that the Amazon EMR 7.1 benchmark yields a 2.2-fold price effectivity enchancment over open supply Spark 3.5.1 and Iceberg 1.5.2 in working the benchmark job.
| Metric | Amazon EMR 7.1 | Open Supply Spark 3.5.1 and Iceberg 1.5.2 |
| Runtime in hours | 0.564 | 1.548 |
| Variety of EC2 situations | 9 | 9 |
| Amazon EBS Measurement | 20gb | 20gb |
| Amazon EC2 price | $5.85 | $16.05 |
| Amazon EBS price | $0.01 | $0.04 |
| Amazon EMR price | $1.37 | $0 |
| Complete price | $7.23 | $16.09 |
| Price financial savings | Amazon EMR 7.1 is 2.2 occasions higher | Baseline |
Along with the time-based metrics mentioned up to now, information from Spark occasion logs reveals that Amazon EMR 7.1 scanned roughly 3.4 occasions much less information from Amazon S3 and 4.1 occasions fewer data than the open supply model within the TPC-DS 3 TB benchmark. This discount in Amazon S3 information scanning contributes on to price financial savings for Amazon EMR workloads.
Run open supply Spark benchmarks on Iceberg tables
We used separate EC2 clusters, every geared up with 9 r5d.4xlarge situations, for testing each open supply Spark 3.5.1 and Iceberg 1.5.2 and Amazon EMR 7.1. The first node was geared up with 16 vCPU and 128 GB of reminiscence, and the eight employee nodes collectively had 128 vCPU and 1024 GB of reminiscence. We carried out checks utilizing the Amazon EMR default settings to showcase the everyday person expertise and minimally adjusted the settings of Spark and Iceberg to take care of a balanced comparability.
The next desk summarizes the Amazon EC2 configurations for the first node and eight employee nodes of sort r5d.4xlarge.
| EC2 Occasion | vCPU | Reminiscence (GiB) | Occasion Storage (GB) | EBS Root Quantity (GB) |
| r5d.4xlarge | 16 | 128 | 2 x 300 NVMe SSD | 20 GB |
Conditions
The next stipulations are required to run the benchmarking:
- Utilizing the directions within the emr-spark-benchmark GitHub repo, arrange the TPC-DS supply information in your S3 bucket and in your native laptop.
- Construct the benchmark utility following the steps supplied in Steps to construct spark-benchmark-assembly utility and duplicate the benchmark utility to your S3 bucket. Alternatively, copy spark-benchmark-assembly-3.5.1.jar to your S3 bucket.
- Create Iceberg tables from the TPC-DS supply information. Observe the directions on GitHub to create Iceberg tables utilizing the Hadoop catalog. For instance, the next code makes use of an EMR 7.1 cluster with Iceberg enabled to create the tables:
Word the Hadoop catalog warehouse location and database title from the previous step. We use the identical tables to run benchmarks with Amazon EMR 7.1 and open supply Spark and Iceberg.
This benchmark utility is constructed from the department tpcds-v2.13_iceberg. When you’re constructing a brand new benchmark utility, swap to the right department after downloading the supply code from the GitHub repo.
Create and configure a YARN cluster on Amazon EC2
To check Iceberg efficiency between Amazon EMR on Amazon EC2 and open supply Spark on Amazon EC2, observe the directions within the emr-spark-benchmark GitHub repo to create an open supply Spark cluster on Amazon EC2 utilizing Flintrock with eight employee nodes.
Based mostly on the cluster choice for this check, the next configurations are used:
Run the TPC-DS benchmark with Apache Spark 3.5.1 and Iceberg 1.5.2
Full the next steps to run the TPC-DS benchmark:
- Log in to the open supply cluster major utilizing
flintrock login $CLUSTER_NAME. - Submit your Spark job:
- Select the right Iceberg catalog warehouse location and database that has the created Iceberg tables.
- The outcomes are created in
s3://<YOUR_S3_BUCKET>/benchmark_run. - You’ll be able to monitor progress in
/media/ephemeral0/spark_run.log.
Summarize the outcomes
After the Spark job finishes, retrieve the check outcome file from the output S3 bucket at s3://<YOUR_S3_BUCKET>/benchmark_run/timestamp=xxxx/abstract.csv/xxx.csv. This may be finished both by means of the Amazon S3 console by navigating to the required bucket location or by utilizing the Amazon Command Line Interface (AWS CLI). The Spark benchmark utility organizes the information by making a timestamp folder and inserting a abstract file inside a folder labeled abstract.csv. The output CSV recordsdata include 4 columns with out headers:
- Question title
- Median time
- Minimal time
- Most time
With the information from three separate check runs with one iteration every time, we are able to calculate the common and geometric imply of the benchmark runtimes.
Run the TPC-DS benchmark with the EMR runtime for Spark
A lot of the directions are much like Steps to run Spark Benchmarking with just a few Iceberg-specific particulars.
Conditions
Full the next prerequisite steps:
- Run
aws configureto configure the AWS CLI shell to level to the benchmarking AWS account. Consult with Configure the AWS CLI for directions. - Add the benchmark utility JAR file to Amazon S3.
Deploy the EMR cluster and run the benchmark job
Full the next steps to run the benchmark job:
- Use the AWS CLI command as proven in Deploy EMR on EC2 Cluster and run benchmark job to spin up an EMR on EC2 cluster. Ensure that to allow Iceberg. See Create an Iceberg cluster for extra particulars. Select the right Amazon EMR model, root quantity measurement, and identical useful resource configuration because the open supply Flintrock setup. Consult with create-cluster for an in depth description of the AWS CLI choices.
- Retailer the cluster ID from the response. We’d like this for the subsequent step.
- Submit the benchmark job in Amazon EMR utilizing
add-stepsfrom the AWS CLI:- Change <cluster ID> with the cluster ID from Step 2.
- The benchmark utility is at
s3://<your-bucket>/spark-benchmark-assembly-3.5.1.jar. - Select the right Iceberg catalog warehouse location and database that has the created Iceberg tables. This needs to be the identical because the one used for the open supply TPC-DS benchmark run.
- The outcomes will likely be in
s3://<your-bucket>/benchmark_run.
Summarize the outcomes
After the step is full, you possibly can see the summarized benchmark outcome at s3://<YOUR_S3_BUCKET>/benchmark_run/timestamp=xxxx/abstract.csv/xxx.csv in the identical manner because the earlier run and compute the common and geometric imply of the question runtimes.
Clear up
To forestall any future costs, delete the sources you created by following the directions supplied within the Cleanup part of the GitHub repository.
Abstract
Amazon EMR is constantly enhancing the EMR runtime for Spark when used with Iceberg tables, attaining a efficiency that’s 2.7 occasions sooner than open supply Spark 3.5.1 and Iceberg 1.5.2 on TPC-DS 3 TB, v2.13. We encourage you to maintain updated with the newest Amazon EMR releases to completely profit from ongoing efficiency enhancements.
To remain knowledgeable, subscribe to the AWS Massive Information Weblog’s RSS feed, the place you’ll find updates on the EMR runtime for Spark and Iceberg, in addition to recommendations on configuration finest practices and tuning suggestions.
Concerning the authors
 Hari Kishore Chaparala is a software program improvement engineer for Amazon EMR at Amazon Internet Companies.
Hari Kishore Chaparala is a software program improvement engineer for Amazon EMR at Amazon Internet Companies.
 Udit Mehrotra is an Engineering Supervisor for EMR at Amazon Internet Companies.
Udit Mehrotra is an Engineering Supervisor for EMR at Amazon Internet Companies.