

{kind=link}
Introduction
In right this moment’s fast-paced software program improvement atmosphere, making certain optimum software efficiency is essential. Monitoring real-time metrics equivalent to response instances, error charges, and useful resource utilization will help keep excessive availability and ship a seamless person expertise. Apache Pinot, an open-source OLAP datastore, provides the flexibility to deal with real-time knowledge ingestion and low-latency querying, making it an acceptable answer for monitoring software efficiency at scale. On this article, we’ll discover the way to implement a real-time monitoring system utilizing Apache Pinot, with a concentrate on establishing Kafka for knowledge streaming, defining Pinot schemas and tables, querying efficiency knowledge with Python, and visualizing metrics with instruments like Grafana.

Studying Targets
- Learn the way Apache Pinot can be utilized to construct a real-time monitoring system for monitoring software efficiency metrics in a distributed atmosphere.
- Learn to write and execute SQL queries in Python to retrieve and analyze real-time efficiency metrics from Apache Pinot.
- Achieve hands-on expertise in establishing Apache Pinot, defining schemas, and configuring tables to ingest and retailer software metrics knowledge in real-time from Kafka.
- Perceive the way to combine Apache Pinot with visualization instruments like Grafana or Apache Superset.
This text was printed as part of the Information Science Blogathon.
Use Case: Actual-time Utility Efficiency Monitoring
Let’s discover a state of affairs the place we ’re managing a distributed software serving tens of millions of customers throughout a number of areas. To take care of optimum efficiency, we have to monitor numerous efficiency metrics:
- Response Instances– How shortly our software responds to person requests.
- Error Charges: The frequency of errors in your software.
- CPU and Reminiscence Utilization: The assets your software is consuming.
Deploy Apache Pinot to create a real-time monitoring system that ingests, shops, and queries efficiency knowledge, enabling fast detection and response to points.
System Structure
- Information Sources:
- Metrics and logs are collected from completely different software companies.
- These logs are streamed to Apache Kafka for real-time ingestion.
- Information Ingestion:
- Apache Pinot ingests this knowledge immediately from Kafka subjects, offering real-time processing with minimal delay.
- Pinot shops the information in a columnar format, optimized for quick querying and environment friendly storage.
- Querying:
- Pinot acts because the question engine, permitting you to run complicated queries towards real-time knowledge to realize insights into software efficiency.
- Pinot’s distributed structure ensures that queries are executed shortly, at the same time as the quantity of knowledge grows.
- Visualization:
- The outcomes from Pinot queries will be visualized in real-time utilizing instruments like Grafana or Apache Superset, providing dynamic dashboards for monitoring KPI’s.
- Visualization is essential to creating the information actionable, permitting you to observe KPIs, set alerts, and reply to points in real-time.
Setting Up Kafka for Actual-Time Information Streaming
Step one is to arrange Apache Kafka to deal with real-time streaming of our software’s logs and metrics. Kafka is a distributed streaming platform that enables us to publish and subscribe to streams of information in real-time. Every microservice in our software can produce log messages or metrics to Kafka subjects, which Pinot will later eat
Set up Java
To run Kafka, we can be putting in Java on our system-
sudo apt set up openjdk-11-jre-headless -y
Confirm the Java Model
java –model
Downloading Kafka
wget https://downloads.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgzsudo mkdir /usr/native/kafka-server
sudo tar xzf kafka_2.13-3.4.0.tgzAdditionally we have to transfer the extracted information to the folder given below-
sudo mv kafka_2.13-3.4.0/* /usr/native/kafka-server

Reset the Configuration Information by the Command
sudo systemctl daemon-reloadBeginning Kafka
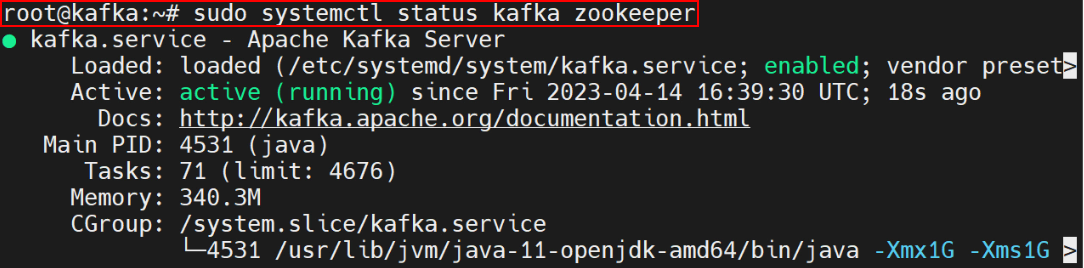
Assuming Kafka and Zookeeper are already put in, Kafka will be began utilizing under instructions:
# Begin Zookeeper
zookeeper-server-start.sh config/zookeeper.properties
# Begin Kafka server
kafka-server-start.sh config/server.properties
Creating Kafka Matters
Subsequent, creation of a Kafka matter for our software metrics. Matters are the channels by means of which knowledge flows in Kafka. Right here, we’ve created a subject named app-metrics with 3 partitions and a replication issue of 1. The variety of partitions distributes the information throughout Kafka brokers, whereas the replication issue controls the extent of redundancy by figuring out what number of copies of the information exist.
kafka-topics.sh --create --topic app-metrics --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1Publishing Information to Kafka
Our software can publish metrics to the Kafka matter in real-time. This script simulates sending software metrics to the Kafka matter each second. The metrics embrace particulars equivalent to service identify, endpoint, standing code, response time, CPU utilization, reminiscence utilization, and timestamp.
from confluent_kafka import Producer
import json
import time
# Kafka producer configuration
conf = {'bootstrap.servers': "localhost:9092"}
producer = Producer(**conf)
# Perform to ship a message to Kafka
def send_metrics():
metrics = {
"service_name": "auth-service",
"endpoint": "/login",
"status_code": 200,
"response_time_ms": 123.45,
"cpu_usage": 55.2,
"memory_usage": 1024.7,
"timestamp": int(time.time() * 1000)
}
producer.produce('app-metrics', worth=json.dumps(metrics))
producer.flush()
# Simulate sending metrics each 2 seconds
whereas True:
send_metrics()
time.sleep(2)
Defining Pinot Schema and Desk Configuration
With Kafka arrange and streaming knowledge, the following step is to configure Apache Pinot to ingest and retailer this knowledge. This includes defining a schema and making a desk in Pinot.
Schema Definition
The schema defines the construction of the information that Pinot will ingest. It specifies the size (attributes) and metrics (measurable portions) that can be saved, in addition to the information varieties for every subject. Create a JSON file named “app_performance_ms_schema.json” with the next content material:
{
"schemaName": "app_performance_ms",
"dimensionFieldSpecs": [
{"name": "service", "dataType": "STRING"},
{"name": "endpoint", "dataType": "STRING"},
{"name": "s_code", "dataType": "INT"}
],
"metricFieldSpecs": [
{"name": "response_time", "dataType": "DOUBLE"},
{"name": "cpu_usage", "dataType": "DOUBLE"},
{"name": "memory_usage", "dataType": "DOUBLE"}
],
"dateTimeFieldSpecs": [
{
"name": "timestamp",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}Desk Configuration
The desk configuration file tells Pinot the way to handle the information, together with particulars on knowledge ingestion from Kafka, indexing methods, and retention insurance policies.
Create one other JSON file named “app_performance_metrics_table.json” with the next content material:
{
"tableName": "appPerformanceMetrics",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"schemaName": "appMetrics",
"replication": "1"
},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.matter.identify": "app_performance_metrics",
"stream.kafka.dealer.record": "localhost:9092",
"stream.kafka.shopper.sort": "lowlevel"
}
}
}This configuration specifies that the desk will ingest knowledge from the app_performance_metrics Kafka matter in real-time. It makes use of the timestamp column as the first time column and configures indexing to assist environment friendly queries.
Deploying the Schema and Desk Configuration
As soon as the schema and desk configuration are prepared, we will deploy them to Pinot utilizing the next instructions:
bin/pinot-admin.sh AddSchema -schemaFile app_performance_ms_schema.json -exec
bin/pinot-admin.sh AddTable -tableConfigFile app_performance_metrics_table.json -schemaFile app_performance_ms_schema.json -exec
After deployment, Apache Pinot will begin ingesting knowledge from the Kafka matter app-metrics and making it accessible for querying.
Querying Information to Monitor KPIs
As Pinot ingests knowledge, now you can begin querying it to observe key efficiency indicators (KPIs). Pinot helps SQL-like queries, permitting us to retrieve and analyze knowledge shortly. Right here’s a Python script that queries the common response time and error charge for every service over the previous 5 minutes:
import requests
import json
# Pinot dealer URL
pinot_broker_url = "http://localhost:8099/question/sql"
# SQL question to get common response time and error charge
question = """
SELECT service_name,
AVG(response_time_ms) AS avg_response_time,
SUM(CASE WHEN status_code >= 400 THEN 1 ELSE 0 END) / COUNT(*) AS error_rate
FROM appPerformanceMetrics
WHERE timestamp >= in the past('PT5M')
GROUP BY service_name
"""
# Execute the question
response = requests.submit(pinot_broker_url, knowledge=question, headers={"Content material-Kind": "software/json"})
if response.status_code == 200:
outcome = response.json()
print(json.dumps(outcome, indent=4))
else:
print("Question failed with standing code:", response.status_code)
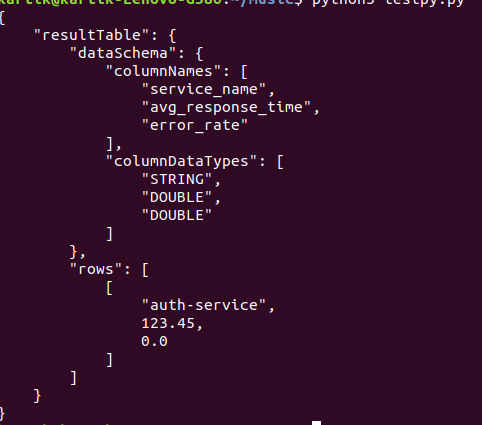
This script sends a SQL question to Pinot to calculate the common response time and error charge for every service within the final 5 minutes. These metrics are essential for understanding the real-time efficiency of our software.
Understanding the Question Outcomes
- Common Response Time: Supplies perception into how shortly every service is responding to requests. Increased values may point out efficiency bottlenecks.
- Error Fee: Reveals the proportion of requests that resulted in errors (standing codes >= 400). A excessive error charge may sign issues with the service.
Visualizing the Information: Integrating Pinot with Grafana
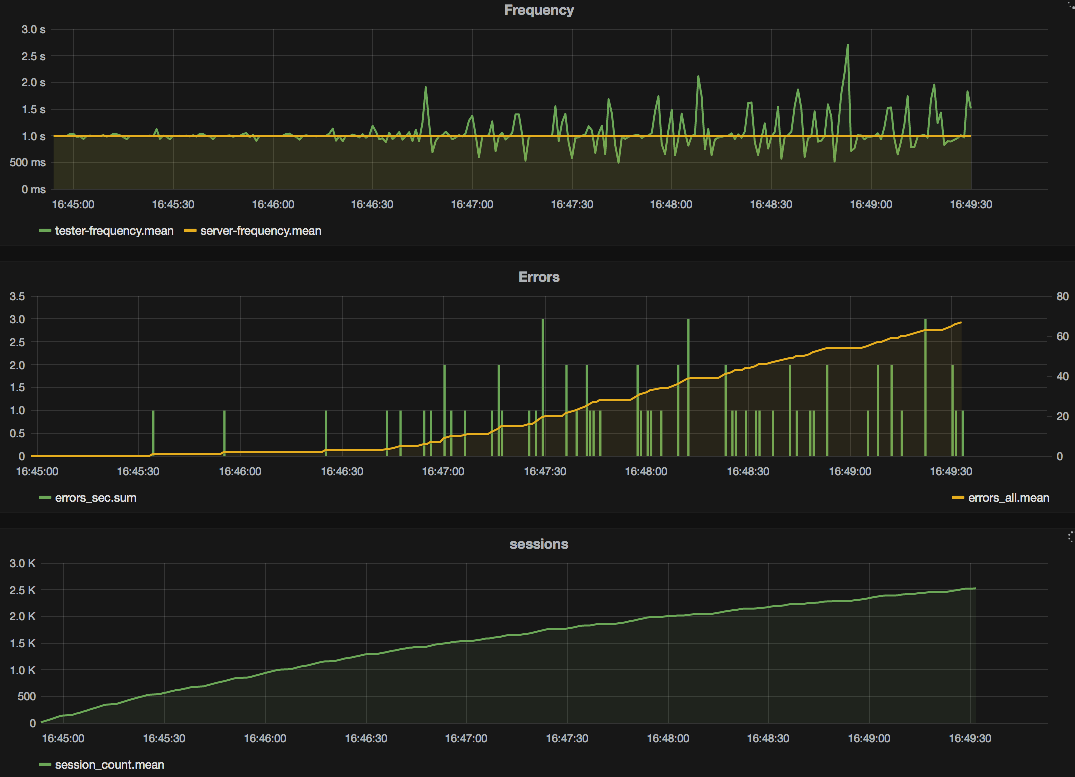
Grafana is a well-liked open-source visualization software that helps integration with Apache Pinot. By connecting Grafana to Pinot, we will create real-time dashboards that show metrics like response instances, error charges, and useful resource utilization. Instance dashboard can embrace the next information-
- Response Instances frequency: A line chart with space displaying the common response time for every service over the previous 24 hours.
- Error Charges: A stacked bar chart highlighting companies with excessive error charges, serving to you determine problematic areas shortly.
- Periods Utilization: An space chart displaying CPU and reminiscence utilization traits throughout completely different companies.
This visualization setup supplies a complete view of our software’s well being and efficiency, enabling us to observe KPIs constantly and take proactive measures when points come up.
Superior Issues
As our real-time monitoring system with Apache Pinot expands, there are a number of superior facets to handle for sustaining its effectiveness:
- Information Retention and Archiving:
- Problem: As your software generates rising quantities of knowledge, managing storage effectively turns into essential to keep away from inflated prices and efficiency slowdowns.
- Answer: Implementing knowledge retention insurance policies helps handle knowledge quantity by archiving or deleting older information which are not wanted for instant evaluation. Apache Pinot automates these processes by means of its section administration and knowledge retention mechanisms.
- Scaling Pinot:
- Problem: The rising quantity of knowledge and question requests can pressure a single Pinot occasion or cluster setup.
- Answer: Apache Pinot helps horizontal scaling, enabling you to develop your cluster by including extra nodes. This ensures that the system can deal with elevated knowledge ingestion and question hundreds successfully, sustaining efficiency as your software grows.
- Alerting :
- Problem: Detecting and responding to efficiency points with out automated alerts will be difficult, probably delaying downside decision.
- Answer: Combine alerting programs to obtain notifications when metrics exceed predefined thresholds. You should utilize instruments like Grafana or Prometheus to arrange alerts, making certain you might be promptly knowledgeable of any anomalies or points in your software’s efficiency.
- Efficiency Optimization:
- Problem: With a rising dataset and complicated queries, sustaining environment friendly question efficiency can grow to be difficult.
- Answer: Repeatedly optimize your schema design, indexing methods, and question patterns. Make the most of Apache Pinot’s instruments to observe and handle efficiency bottlenecks. Make use of partitioning and sharding strategies to higher distribute knowledge and queries throughout the cluster.
Conclusion
Efficient real-time monitoring is important for making certain the efficiency and reliability of recent purposes. Apache Pinot provides a robust answer for real-time knowledge processing and querying, making it well-suited for complete monitoring programs. By implementing the methods mentioned and contemplating superior subjects like scaling and safety, you’ll be able to construct a strong and scalable monitoring system that helps you keep forward of potential efficiency points, making certain a clean expertise in your customers.
Key Takeaways
- Apache Pinot is adept at dealing with real-time knowledge ingestion and supplies low-latency question efficiency, making it a robust software for monitoring software efficiency metrics. It integrates properly with streaming platforms like Kafka, enabling instant evaluation of metrics equivalent to response instances, error charges, and useful resource utilization.
- Kafka streams software logs and metrics, which Apache Pinot then ingests. Configuring Kafka subjects and linking them with Pinot permits for steady processing and querying of efficiency knowledge, making certain up-to-date insights.
- Correctly defining schemas and configuring tables in Apache Pinot is essential for environment friendly knowledge administration. The schema outlines the information construction and kinds, whereas the desk configuration controls knowledge ingestion and indexing, supporting efficient real-time evaluation.
- Apache Pinot helps SQL-like queries for in-depth knowledge evaluation. When used with visualization instruments equivalent to Grafana or Apache Superset, it permits the creation of dynamic dashboards that present real-time visibility into software efficiency, aiding within the swift detection and determination of points.
Regularly Requested Questions
A. Apache Pinot is optimized for low-latency querying, making it ultimate for situations the place real-time insights are essential. Its skill to ingest knowledge from streaming sources like Kafka and deal with large-scale, high-throughput knowledge units permits it to offer up-to-the-minute analytics on software efficiency metrics.
A. Apache Pinot is designed to ingest real-time knowledge by immediately consuming messages from Kafka subjects. It helps each low-level and high-level Kafka shoppers, permitting Pinot to course of and retailer knowledge with minimal delay, making it accessible for instant querying.
A. To arrange a real-time monitoring system with Apache Pinot, you want:
Information Sources: Utility logs and metrics streamed to Kafka.
Apache Pinot: For real-time knowledge ingestion and querying.
Schema and Desk Configuration: Definitions in Pinot for storing and indexing the metrics knowledge.
Visualization Instruments: Instruments like Grafana or Apache Superset for creating real-time dashboards
A. Sure, Apache Pinot helps integration with different knowledge streaming platforms like Apache Pulsar and AWS Kinesis. Whereas this text focuses on Kafka, the identical ideas apply when utilizing completely different streaming platforms, although configuration particulars will range.
The media proven on this article isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
Hey World : Myself Kartik Sharma, working as senior knowledge engineer and enterprise analyst for Zensar Applied sciences Ltd. I’m new to running a blog and simply making an attempt it out for enjoyable. “A techno geek who by chance fell in love with phrases.”